
EP17: Design patterns cheat sheet. Also...

For this week’s newsletter, we will cover:
Design patterns cheat sheet
6 ways to turn code into beautiful architecture diagrams
What is a File Descriptor?
Scan to pay in 2 minutes
Direct payments
Design patterns cheat sheet


6 ways to turn code into beautiful architecture diagrams
1. Diagrams
Turn python code into cloud system architecture diagrams
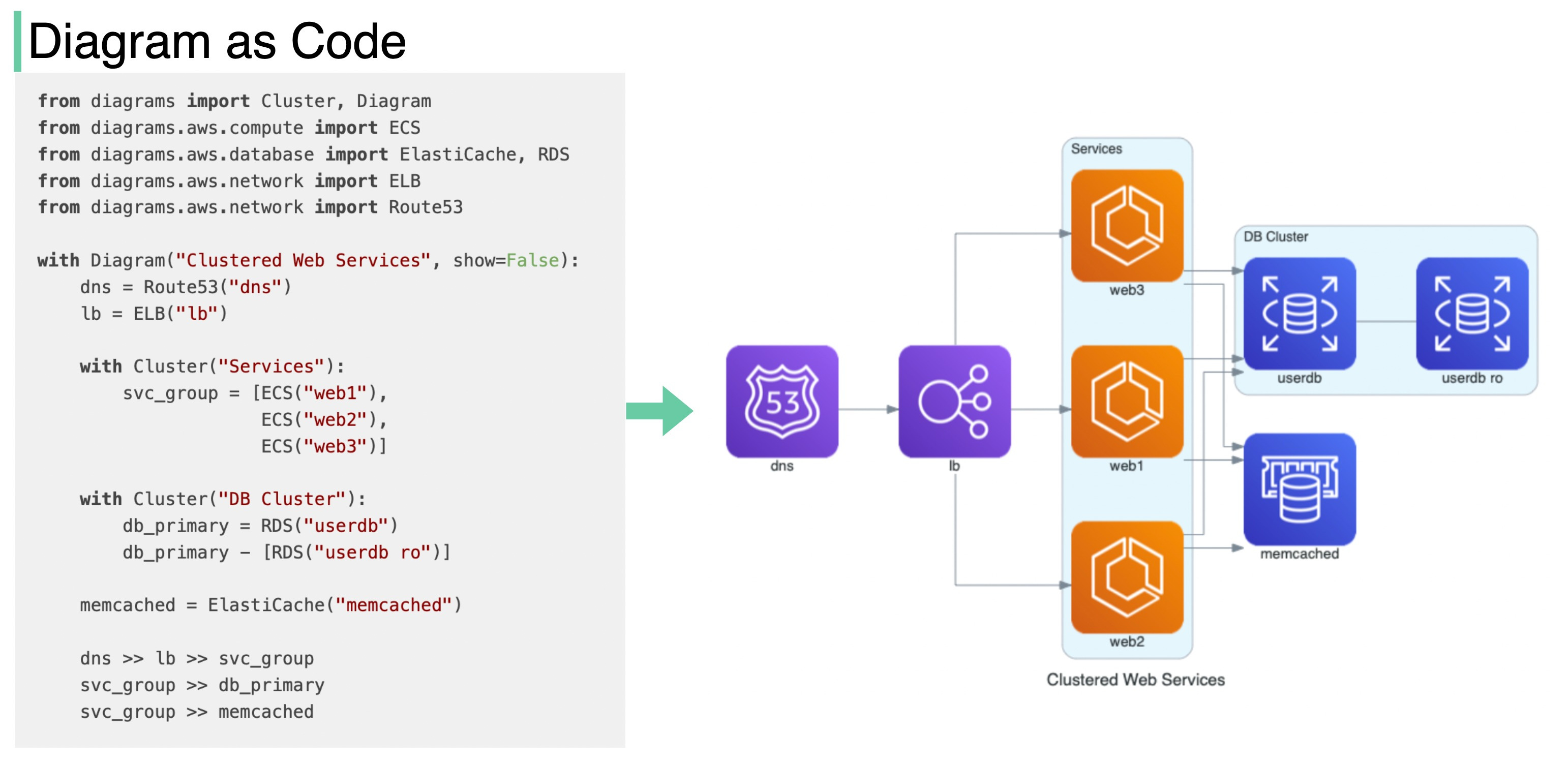
Thanks for reading ByteByteGo Newsletter! Subscribe for free to receive new posts and support my work.
2. Mermaid
Generation of diagram and flowchart from text in a similar manner as markdown
Example:

3. ASCII editor
Free editor: Asciiflow, dot-to-ascii
Paid editor: Monodraw


4. PlantUML
It is an open-source tool allowing users to create diagrams from plain text language.

5. Markmap
Visualize your Markdown as mindmaps. It supports the VS code plugin.

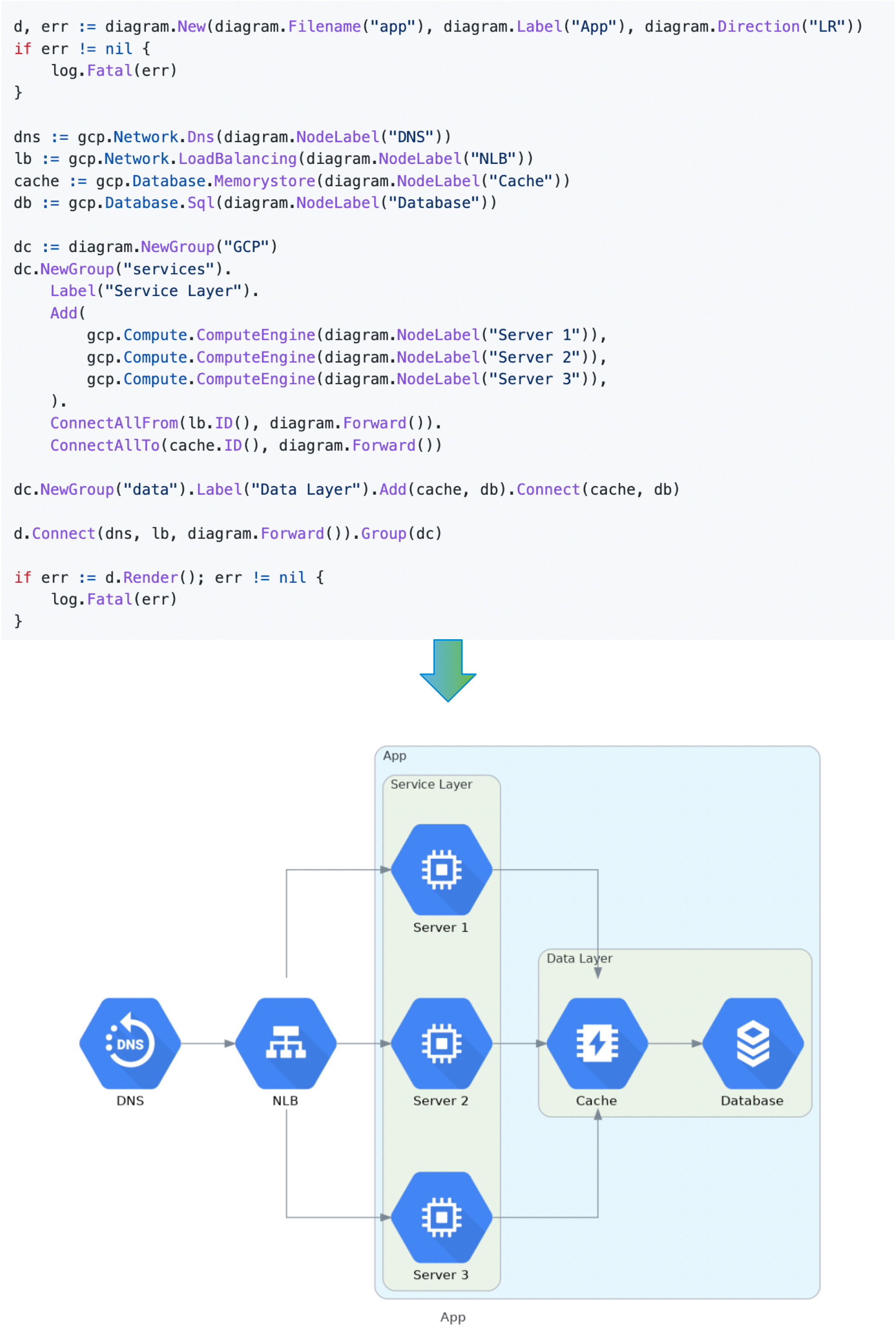
6. Go diagrams
Create beautiful system diagrams with Go
What is a File Descriptor?
How do we interact with Linux Filesystem via file descriptors?
A file descriptor represents an open file. It is a unique number assigned by the operating system to each file. It is an abstraction for working with files. We need to use file descriptors to read from or write to files in our program. Each process maintains its own file descriptor table.
The diagram below shows the layered architecture in Linux filesystem. Let’s take process 1234 as an example.

🔹 In User Space
When we open a file called “fileA.txt” in Process 1234, we get file descriptor fd1, which is equal to 3. We can then pass the file descriptor to other functions to write data to the file.
🔹 In Kernel Space
In Linux kernel, there is a process table to maintain the data for the processes. Each process has an entry in the table. Each process maintains a file descriptor table, with file descriptors as its indices. Notice that file descriptors 0,1 and 2 are reserved in each file descriptor table to represent stdin, stdout, and stderr.
The file pointer points to an entry in the open file table, which has information about open files across all processes. Multiple file descriptors can point to the same file table entry. For example, file descriptor 0, 1 and 2 points to the same open file table entry.
Since different open file table entries can represent the same file, it is a waste of resources to store the file static information so many times. We need another abstraction layer called ‘vnode table’ to store the static data.
In each file table entry, there is a vnode pointer, which points to an entry in vnode table. The static information includes file type, function pointers, reference counts, inode etc. inode describes a physical object in the filesystem.
🔹 In Filesystem
The inode array element stores the actual file information, including permission mode, owners, timestamps, etc. inode also points to the data blocks stored in the filesystem.
Over to you: When we close a file in a program, do you know which entries are deleted in these data structures?
Scan to pay in 2 minutes (YouTube Video)
Direct payments
Do you know how you get paid at work? In the US, tech companies usually run payrolls via Automatic Clearing House (ACH).

ACH handles retail transactions and is part of American retail payment systems. It processes transactions in batches, not in real-time. The diagram below shows how ACH direct deposit works with payrolls.
🔹Step 0: Before we can use ACH network, the originator who starts the transactions needs to open an account at a commercial bank because only banks are allowed to initiate ACH transactions directly. The bank is called ODFI (Originating Depository Financial Institution). Then the transaction receiver needs to authorize the originator for certain types of transactions.
🔹Step 1: The originator company originates salary payment transactions. The transactions are sent to a 3rd-party processor like Gusto. The third-party processor helps with ACH-related services like generating ACH files, etc.
🔹Step 2: The third-party processor generates ACH files on behalf of the originator. The files are uploaded to an SFTP established by the ODFI. This should be done by the 7 PM cut-off time, as specified by the ODFI bank.
🔹Step 3: After normal business hours in the evening, the ODFI bank forwards the ACH files to the ACH operator for clearing and settlement. There are two ACH operators, one is the Federal Reserve (FedACH), and the other is EPN (Electronic Payment Network – which is operated by a private company).
🔹Step 4: The ACH files are processed around midnight and made available to the receiving bank RDFI (Receiving Depository Financial Institution.)
🔹Step 5: The RDFI operates on the receiver’s bank accounts based on the instructions in the ACH files. In our case, the receiver receives $100 from the originator. This is done when the RDFI opens for business at 6 AM the next day.
ACH is a next-day settlement system. It means transactions sent out by 7 PM on one day will arrive the following morning.
Since 2018, it’s possible to choose Same Day ACH so funds can be transferred on the same business day.
Over to you: ACH is a US financial network. If you live outside the US, do you know what payment method your employer uses to send payment? What’s the difference between ACH and wire transfer?
Thanks for making it this far! 🤗
If you want to learn more about System Design, check out our books:
Paperback edition: https://geni.us/XxCd
Digital edition: https://bit.ly/3lg41jK
Great job on the design patterns cheat sheet Mr. Alex, thank you so much!
It would be great if these patterns came with a real-world example, so we can see how each one could be implemented in a real-world application.
Nice!!!! Thank you for putting so much effort into making this!