
8 Data Structures That Power Your Databases.

8 Data Structures That Power Your Databases. Which one should we pick?
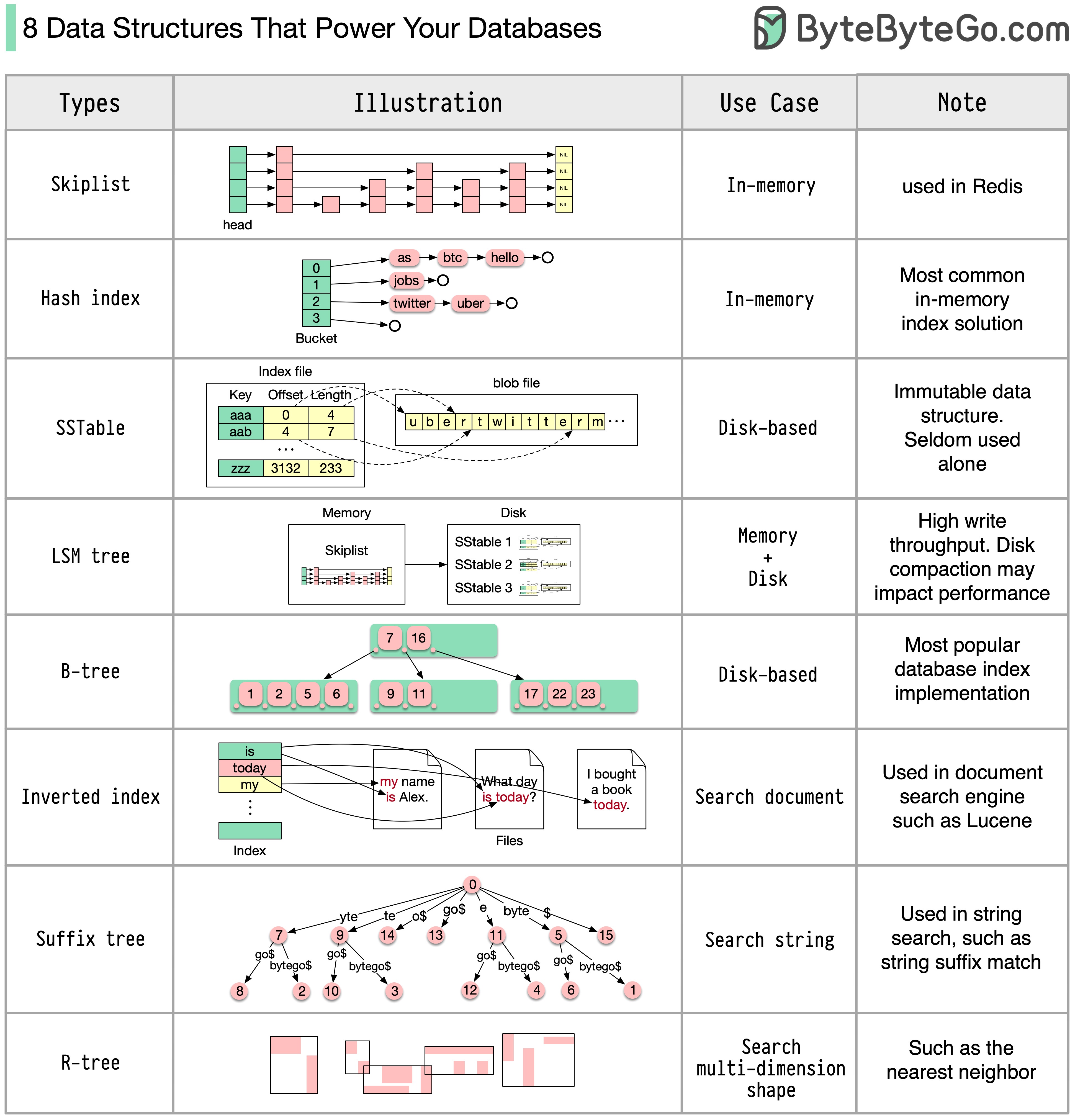
The answer will vary depending on your use case. Data can be indexed in memory or on disk. Similarly, data formats vary, such as numbers, strings, geographic coordinates, etc. The system might be write-heavy or read-heavy. All of these factors affect your choice of database index format.
The following are some of the most popular data structures used for indexing data:
🔹Skiplist: a common in-memory index type. Used in Redis
🔹Hash index: a very common implementation of the “Map” data structure (or “Collection”)
🔹SSTable: immutable on-disk “Map” implementation
🔹LSM tree: Skiplist + SSTable. High write throughput
🔹B-tree: disk-based solution. Consistent read/write performance
🔹Inverted index: used for document indexing. Used in Lucene
🔹Suffix tree: for string pattern search
🔹R-tree: multi-dimension search, such as finding the nearest neighbor
This is not an exhaustive list of all database index types. Over to you:
1). Which one have you used and for what purpose?
2). There is another one called “reverse index”. Do you know the difference between “reverse index” and “inverted index”?
I will provide a more in-depth analysis of this topic. Subscribe to our newsletter to get the latest update.
Byte eat go actually. Very digestible educational content
Hello. Lives bytebytego