A Crash Course in Caching - Part 2

This is part 2 of the Crash Course in Caching series.
Distributed cache
A distributed cache stores frequently accessed data in memory across multiple nodes. The cached data is partitioned across many nodes, with each node only storing a portion of the cached data. The nodes store data as key-value pairs, where each key is deterministically assigned to a specific partition or shard. When a client requests data, the cache system retrieves the data from the appropriate node, reducing the load on the backing storage.
There are different sharding strategies, including modulus, range-based and consistent hashing.
Modulus sharding
Modulus sharding involves assigning a key to a shard based on the hash value of the key modulo the total number of shards. Although this strategy is simple, it can result in many cache misses when the number of shards is increased or decreased. This is because most of the keys will be redistributed to different shards when the pool is resized.

Range-based sharding
Range-based sharding assigns keys to specific shards based on predefined key ranges. With this approach, the system can divide the key space into specific ranges and then map each range to a particular shard. Range-based sharding can be useful for certain business scenarios where data is naturally grouped or partitioned in specific ranges, such as geolocation-based data or data related to specific customer segments.
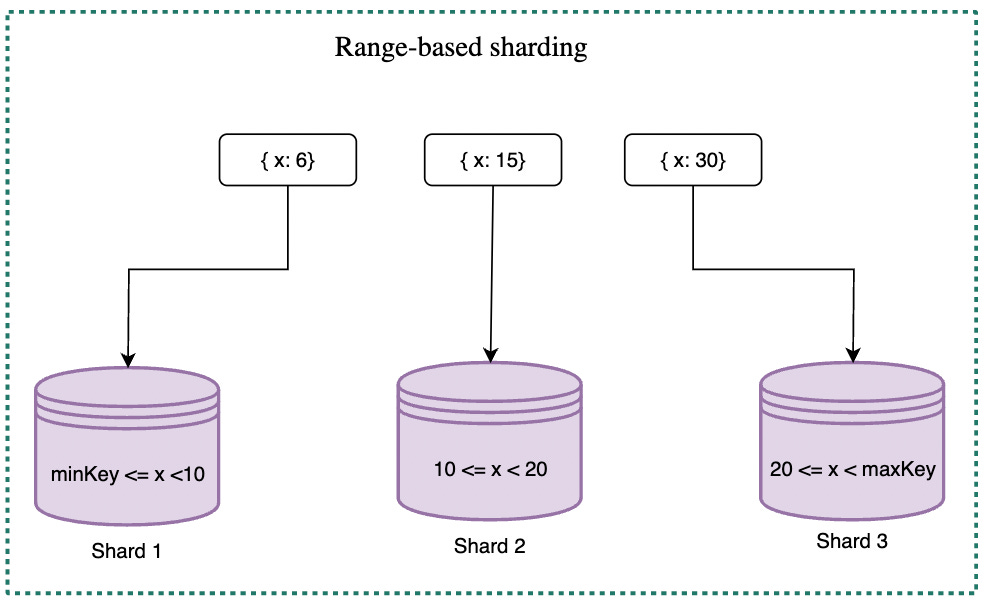
However, this approach can also be challenging to scale because the number of shards is predefined and cannot be easily changed. Changing the number of shards requires redefining the key ranges and remapping the data.
Consistent hashing
Consistent hashing is a widely-used sharding strategy that provides better load balancing and fault tolerance than other sharding methods. With consistent hashing, the keys and the nodes are both mapped to a fixed-size ring, using a hash function to assign each key and node a position on the ring.
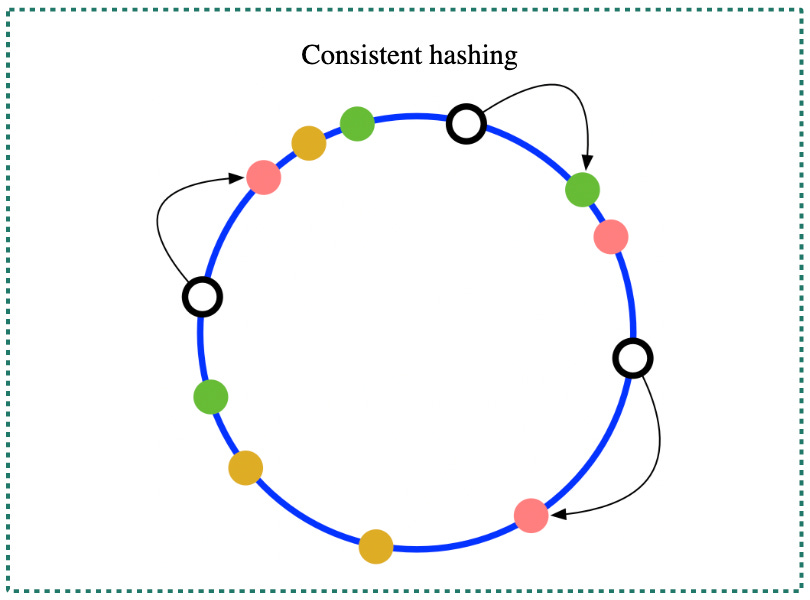
When a key is requested, the system uses the same hash function to map the key to a position on the ring. The system then traverses the ring clockwise from that position until it reaches the first node. That node is responsible for storing the data associated with the key. Adding or removing nodes from the system only requires remapping the keys that were previously stored on the affected nodes, rather than redistributing all the keys, making it easy to change the number of shards with a limited amount of data rehashed. Refer to the reference material to learn more about consistent hashing.
Cache strategies
In this section, we will provide an in-depth analysis of various cache strategies, their characteristics, and suitable use cases.
Cache strategies can be classified by the way they handle reading or writing data:
Read Strategies: Cache-Aside and Read-Through
Write Strategies: Write-Around, Write-Through, and Write-Back
Read Strategies
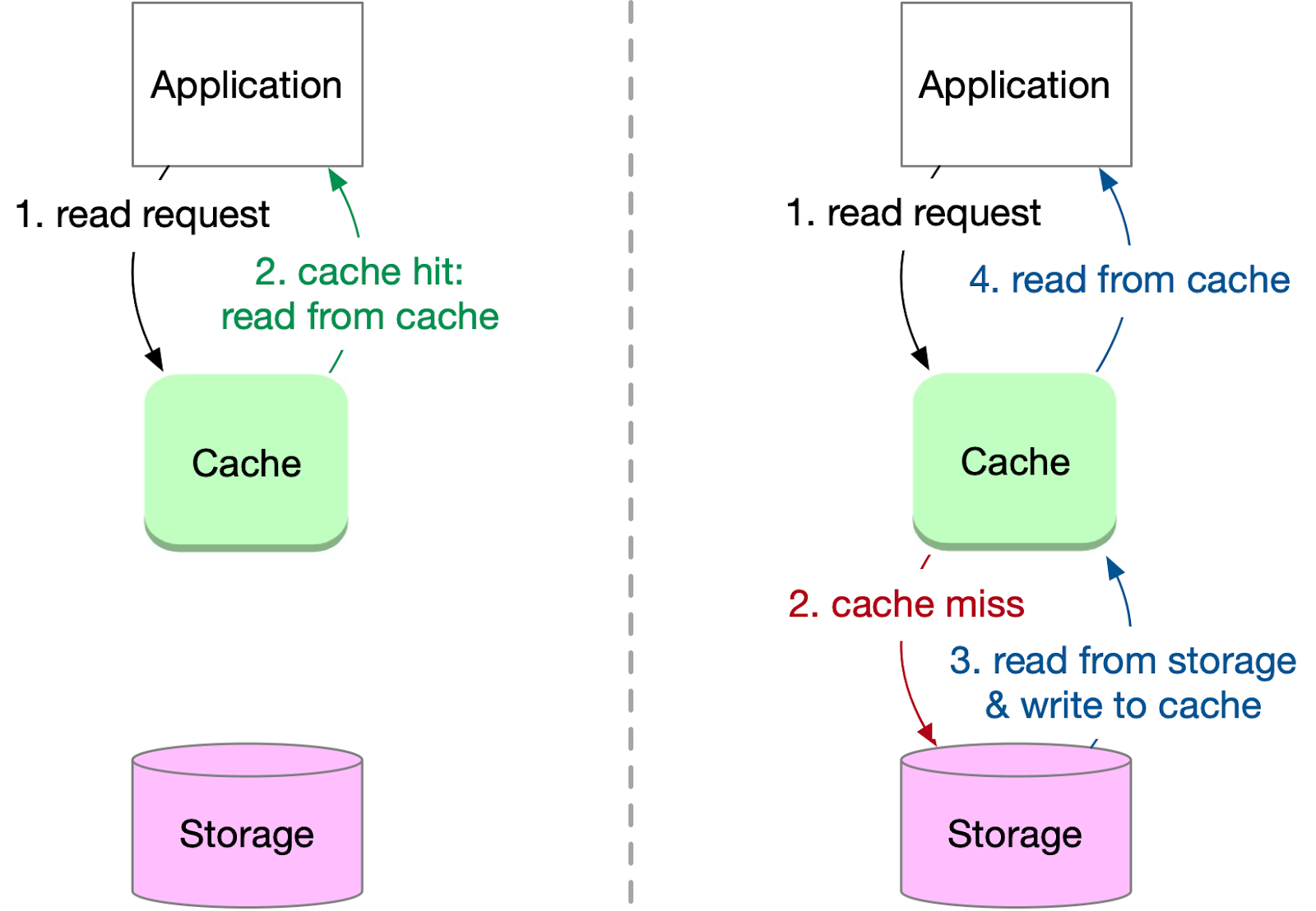
Cache-aside
Cache-aside, also known as lazy loading, is a popular cache strategy where the application directly communicates with both the cache and storage systems. It follows a specific workflow for reading data:
The application requests a key from the cache.
If the key is found in the cache (cache hit), the data is returned to the application.
If the key is not found in the cache (cache miss), the application proceeds to request the key from storage.
The storage returns the data to the application.
The application writes the key and corresponding data into the cache for future reads.

Cache-aside is versatile, as it can accommodate various use cases and adapts well to read-heavy workloads.
Pros:
The system can tolerate cache failures, as it can still read from the storage.
The data model in the cache can differ from that in the storage, providing flexibility for a variety of use cases.
Cons:
The application must manage both cache and storage, complicating the code.
Ensuring data consistency is challenging due to the lack of atomic operations on cache and storage.
When using cache-aside, it is crucial to consider other potential data consistency issues. For instance, if a piece of data is written to the cache, and the value in the storage is updated afterward, the application can only read the stale value from the cache until it is evicted. One solution to this problem is to set an acceptable Time-To-Live (TTL) for each cached record, ensuring that stale data becomes invalid after a certain period. For more stringent data freshness requirements, the application can combine cache-aside with one of the write strategies that are discussed below.
Read-through
The read-through strategy is another common caching approach where the cache serves as an intermediary between the application and the storage system, handling all read requests. This strategy simplifies the application's role by delegating data retrieval responsibilities to the cache. Read-through is particularly suitable for read-heavy workloads and is commonly employed in cache libraries and some stand-alone cache providers. The basic workflow for read-through follows these steps:
The application requests to read a key from the cache.
If the key is found in the cache (cache hit), the data is returned to the application.
If the key is not found in the cache (cache miss), the cache requests the key from the storage.
The cache retrieves the data from storage, writes the key and associated data into the cache, and returns the data to the application.