
A Deep Dive into Amazon DynamoDB Architecture

State of Observability for Financial Services and Insurance (Sponsored)

Financial institutions are experiencing an incredible transformation, stemming from consumers expecting a higher level of digital interaction and access to services and a lower dependency on physical services. At the same time, FSI organizations are faced with increased regulation, with new mandates for IT and cyber risk management such as the Digital Operational Resilience Act (DORA).
To ensure development and innovation proceed at the required speed with a customer-centric focus, they’re turning to observability. Dive into the facts and figures of the adoption and business value of observability across the FSI and insurance sectors.
In 2021, there was a 66-hour Amazon Prime Day shopping event.
The event generated some staggering stats:
Trillions of API calls were made to the database by Amazon applications.
The peak load to the database reached 89 million requests per second.
The database provided single-digit millisecond performance while maintaining high availability.
All of this was made possible by DynamoDB.
Amazon’s DynamoDB is a NoSQL cloud database service that promises consistent performance at any scale.
Besides Amazon’s in-house applications, hundreds of thousands of external customers rely on DynamoDB for high performance, availability, durability, and a fully managed serverless experience. Also, many AWS services such as AWS Lambda, AWS Lake Formation, and Amazon SageMaker are built on top of DynamoDB.
In this post, we will look at the evolution of DynamoDB, its operational requirements, and the techniques utilized by the engineers to turn those requirements into reality.
History of DynamoDB
In the early years, Amazon realized that letting applications access traditional enterprise databases was an invitation to multiple scalability challenges such as managing connections, dealing with concurrent workloads, and handling schema updates.
Also, high availability was a critical property for always-online systems. Any downtime negatively impacted the company’s revenue.
There was a pressing need for a highly scalable, available, and durable key-value database for fast-changing data such as a shopping cart.
Dynamo was a response to this need.
However, there was one drawback of Dynamo. It was a single-tenant system and teams were responsible for managing their own Dynamo installations. In other words, every team that used Dynamo had to become experts on various parts of the database service, creating a barrier to adoption.
At about the same time, Amazon launched SimpleDB which reduced operational burden for the teams by providing a managed and elastic experience. The engineers within Amazon’s development team preferred using SimpleDB even though Dynamo might be more suitable for their use case.
But SimpleDB also had some limitations such as:
The tables had a small storage capacity of 10 GB.
Request throughput was low.
Unpredictable read and write latencies because all table attributes were indexed.
Also, the operational burden wasn’t eliminated. Developers still had to take care of dividing data between multiple tables to meet their application’s storage and throughput requirements.
Therefore, the engineers concluded that a better solution would be to combine the best parts of Dynamo (scalability and predictable high performance) with the best parts of SimpleDB (ease of administration, consistency, and a table-based data model).
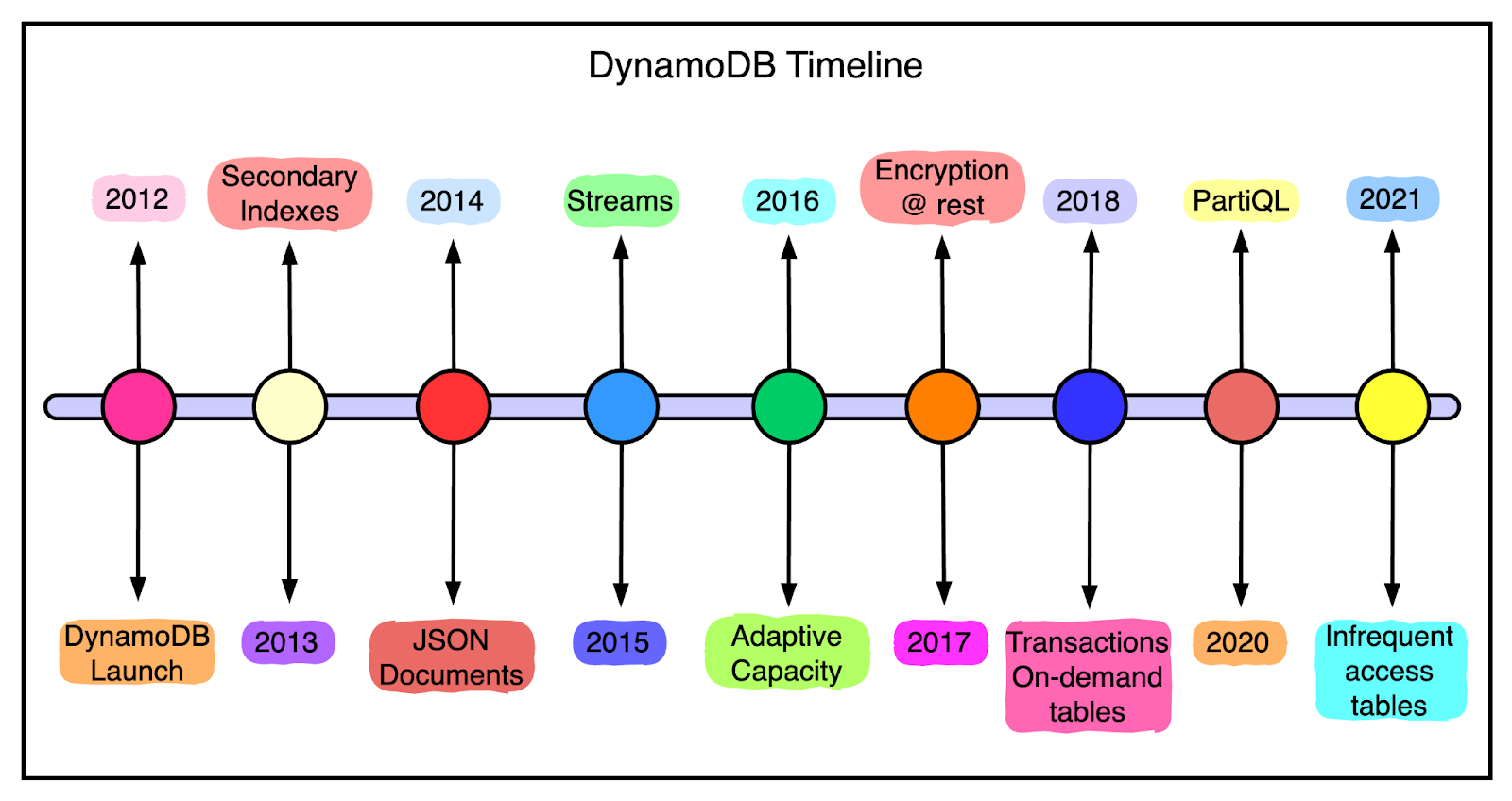
This led to the launch of DynamoDB as a public AWS service in 2012. It was a culmination of everything they had learned from building large-scale, non-relational databases for Amazon.
Over the years, DynamoDB has added several features based on customer demand.
The below timeline illustrates this constant progress.
Operational Requirements of DynamoDB
DynamoDB has evolved over the years, much of it in response to Amazon’s experiences building highly scalable and reliable cloud computing services. A key challenge has been adding features without impacting the key operational requirements.
The below diagram shows the six fundamental operational requirements fulfilled by DynamoDB.

Let’s look at each of them in a little more detail.
Fully Managed Cloud Service
A fundamental goal of DynamoDB is to free developers from the burden of running their database system. This includes things like patching software, configuring a distributed database cluster, and taking care of hardware needs.
The applications can just talk to the DynamoDB API for creating tables. They can read and write data without worrying about where those tables are physically stored or how they’re being managed.
DynamoDB handles everything for the developer right from resource provisioning to software upgrades, data encryption, taking backups, and even failure recovery.
Multi-Tenant Architecture
DynamoDB also aims to create cost savings for the customers.
One way to achieve this is using a multi-tenant architecture where data from different customers is stored on the same physical machines. This ensures better resource utilization and lets Amazon pass on the savings to the customers.
However, you still need to provide workload isolation in a multi-tenant system.
DynamoDB takes care of it via resource reservations, tight provisioning, and monitoring usage for every customer.
Boundless Scale for Tables
Unlike SimpleDB, there are no predefined limits for how much data can be stored in a DynamoDB table.
DynamoDB is designed to scale the resources dedicated to a table from several servers to many thousands as needed. A table can grow elastically to meet the demands of the customer without any manual intervention.
Predictable Performance
DynamoDB guarantees consistent performance even when the tables grow from a few megabytes to hundreds of terabytes.
For example, if your application is running in the same AWS region as its data, you can expect to see average latency in the low single-digit millisecond range.
DynamoDB handles any level of demand through horizontal scaling by automatically partitioning and repartitioning data as and when needed.
Highly Available
DynamoDB supports high availability by replicating data across multiple data centers or availability zones.
Customers can also create global tables that are geo-replicated across selected regions and provide low latency all across the globe. DynamoDB offers an availability SLA of 99.99% for regular tables and 99.999% for global tables.
Flexible Use Cases
Lastly, DynamoDB has a strong focus on flexibility and doesn’t force developers to follow a particular data model.
There’s no fixed schema and each data item can contain any number of attributes. Tables use a key-value or document data model where developers can opt for strong or eventual consistency while reading items from the table.
Latest articles
If you’re not a paid subscriber, here’s what you missed this month.

To receive all the full articles and support ByteByteGo, consider subscribing:
Architecture of DynamoDB
Now that we’ve looked at the operational requirements of DynamoDB, time to learn more about the architecture that helps fulfill these requirements.
To simplify the understanding, we will look at specific parts of the overall architecture one by one.
DynamoDB Tables
A DynamoDB table is a collection of items where each item is a collection of attributes.

Each item is uniquely identified by a primary key and the schema of this key is specified at the time of table creation. The primary key’s schema contains a partition key or it can be a composite key (consisting of a partition and sort key).
The partition key is important as it helps determine where the item will be physically stored. We will look at how that works out in a later section.
DynamoDB also supports secondary indexes to query data in a table using an alternate key. A particular table can have one or more secondary indexes.
Interface
DynamoDB provides a simple interface to store or retrieve items from a table.
The below table shows the primary operations that can be used by clients to read and write items in a DynamoDB table.

Also, DynamoDB supports ACID transactions that can update multiple items while ensuring atomicity, consistency, isolation, and durability. The key point to note is that this is managed without compromising on the other operational guarantees related to scaling and availability.
Partitioning and Replication
A DynamoDB table is divided into multiple partitions. This provides two benefits:
Handling more throughput as requests increase
Store more data as the table grows
Each partition of the table hosts a part of the table’s key range. For example, if there are 100 keys and 5 partitions, each partition can hold 20 keys.
But what about the availability guarantees of these partitions?
Each partition has multiple replicas distributed across availability zones. Together, these replicas form a replication group and improve the partition’s availability and durability.
A replication group consists of storage replicas that contain both the write-ahead logs and the B-tree that stores the key value data. Also, a group can contain replicas that only store write-ahead log entries and not the key-value data. These replicas are known as log replicas. We will learn more about their usage in a later section.

But whenever you replicate data across multiple nodes, guaranteeing a consensus becomes a big issue. What if each partition has a different value for a particular key?
The replication group uses Multi-Paxos for consensus and leader election. The leader is a key player within the replication group:
The leader serves all write requests. On receiving a write request, the leader of the group generates a write-ahead log record and sends it to the other replicas. A write is acknowledged to the application once a quorum of replicas stores the log record to their local write-ahead logs.
The leader also serves strongly consistent read requests. On the other hand, any other replica can serve eventually consistent reads.
But what happens if the leader goes down?
The leader of a replication group maintains its leadership using a lease mechanism. If the leader of the group fails and this failure is detected by any of the other replicas, the replica can propose a new round of the election to elect itself as the new leader.
DynamoDB Request Flow
DynamoDB consists of tens of microservices. However, there are a few core services that carry out the most critical functionality within the request flow.
The below diagram shows the request flow on a high level.

Let’s understand how it works in a step-by-step manner.
Requests arrive at the request router service. This service is responsible for routing each request to the appropriate storage node. However, it needs to call other services to make the routing decision.
The request router first checks whether the request is valid by calling the authentication service. The authentication service is hooked to the AWS IAM and helps determine whether the operation being performed on a given table is authorized.
Next, the request router fetches the routing information from the metadata service. The metadata service stores routing information about the tables, indexes, and replication groups for keys of a given table or index.
The request router also checks the global admission control to make sure that the request doesn’t exceed the resource limit for the table.
Lastly, if everything checks out, the request router calls the storage service to store the data on a fleet of storage nodes. Each storage node hosts many replicas belonging to different partitions.
Hot Partitions and Throughput Dilution
As you may have noticed, partitioning is a key selling point for DynamoDB. It provides a way to dynamically scale both the capacity and performance of tables as the demand changes.
In the initial release, DynamoDB allowed customers to explicitly specify the throughput requirements for a table in terms of read capacity units (RCUs) and write capacity units (WCUs). As the demand from a table changed (based on size and load), it could be split into partitions.
For example, let’s say a partition has a maximum throughput of 1000 WCUs. When a table is created with 3200 WCUs, DynamoDB creates 4 partitions with each partition allocated 800 WCUs. If the table capacity was increased to 6000 WCUs, then partitions will be split to create 8 child partitions with 750 WCUs per partition.
All of this was controlled by the admission control system to make sure that storage nodes don’t become overloaded. However, this approach assumed a uniform distribution of throughput across all partitions, resulting in some problems.
Two consequences because of this approach were hot partitions and throughput dilation.
Hot partitions arose in applications that had non-uniform access patterns. In other words, more traffic consistently went to a few items on the tables rather than an even distribution.
Throughput dilution was common for tables where partitions were split for size. Splitting a partition for size would result in the throughput of the partition being equally divided among the child partitions. This would decrease the per-partition throughput.
The static allocation of throughput at a partition level can cause reads and writes to be rejected if that partition receives a high number of requests. The partition’s throughput limit was exceeded even though the total provisioned throughput of the table was sufficient. Such a condition is known as throttling.
The below illustration shows this concept:

From a customer’s perspective, throttling creates periods of unavailability even though the service behaved as expected. To solve this, the customer will try to increase the table’s provisioned throughput but not be able to use all that capacity effectively. In other words, tables would be over-provisioned, resulting in a waste of resources.
To solve this, DynamoDB implemented a couple of solutions.
Bursting
While non-uniform access to partitions meant that some partitions exceeded their throughput limit, it also meant that other partitions were not using their allocated throughput. In other words, there was unused capacity being wasted.
Therefore, DynamoDB introduced the concept of bursting at the partition level.
The idea behind bursting was to let applications tap into this unused capacity at a partition level to absorb short-lived spikes for up to 300 seconds. The unused capacity is called the burst capacity.
It’s the same as storing money in the bank from your salary each month to buy a new car with all those savings.
The below diagram shows this concept.

The capacity management was controlled using multiple token buckets as follows:
Allocated token bucket for a partition
Burst token bucket for a partition
Node-level token bucket
Together, these buckets provided admission control:
If a read request arrived on a storage node and there were tokens in the partition’s allocated bucket, the request was admitted and the tokens were deducted from the partition bucket and node-level bucket
Once a partition exhausted all provisioned tokens, requests were allowed to burst only when tokens were available both in the burst token and the node-level token bucket
Global Admission Control
Bursting took care of short-lived spikes. However, long-lived spikes were still a problem in cases that had heavily skewed access patterns across partitions.
Initially, the DynamoDB developers implemented an adaptive capacity system that monitored the provisioned and consumed capacity of all tables. In case of throttling where the table level throughput wasn’t exceeded, it would automatically boost the allocated throughput.
However, this was a reactive approach and kicked in only after the customer had experienced a brief period of unavailability.
To solve this problem, they implemented Global Admission Control or GAC.
Here’s how GAC works:
It builds on the idea of token buckets by implementing a service that centrally tracks the total consumption of a table’s capacity using tokens.
Each request router instance maintains a local token bucket to make admission decisions.
The routers also communicate with the GAC to replenish tokens at regular intervals.
When a request arrives, the request router deducts tokens.
When it runs out of tokens, it asks for more tokens from the GAC.
The GAC instance uses the information provided by the client to estimate global token consumptions and provides the tokens available for the next time unit to the client’s share of overall tokens.
Managing Durability with DynamoDB
One of the central tenets of DynamoDB is that the data should never be lost after it has been committed. However, in practice, data loss can happen due to hardware failures or software bugs.
To guard against these scenarios, DynamoDB implements several mechanisms to ensure high durability.
Hardware Failures
In a large service like DynamoDB, hardware failures such as memory and disk failures are common. When a node goes down, all partitions hosted on that node are down to just two replicas.
The write-ahead logs in DynamoDB are critical for providing durability and crash recovery.
Write-ahead logs are stored in all three replicas of a partition. To achieve even higher levels of durability, the write-ahead logs are also periodically archived to S3 which is designed for 11 nines of durability.
Silent Data Errors and Continuous Verification
Some hardware failures due to storage media, CPU, or memory can cause incorrect data to be stored. Unfortunately, these issues are difficult to detect and they can happen anywhere.
DynamoDB extensively maintains checksums within every log entry, message, and log file to detect such data. Data integrity is validated for every data transfer between two nodes.
DynamoDB also continuously verifies data at rest using a scrub process. The goal of this scrub process is to detect errors such as bit rot.
The process verifies two things:
All three copies of the replicas in the replication group have the same data
Data of the live replicas matches with a copy of a replica built offline using the archived write-ahead log entries
The verification is done by computing the checksum of the live replica and matching that with a snapshot of one generated from the log entries archived in S3.
Backups and Restores
A customer’s data can also get corrupted due to a bug in their application code.
To deal with such scenarios, DynamoDB supports backup and restore functionalities. The great part is that backups and restores don’t affect the performance or availability of the table since they are built using the write-ahead logs that are archived in S3.
Backups are full copies of DynamoDB tables and are stored in an S3 bucket. They are consistent across multiple partitions up to the nearest second and can be restored to a new table anytime.
DynamoDB also supports point-in-time restore allowing customers to restore the contents of a table that existed at any time in the previous 35 days.
Managing Availability with DynamoDB
Availability is a major selling point of a managed database service like DynamoDB.
Customers expect almost 100% availability and even though it may not be theoretically possible, DynamoDB employs several techniques to ensure high availability.
DynamoDB tables are distributed and replicated across multiple Availability Zones (AZs) within a region. The platform team regularly tests resilience to node, rack, and AZ failures.
However, they also had to solve several challenges to bring DynamoDB to such a high level of availability
Write and Read Availability
The write availability of a partition depends on a healthy leader and a healthy write quorum that consists of two out of three replicas from different AZs.
In other words, a partition becomes unavailable for writes if the number of replicas needed to achieve the minimum quorum requirements is unavailable. If one of the replicas goes down, the leader adds a log replica in the group since it is the fastest way to ensure that the write quorum is always available.
As mentioned earlier, the leader replica serves consistent reads while other replicas can serve eventually consistent reads.
Failure Detection
The availability of a database is highly dependent on the ability to detect failures.
Failure detection must be quick to minimize downtime. Also, it should be able to detect false positives because triggering a needless failover can lead to bigger disruptions in the service.
For example, when all replicas lose connection to the leader, it’s clear that the leader is down and a new election is needed.
However, nodes can also experience gray failures due to communication issues between a leader and followers. For instance, a replica doesn’t receive heartbeats from a leader due to some network issue and triggers a new election. However, a newly elected leader has to wait for the expiry of the old leader’s lease resulting in unavailability.
To get around gray failures like this, a replica that wants to trigger a failover confirms with the other replicas whether they are also unable to communicate with the leader. If the other replicas respond with a healthy leader message, the follower drops its leader election attempt.
Metadata Availability
As we saw in the DynamoDB’s request flow diagram, metadata is a critical piece that makes the entire process work.
Metadata is the mapping between a table’s primary keys and the corresponding storage nodes. Without this information, the requests cannot be routed to the correct nodes.
In the initial days, DynamoDB stored the metadata in DynamoDB itself. When the request router received a request for a table it had not seen before, it downloaded the routing information for the entire table and cached it locally for subsequent requests. Since this information didn’t change frequently, the cache hit rate was almost 99.75 percent.
However, bringing up new router instances with empty caches would result in a huge traffic spike to the metadata service, impacting performance and stability.
To reduce the reliance on local caching of the metadata, DynamoDB built an in-memory distributed datastore called MemDS.
See the below diagram for the role of MemDS.

As you can see, MemDS stores all the metadata in memory and replicates it across the fleet of MemDB servers.
Also, a partition map cache (MemDS cache) was deployed on each request router instance to avoid a bi-modal cache setup. Whenever there is a cache hit, an asynchronous call is made to MemDS to refresh the cache, ensuring that there is a constant flow of traffic to the MemDS fleet rather than traffic spikes.
Conclusion
DynamoDB has been a pioneer in the field of NoSQL databases in the cloud-native world.
Thousands of companies all across the world rely on DynamoDB for their data storage needs due to its high availability and scalability properties.
However, behind the scenes, DynamoDB also packs a lot of learnings in terms of designing large-scale database systems.
Some of the key lessons the DynamoDB team had were as follows:
Adapting to the traffic patterns of user applications improves the overall customer experience
To improve stability, it’s better to design systems for predictability over absolute efficiency
For high durability, perform continuous verification of the data-at-rest
Maintaining high availability is a careful balance between operational discipline and new features
These lessons can act as great takeaways for us.
References:
Amazon DynamoDB: A Scalable, Predictably Performant and Fully Managed NoSQL Database Service
Amazon DynamoDB: Evolution of a Hyperscale Cloud Database Service
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.
Can you create more such content in depth ...like say OpenAI architecture..
Man this is Awesome !! Keep going !!