
A Guide to Context Engineering for LLMs

The workshop for teams drowning in observability tools (Sponsored)

Five vendors, rising costs, and you still can’t tell why something broke.
Sentry’s Lazar Nikolov sits down with Recurly’s Chris Barton to talk through what observability consolidation actually looks like in practice: how to evaluate your options, where AI fits in, and how to think about cost when you’re ready to simplify.
Giving an LLM more information can make it dumber. A 2025 research study by Chroma tested 18 of the most powerful language models available, including GPT-4.1, Claude, and Gemini, and found that every single one performed worse as the amount of input grew.
The degradation wasn’t minor, either. Some models held steady at 95% accuracy and then nosedived to 60% once the input crossed a certain length.
This finding busts one of the most common myths about working with LLMs that more context is always better. The reality is that LLMs have architectural blind spots that make what you put in front of them, and how you structure it, far more important than how much you include.
The discipline of getting this right is called context engineering.
In this article, we’ll look at how LLMs actually process the information you give them, what context engineering is, and the strategies that can help with it.
Key Terminologies
Before we go further, there are three terms that come up constantly when talking about LLMs. Getting clear on these first will make everything that follows much easier to reason about.
Tokens: They are the units LLMs think in. They aren’t full words, but rather chunks of text that average roughly three-quarters of a word each. The word “context” is one token, while the word “engineering” gets split into two. Every piece of text the model processes, from your question to its instructions to any documents you’ve included, is measured in tokens.
Context Window: It is the total number of tokens the model can see at once during a single interaction. Everything has to fit inside this window: the system instructions that define the model’s behavior, the conversation history, any external documents or data you’ve injected, and your actual question. Modern models advertise context windows ranging from 128,000 to over 2 million tokens. That sounds enormous, but as we’ll see, bigger isn’t straightforwardly better.
Attention: This is the mechanism the model uses to figure out which tokens matter to which other tokens. Before generating each new token of its response, the model compares it against every other token currently in the context window. This gives LLMs their ability to connect ideas across long stretches of text, but it’s also the source of their most important limitations.
How LLMs Process Context
When we send text to an LLM, it doesn’t read from top to bottom the way a human would. The attention mechanism compares every token against every other token to compute relationships, which means the model can, in principle, connect an idea from the first sentence of the input to one in the last sentence. However, this power comes with two critical costs.
The first is computational. Doubling the number of tokens in the context window roughly quadruples the computation required. Longer contexts are disproportionally slower and more expensive.
The second cost is more consequential. Attention isn’t distributed evenly across the context window. Research has consistently shown that LLMs pay the most attention to tokens at the beginning and end of the input, with a significant drop-off in the middle. This is known as the “lost in the middle” problem, and research has found that accuracy can drop by over 30% when relevant information is placed in the middle of the input compared to the beginning or end.
See the diagram below that shows the attention curve:
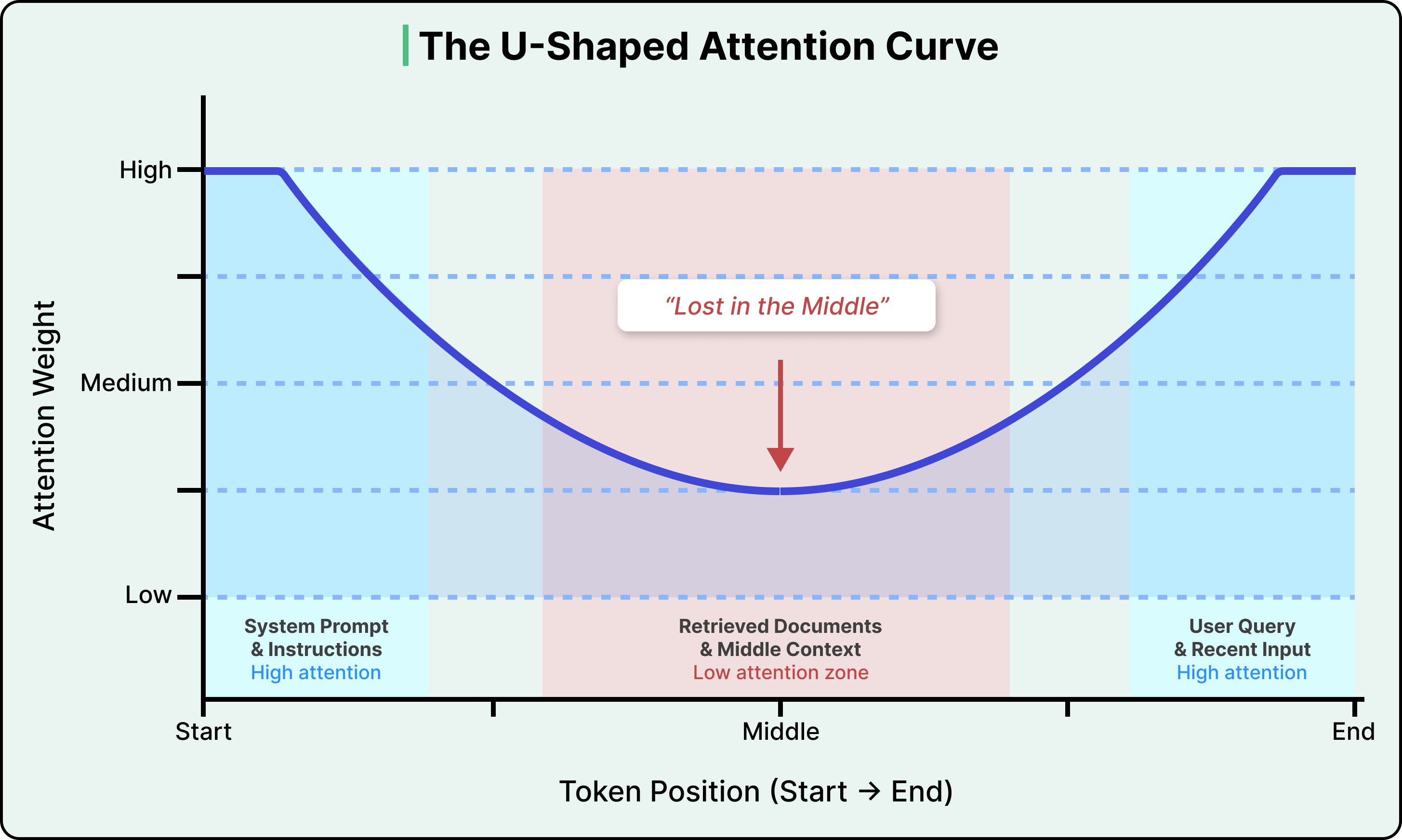
This isn’t a bug in any particular model, but rather a structural property of how transformers (the neural network architecture that powers virtually all modern LLMs) encode the position of tokens.
The positional encoding method used in most modern LLMs (called Rotary Position Embedding, or RoPE) introduces a decay effect that makes tokens far from both the start and end of the sequence land in a low-attention zone. Newer models have reduced the severity, but no production model has fully eliminated it.
The practical implication is that the position of information in the input matters as much as the information itself. If we paste a long document into an LLM, the model is most likely to miss information buried in the middle pages.
Why More Context Can Hurt
The uneven attention distribution is one problem, but there’s a broader pattern that compounds it, known as context rot.
Context rot is the degradation of LLM performance as input length increases, even on simple tasks. The Chroma research team’s 2025 study tested 18 frontier models and found that this degradation isn’t gradual. Models can maintain near-perfect accuracy up to a certain context length, and then performance drops off a cliff unpredictably, varying by model and by task in ways that make it impossible to reliably predict when you’ll hit a breaking point.
Why does this happen?
Every token you add to the context window draws from a finite attention budget. Irrelevant information buries important information in low-attention zones, and content that sounds related but isn’t actually useful confuses the model’s ability to identify what’s relevant. The model doesn’t get smarter with more input, but kind of gets distracted.
On top of this, LLMs are stateless. They have zero memory between calls, and each interaction starts completely fresh. When there is a multi-turn conversation with an LLM like ChatGPT, and it seems to “remember” what we said earlier, that’s because the system is re-injecting the conversation history into the context window each time. The model itself remembers nothing, which means someone, or some system, has to decide for every single call what information to include, what to leave out, and how to structure it.
There’s also a meaningful gap between marketing and reality. Models advertise million-token context windows, and they pass simple benchmarks at those lengths. However, the effective context length, where the model actually uses information reliably, is often much smaller. Passing a “needle in a haystack” test (finding one planted sentence in a long document) is very different from reliably synthesizing information scattered across hundreds of pages
Defining Context Engineering
Context engineering is the practice of designing, assembling, and managing the entire information environment an LLM sees before it generates a response. It goes beyond writing a single good instruction to orchestrating everything that fills the context window, so the model has exactly what it needs for the task at hand and nothing more.
To understand what this involves, it helps to see what actually competes for space inside a context window. There are six types of context in a typical LLM call:
System instructions (the behavioral rules, persona, and guidelines the model follows)
User input (your actual question or command)
Conversation history (the short-term memory of the current session)
Retrieved knowledge (documents, database results, or API responses pulled in from external sources)
Tool descriptions (definitions of tools the model can call and how to use them)
Tool outputs (results returned from previous tool calls)
The user’s actual question is often a tiny fraction of the total token count.
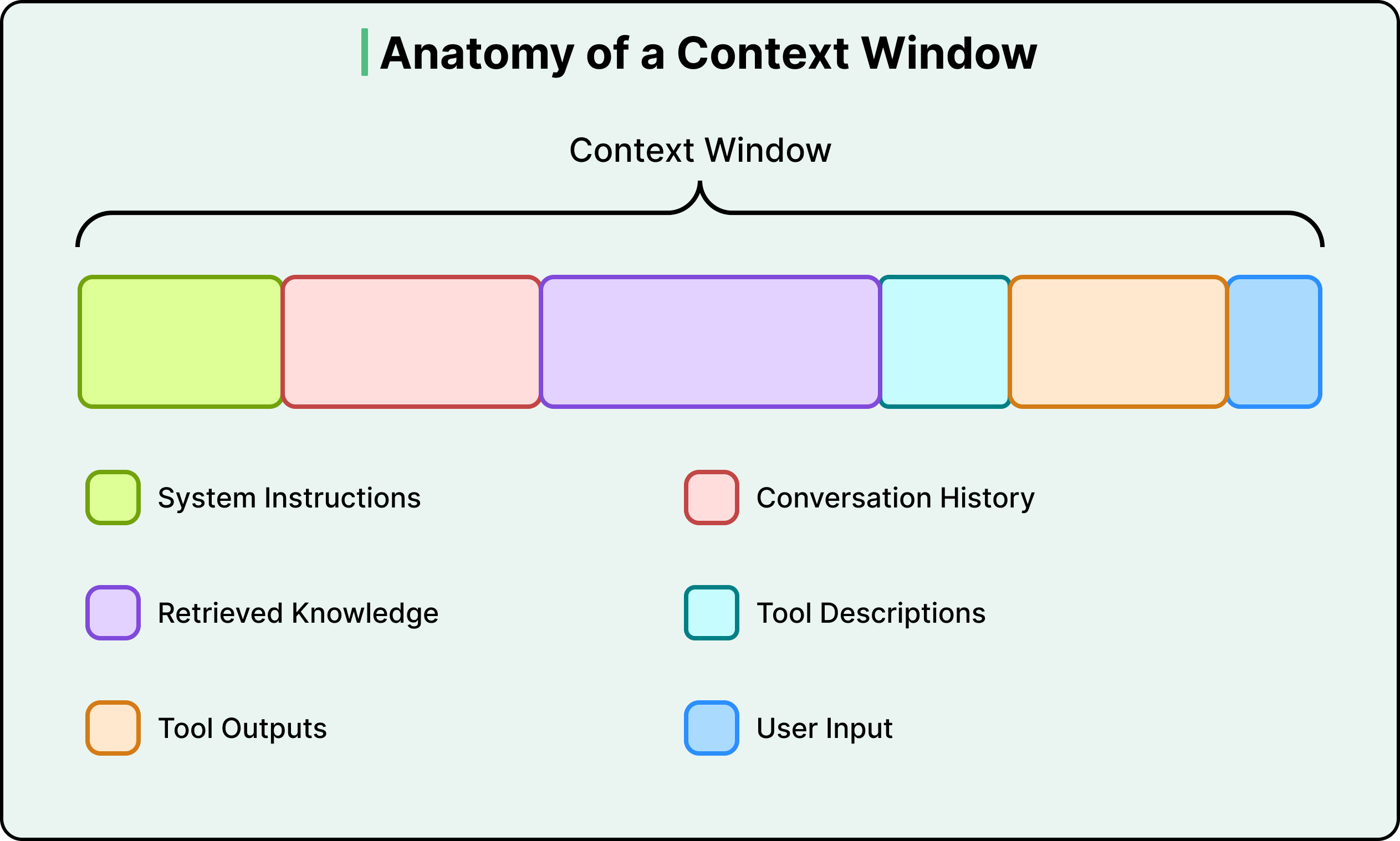
The rest is infrastructure, and that infrastructure is what context engineering designs.
This also clarifies how context engineering differs from prompt engineering. Prompt engineering asks, “How do I phrase my instruction to get the best result?” On the other hand, Context engineering asks, “What does the model need to see right now, and how do I assemble all of it dynamically?”
Prompt engineering is one component within context engineering, focused on the instruction layer, while context engineering encompasses the full information system around the model. As Andrej Karpathy put it in a widely referenced post, context engineering is the “delicate art and science of filling the context window with just the right information for the next step.”
Two people using the same model can get wildly different results. The model is the same, but the context is different, and context engineering is the factor that determines things.
Core Strategies
Developers have converged on four broad strategies for managing context, categorized as write, select, compress, and isolate. Each one is a direct response to a specific constraint we’ve already covered.
Write: Save Context Externally
The constraint it addresses is that the context window is finite, and statelessness means information is lost between calls.
Instead of trying to keep everything inside the context window, save important information to external storage and bring it back when needed. This takes two main forms.
The first is scratchpads, where an agent saves intermediate plans, notes, or reasoning steps to external storage during a long-running task. Anthropic’s multi-agent research system does exactly this. The lead researcher agent writes its plan to external memory at the start of a task, because if the context window exceeds 200,000 tokens, it gets truncated and the plan would be lost.
The second form is long-term memory, which involves persisting information across sessions. ChatGPT auto-generates user preferences from conversations, Cursor and Windsurf learn coding patterns and project context, and Claude Code uses CLAUDE.md files as persistent instruction memory. All of these systems treat external storage as the real memory layer, with the context window serving as a temporary workspace.
Select: Pull In Only What’s Relevant
The constraint it addresses is that more context isn’t better, and the model needs the right information rather than all available information.
The most important technique here is Retrieval-Augmented Generation, or RAG. Instead of stuffing all your knowledge into the context window, we store it externally in a searchable database. At query time, retrieve only the chunks most relevant to the current question and inject those into the context, giving the model targeted knowledge without the noise of everything else.
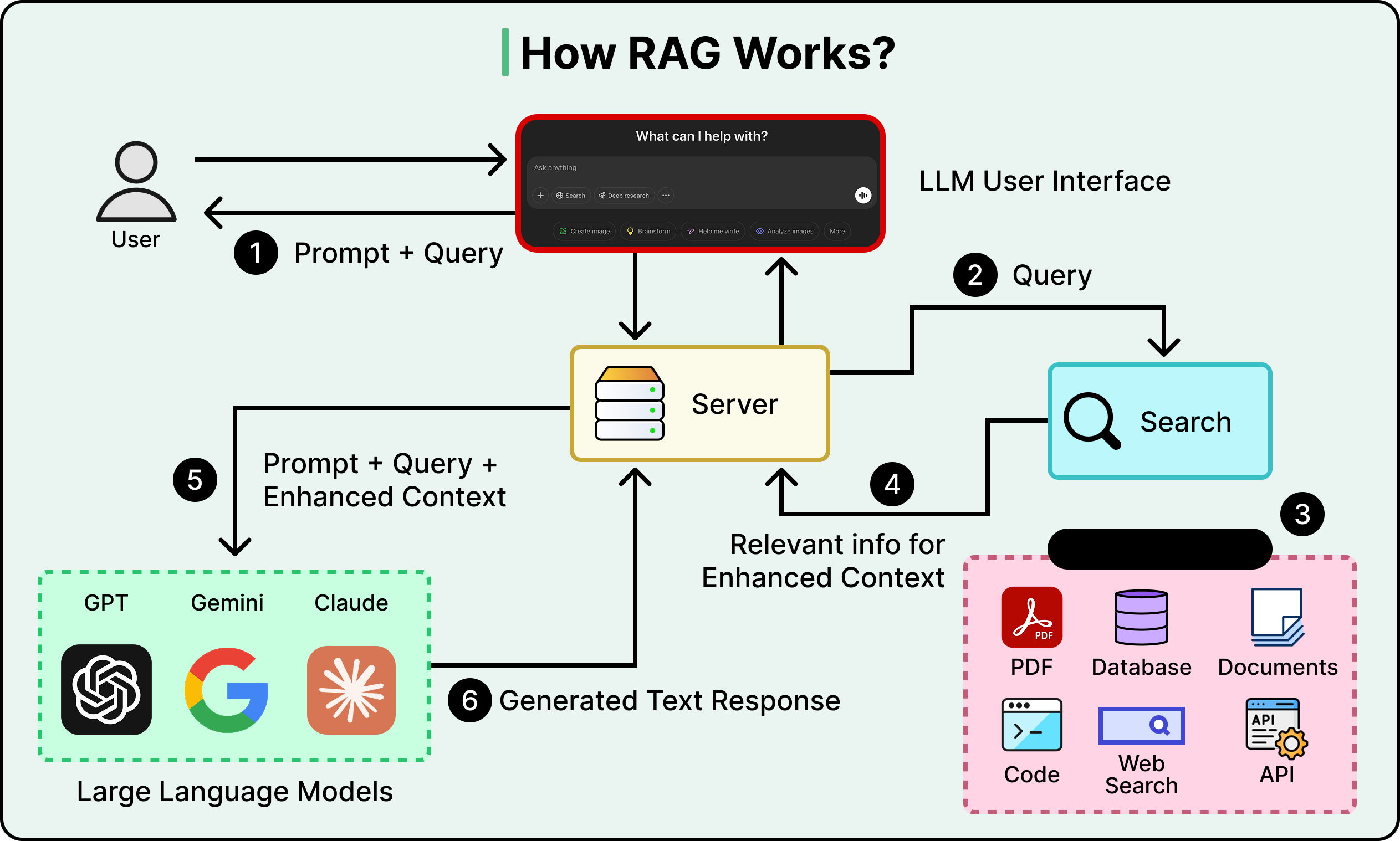
Selection also applies to tools. When an agent has dozens of available tools, listing every tool description in every prompt wastes tokens and confuses the model. A better approach is to retrieve only the tool descriptions relevant to the current task.
The critical tradeoff with selection is precision. If the retrieval pulls in documents that are almost relevant but not quite, they become distractors that add tokens and push important context into low-attention zones. The retrieval step itself has to be good, or the whole strategy backfires.
Compress: Keep Only What You Need
The constraint it addresses is the context rot and the escalating cost of attention across more tokens.
As agent workflows span dozens or hundreds of steps, the context window fills up with accumulated conversation history and tool outputs. Compression strategies reduce this bulk while trying to preserve the essential information.
Conversation summarization is the most common approach. Claude Code, for instance, triggers an “auto-compact” process when the context hits 95% capacity, summarizing the entire interaction history into a shorter form. Cognition, the company behind the Devin coding agent, trained a separate, dedicated model specifically for summarization at agent-to-agent boundaries. The fact that they built a separate model just for this step tells us how consequential bad compression can be, since a specific decision or detail that gets summarized away is gone permanently.
Simpler forms of compression include trimming (removing older messages from the history) and tool output compression (reducing verbose search results or code outputs to their essentials before they enter the context).
Isolate: Split Context Across Agents
The constraint it addresses is that of attention dilution and context poisoning when too many types of information compete in one window.
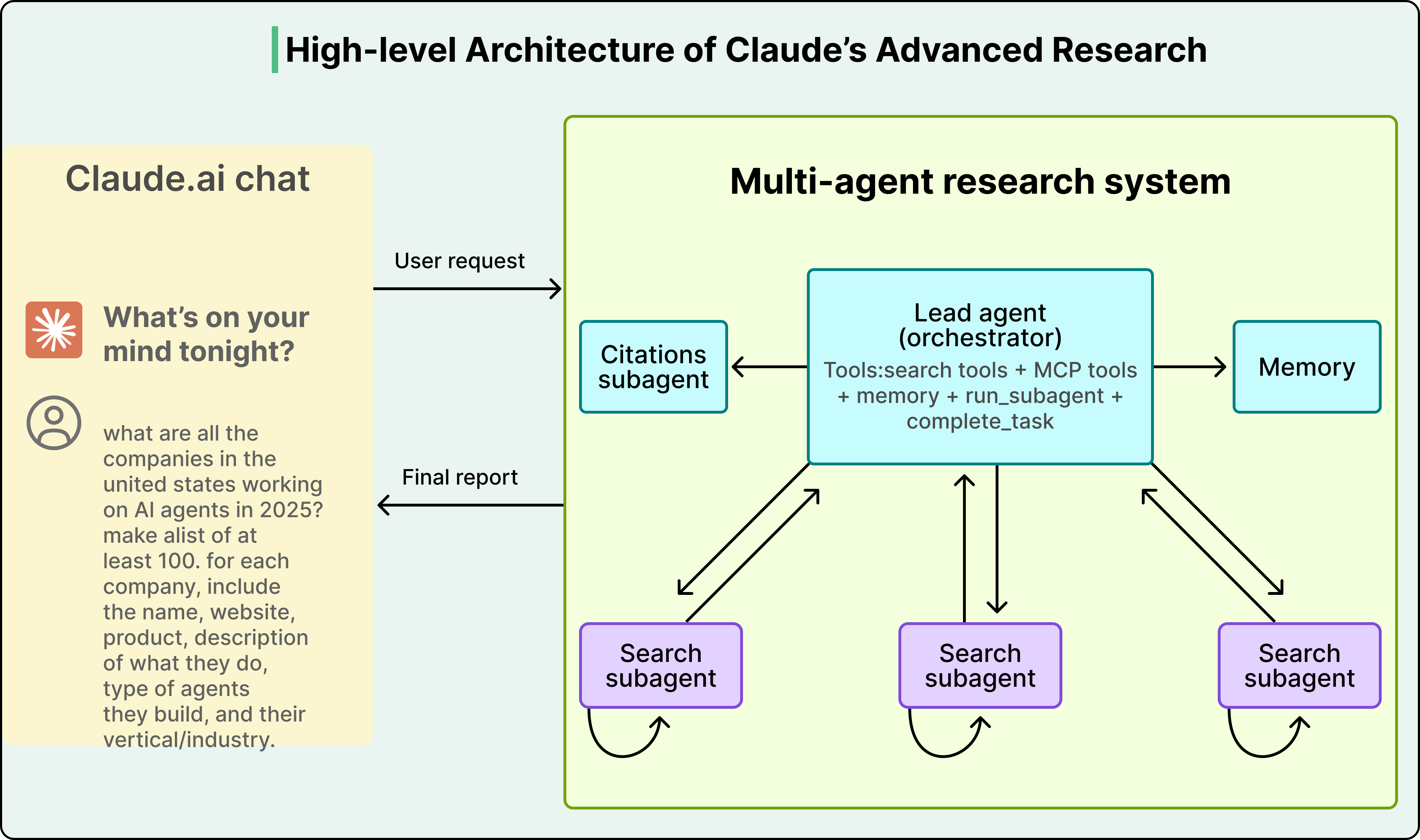
Instead of one agent trying to handle everything in a single bloated context window, this strategy splits the work across multiple specialized agents, each with its own clean, focused context. A “researcher” agent gets a context loaded with search tools and retrieved documents, while a “writer” agent gets a context loaded with style guides and formatting rules, so neither is distracted by the other’s information.
Anthropic demonstrated this with their multi-agent research system, where a lead Opus 4 agent delegated sub-tasks to Sonnet 4 sub-agents. The system achieved a 90.2% improvement over a single Opus 4 agent on research tasks, despite using the same underlying model family. The entire performance gain came from how context was managed, not from a more powerful model.
See the diagram below:
Tradeoffs
These strategies are powerful, but they involve trade-offs with no universal right answers:
Compression versus information loss: Every time you summarize, you risk losing a detail that turns out to matter later. The more aggressively you compress, the more you save on tokens, but the higher the chance of permanently destroying something important.
Single agent versus multi-agent: Anthropic’s multi-agent results are impressive, but others, notably Cognition, have argued that a single agent with good compression delivers more stability and lower cost. Both sides are debating the same core question of how to manage context effectively, and the answer depends on task complexity, cost tolerance, and reliability requirements.
Retrieval precision versus noise: RAG adds knowledge, but imprecise retrieval adds distractors. If the documents you retrieve aren’t genuinely relevant, they consume tokens and push important content into low-attention positions, so the retrieval system itself has to be well-engineered, or RAG makes things worse.
Cost versus richness: Every token costs money and processing time. The disproportionate scaling of attention means longer contexts get expensive fast, and context engineering is partly an economics problem of figuring out where the return on additional tokens stops being worth the cost.
Conclusion
The core takeaway is that the model is only as good as the context it receives. Working with LLMs effectively requires thinking about the entire system around the model, not just the model itself.
As models get more powerful, context engineering becomes more important. When the model is capable enough, most failures stop being intelligence failures and start being context failures, where the model could have gotten it right but didn’t have what it needed or had too much of what it didn’t need.
The strategies are evolving, and best practices are being revised as new models ship. However, the underlying constraints of finite attention, positional bias, and statelessness are architectural.
References
“The quality of AI’s output tells you something about the quality of your input.
Think of it like a detective solving a case. One clue (the suspect was in town that day) leaves hundreds of possibilities open. Two clues (they were in town and had a motive) narrows it down. Five independent clues might point to exactly one person.” - Julie Zhuo
great read. awesome breakdown of the terminology as well. considering the audience here, i think it’s great we all align on the terms as we discuss.