
A Guide to Effective Prompt Engineering

Unblocked is the AI code review with judgment of your best engineer. (Sponsored)

Most AI code review tools analyze the diff. Sometimes the file, occasionally the repo.
Experienced engineers work differently. They remember that Slack thread that explains why this database pattern exists. They know David on the platform team has strong opinions about error handling. They’ve internalized dozens of unwritten conventions.
Unblocked is the only AI code review tool that uses deep insight of your codebase, docs, and discussions to give high-signal feedback based on how your system actually works – instead of flooding your PR with stylistic nitpicks.
“Unblocked has reversed my AI fatigue completely. The level of precision is wild.” - Senior developer, Clio
Prompt engineering is the process of crafting instructions that guide AI language models to generate desired outcomes. At first glance, it might seem straightforward. We simply tell the AI what we want, and it delivers. However, anyone who has worked with these models quickly discovers that writing effective prompts is more challenging than it appears.
The ease of getting started with prompt engineering can be misleading.
While anyone can write a prompt, not everyone can write one that consistently produces high-quality results. Think of it as the difference between being able to communicate and being able to communicate effectively. The fundamentals are accessible, but mastery requires practice, experimentation, and understanding how these models process information.
In this article, we will look at the core techniques and best practices for prompt engineering. We will explore different prompting approaches, from simple zero-shot instructions to advanced chain-of-thought reasoning.
What Makes a Good Prompt
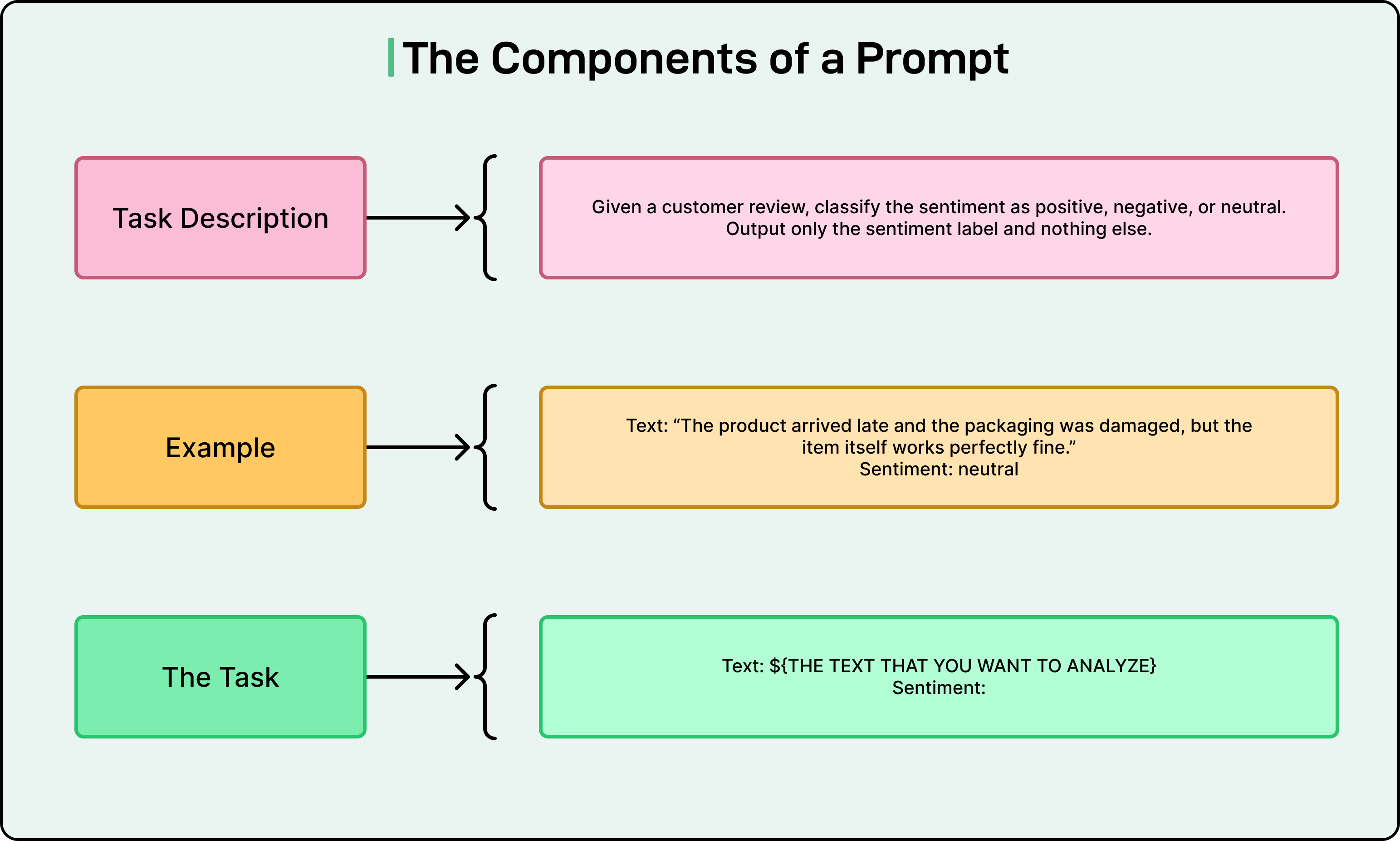
A prompt typically consists of several components:
The task description explains what we want the model to do, including any role or persona we want it to adopt.
The context provides necessary background information. Examples demonstrate the desired behavior or format.
Finally, the concrete task is the specific question to answer or action to perform.
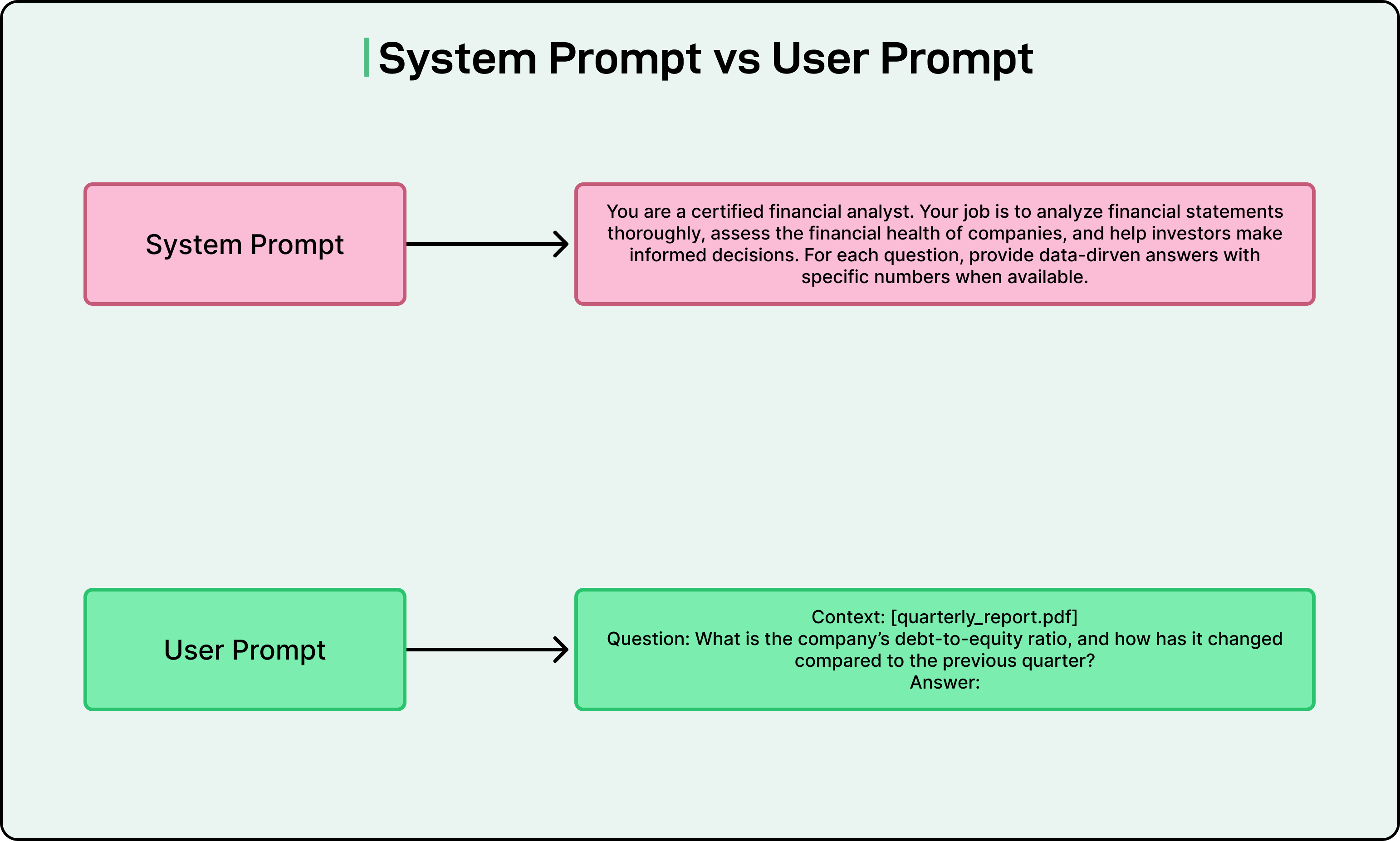
Most model APIs allow us to split prompts into system prompts and user prompts.
System prompts typically contain task descriptions and role-playing instructions that shape how the model behaves throughout the conversation.
On the other hand, user prompts contain the actual task or question. For instance, if we are building a chatbot that helps buyers understand property disclosures, the system prompt might instruct the model to act as an experienced real estate agent, while the user prompt contains the specific question about a property.
See the diagram below:
Clarity is the key factor to effective prompting. Just as clear communication helps humans understand what we need, specific and unambiguous instructions help AI models generate appropriate responses. We should explain exactly what we want, define any scoring systems or formats we expect, and eliminate assumptions about what the model might already know.
Context is equally important. Providing relevant information helps models perform better and reduces hallucinations. If we want the model to answer questions about a research paper, including that paper in the context will significantly improve response quality. Without sufficient context, the model must rely on its internal knowledge, which may be outdated or incorrect.
GitHub Copilot: Innovate Faster with AI, Wherever You Code (Sponsored)

Meet GitHub Copilot. Accelerate software innovation on any platform or code repository with GitHub Copilot, the agentic AI software development tool that meets you where you are.
With GitHub Copilot your team can:
Plan, build, and deploy with transformed AI-powered workflows.
Use agentic capabilities to tackle hard tasks: spec-driven development, docs generation, testing, and app modernization/migration.
Integrate GitHub Copilot anywhere: your teams, your toolchain, with flexible plans for agentic workflows.
How Models Process Prompts
In-context learning is the fundamental mechanism that makes prompt engineering work.
This term refers to a model’s ability to learn new behaviors from examples provided in the prompt itself, without requiring any updates to the model’s weights. When we show a model examples of how to perform a task, it can adapt its responses to match the pattern we have demonstrated.
Models are typically better at understanding instructions at the beginning and end of prompts compared to the middle. This phenomenon, sometimes called the “needle in a haystack” problem, means we should place the most important information at strategic positions in our prompts.
The number of examples needed depends on both the model’s capability and the task’s complexity. Stronger models generally require fewer examples to understand what we want. For simpler tasks, powerful models might not need any examples at all. For domain-specific applications or complex formatting requirements, providing several examples can make a significant difference.
Core Prompting Techniques
Let’s look at some key prompting techniques:
Technique 1: Zero-Shot Prompting
Zero-shot prompting means giving the model instructions without providing any examples. In this approach, we simply describe what we want, and the model attempts to fulfill the request based on its training.
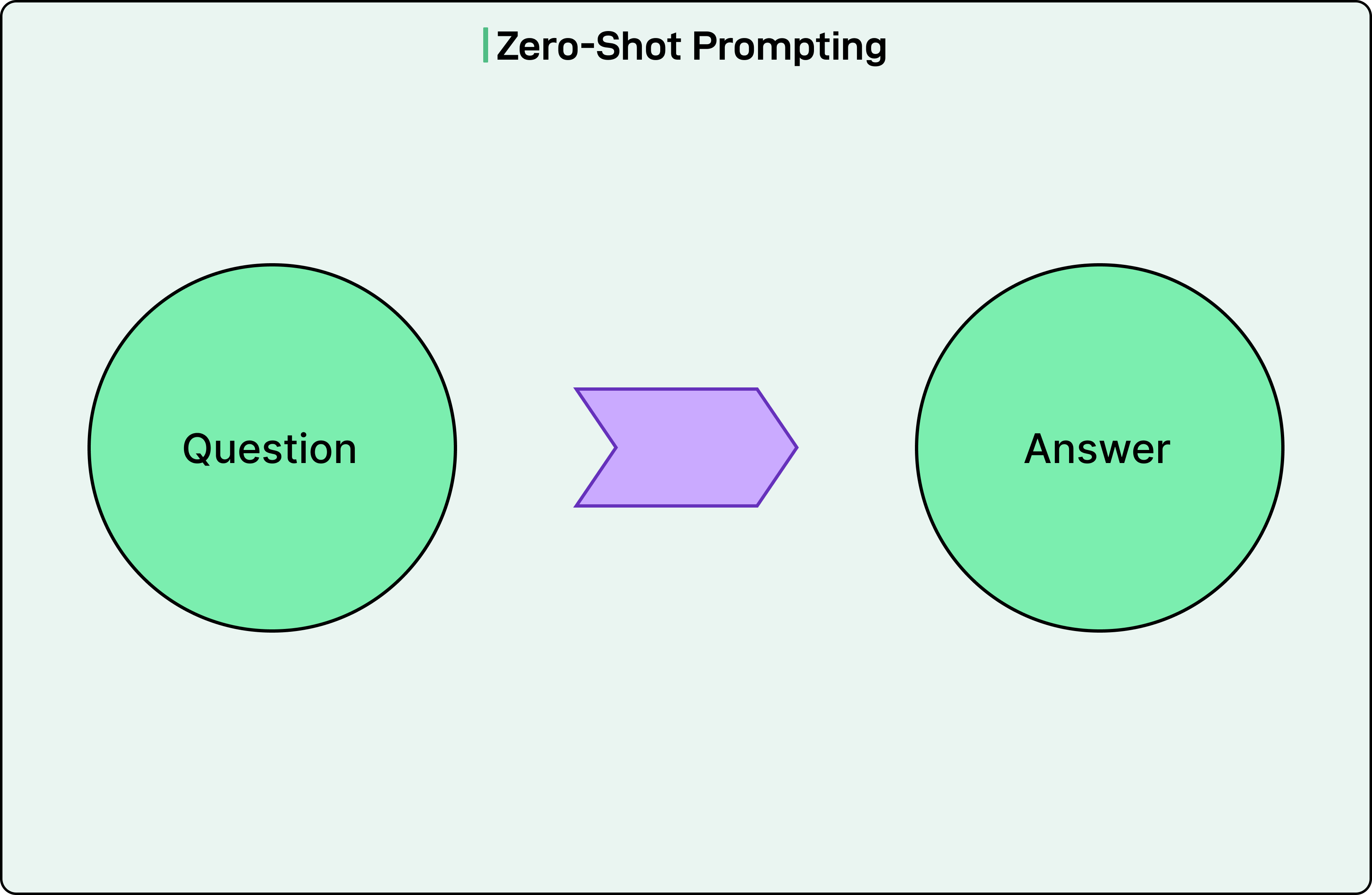
This technique works best for straightforward tasks where the desired output is clear from the instructions alone. For example, “Translate the following text to French” or “Summarize this article in three sentences” are both effective zero-shot prompts.
The main advantage of zero-shot prompting is efficiency. It uses fewer tokens, which reduces costs and latency. The prompts are also simpler to write and maintain. However, zero-shot prompting has limitations. When we need specific formatting or behavior that differs from the model’s default responses, zero-shot prompts may not be sufficient.
Best practices for zero-shot prompting include being as explicit as possible about what we want, specifying the output format clearly, and stating any constraints or requirements upfront. If the model’s initial response is not what we expected, we should revise the prompt to add more detail rather than immediately jumping to few-shot examples.
Technique 2: Few-Shot Prompting
Few-shot prompting involves providing examples that demonstrate how we want the model to respond. One-shot prompting uses a single example, while few-shot typically means two to five or more examples.
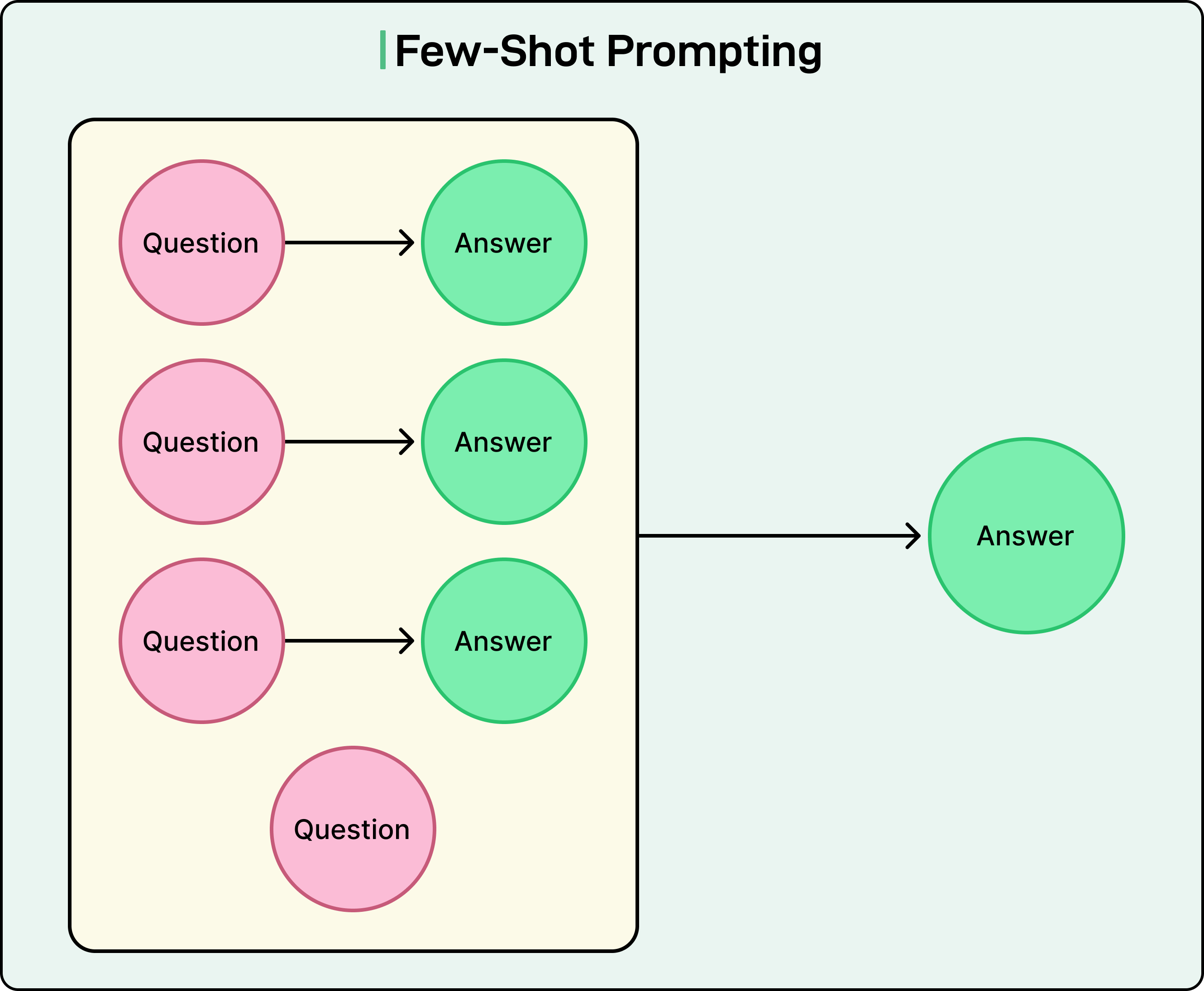
This technique is valuable when we need specific formatting or when the desired behavior might be ambiguous from instructions alone. For instance, if we are building a bot to talk to young children and want it to respond to questions about fictional characters in a particular way, showing an example helps the model understand the expected tone and approach.
Consider this comparison. Without an example, if a child asks, “Will Santa bring me presents on Christmas?”, a model might explain that Santa Claus is fictional. However, if we provide an example like “Q: Is the tooth fairy real? A: Of course! Put your tooth under your pillow tonight,” the model learns to maintain the magical perspective appropriate for young children.
The number of examples matters. More examples generally lead to better performance, but we are limited by context length and cost considerations. For most applications, three to five examples strike a good balance. We should experiment to find the optimal number for our specific use case.
When formatting examples, we can save tokens by choosing efficient structures. For instance, “pizza -> edible” uses fewer tokens than “Input: pizza, Output: edible” while conveying the same information. These small optimizations add up, especially when working with multiple examples.
Technique 3: Chain-of-Thought Prompting
Chain-of-thought prompting, often abbreviated as CoT, involves explicitly asking the model to think step by step before providing an answer. This technique encourages systematic problem-solving and has been shown to significantly improve performance on complex reasoning tasks.
The simplest implementation is adding phrases like “think step by step” or “explain your reasoning” to our prompts. The model then works through the problem methodically, showing its reasoning process before arriving at a conclusion.
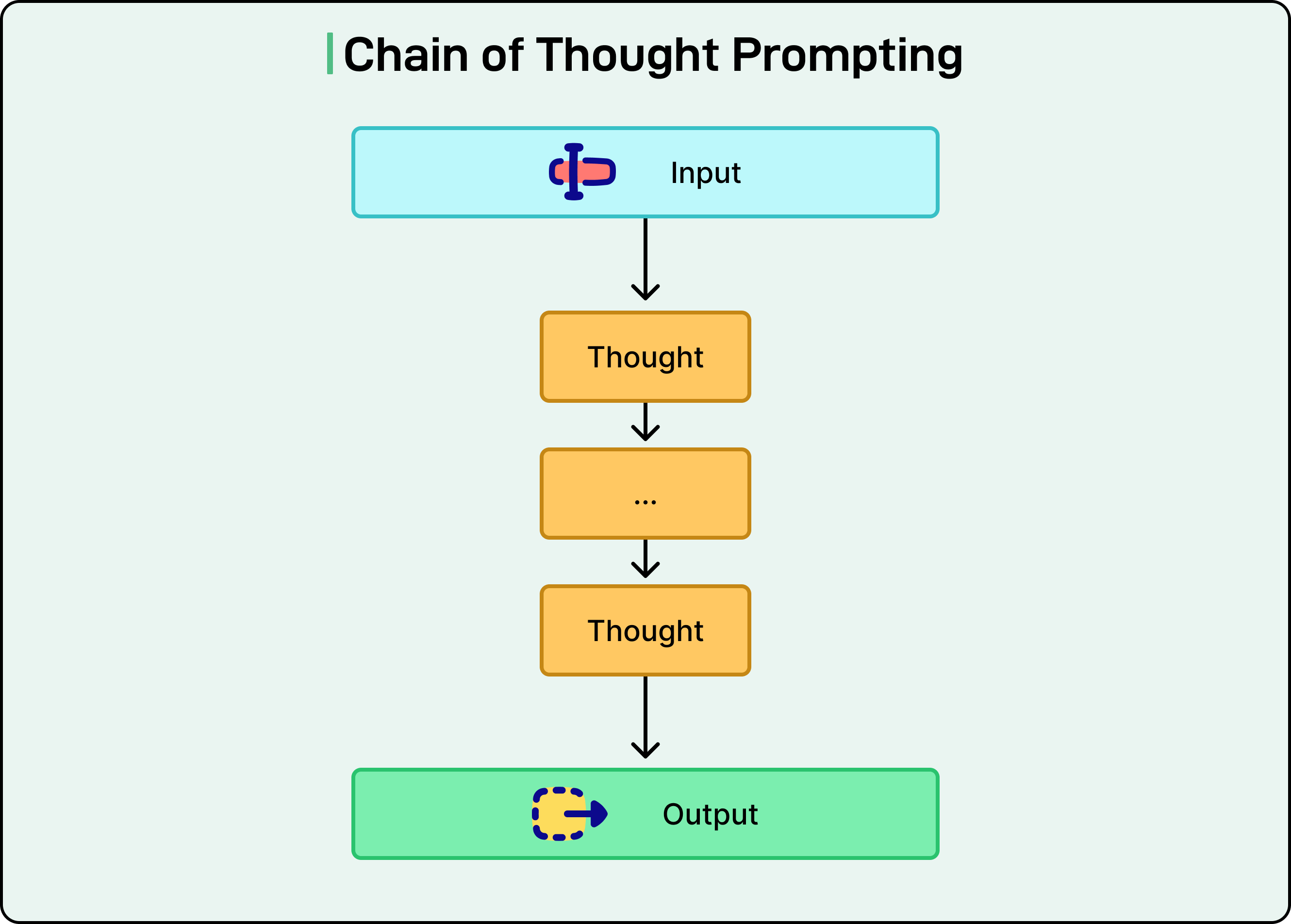
CoT often improves model performance across various benchmarks, particularly for mathematical problems, logic puzzles, and multi-step reasoning tasks. CoT also helps reduce hallucinations because the model must justify its answers with explicit reasoning steps.
We can implement CoT in several ways. Zero-shot CoT simply adds a reasoning instruction to our prompt. We can also specify the exact steps we want the model to follow, or provide examples that demonstrate the reasoning process. The variation depends on the specific application and how much control we need over the reasoning structure.
The trade-off with CoT is increased latency and cost. The model generates more tokens as it works through its reasoning, which takes more time and increases API costs. For complex tasks where accuracy is critical, this trade-off is usually worthwhile.
Technique 4: Role Prompting
Role prompting assigns a specific persona or area of expertise to the model. By telling the model to adopt a particular role, we influence the perspective and style of its responses.
For example, if we ask a model to score a simple essay like “Summer is the best season. The sun is warm. I go swimming. Ice cream tastes good in summer,” it might give a low score based on general writing standards. However, if we first instruct the model to adopt the persona of a first-grade teacher, it will evaluate the essay from that perspective and likely assign a higher, more appropriate score.
Role prompting is particularly effective for customer service applications, educational content, creative writing, and any scenario where the context or expertise level matters. The model can adjust its vocabulary, level of detail, and approach based on the assigned role.
When using role prompting, we should be specific about the role and any relevant characteristics. Rather than just saying “act as a teacher,” we might say “act as an encouraging first-grade teacher who focuses on effort and improvement.” The more specific we are, the better the model can embody that perspective.
Technique 5: Prompt Chaining and Decomposition
Prompt chaining involves breaking complex tasks into smaller, manageable subtasks, each with its own prompt. Instead of handling everything in one giant prompt, we create a series of simpler prompts and chain them together.
Consider a customer support chatbot. The process of responding to a customer request can be decomposed into two main steps:
Classify the intent of the request
Generate an appropriate response based on that intent
The first prompt focuses solely on determining whether the customer needs billing help, technical support, account management, or general information. Based on that classification, we then use a second, specialized prompt to generate the actual response.
This approach offers several benefits. Each prompt is simpler to write and maintain. We can monitor and debug each step independently. We can use different models for different steps, perhaps using a faster, cheaper model for intent classification and a more powerful model for response generation. We can also execute independent steps in parallel when possible.
The main drawback is increased perceived latency for end users. With multiple steps, users wait longer to see the final output. However, for complex applications, the improved reliability and maintainability often outweigh this concern.
Best Practices for Writing Effective Prompts
Some best practices for effective prompting are as follows:
Be Clear and Specific: Ambiguity is the enemy of effective prompting. We should eliminate all uncertainty about what we want the model to do. If we want the model to score essays, we need to specify the scoring scale. Should it use 1 to 5 or 1 to 10? Are fractional scores allowed? What should the model do if it is uncertain about a score?
Provide Sufficient Context: Context helps models generate accurate, relevant responses. If we want the model to answer questions about a document, including that document in the prompt is essential. Without it, the model can only rely on its training data, which may lead to outdated or incorrect information.
Specify Output Format: We should explicitly state how we want the model to respond. Do we want a concise answer or a detailed explanation? Should the output be formatted as JSON, a bulleted list, or a paragraph? Should the model include preambles, or should it get straight to the point?
Use Examples Strategically: Examples are powerful tools for reducing ambiguity, but they come with a cost in terms of tokens and context length. We should provide examples when the desired format or behavior is not obvious from instructions alone. For straightforward tasks, examples may not be necessary.
Iterate and Experiment: Prompt engineering is iterative. We rarely write the perfect prompt on the first try. We should start with a basic prompt, test it, observe the results, and refine based on what we learn.
Versioning Prompts: We should version our prompts so we can track changes over time. Using consistent evaluation data allows us to compare different prompt variations objectively. We should test prompts not just in isolation but in the context of the complete system to ensure that improvements in one area do not create problems elsewhere.
Common Pitfalls to Avoid
Some common pitfalls that should be avoided when writing prompts are as follows:
Being Too Vague: One of the most common mistakes is assuming the model understands our intent without explicit explanation. Vague prompts like “write something about climate change” leave too much open to interpretation. Do we want a scientific explanation, a persuasive essay, a news article, or a social media post? What length? What perspective? The model will make its own choices, which may not align with what we actually want.
Overcomplicating Prompts: While clarity and detail are important, we can go too far in the other direction. Overly complex prompts with excessive instructions, too many examples, or convoluted logic can confuse the model rather than help it. We should aim for the simplest prompt that achieves our goal. If a zero-shot prompt works well, there is no need to add examples. If three examples are sufficient, five may not improve results.
Ignoring Output Format: Failing to specify the output format can cause problems, especially when model outputs feed into other systems. If we need structured data but do not request it explicitly, the model might generate unstructured text that requires additional parsing or cleaning. This adds complexity and potential points of failure to our application.
Not Testing Sufficiently: A single successful output does not mean the prompt is reliable. We should test prompts with various inputs, including edge cases and unusual scenarios. What works for typical cases might fail when inputs are slightly different or unexpected. Building a small evaluation dataset and testing systematically helps identify weaknesses before they become problems in production.
Conclusion
Effective prompt engineering combines clear communication, strategic use of examples, and systematic experimentation.
The core techniques we have explored, including zero-shot prompting, few-shot prompting, chain-of-thought reasoning, role prompting, and prompt chaining, provide a solid foundation for working with AI language models.
The key principles remain consistent across different models and applications:
Be specific and clear in our instructions.
Provide sufficient context for the model to work with.
Specify the output format we need.
Use examples when they add value and iterate based on results.
The prompt chaining section is the one most teams underinvest in. In production, I've found that a three-step chain (classify intent → gather context → generate response) outperforms a single carefully-crafted mega-prompt every time, even though it costs more tokens.
One pattern missing from this guide that's been huge for me: structured output constraints. Instead of asking the model to "respond in JSON," defining a strict schema (with required fields, enums for valid values, etc.) and validating the output programmatically eliminates an entire class of parsing failures. Combined with chain-of-thought in a separate reasoning step before the structured output step, you get both accuracy and reliability.
I’ve noticed that when I craft prompts using XML, the output becomes absurdly consistent.
Also I recently listened to Lenny’s podcast. The guest is Sander Schulhoff. He created the very first prompt engineering guide on the internet, two months before ChatGPT’s release. In the episode, he mentioned that it’s better to put additional information at the beginning of a prompt, for two reasons.
First, that information can get cached.
Second, if you place all the extra context at the end and it becomes very long, the model may lose track of the original task and instead latch onto a question or instruction buried in the additional information.