
A Guide to LLM Evals

The Developer's Guide to MCP Auth (Sponsored)

Securely authorizing access to an MCP server is complex. You need PKCE, scopes, consent flows, and a way to revoke access when needed.
Learn from WorkOS how to implement OAuth 2.1 in a production-ready setup, with clear steps and examples.
Large Language Models (LLMs) have moved from research labs into production applications at a remarkable pace. Developers are using them for everything from customer support chatbots to code generation tools to content creation systems. However, this rapid adoption brings an important question: how do we know if our LLM is actually working well?
Unlike traditional software, where we can write unit tests that check for exact outputs, LLMs are probabilistic systems. Ask the same question twice, and the model might give different answers, both of which could be perfectly valid. This uncertainty makes evaluation challenging but absolutely necessary.
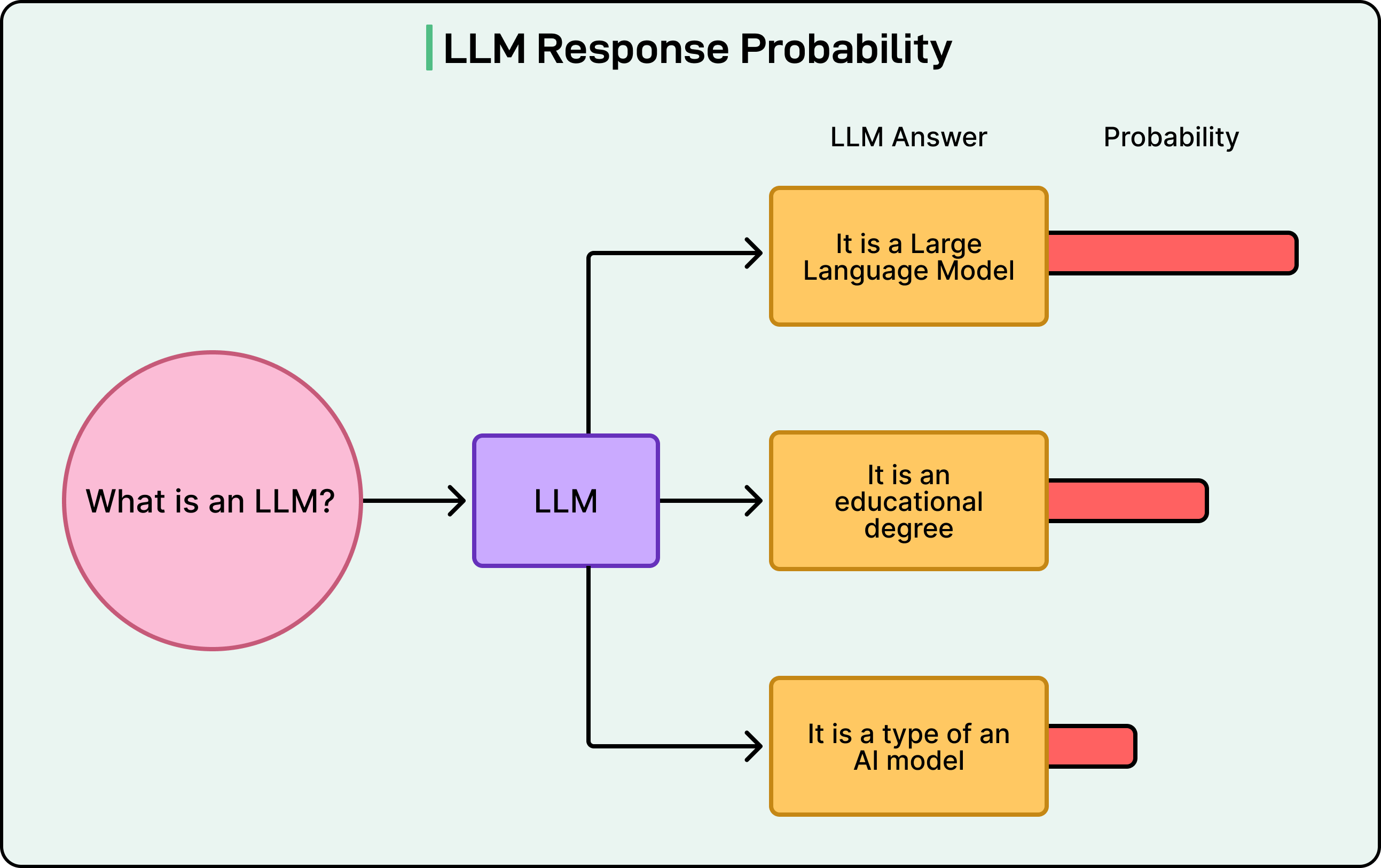
This is where “evals” come in. Short for evaluations, evals are the systematic methods we use to measure how well our LLM performs. Without proper evaluation, we’re essentially flying blind, unable to know whether our latest prompt change made things better or worse, whether our model is ready for production, or whether it’s handling edge cases correctly.
In this article, we’ll explore why LLM evaluation is challenging, the different types of evaluations available, key concepts to understand, and practical guidance on setting up an evaluation process.
The 2025 Data Streaming & AI Report (Sponsored)

AI is only as powerful as the data behind it — but most teams aren’t ready.
We surveyed 200 senior IT and data leaders to uncover how enterprises are really using streaming to power AI, and where the biggest gaps still exist.
Discover the biggest challenges in real-time data infrastructure, the top obstacles slowing down AI adoption, and what high-performing teams are doing differently in 2025.
Download the full report to see where your organisation stands.
Why LLM Evaluation Is Challenging
If we’re used to testing traditional software, LLM evaluation will feel different in fundamental ways. In conventional programming, we write a function that takes an input and produces a deterministic output. Testing is straightforward. Given input X, we expect output Y. If we get Y, the test passes. If not, it fails.
LLMs break this model in several ways.
First, there’s the subjective nature of language itself. What makes a response “good”? One response might be concise while another is comprehensive. Both could be appropriate depending on context. Unlike checking if a function returns the number 42, judging the quality of a paragraph requires nuance.
Second, most questions or prompts have multiple valid answers. For example, if we ask an LLM to summarize an article, there are countless ways to do it correctly. An eval that checks for exact text matching would fail even when the model produces excellent summaries.
Third, language is deeply context-dependent. The same words can mean different things in different situations. Sarcasm, humor, cultural references, and implied meaning all add layers of complexity that simple pattern matching can’t capture.
Finally, there’s a significant gap between impressive demos and consistent production performance. An LLM might handle our carefully crafted test cases beautifully but stumble on the messy, unpredictable inputs that real users provide.
Traditional software testing approaches like unit tests and integration tests remain valuable for the code surrounding our LLM, but they don’t fully translate to evaluating the model’s language understanding and generation capabilities. We need different tools and frameworks for this new challenge.
Types of LLM Evaluations
When evaluating LLMs, we have several approaches available, each with different strengths and tradeoffs. Let’s explore the main categories.
Automatic Evaluations
Automatic evaluations are programmatic assessments that can run without human involvement.
The simplest form is exact matching, where we check if the model’s output exactly matches an expected string. This works well for structured outputs like JSON or when there’s genuinely only one correct answer, but it’s too rigid for most natural language tasks.
Keyword matching is slightly more flexible. We check whether the output contains certain required keywords or phrases without demanding exact matching. This catches some variation while still being deterministic and easy to implement.
Semantic similarity measures how close the model’s output is to a reference answer in meaning, even if the words differ. These often use embedding models to compare the semantic content rather than surface-level text.
One increasingly popular approach is model-based evaluation, where we use another LLM as a judge. In this approach, we can ask a powerful model like GPT-4 or Claude to rate our target model’s outputs on criteria like helpfulness, accuracy, or relevance. This approach can capture nuance that simpler metrics miss, though it introduces its own complexities.
See the diagram below:
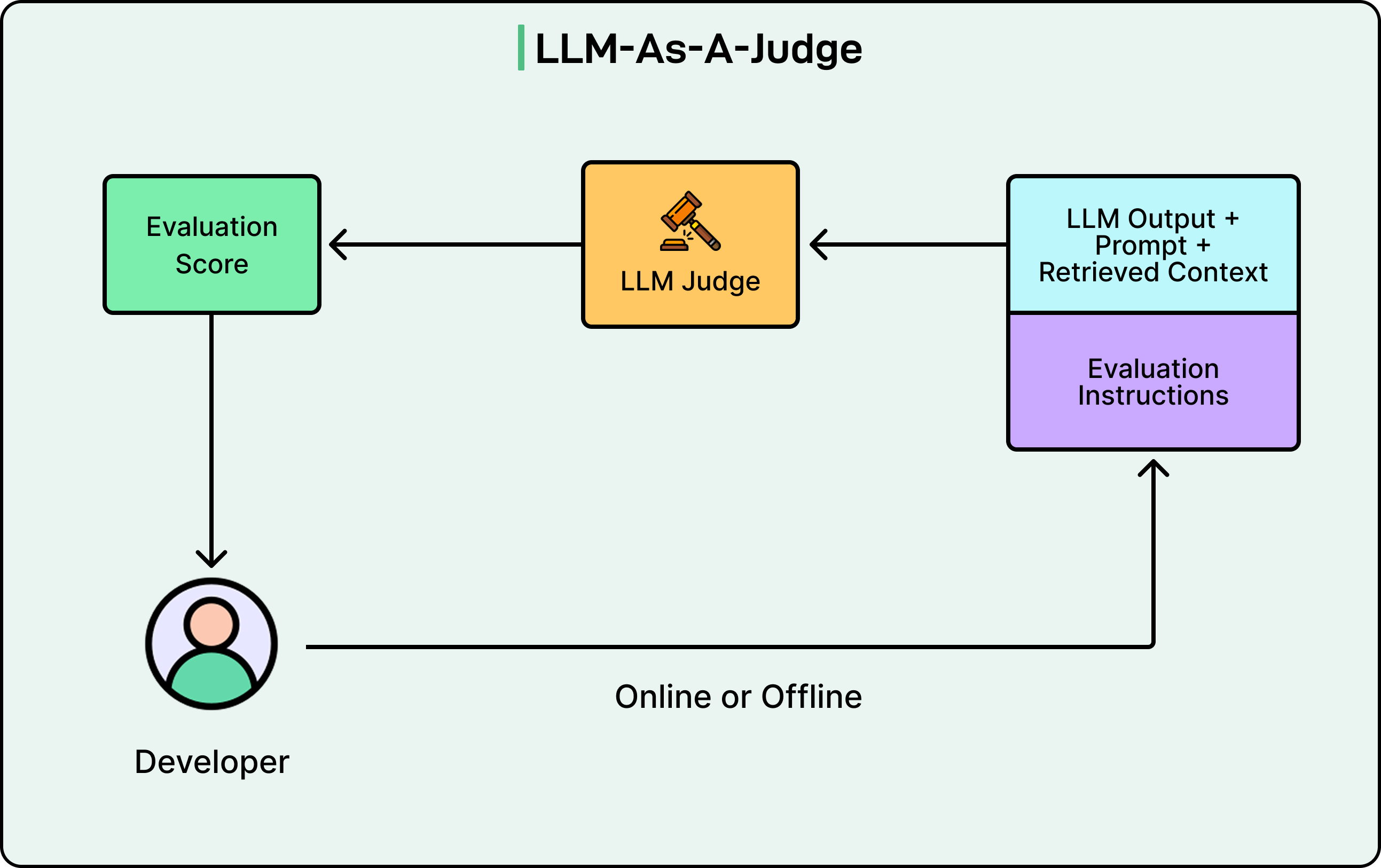
Automatic evaluations shine when we need to catch obvious failures, run regression tests to ensure changes don’t break existing functionality, or quickly iterate on prompts. However, they can miss subtle issues that only human judgment would catch.
Human Evaluations
Despite advances in automated testing, human evaluation remains the gold standard for assessing nuanced aspects of LLM performance. Humans can judge subjective qualities like tone, appropriateness, helpfulness, and whether a response truly addresses the underlying intent of a question.
Human evaluations take several forms. In preference ranking, evaluators compare multiple outputs and select which they prefer. Likert scales ask raters to score outputs on numerical scales across different dimensions. Task completion evaluations test whether the output accomplishes a specific goal.
The main tradeoff with human evaluation is cost and speed versus accuracy. Getting high-quality human ratings is expensive and time-consuming, but for many applications, it’s the only way to truly validate performance. For reference, human evaluation becomes essential when we’re working on subjective tasks, dealing with safety-critical applications, or need to validate our automatic evals.
Benchmark-Based Evaluations
The ML research community has developed standardized benchmark datasets for evaluating LLMs. These include datasets like MMLU (Massive Multitask Language Understanding) for general knowledge, HellaSwag for common sense reasoning, and HumanEval for code generation.
The advantage of benchmarks is comparability. We can see how our model stacks up against others and track progress using established baselines. They also provide ready-made test sets covering diverse scenarios.
However, benchmarks have limitations. They might not reflect our specific use case. A model that scores highly on academic benchmarks might still perform poorly on our customer support application. Additionally, as benchmarks become widely known, there’s a risk of models being optimized specifically for them rather than for general capability.
Key Concepts in LLM Evals
To build effective evaluations, we need to understand several core concepts:
Evaluation Metrics
Different tasks require different metrics. For classification tasks, we might use accuracy or F1 score. For text generation, metrics like BLEU and ROUGE measure overlap with reference texts, though they have known limitations. For code generation, we can check if the code executes correctly and produces expected outputs.
Beyond task-specific metrics, we often care about quality dimensions that cut across tasks.
Is the output relevant to the input?
Is it coherent and well-structured? Is it factually accurate?
Is it helpful to the user?
Does it avoid harmful content?
Evaluation Datasets
The quality of our evaluation depends heavily on the quality of our test dataset. We need test cases that are representative of real-world usage, diverse enough to cover different scenarios, and include edge cases where the model might fail.
A common pitfall is data contamination, where our test examples overlap with the model’s training data. This can make performance look better than it actually is on truly novel inputs. Using held-out data or creating new test cases helps avoid this issue.
Statistical Considerations
Since LLM outputs can vary between runs (especially with higher temperature settings), we need to think statistically about evaluation. A single test run might not be representative. Sample size matters where testing on ten examples gives us much less confidence than testing on a thousand.
We also need to account for variance in the model’s outputs. Running the same prompt multiple times and averaging results can give us a more stable picture of performance. Understanding and controlling for parameters like temperature, top-p, and random seeds helps make our evals reproducible.
Setting Up Your Eval Process
Here’s a practical approach to building an eval process.
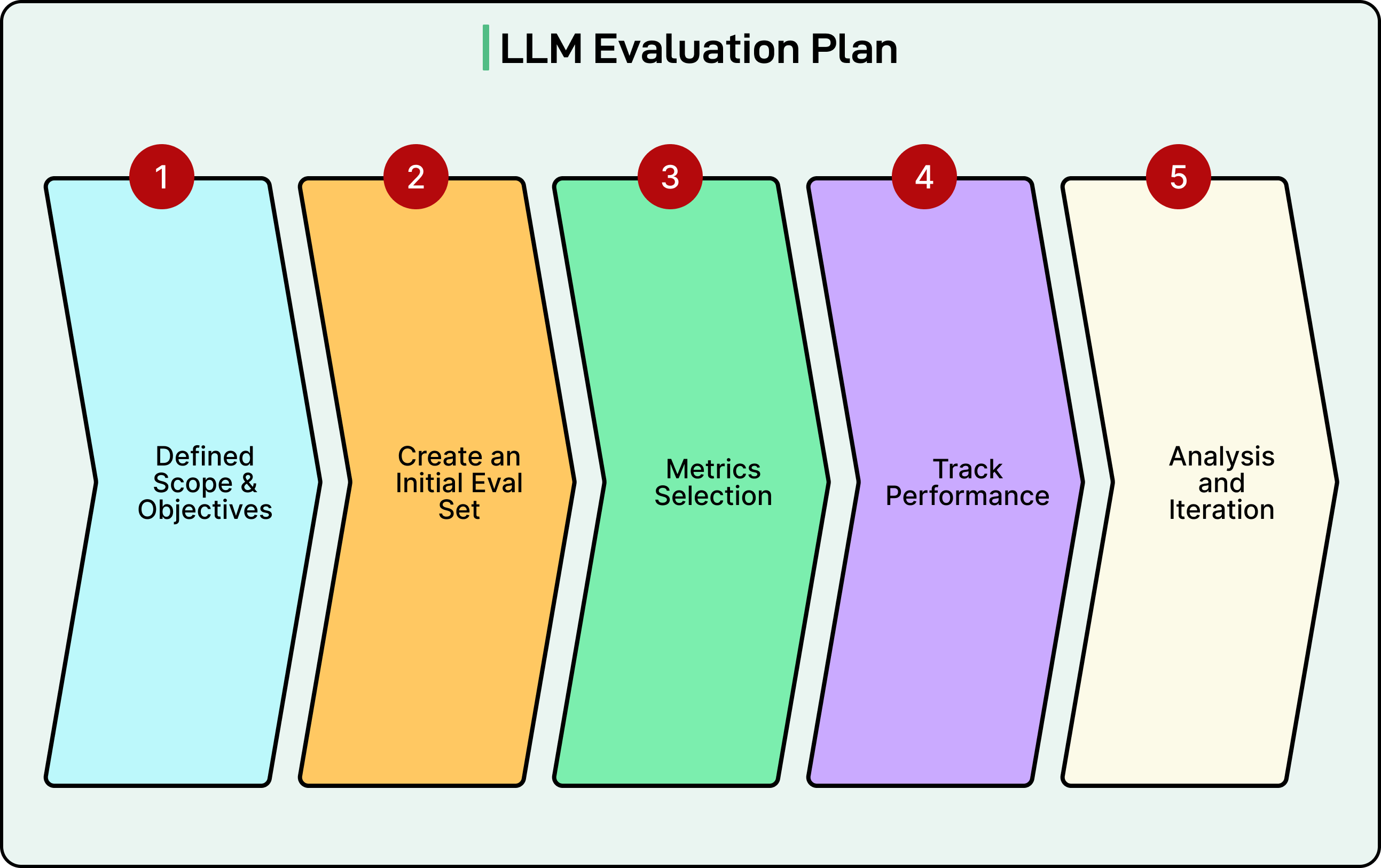
Define success for our use case: What does “good” mean for our specific application? If we’re building a customer support bot, maybe “good” means answering the question accurately, maintaining a friendly tone, and escalating to humans when appropriate.
Create an initial eval set: Start with 50-100 diverse examples covering common cases, edge cases, and known failure modes. We don’t need thousands of examples to start getting value.
Choose our evaluation approach: If we have limited resources, start with automatic evals. If quality is paramount and we have a budget, incorporate human evaluation. Often, a hybrid approach works best where we use automatic evals for broad coverage and quick iteration with human evals for final validation.
Set up an iteration cycle: Run evals, identify where the model fails, make improvements (better prompts, different models, fine-tuning, etc.), and re-evaluate. This cycle is how we progressively improve performance.
Track performance over time: Keep a record of eval scores across different versions. This helps us understand whether changes are helping and preventing regression.
Version everything: Track which model version, which prompt version, and which eval dataset version produced each result. This makes debugging and reproduction much easier.
The key is to start simple and iterate. Don’t wait for the perfect eval setup. A basic eval running regularly is infinitely more valuable than a sophisticated eval that never gets implemented.
Common Pitfalls and Best Practices
While building an eval practice, it’s good to watch out for these common mistakes:
Overfitting to the eval set is a real risk. If we repeatedly optimize against the same test cases, we might improve scores without improving real-world performance. Regularly refreshing our eval set with new examples helps prevent this.
We can also fall into the trap of gaming the metrics. Just because a model scores well on a particular metric doesn’t mean it’s actually better. Always combine quantitative metrics with a qualitative review of actual outputs.
Many teams neglect edge cases and adversarial examples. Real users will find ways to break the system that we never anticipated. Actively seeking out and testing difficult cases makes our evals more robust.
On the flip side, relying solely on vibes and anecdotes is problematic. Human intuition is valuable but can be misleading. Systematic evaluation gives us data to make informed decisions.
Perhaps the biggest pitfall is not evaluating at all. In the rush to ship features, evaluation often gets deprioritized. But shipping without evals means we have no idea if we’re making things better or worse.
The best practice is to maintain a diverse, evolving eval suite that grows alongside our product. As we discover new failure modes or expand to new use cases, they can be added to the eval set.
Conclusion
LLM evaluation is a continuous practice that should be woven into our development workflow. Just as we wouldn’t ship traditional software without tests, we shouldn’t deploy LLM applications without proper evaluation.
Good evals give us the confidence to iterate quickly and deploy safely. They help us understand what’s working and what isn’t while providing objective measures for comparing different approaches. They catch regressions before users do.
The good news is that we don’t need a sophisticated setup to start. Begin with a small set of test cases and basic metrics. Run evals regularly. Pay attention to failures. Gradually expand and refine our eval suite as we learn more about our application’s requirements.
The field of LLM evaluation is still evolving, with new tools, frameworks, and best practices emerging regularly. But the fundamental principle remains constant: we can’t improve what we don’t measure. By making evaluation a core part of our LLM development process, we transform what might otherwise be guesswork into engineering.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Thanks ByteByteGo team, another great technical LLM Eval guidance with super clear structure and nice flow!
Good primer. The trap is treating evals as a one-time scorecard. The probability of any answer shifts the moment your prompt, model, or data moves. Rerun them on every change or you are flying blind by week two.