A Guide to Retry Pattern in Distributed Systems

In a monolithic application, a function call is a local, in-memory process. Aside from a catastrophic hardware failure or a process crash, the execution of a function is essentially guaranteed. If the process is alive, the call succeeds.
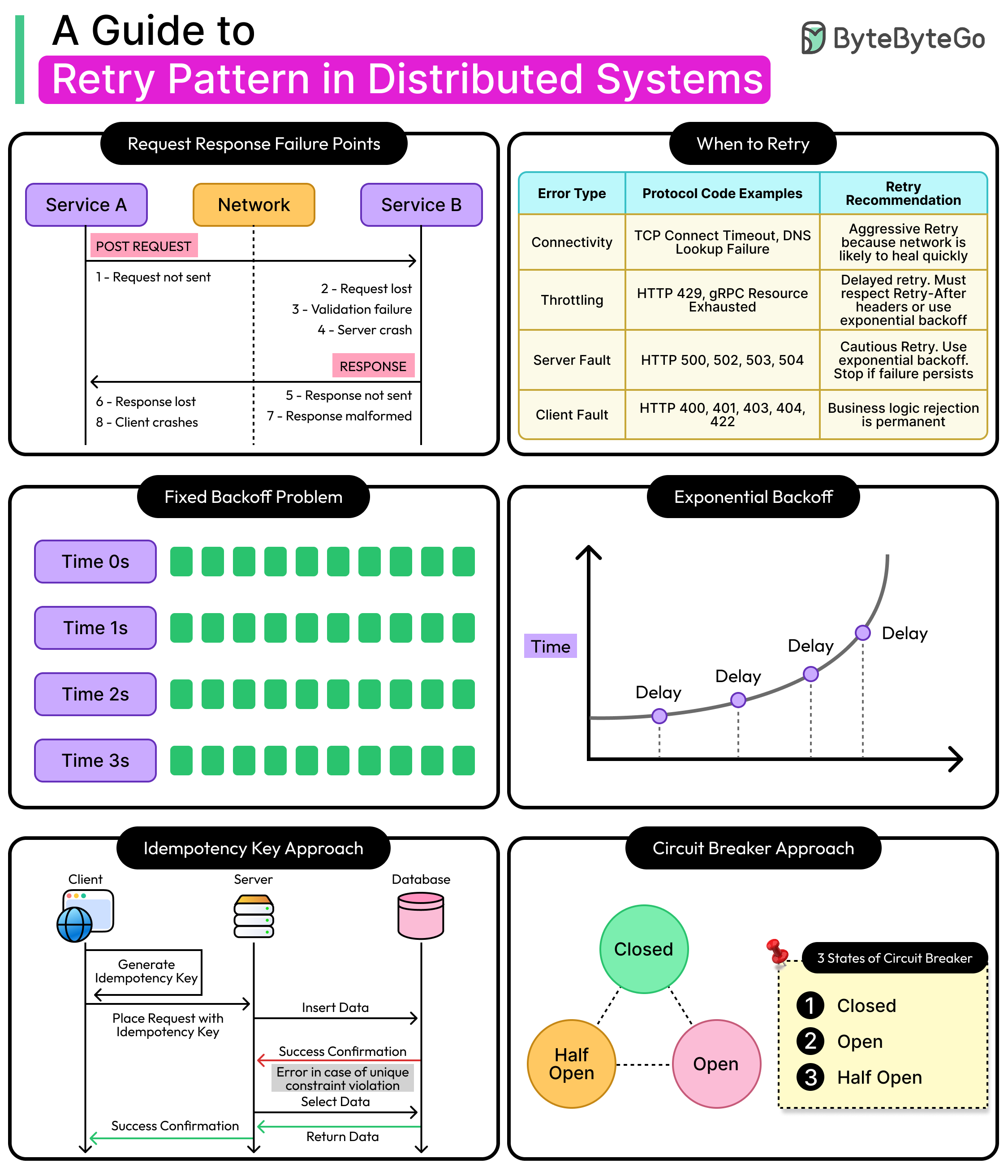
However, in distributed systems, this guarantee does not hold. Components communicate over physical networks that are inherently unreliable. This reality is captured in the “Fallacies of Distributed Computing,” specifically the first fallacy: “The network is reliable”. In truth, it is not. A request sent from Service A to Service B may fail not because Service B is broken, but simply because the communication medium momentarily faltered.
This creates a need for defensive programming patterns, and one of the primary mechanisms we use is the Retry pattern. By automatically retrying a failed operation, a system can trade latency for availability, turning what would have been a failed user request into a successful one.
However, retries are both essential and dangerous in distributed systems. On the one hand, they transform unreliable networks into reliable ones. But on the other hand, indiscriminate retries can lead to latency amplification, resource exhaustion, and cascading failures that can take down entire platforms.
In this article, we will explore the retry pattern in depth, understand when and how to use it safely and effectively.