API redesign: shopping cart and Stripe payment

In this issue, we continue with our hands-on exploration of the two remaining API design examples. We’ll explore how to build a shopping cart API and study the Stripe payment API redesign.
Example 2 - Shopping Cart
In this section, we design a simple shopping cart.
Step 1 - Analyze the requirements and design APIs
A shopping cart needs to support the following core features:
Creating a cart
Viewing a cart
Adding an item to a cart
Viewing items within a cart
We are defining our resources as cart and item. Below, we’ve outlined the corresponding APIs:

Note that we use mine as a special cart identifier because a user has only one shopping cart.
When we add an item to a cart, a Google-style API might specify the verb in the URL, like so:
POST /v1/carts/mine/items:addThere are some who aren’t fans of colons in the URLs. In our view, developers should follow their organization’s API specifications. When we all speak the same language, we’re less prone to errors.
Step 2 - Optimizations
Consider a shopping cart filled with many items. To enhance our query experience, we’ll introduce filtering, sorting, and pagination.
Filtering
Let’s think about querying all red items in our cart. Here’s what the API would look like:
GET /v1/carts/mine/items?filter=redNote that we need to be cautious about providing broad filtering capabilities. This could potentially impact performance adversely. As a better alternative, we should offer structured filtering which limits the options to certain parameters like color and weight.
For product search pages, structured filtering becomes even more essential. They require additional filters like price, category, location, and more.
Sorting
Imagine sorting items in the cart based on when they were added:
GET /v1/carts/mine/items?sort_by=timeSimilar to filtering, our sorting mechanism is also structured. We provide a set of predefined sorting fields for selection.
Pagination
When there are more items than a single page can accommodate, we use a technique called pagination. This lets users navigate through pages of items.
There are two popular methods for pagination. They are offset pagination and cursor-based pagination.
Offset pagination works by using a page number and the desired count of results per page as parameters. This gives users the ability to see the total pages and the exact page number. An example could look like this:
GET /v1/carts?page={page}&count={count}The server uses the page and count parameters to calculate the exact offset and limit to request from the database. Implementing this with a relational database is simple. For example, with page = 2 and count = 10, a database query might look like this:
SELECT * FROM carts
WHERE cart_id = 1234
ORDER BY item_id DESC
LIMIT 10 OFFSET 10;Offset pagination is simple to implement. It gives the user the ability to jump to a specific page in the dataset.
However, offset pagination does not work well for large datasets. Performance can degrade as it requires the database to scan the table up to "offset + limit" rows. As the offset advances further in the dataset, the database still needs to perform wasteful table scans and discard many rows.
Offset pagination also does not work well for datasets that are being written too frequently. A good example is messages in a busy chat group. High data velocity can lead to duplicates or skipped results.
On the other hand, cursor-based pagination uses a pointer to a specific item. It returns results after that pointer in subsequent requests. This method is based on a unique, sequential column in the table, and it offers advantages in scalability and stability over offset pagination. It doesn't require rescanning the dataset up to the offset for each request.
An example of cursor-based pagination could look like this. It uses maxPageSize and pageToken.
GET /v1/carts?maxPageSize={maxPageSize}&pageToken={pageToken}Response:
{
results: [...],
nextPageToken={ xxx }
}In the example, pageToken is the cursor, and maxPageSize defines the maximum results returned in a response.
Cursor-based pagination addresses the drawbacks of offset-based pagination. It scales well for a large dataset. The cursor points to a specific row on a primary column, and the database can use the index to jump to that specific location quickly, without resorting to a table scan. It also stabilizes the pagination window and it works well for fast-changing dataset. However, cursor-based pagination sacrifices the ability to jump to a specific page.
Step 3 - Security
Many shopping carts allow item additions without signing in. This is known as anonymous cart functionality. These public APIs become potential DDoS attack targets. We must guard against attackers adding or removing a large number of items from tens of thousands of PCs, leading to system resource exhaustion.
When designing APIs, it’s crucial to employ appropriate rate-limiting algorithms for DDoS attack prevention. This can be implemented at the firewall or API gateway level. For example, firewalls can reject recurrent requests from a single IP address, while API gateway could limit “add to or remove from shopping cart” requests to 100 per minute.
Example 3 - Stripe API Redesign
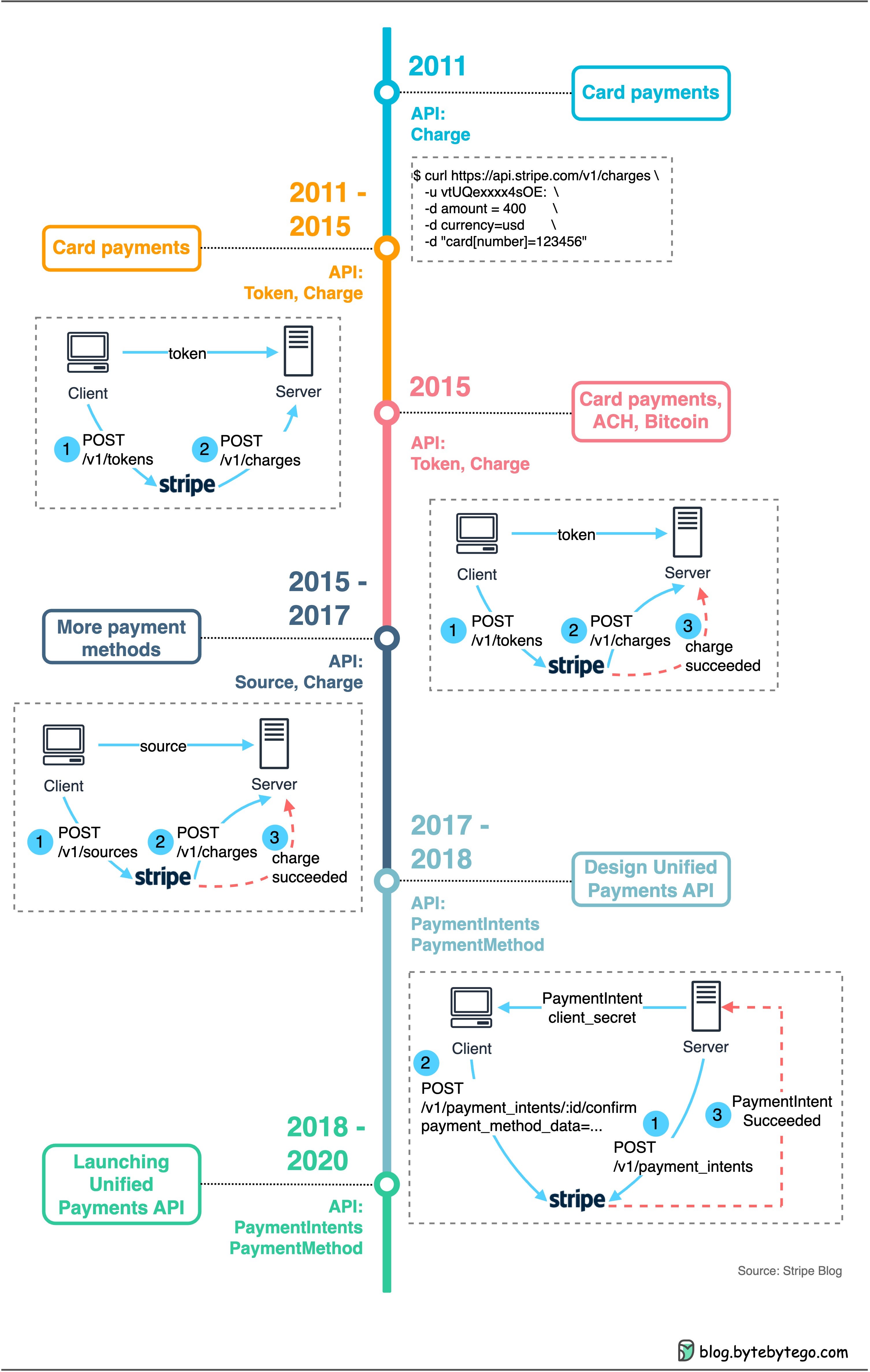
So far, we have covered two examples. Now, we’re going to examine a real-life example. The diagram below shows the development of the Stripe payments API over the past 10+ years [5].
Stage 1 2011: The Stripe API, or what could be described as “7 lines of code”, revolved around the Charge concept. At this point, it exclusively handled card payments.
Stage 2 2011-2015: the Stripe API introduced the Token API. Its goal was to enable its customers to avoid the complex and tedious process of adhering to PCI compliance requirements.
Stage 3 2015: ACH and Bitcoin payments entered the scene. Because these types of transactions needed some time to “finalize”, Stripe integrated a feedback loop into the API. The change helped indicate the success of the charge.
Stage 4 2015-2017: This stage saw the addition of even more payment methods, including AliPay, WeChat Pay, and iDeal. As a result, the Source API was developed as an abstraction to support these varying payment methods.
Stage 5 2017-2018: As the number of supported payment methods grew, the team spent several months drafting a Unified Payments API, with the introduction of PaymentIntents and PaymentMethod.
Stage 6 2018-2020: Stripe invested two years to migrate their clients to the Unified Payments API.