
AWS lamda, HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC), How to scale a website, DevOps books (Episode 1)

How does AWS lambda work behind the scenes?
Serverless is one of the hottest topics in cloud services. How does AWS Lambda work behind the scenes?
Lambda is a serverless computing service provided by Amazon Web Services (AWS), which runs functions in response to events.
Firecracker MicroVM
Firecracker is the engine powering all of the Lambda functions [1]. It is a virtualization technology developed at Amazon and written in Rust.
The diagram below illustrates the isolation model for AWS Lambda Workers.
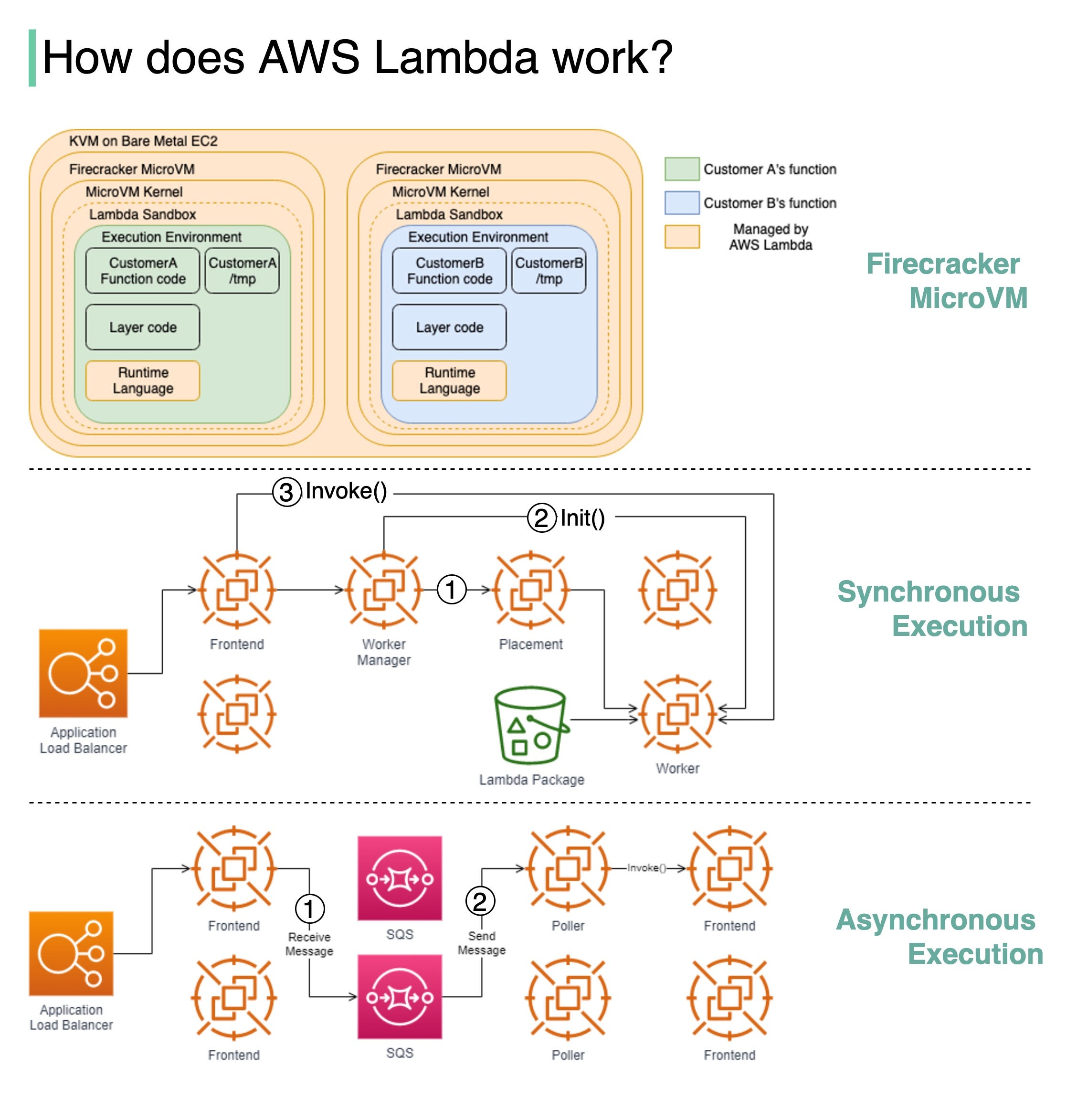
Lambda functions run within a sandbox, which provides a minimal Linux userland, some common libraries and utilities. It creates the Execution environment (worker) on EC2 instances.
How are lambdas initiated and invoked? There are two ways.
Synchronous execution
Step1: "The Worker Manager communicates with a Placement Service which is responsible to place a workload on a location for the given host (it’s provisioning the sandbox) and returns that to the Worker Manager" [2].
Step 2: "The Worker Manager can then call Init to initialize the function for execution by downloading the Lambda package from S3 and setting up the Lambda runtime" [2]
Step 3: The Frontend Worker is now able to call Invoke [2].
Asynchronous execution
Step 1: The Application Load Balancer forwards the invocation to an available Frontend which places the event onto an internal queue(SQS).
Step 2: There is "a set of pollers assigned to this internal queue which are responsible for polling it and moving the event onto a Frontend synchronously. After it’s been placed onto the Frontend it follows the synchronous invocation call pattern which we covered earlier" [2].
Question: Can you think of any use cases for AWS Lambda?
Sources:
[1] AWS Lambda whitepaper: https://lnkd.in/gVGjNj7S
[2] Behind the scenes, Lambda: https://lnkd.in/gbNNDWFY
Image source: [1] [2]
HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC).
What problem does each generation of HTTP solve? The diagram below illustrates the key features.

🔹HTTP 1.0 was finalized and fully documented in 1996. Every request to the same server requires a separate TCP connection.
🔹HTTP 1.1 was published in 1997. A TCP connection can be left open for reuse (persistent connection), but it doesn’t solve the HOL (head-of-line) blocking issue.
HOL blocking - when the number of allowed parallel requests in the browser is used up, subsequent requests need to wait for the former ones to complete.
🔹HTTP 2.0 was published in 2015. It addresses HOL issue through request multiplexing, which eliminates HOL blocking at the application layer, but HOL still exists at the transport (TCP) layer.
As you can see in the diagram, HTTP 2.0 introduced the concept of HTTP “streams”: an abstraction that allows multiplexing different HTTP exchanges onto the same TCP connection. Each stream doesn’t need to be sent in order.
🔹HTTP 3.0 first draft was published in 2020. It is the proposed successor to HTTP 2.0. It uses QUIC instead of TCP for the underlying transport protocol, thus removing HOL blocking in the transport layer.
QUIC is based on UDP. It introduces streams as first-class citizens at the transport layer. QUIC streams share the same QUIC connection, so no additional handshakes and slow starts are required to create new ones, but QUIC streams are delivered independently such that in most cases packet loss affecting one stream doesn't affect others.
How to scale a website to support millions of users?
We will explain this step-by-step.
The diagram below illustrates the evolution of a simplified eCommerce website. It goes from a monolithic design on one single server, to a service-oriented/microservice architecture.
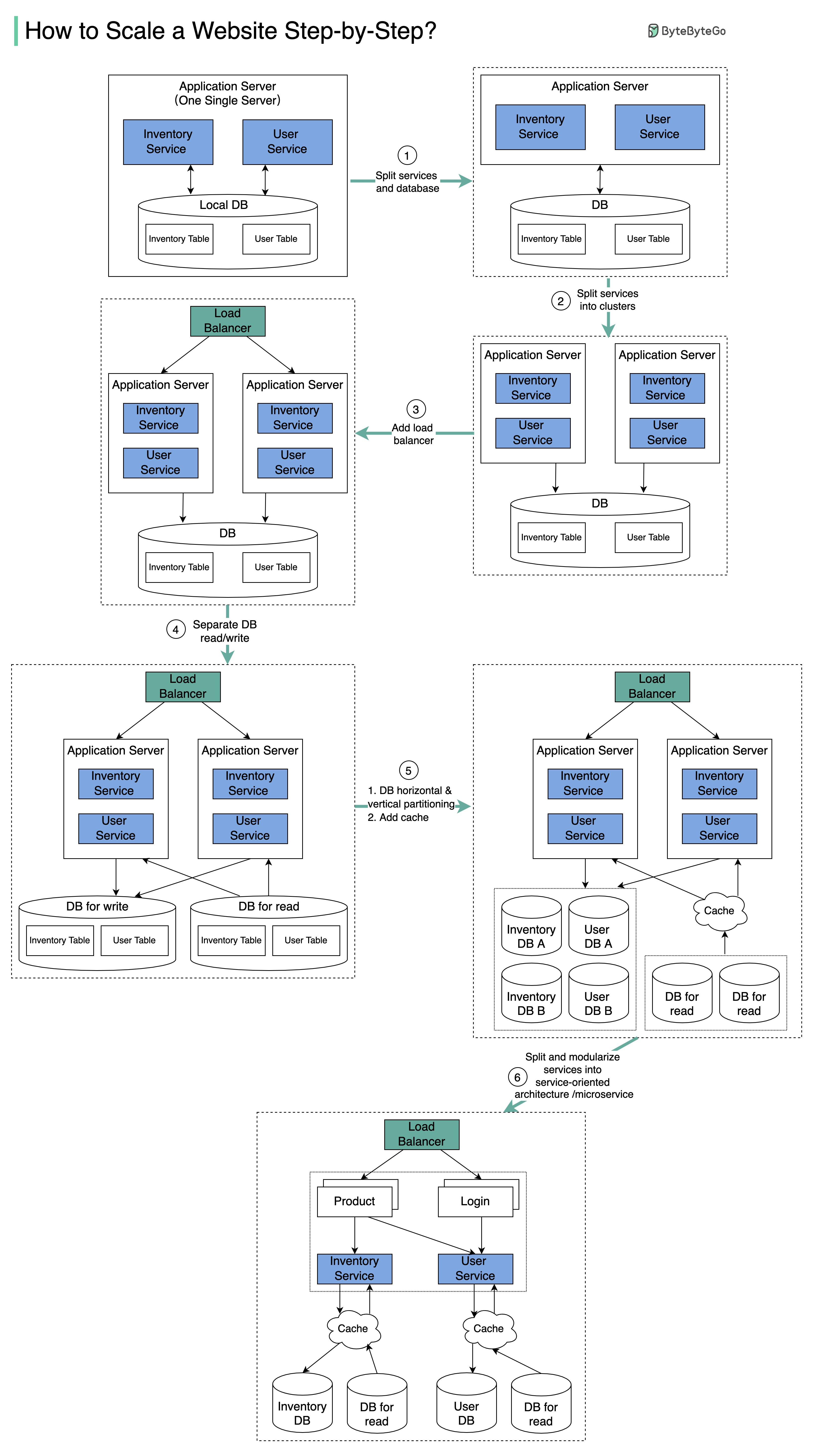
Suppose we have two services: inventory service (handles product descriptions and inventory management) and user service (handles user information, registration, login, etc.).
Step 1 - With the growth of the user base, one single application server cannot handle the traffic anymore. We put the application server and the database server into two separate servers.
Step 2 - The business continues to grow, and a single application server is no longer enough. So we deploy a cluster of application servers.
Step 3 - Now the incoming requests have to be routed to multiple application servers, how can we ensure each application server gets an even load? The load balancer handles this nicely.
Step 4 - With the business continuing to grow, the database might become the bottleneck. To mitigate this, we separate reads and writes in a way that frequent read queries go to read replicas. With this setup, the throughput for the database writes can be greatly increased.
Step 5 - Suppose the business continues to grow. One single database cannot handle the load on both the inventory table and user table. We have a few options:
1. Vertical scaling. Adding more power (CPU, RAM, etc.) to the database server. It has a hard limit.
2. Horizontal scaling by adding more database servers.
3. Adding a caching layer to offload read requests.
Step 6 - Now we can modularize the functions into different services. The architecture becomes service-oriented / microservice.
Question: what else do we need to support an e-commerce website at Amazon’s scale?
DevOps books
Some DevOps books I find enlightening:

🔹Accelerate - presents both the findings and the science behind measuring software delivery performance.
🔹Continuous Delivery - introduces automated architecture management and data migration. It also pointed out key problems and optimal solutions in each area.
🔹Site Reliability Engineering - famous Google SRE book. It explains the whole life cycle of Google’s development, deployment, and monitoring, and how to manage the world’s biggest software systems.
🔹Effective DevOps - provides effective ways to improve team coordination.
🔹The Phoenix Project - a classic novel about effectiveness and communications. IT work is like manufacturing plant work, and a system must be established to streamline the workflow. Very interesting read!
🔹The DevOps Handbook - introduces product development, quality assurance, IT operations, and information security.
What’s your favorite dev-ops book?
7 - event driven architecture with message queue
Which tools do you use to draw architecture diagram like these?