Consistent Hashing 101: How Modern Systems Handle Growth and Failure

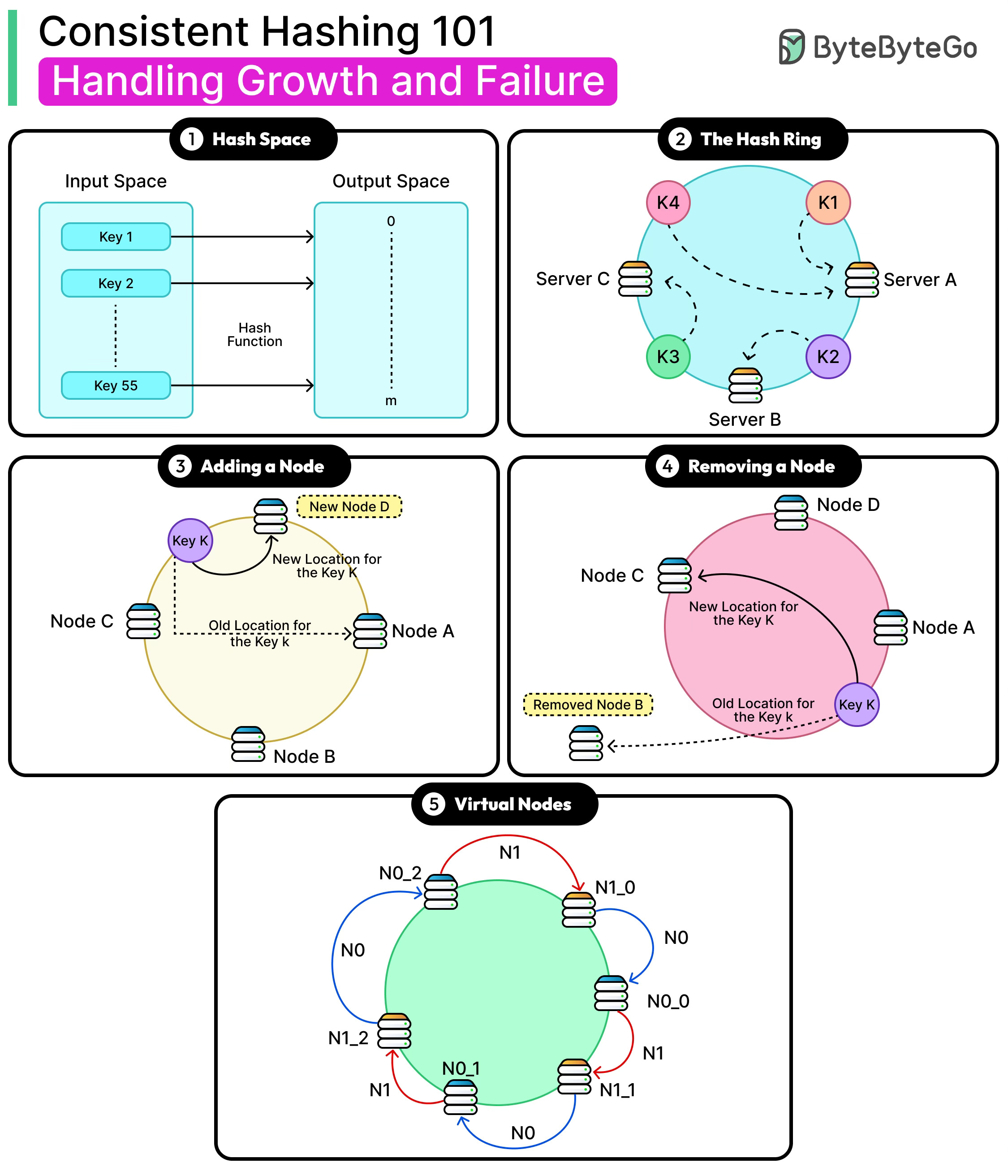
In the world of distributed systems, one of the hardest problems isn’t just storing or retrieving data. It’s figuring out where that data should live when we have dozens, hundreds, or even thousands of servers.
Imagine running a large-scale web service where user profiles, cached web pages, or product catalogs need to be spread across multiple machines.
Consistent hashing emerged as a clever solution to this problem and quickly became one of the foundational ideas for scaling distributed systems.
Instead of scattering keys randomly and having to reshuffle them every time the cluster size changes, consistent hashing ensures that only a small, predictable portion of keys needs to move when servers are created or destroyed. This property, often described as “minimal disruption,” is what makes the technique so powerful.
Over the years, consistent hashing has been adopted by some of the largest companies in technology. It underpins distributed caching systems like memcached, powers databases like Apache Cassandra and Riak, and is at the heart of large-scale architectures such as Amazon Dynamo. When browsing a social media feed, streaming a video, or shopping online, chances are that consistent hashing is working quietly in the background to keep the experience smooth and fast.
In this article, we will look at consistent hashing in detail. We will also understand the improvements to consistent hashing using virtual nodes and how it helps scale systems.