
Data Replication: A Key Component for Building Large-Scale Distributed Systems

Data replication is critical for building reliable, large-scale distributed systems. In this issue, we will explore common replication strategies and key factors in choosing a suitable strategy.
Throughout this issue, we will use databases as examples. Note that they are not the only data sources where replication can be useful. Replication could apply to cache servers like Redis and even application servers for critical in-memory data structures.
So, what is replication? It's a method of copying data from one place to another. We use it to make sure that our data is available when and where we need it. It helps us improve the durability and availability of our data, reduce latency, and increase bandwidth and throughput.

But choosing a replication strategy isn't always straightforward. There are different strategies, each with its own benefits and drawbacks. Some strategies might be better for certain use cases, while others might be better for different situations.
In this issue, we'll explore three main replication strategies: Leader-Follower, Multi-Leader, and Leaderless. We'll break down what each strategy is, how it works, and where it's most effectively used. We’ll discuss the trade-offs involved in each, so we can make informed decisions about the best strategy for our systems.
So, let's dive in and start exploring the world of data replication together.
A Primer on Replication
Let’s examine at a high level why replication is needed. As we mentioned earlier, we’ll use databases as examples throughout, but this applies to other types of data sources as well.
Improving Durability
Improving durability is perhaps the single most important reason for data replication. When a single database server fails, it could lead to catastrophic data loss and downtime. If the data is replicated to other database servers, the data is preserved even if one server goes down. Some replication strategies, like asynchronous replication, may still result in a small amount of data loss, but overall durability is greatly improved.

You might be wondering: Isn’t regular data backup sufficient for durability? Backups can certainly recover data after disasters like hardware failure. But backups alone have limitations for durability. Backups are periodic, so some data loss is likely between backup cycles. Restoring from backups is also slow and results in downtime. Replication to standby servers provides additional durability by eliminating (or greatly reducing) data loss windows and allowing faster failover. Backups and replication together provide both data recovery and minimized downtime.
Improving Availability
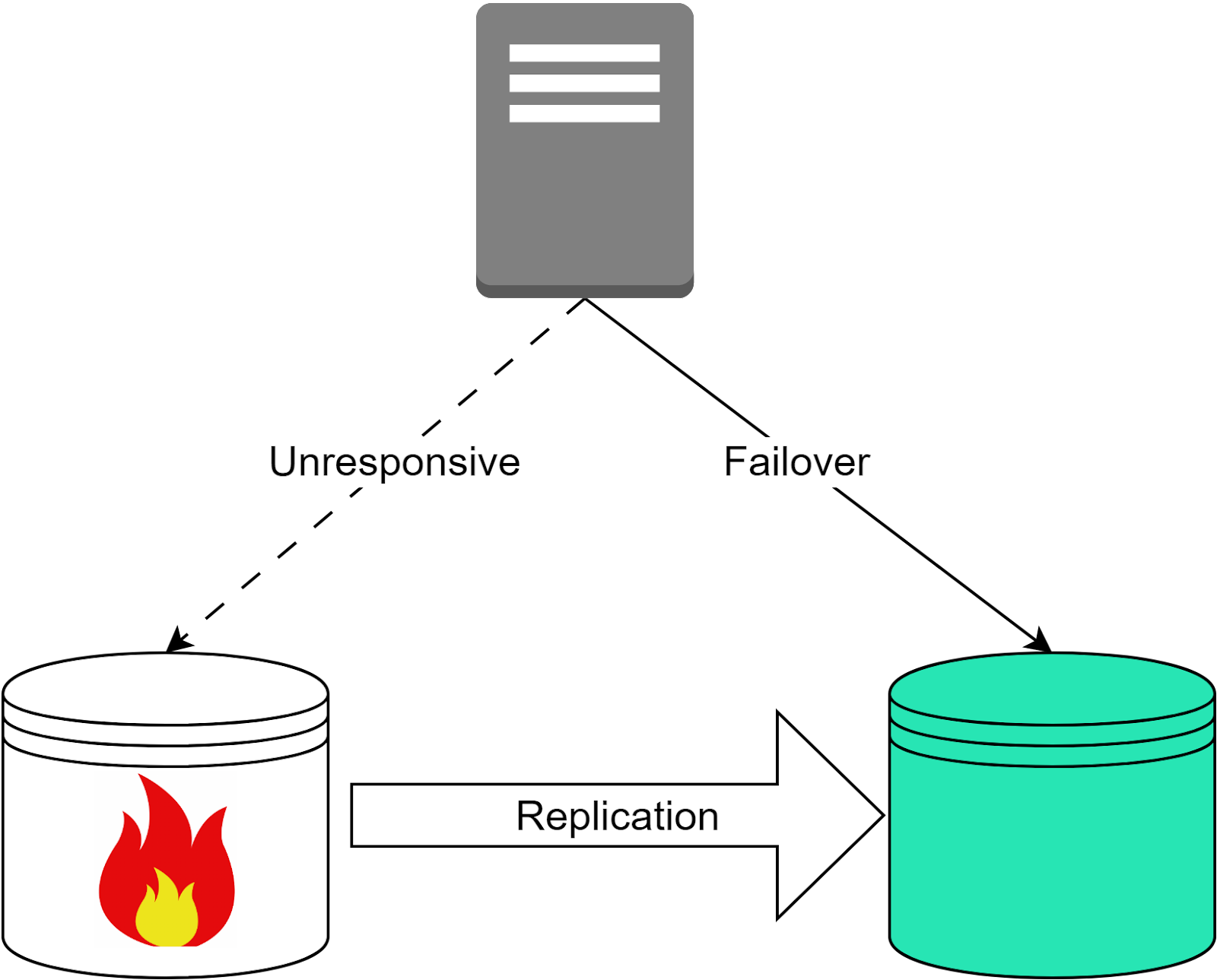
Another critical reason to replicate data is to improve overall system availability and resilience. When one database server goes offline or gets overwhelmed, keeping applications running smoothly can be challenging.
Simply redirecting traffic to a new server is non-trivial. The new node needs to already have a nearly identical copy of the data to take over quickly. And switching databases behind-the-scenes while maintaining continuous uptime for applications and users requires careful failover orchestration.
Replication enables seamless failover by keeping standby servers ready with up-to-date data copies. Applications can redirect traffic to replicas when issues occur with minimal downtime. Well-designed systems automatically handle redirection and failure recovery via monitoring, load balancing, and replication configurations.
Of course, replication has its own overhead costs and complexities. But without replication, a single server outage could mean prolonged downtime. Replication maintains availability despite outages.
Increasing Throughput
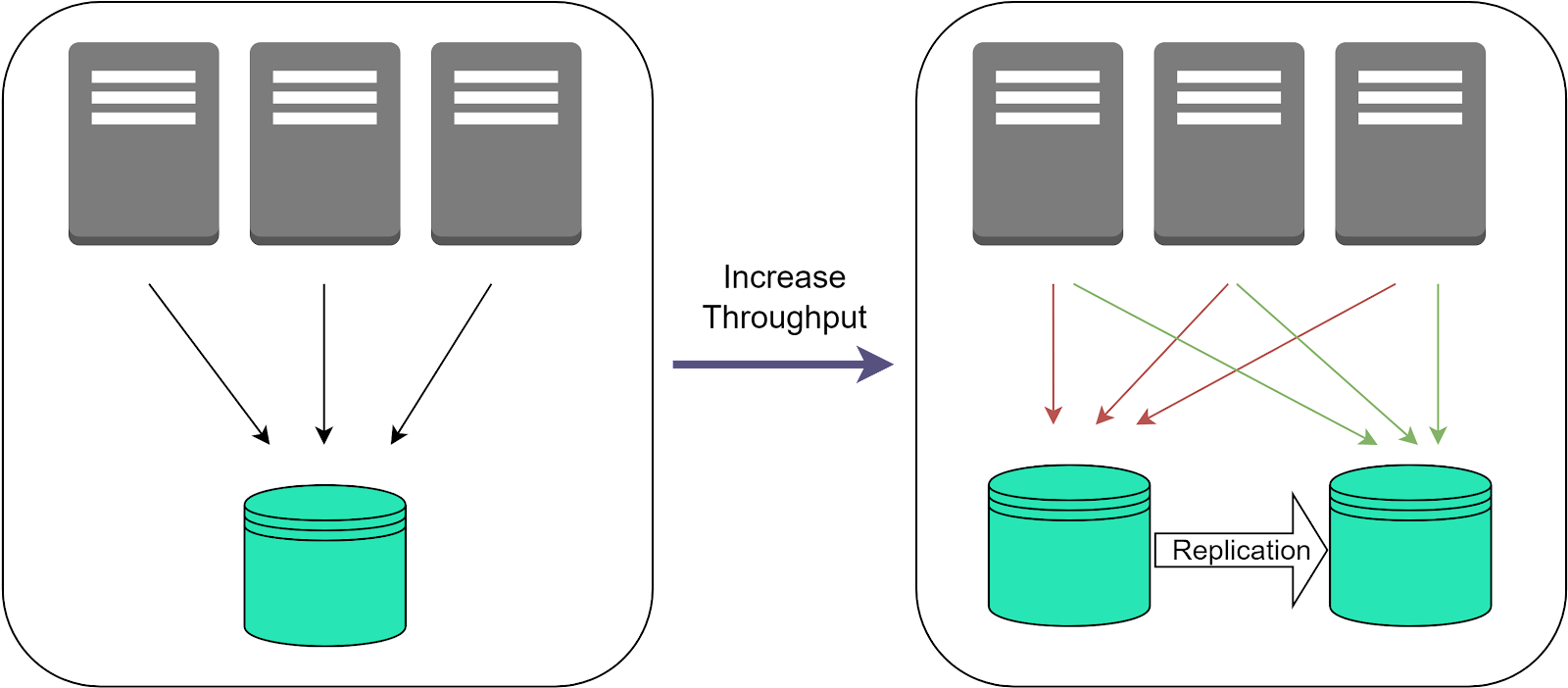
Replicating data across multiple database instances also increases total system throughput and scalability by spreading load across nodes.
With a single database server, there is a maximum threshold of concurrent reads and writes it can handle before performance degrades. By replicating to multiple servers, application requests can be distributed across replicas. More replicas means more capacity to handle load in parallel.
This sharding of requests distributes workload. It allows the overall system to sustain much higher throughput compared to a single server. Additional replicas can be added to scale out capacity even further as needed.
The replication itself has associated overheads that can become bottlenecks if not managed properly. Factors like inter-node network bandwidth, replication lag, and write coordination should be monitored.
But proper replication configurations allow horizontally scaling out read and write capacity. This enables massive aggregated throughput and workload scalability far beyond a single server's limits.
Reducing Latency
Data replication can also improve latency by locating data closer to users. For example, replicating a database to multiple geographic regions brings data copies closer to local users. This reduces the physical network distance that data has to travel compared to a single centralized database location.
Shorter network distance means lower transmission latency. So users' read and write requests see faster response times when routed to a nearby replicated instance versus one further away. Multi-region replication enables localized processing that avoids the high latencies of cross-country or intercontinental network routes.
Keep in mind that distributing copies across regions introduces complexities like replica synchronization, consistency, and conflict resolution with concurrent multi-site updates. Solutions like consistency models, conflict resolution logic, and replication protocols help manage this complexity.
When applicable, multi-region replication provides major latency improvements for geo-distributed users and workloads by localizing processing. The lower latency also improves user experience and productivity.

