
S3-like storage system

What happens when you upload a file to Amazon S3?
Before we dive into the design, let’s define some terms.
𝐁𝐮𝐜𝐤𝐞𝐭. A logical container for objects. The bucket name is globally unique. To upload data to S3, we must first create a bucket.
𝐎𝐛𝐣𝐞𝐜𝐭. An object is an individual piece of data we store in a bucket. It contains object data (also called payload) and metadata. Object data can be any sequence of bytes we want to store. The metadata is a set of name-value pairs that describe the object.
An S3 object consists of (Figure 1):
🔹 Metadata. It is mutable and contains attributes such as ID, bucket name, object name, etc.
🔹 Object data. It is immutable and contains the actual data.
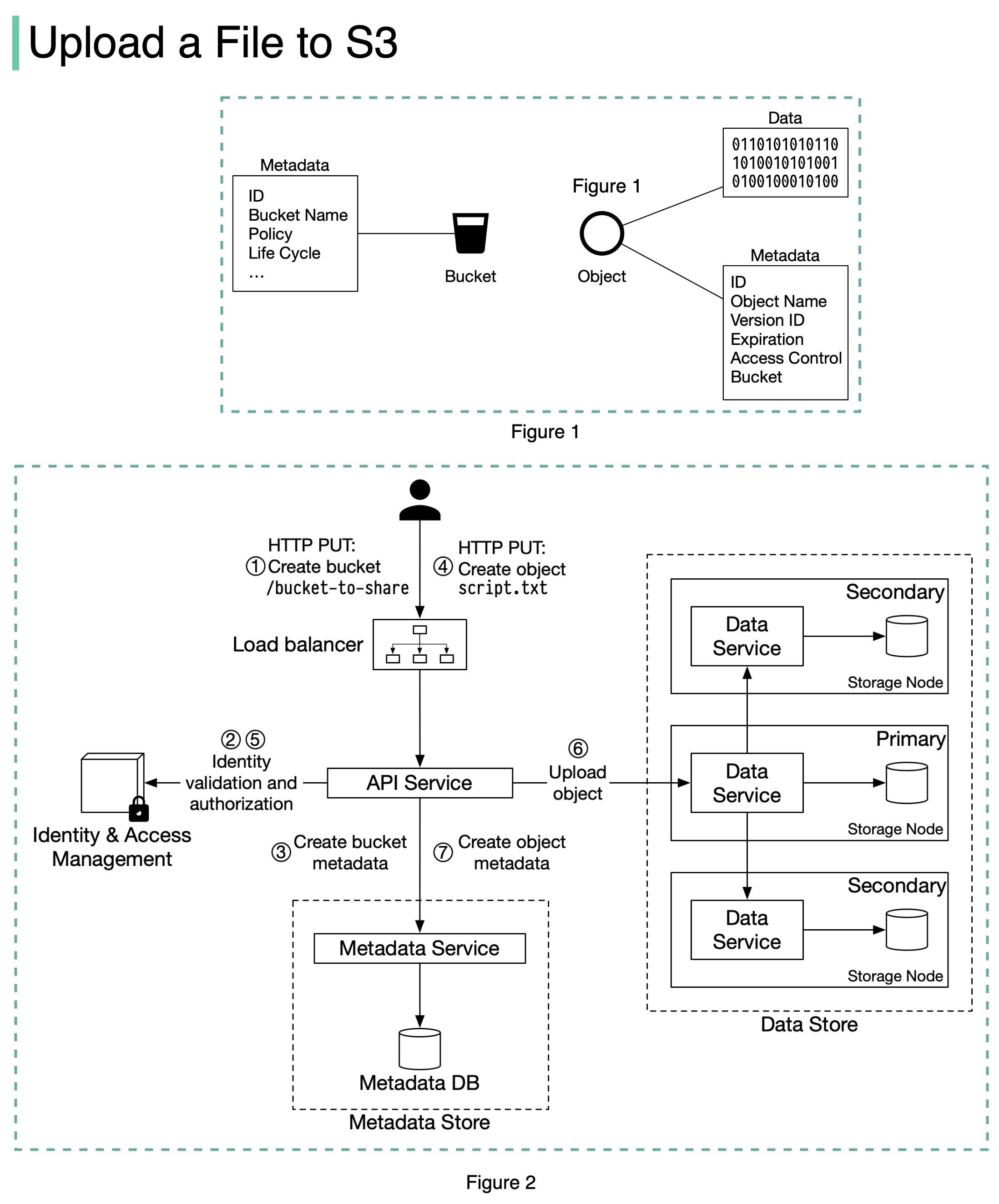
In S3, an object resides in a bucket. The path looks like this: /bucket-to-share/script.txt. The bucket only has metadata. The object has metadata and the actual data.
The diagram below (Figure 2) illustrates how file uploading works. In this example, we first create a bucket named “bucket-to-share” and then upload a file named “script.txt” to the bucket.
1. The client sends an HTTP PUT request to create a bucket named “bucket-to-share.” The request is forwarded to the API service.
2. The API service calls Identity and Access Management (IAM) to ensure the user is authorized and has WRITE permission.
3. The API service calls the metadata store to create an entry with the bucket info in the metadata database. Once the entry is created, a success message is returned to the client.
4. After the bucket is created, the client sends an HTTP PUT request to create an object named “script.txt”.
5. The API service verifies the user’s identity and ensures the user has WRITE permission on the bucket.
6. Once validation succeeds, the API service sends the object data in the HTTP PUT payload to the data store. The data store persists the payload as an object and returns the UUID of the object.
7. The API service calls the metadata store to create a new entry in the metadata database. It contains important metadata such as the object_id (UUID), bucket_id (which bucket the object belongs to), object_name, etc.
If you enjoyed this post, you might like our system design interview books as well.
SDI-vol1: https://amzn.to/3tK0qQn
SDI-vol2: https://amzn.to/37ZisW9
There is a correction in the durability calculations in the Book.
Erasure Coding
11 nines of durability for EC(8,4), with AFR of 0.81% is incorrect!
Using the calculator referenced in the book it is 14 nines.
EC(8,4)
MTTR = 6.5
AFR = 0.81% = 0.0081
P(F) = AFR * (MTTR (days)/365) = 0.0081 * (6.5/365)
P(S) = 1 - P(F)
0.99999999999999722488 ~ 14 nines
EC(17,3)
MTTR = 6.5
AFR = 0.41% = 0.0041
P(F) = AFR * (MTTR (days)/365) = 0.0041 * (6.5/365)
P(S) = 1 - P(F)
0.99999999999227524332 ~ 11 nines
For 11 nines we need AFR of 0.41% and EC(17,3) scheme
Replication
Similarly, 6 nines of durability for replication 3 is incorrect as well. It is 9 nines! (In this case, the book does mentions it as a rough estimate).
(1- (0.0081 * (6.5/365))^3)^(365/6.5)
0.99999999983146269658 = 9
Besides MTTR for replication will be better in comparison to erasure coding because of parity calculation overhead involved in EC. This would give us number of nines of durability better than 9 in this case!
https://github.com/Backblaze/erasure-coding-durability/blob/master/durability.py
Book mentions following statement under back-of-the-envelope estimations. What is the purpose of this? How does it serve in any estimations? IOPS is not mentioned anywhere in the rest of the chapter.
"IOPS. Let’s assume one hard disk (SATA interface, 7200 rpm) is capable of doing 100~150 random seeks per second (100-150 IOPS)."