
Dropbox Multimedia Search: Making File Search More Useful

How to stop bots from abusing free trials (Sponsored)

Free trials help AI apps grow, but bots and fake accounts exploit them. They steal tokens, burn compute, and disrupt real users.
Cursor, the fast-growing AI code assistant, uses WorkOS Radar to detect and stop abuse in real time. With device fingerprinting and behavioral signals, Radar blocks fraud before it reaches your app.
Disclaimer: The details in this post have been derived from the details shared online by the Dropbox Engineering Team. All credit for the technical details goes to the Dropbox Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
You’re racing against a deadline, and you desperately need that specific image from last month’s campaign or that video clip from a client presentation. You know it exists somewhere in your folders, but where? Was it in that project folder? A shared team drive? Or nested somewhere three levels deep in an old archive?
We’ve all been in this situation at some point, as this is the daily reality for knowledge workers who lose countless hours hunting for the right files within their cloud storage.
The problem becomes even more frustrating with multimedia content. While documents often have descriptive titles and searchable text inside them, images and videos typically come with cryptic default names like IMG_6798 or VID_20240315. Without meaningful labels, these files become nearly impossible to locate unless you manually browse through folders or remember exactly where you saved them.
Dropbox solved this problem by building multimedia search capabilities into Dropbox Dash, their universal search and knowledge management platform.
The challenge their engineering team faced wasn’t just about finding a file anymore. It’s about finding what’s inside that file. And when the folder structure inevitably breaks down, when files get moved or renamed by team members, or when you simply can’t recall the location of what you need, traditional filename-based search falls short.
In this article, we’ll explore how the Dropbox engineering team implemented multimedia search features and the technical challenges they faced along the way.
Challenges of Multimedia Search
Building a search feature for images, videos, and audio files presents a fundamentally different set of problems compared to searching through text documents.
Some of the key challenges are as follows:
Storage Costs: The sheer size difference is significant. Image files average about 3X larger than typical documents, while video files clock in at roughly 13X larger. These size differences directly translate to increased storage demands and costs.
Compute Intensity: Beyond storage, multimedia files require substantially more processing power to extract useful features. The complexity goes beyond just handling larger files. Unlike text documents, multimedia search needs visual previews at multiple resolutions to be useful, dramatically increasing computational requirements.
Ranking Relevance: Dropbox Dash already operated a sophisticated multi-phase retrieval and ranking system optimized for textual content. Extending this to multimedia meant indexing entirely new types of signals, creating query plans that leverage these signals effectively, and handling edge cases to avoid irrelevant results appearing at the top.
Preview Generation Dilemma: Users need visual previews to quickly identify the right file, and they need these previews in multiple resolutions for a smooth experience. However, only a small fraction of indexed files actually get viewed during searches. Pre-generating previews for everything would be extremely wasteful, but generating them on demand during searches introduces latency challenges that could frustrate users.
The Dropbox engineering team had to ensure their solution supported seamless browsing, filtering, and previewing of media content directly within Dash. This meant confronting higher infrastructure costs, stricter performance requirements, and adapting systems originally designed for text-based retrieval.
The Architecture
To deliver fast and accurate multimedia search while keeping costs manageable, the Dropbox engineering team designed a solution built on three core pillars:
A metadata-first indexing pipeline
Intelligent location-aware search
A preview generation system that creates visuals only when needed
Indexing Pipeline for Metadata
The foundation of multimedia search begins with indexing, the process of cataloging files so they can be quickly retrieved later. Dropbox made a critical early decision to index lightweight metadata rather than performing deep content analysis on every single file. This approach dramatically reduces computational costs while still enabling effective search.
Before building this multimedia search capability, Dropbox had intentionally avoided downloading or storing raw media blobs to keep storage and compute costs low. However, this meant their existing search index lacked the necessary features to support rich, media-specific search experiences. To bridge this gap, the team added support for ingesting multimedia blob content to extract the required features. Importantly, they retain the raw content not just for preview generation, but also to enable computing additional features in the future without needing to re-ingest files.
To power this indexing pipeline, Dropbox leveraged Riviera, its existing internal compute framework that already processes tens of petabytes of data daily for Dropbox Search. By reusing proven infrastructure, the team gained immediate benefits in scalability and reliability without building something entirely from scratch.
The indexing process extracts several key pieces of information from each multimedia file. This includes basic details like file path and title, EXIF data such as camera metadata, timestamps, and GPS coordinates, and even third-party preview URLs when available from applications like Canva.
See the diagram below:
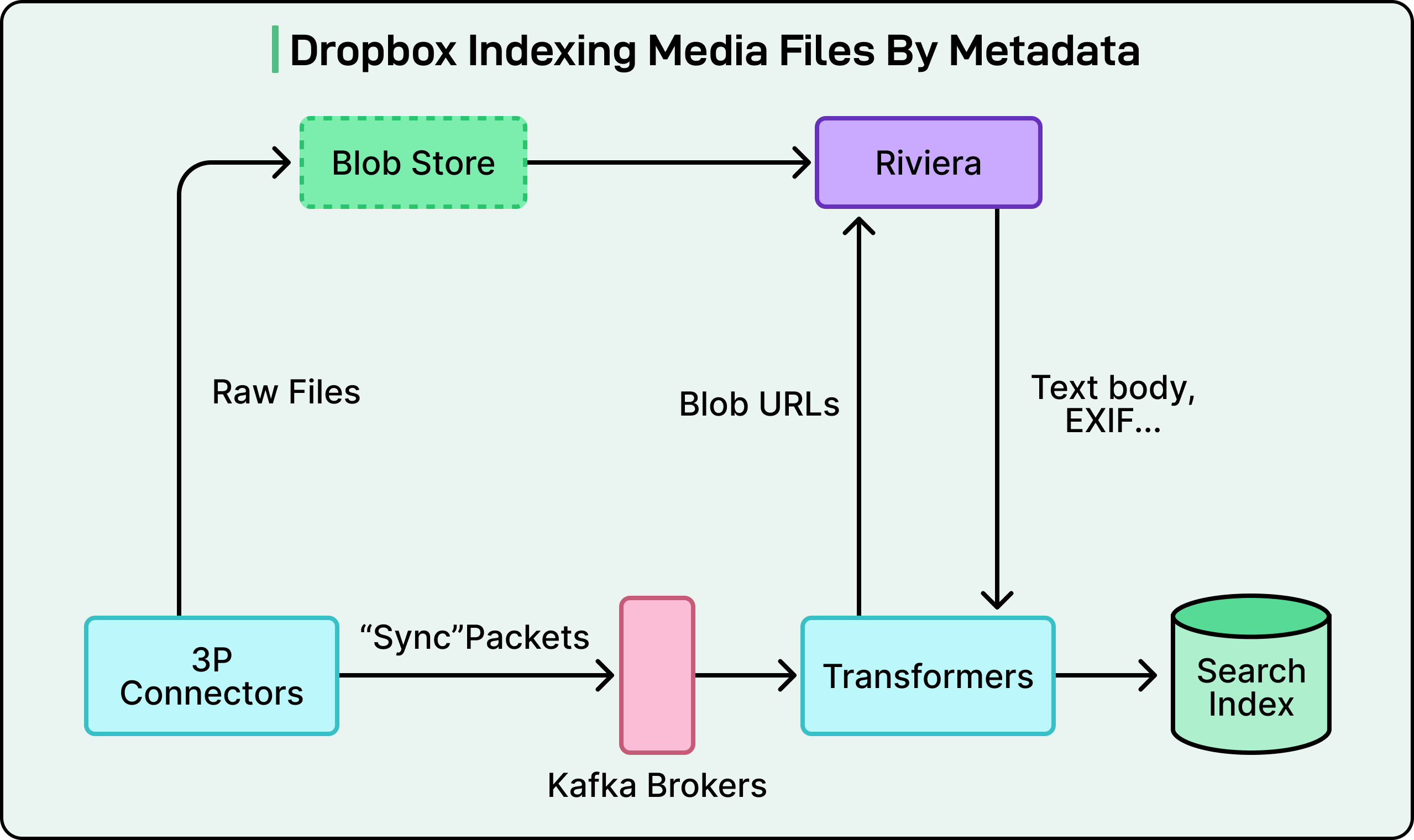
The data flows through the system in the following way:
Raw files are stored in a blob store
Riviera extracts features and metadata from these files
Information flows through third-party connectors
Kafka message brokers transport the data
Transformers process and structure the information
Finally, everything populates the search index
This metadata-first approach provides a lightweight foundation for search functionality while keeping processing overhead minimal. The team plans to selectively incorporate deeper content analysis techniques like semantic embeddings and optical character recognition in future iterations, but starting simple allowed them to ship faster.
Geolocation-Aware Retrieval System
Another feature Dropbox built into multimedia search is the ability to find photos and videos based on where they were taken. This geolocation-aware system works through a process called reverse geocoding.
See the diagram below:
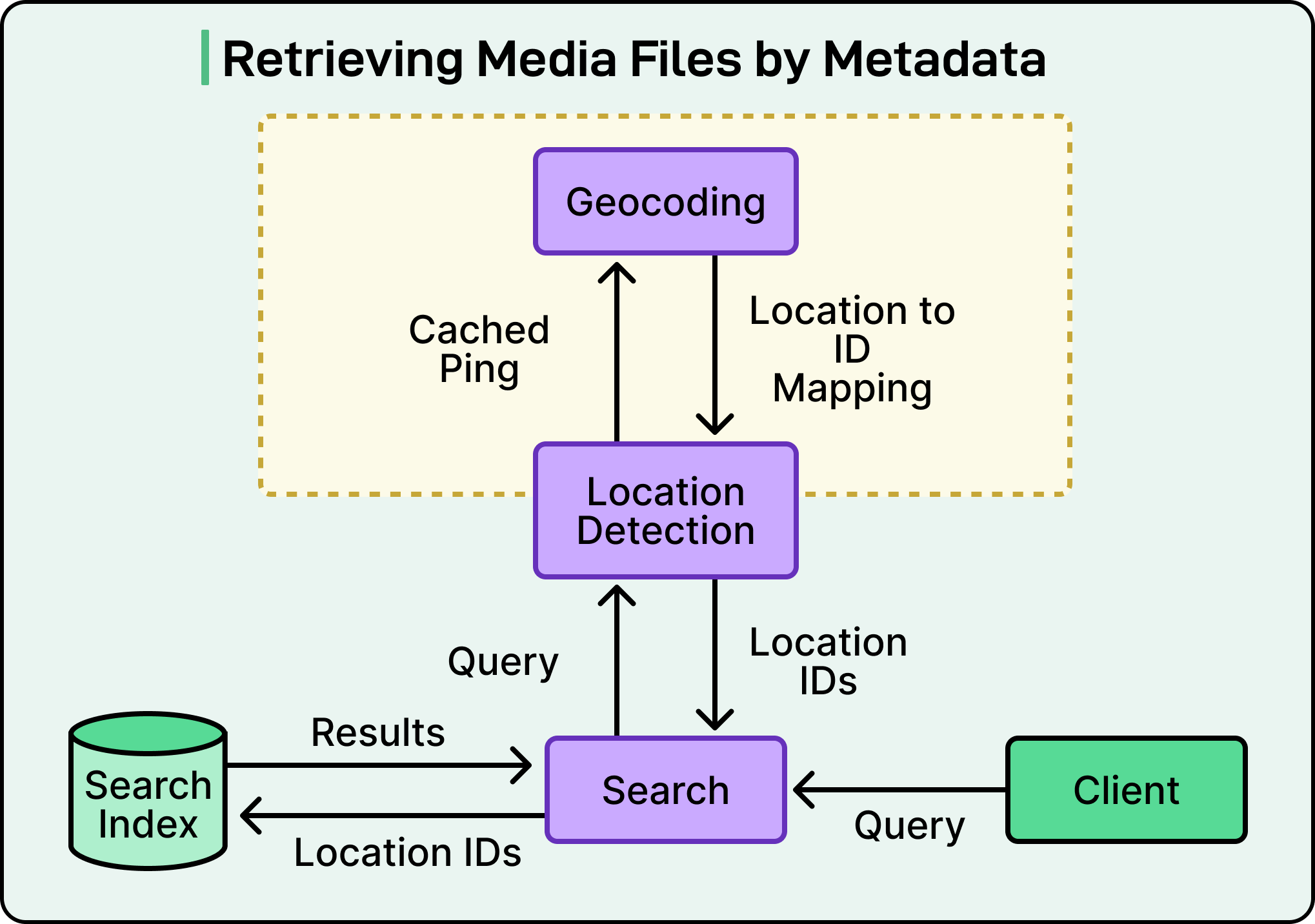
During indexing, when a file contains GPS coordinates in its metadata, Dropbox converts those coordinates into a hierarchical chain of location IDs. For example, a photo taken in San Francisco would generate a chain linking San Francisco to California to the United States. This hierarchy is crucial because it enables flexible searching at different geographic levels.
At query time, when a user searches for something like “photos from California,” the system identifies that “California” is a geographic reference, validates it against a cached mapping of location IDs, and retrieves all photos tagged with that location or any of its child locations, like San Francisco. Since the number of known geographic locations has a manageable size, Dropbox caches the entire location mapping at service startup, making lookups extremely fast.
This approach elegantly handles the challenge of location-based search without requiring users to remember exact locations or browse through folder structures organized by place.
Just-In-Time Preview Generation
The most interesting architectural decision Dropbox made was generating previews on demand rather than pre-computing them for all files. This choice directly addresses the preview generation dilemma mentioned earlier.
The rationale was straightforward. Dropbox ingests files at a rate roughly three orders of magnitude higher than users query for them. Pre-computing previews for every single multimedia file would be prohibitively expensive, especially since only a small fraction of indexed files actually get viewed during searches.
Instead, when a search returns results, the system generates preview URLs that the frontend can fetch. These URLs point to a preview service built on top of Riviera that generates thumbnails and previews in multiple resolutions on the fly. To avoid repeatedly generating the same preview, the system caches them for 30 days, striking a balance between storage costs and performance.
See the diagram below:
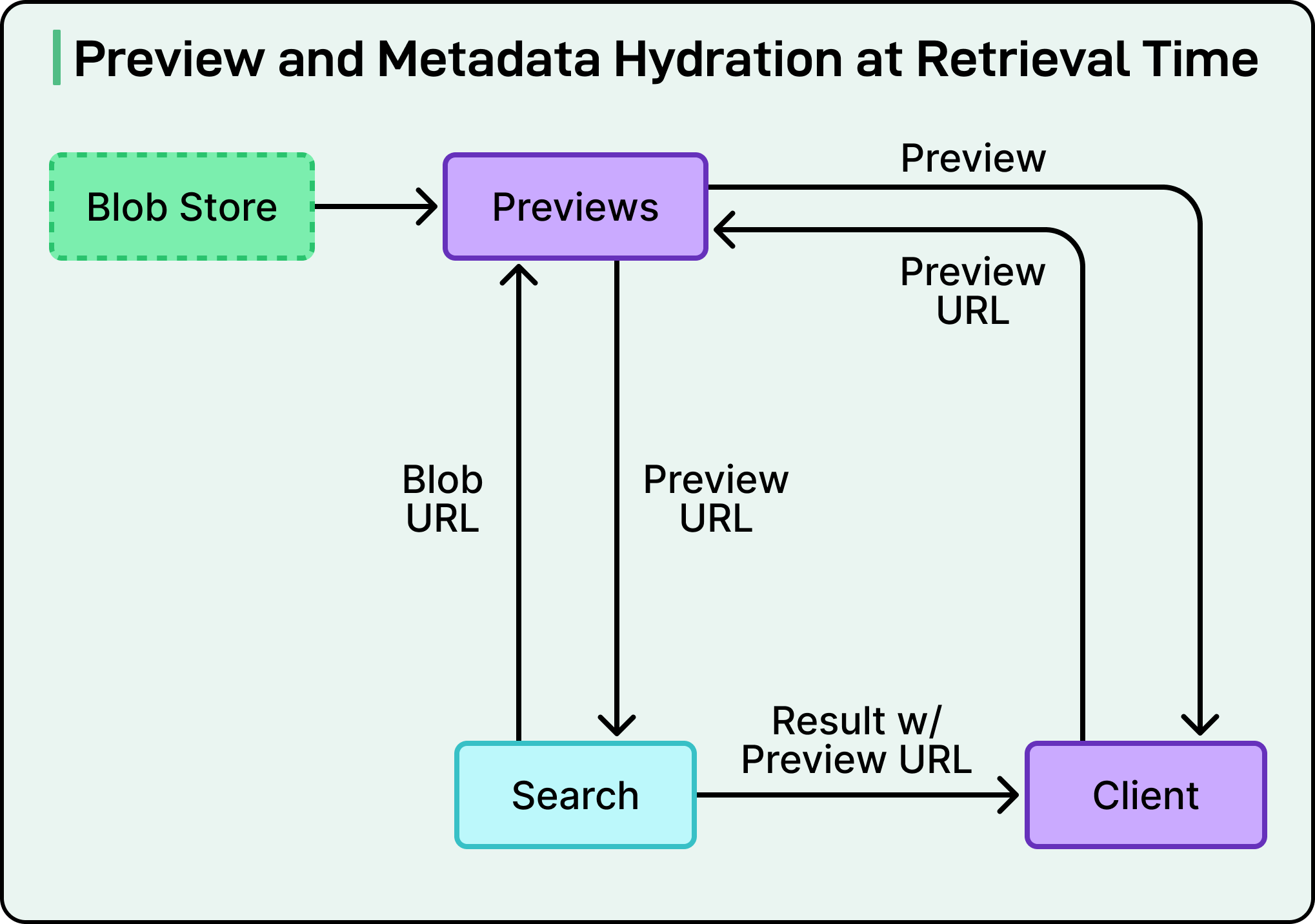
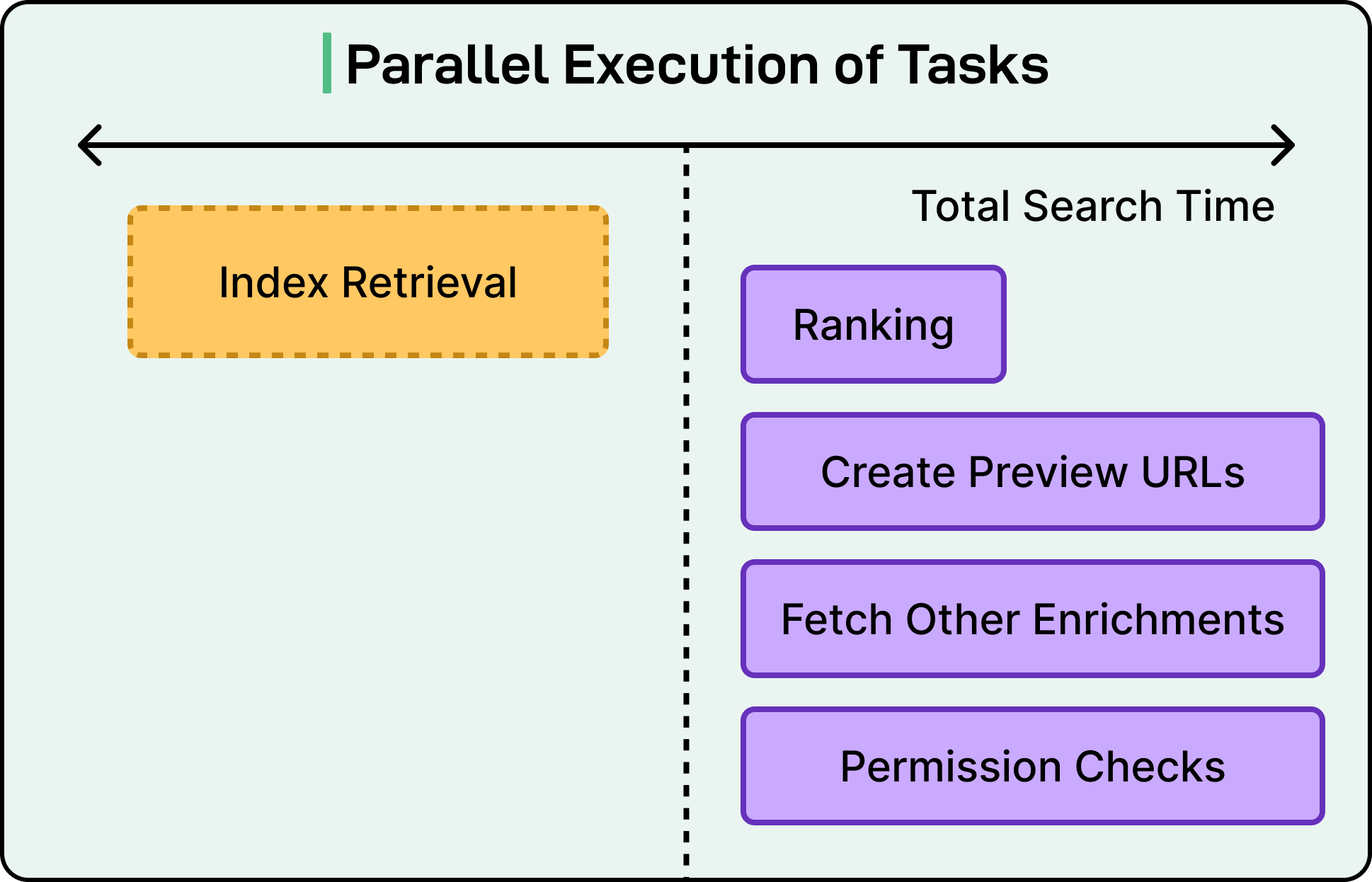
The team optimized for speed by running preview URL generation in parallel with other search operations like ranking results, checking permissions, and fetching additional metadata. This parallelization significantly reduces overall response time. When users want to see more detail about a specific file, such as camera information or exact timestamps, the system fetches this metadata on demand through a separate endpoint, keeping the initial search response lean and fast.
See the diagram below:
Technical Trade-Offs and Design Decisions
Building the multimedia search feature required the Dropbox engineering team to make deliberate choices about where to invest resources and where to optimize for efficiency.
Cost vs. Performance Decisions
The team made three key trade-offs to balance system performance with infrastructure costs.
First, they chose metadata-only indexing initially, deferring expensive content analysis techniques like OCR and semantic embeddings to future iterations. This allowed them to ship faster while keeping compute costs manageable.
Second, they shifted the compute from the write path to the read path by generating previews just-in-time rather than during ingestion.
Finally, they implemented selective ingestion that currently covers 97% of media files, with ongoing work to optimize handling of edge cases.
Reusing What Works
Rather than building everything from scratch, Dropbox maximized code reusability wherever possible. They leveraged the existing Riviera framework for consistency with their established infrastructure and reused the Dropbox preview service that was already battle-tested. The team also shared frontend components between Dropbox and Dash, ensuring a consistent user experience across both platforms.
A critical organizational decision was establishing clear API boundaries between different systems. This separation allowed multiple teams to work in parallel rather than sequentially, significantly accelerating development timelines without creating integration headaches later.
Conclusion
Building a multimedia search for Dropbox Dash showcases how thoughtful engineering can solve complex problems without over-engineering the solution. By starting with lightweight metadata indexing, deferring expensive operations to query time, and leveraging existing infrastructure wherever possible, the Dropbox engineering team created a scalable system that balances performance with cost efficiency.
The development process itself offers valuable lessons. When faced with interdependencies that could have slowed progress, the team temporarily proxied Dropbox Search results through a custom endpoint during UX development. This workaround allowed frontend work to proceed in parallel while the backend infrastructure was being built, dramatically accelerating the overall timeline.
Performance monitoring played a crucial role in refining the system. The team added latency tracking for preview generation, used instrumentation to identify bottlenecks, and implemented aggressive concurrency improvements based on the metrics they gathered. This data-driven approach to optimization ensured they focused efforts where they would have the most impact.
As mentioned, Dropbox plans to enhance multimedia search with semantic embeddings and optical character recognition, bringing even deeper content understanding to the platform. The architecture they’ve built maintains clear paths for these future enhancements without requiring fundamental redesigns.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.