
EP186: Latency vs. Throughput

👋 Goodbye low test coverage and slow QA cycles (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native solution provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to less than 15 minutes.
They can get you:
80% automated E2E test coverage in weeks—not years
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
This week’s system design refresher:
Latency vs. Throughput
Top 20 System Design Concepts You Should Know
How to Debug a Slow API?
How LLMs See the World
RAG vs Fine-tuning: Which one should you use?
SPONSOR US
Latency vs. Throughput
Ever wondered why your app feels slow even when the bandwidth looks fine? Latency and throughput explain two very different stories of performance.
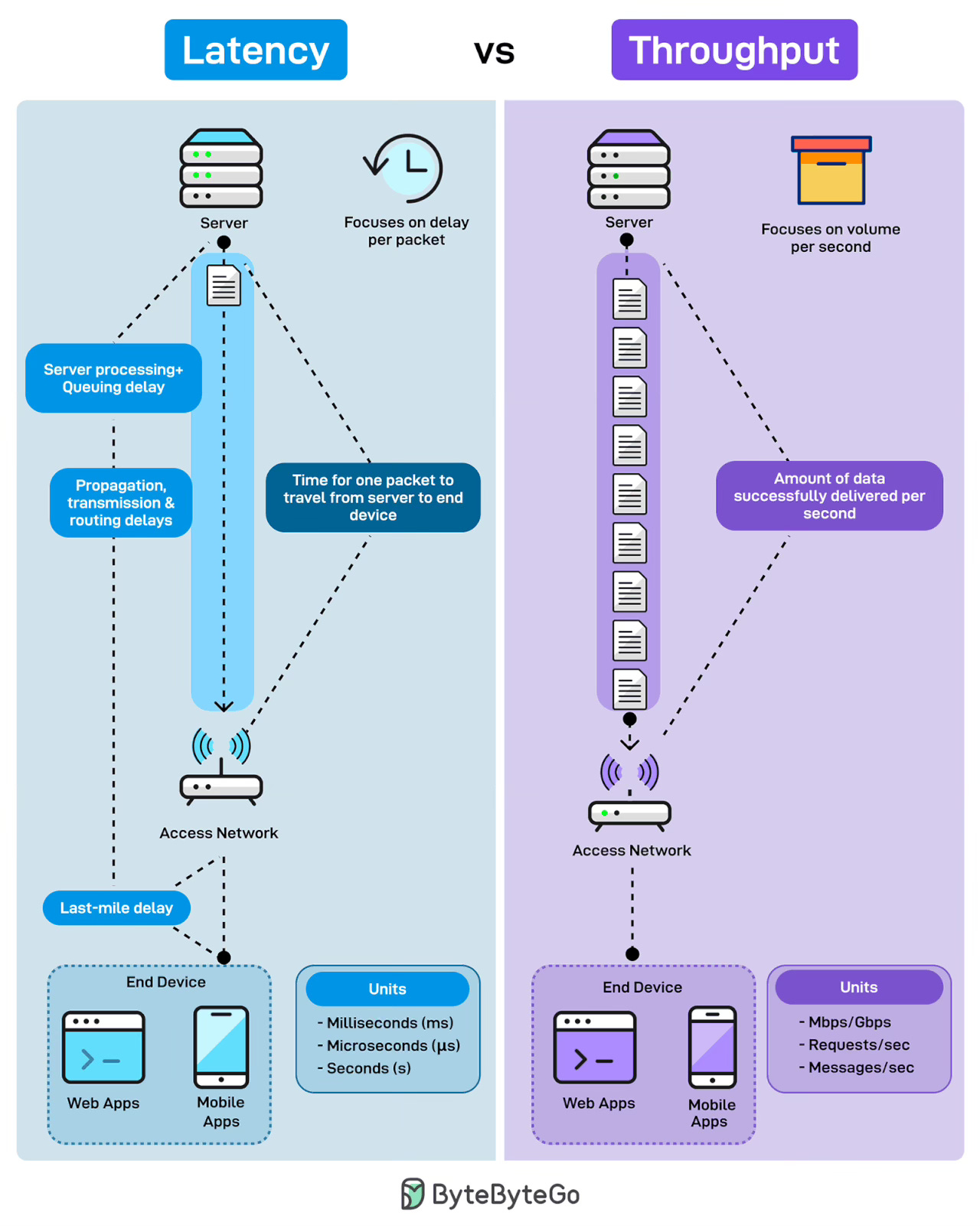
Latency measures the delay per packet. It is what users feel when they click a button. It’s responsiveness. It is the time for one request to travel from the server to the end device. This includes server processing time, queuing delays, propagation through the network, transmission delays, and the last-mile connection to the user’s device.
Throughput measures volume per second. It is how much data successfully gets delivered in a given timeframe. Not how fast each packet moves, but how many packets flow through the pipe. Throughput is capacity. High throughput means the system handles the load without choking.
Over to you: How do you measure these metrics in a way that actually predicts when things will break?
Top 20 System Design Concepts You Should Know

Load Balancing: Distributes traffic across multiple servers for reliability and availability.
Caching: Stores frequently accessed data in memory for faster access.
Database Sharding: Splits databases to handle large-scale data growth.
Replication: Copies data across replicas for availability and fault tolerance.
CAP Theorem: Trade-off between consistency, availability, and partition tolerance.
Consistent Hashing: Distributes load evenly in dynamic server environments.
Message Queues: Decouples services using asynchronous event-driven architecture.
Rate Limiting: Controls request frequency to prevent system overload.
API Gateway: Centralized entry point for routing API requests.
Microservices: Breaks systems into independent, loosely coupled services.
Service Discovery: Locates services dynamically in distributed systems.
CDN: Delivers content from edge servers for speed.
Database Indexing: Speeds up queries by indexing important fields.
Data Partitioning: Divides data across nodes for scalability and performance.
Eventual Consistency: Guarantees consistency over time in distributed databases
WebSockets: Enables bi-directional communication for live updates.
Scalability: Increases capacity by upgrading or adding machines.
Fault Tolerance: Ensures system availability during hardware/software failures.
Monitoring: Tracks metrics and logs to understand system health.
Authentication & Authorization: Controls user access and verifies identity securely.
Over to you: Which other System Design concept will you add to the list?
How to Debug a Slow API?
Your API is slow. Users are complaining. And you have no idea where to start looking. Here is the systematic approach to track down what is killing your API.

Start with the network: High latency? Throw a CDN in front of your static assets. Large payloads? Compress your responses. These are quick wins that don’t require touching code.
Check your backend code next: This is where most slowdowns hide. CPU-heavy operations should run in the background. Complicated business logic that needs simplification. Blocking synchronous calls that should be async. Profile it, find the hot paths, fix them.
Check the database: Missing indexes are the classic culprit. Also watch for N+1 queries, where you are hammering the database hundreds of times when one batch query would do.
Don’t forget external APIs: That Stripe call, that Google Maps request, they are outside your control. Make parallel calls where you can. Set aggressive timeouts and retries so one slow third-party doesn’t tank your whole response.
Finally, check your infrastructure: Maxed-out servers need auto-scaling. Connection pool limits need tuning. Sometimes the problem isn’t your code at all, it’s that you are trying to serve 10,000 requests with resources built for 100.
The key is being methodical. Don’t just throw solutions at the wall. Measure first, identify the actual bottleneck, then fix it.
Over to you: What is the weirdest performance issue you have tracked down?
How LLMs See the World

When you type “Hello world” into ChatGPT or Claude, the model isn’t processing those letters and spaces like you’re reading this post right now. It’s converting everything into numbers through a process most people never think about.
Preprocessing comes first. Text gets normalized. Unicode characters, spacing quirks, and special symbols, they all get cleaned up and standardized. “Hello world” becomes a consistent format that the model can actually work with.
Then comes tokenization. This is where things get interesting. The model splits text into tokens, and there are different approaches.
Character-based tokenization breaks everything down to individual characters. “Hello world” becomes [”H”, “e”, “l”, “l”, “o”, “ “, “w”, “o”, “r”, “l”, “d”]. Simple but inefficient.
Word-based splits on whole words. [”Hello”, “world”]. Cleaner but struggles with rare words and creates massive vocabularies.
Subword-based is what modern LLMs actually use. GPT, Gemini, Claude, they all rely on this. “Hello world” becomes something like [”Hell”, “o”, “world”]. It balances efficiency with flexibility, handling rare words by breaking them into known subword pieces.
The final step is Token IDs. Those subwords get mapped to numbers like [15496, 345, 995]. Each token ID corresponds to an embedding vector inside the model. That’s what the neural network actually processes.
Over to you: Why do some models handle code better than natural language? Is it the tokenizer?
RAG vs Fine-tuning: Which one should you use?
When it comes to adapting Large Language Models (LLMs) to new tasks, two popular approaches stand out: Retrieval-Augmented Generation (RAG) and Fine-tuning. They solve the same problem, making models more useful, but in very different ways.
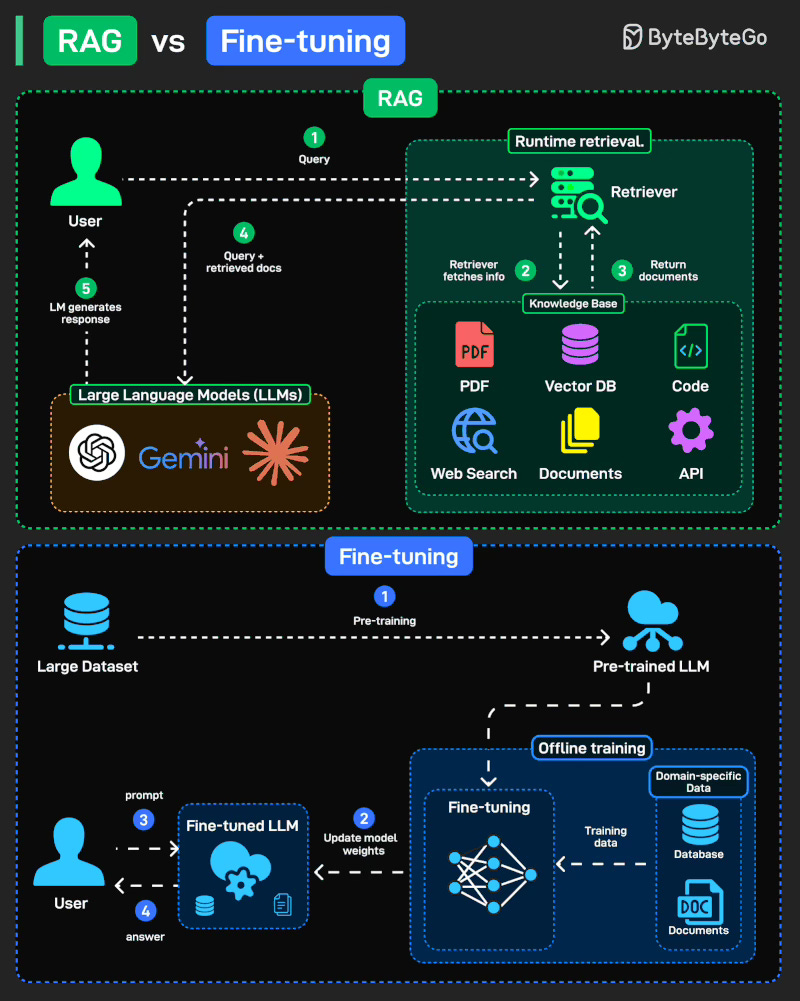
RAG (Retrieval-Augmented Generation): Fetches knowledge at runtime from external sources (docs, DBs, APIs). Flexible, always fresh.
Fine-tuning: Offline training that updates model weights with domain-specific data, making the model an expert in your field.
Over to you: For your domain, is fresh knowledge (RAG) or embedded expertise (Fine-tuning) more valuable?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
A highly related but very different concept in system design/implementation/management.