
EP220: RAG vs Graph RAG vs Agentic RAG

✂️ Cut your QA cycles down to minutes with QA Wolf (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
This week’s system design refresher:
RAG vs Graph RAG vs Agentic RAG
Redis Data Structures Every Engineer Should Know
API Security Best Practices
Design Patterns Cheat Sheet
The Testing Pyramid
RAG vs Graph RAG vs Agentic RAG
RAG connects LLMs to your data and there are three different ways to do it.

Standard RAG
The query is converted into an embedding and matched against a vector database.
The top-K closest chunks are pulled out and passed to the LLM as context.
The LLM writes a grounded answer using only what was retrieved.
Graph RAG
The query is classified: specific questions route to local search, broad questions route to global search.
Local search: query embedded → vector DB finds matching entities → pipeline traverses across the knowledge graph collecting linked context → LLM synthesis final answer.
Global search: no vector search, no graph traversal → community reports loaded in batches → LLM scores each for relevance → top-ranked context → LLM synthesizes final response.
Agentic RAG
A reasoning agent reads the query, breaks it into sub-questions and picks the sources.
The context across multiple sources is retrieved, depending on the sub-query.
Another agent checks whether the retrieved context answers the question. If not, it re-retrieves.
Once satisfied, the final answer is synthesized by LLM based on the prompt.
Standard RAG is fast and cheap but if the wrong chunk is retrieved, the answer is wrong and nothing catches it.Use it when the answer lives in your documents and speed matters.
Graph RAG is expensive to build and slow to update. Use it for structured knowledge like legal, compliance, or biomedical data.
Agentic RAG is more capable and flexible but slower, expensive, and harder to debug. Use it when the question needs multi-step reasoning and self-correction.
Over to you: Which of these are you running in production?
Redis Data Structures Every Engineer Should Know
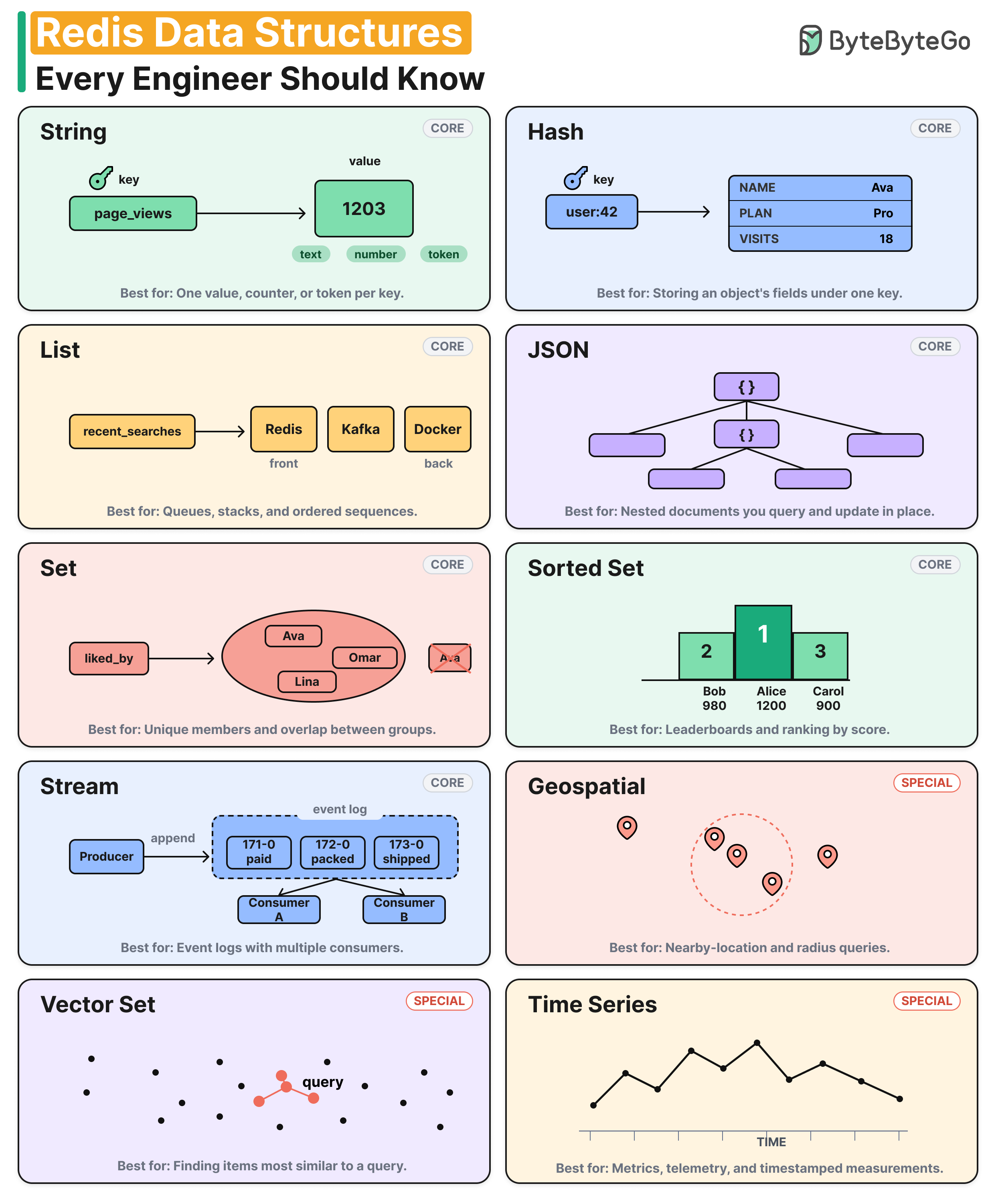
Strings store one value per key. They work for counters, session tokens, and cached payloads.
Hashes store an object's fields under one key. You can update one field without rewriting the rest.
Lists are ordered sequences with fast push and pop at both ends. They fit queues, feeds, and recent-item lists.
Sets hold unique members and support intersection, union, and difference. They cover tagging, follower overlap, and deduplication.
Sorted Sets rank members by a numeric score. They handle leaderboards, priority queues, and top-N or range-by-score queries.
Streams are an append-only log with consumer groups. Each consumer tracks its own position, and the server tracks unacknowledged messages.
JSON stores nested documents with JSONPath access. You can update a field deep in a document without read-modify-write.
Geospatial provides latitude/longitude indexes with radius and box queries. Under the hood it's a Sorted Set with geohash scores.
Vector Set runs approximate nearest-neighbor search over embeddings. It's the retrieval step in most RAG pipelines.
Time Series stores timestamped samples with built-in retention, downsampling, and labels. It fits metrics, telemetry, and IoT data.
Over to you: All ten are built-in as of Redis 8. Which one do you use most outside of caching?
API Security Best Practices
Most API breaches happen because of broken authorization, leaked secrets, or missing rate limits. Let's look at some of the basics.

Use Modern OAuth/OIDC + MFA: PKCE for public clients, short-lived tokens, and step-up MFA for anything sensitive. Implicit and password grants should be dead by now.
Enforce Fine-Grained Authorization: Check object, function, and field-level permissions on every request. BOLA is still the top API vulnerability.
Minimize Scopes and Data: Give each client the smallest token scope and the least data it needs. Only return the fields the caller actually needs.
Encrypt Every Hop: TLS for external traffic and mTLS between services. If it crosses a network boundary, encrypt it.
Protect Secrets and Keys: Store signing keys in HSM-backed vaults. Rotate them.
Validate Requests with Schemas: Reject unknown fields, oversized payloads, and suspicious URLs at the gateway. Don't let bad input reach your business logic.
Rate Limit and Cap Resources: Quotas per user, payload size caps, and execution timeouts. Without these, one misbehaving client takes down your entire system.
Defend Sensitive Business Flows: Protect login, checkout, and OTP with anti-bot, idempotency keys, and step-up auth.
Control Outbound and Third-Party Calls: Allowlist where your API can call out to and block internal metadata endpoints. Your security is only as strong as your weakest integration.
Harden Config and Error Handling: Deny by default on CORS, methods, and debug endpoints. Return generic errors, never stack traces.
Inventory APIs and Versions: Track every endpoint, version, and shadow API. You can't secure what you don't know exists.
Log, Detect, and Respond: Push auth decisions and anomalies to a SIEM. Alert on 401 spikes before they become incidents.
Over to you: Which of these best practices is the hardest to enforce across your services?
Design Patterns Cheat Sheet
The cheat sheet briefly explains each pattern and how to use it.

What's included?
Factory
Builder
Prototype
Singleton
Chain of Responsibility
And many more!

The Testing Pyramid

Testing is the backbone of reliable software. The Testing Pyramid is a widely accepted strategy for structuring tests into three key layers:
Unit Tests: These are the foundation of the pyramid. Unit tests are fast, isolated, and low-cost to write and maintain. They test individual functions, methods, or components.
Integration Tests: These tests validate interactions between components, such as APIs, databases, and external services. They are slower than unit tests and require more setup.
E2E Tests: These simulate real user flows from start to finish across the full system. They are expensive to write and maintain and tend to be slow to execute.
As you go up the pyramid, the cost of test development, execution, and maintenance increases.
Over to you: Which layer do you find most valuable in your testing strategy, and why?
@ByteByteGo One of the clearest comparisons I've seen. This will help many engineers understand where each approach fits.
The jump from RAG to Agentic RAG is bigger than the diagram makes it look. Plain RAG and Graph RAG change what the model knows before it answers. Agentic RAG, the moment it has tool selection and MCP servers in the loop, changes what the model can do, not just what it retrieves. That is a different risk surface. A bad retrieval gives you a wrong answer you can read and reject. A bad tool call acts before you see it. Once retrieval can trigger actions, the hard part stops being relevance and starts being what the agent is allowed to do with what it found.