
EP46: Step-by-step guide on System Design Interview

This week’s system design refresher:
System Design Interview: The step-by-step guide (Youtube video)
Why is Redis so fast?
Things to consider when using cache
Git Workflow & Immutability
ChatGPT, Jasper AI, Copy AI: How are AI writers different?
Learn and Master Data Streaming with Redpanda University (Sponsored)

Data streaming can be hard to master. With Redpanda, engineers can get started with a simpler, faster, more resource-efficient system that won’t lose your data.
That’s why we put together a set of short, easy-to-digest courses on streaming data fundamentals, plus how to get started with Redpanda, our uber-fast, easy-to-use, Kafka-compatible, and source-available streaming data platform.
In this series of short courses, you will learn:
The fundamentals of event streaming
Stateless and stateful stream processing
Advanced courses on stream processing and cluster operations
New courses added regularly
System Design Interview: The step-by-step guide
We have helped over 100,000 engineers level up their system design skills in the past few years.
Here is a simple but powerful, step-by-step framework we put together to help you crack system design interviews.
The Framework:
Step 1 - Understand the problem and establish the design scope
Step 2 - Propose high-level design and get buy-in
Step 3 - Design deep dive
Step 4 - Wrap up
In this 10 minutes video, we go deeper into each step:
- Why do we need a framework
- What to focus on
- How to discuss trade-offs
- Dos and Don'ts
- Common mistakes to avoid
Why is Redis so fast?
The diagram below shows 3 main reasons:
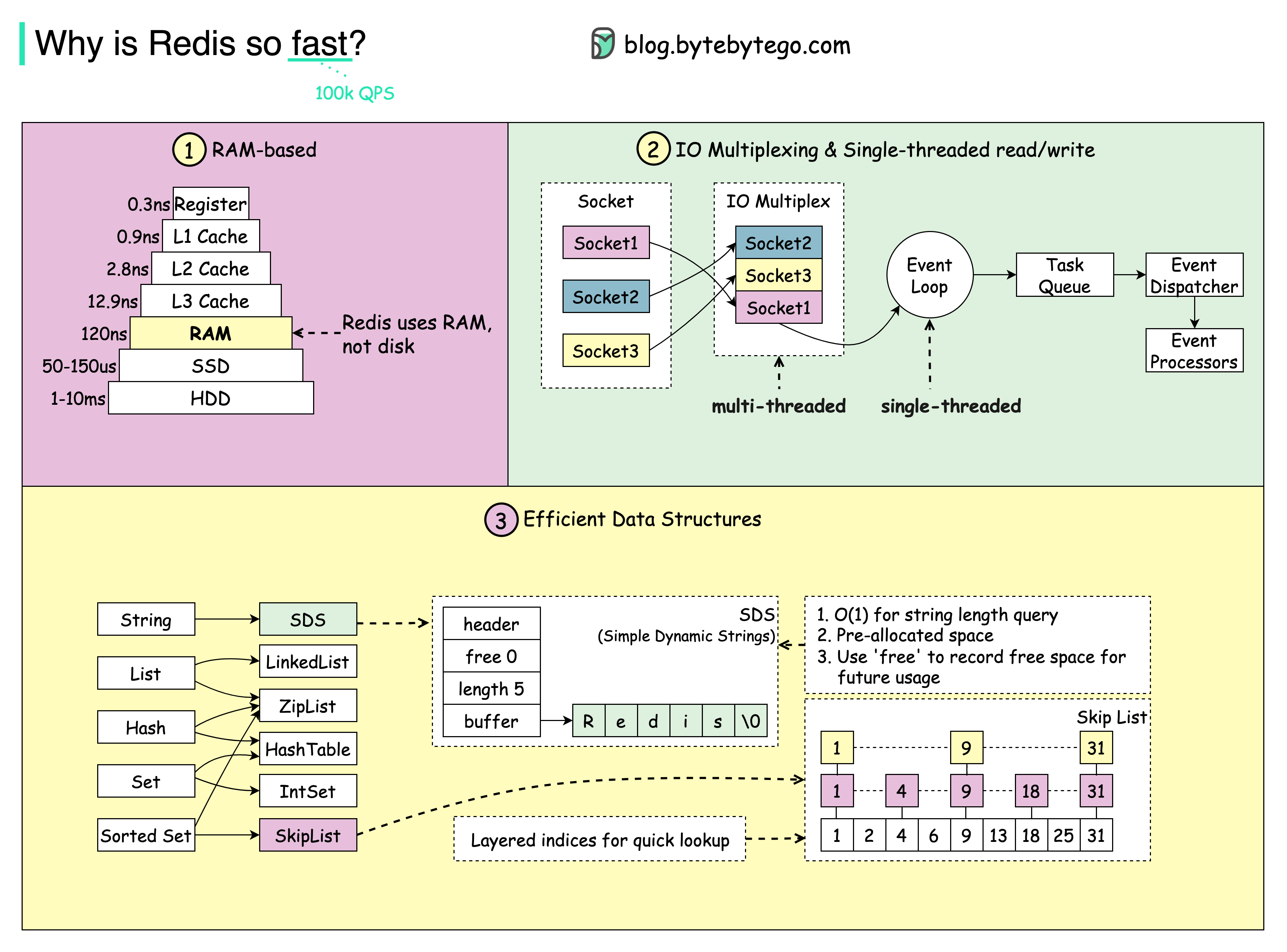
1️⃣ Redis is RAM-based. Access to RAM is at least 1000 times faster than access to random disks. Redis can be used as a cache to improve application responsiveness and reduce database load when used as a cache.
2️⃣ Redis implements IO multiplexing and single-threaded execution.
3️⃣ A number of efficient lower-level data structures are leveraged by Redis. By keeping these data structures in memory, serialization and deserialization costs are reduced.
SortedSet, for example, makes the implementation of leaderboards so simple and efficient. On the other hand, a bitmap can be used to aggregate month-over-month login statuses.
👉 Over to you: What do you use Redis for in your projects?
Things to consider when using cache
Caching is one of the 𝐦𝐨𝐬𝐭 𝐜𝐨𝐦𝐦𝐨𝐧𝐥𝐲 used techniques when building fast online systems. When using a cache, here are the top 5 things to consider:
The first version of the cheatsheet was written by guest author Love Sharma.
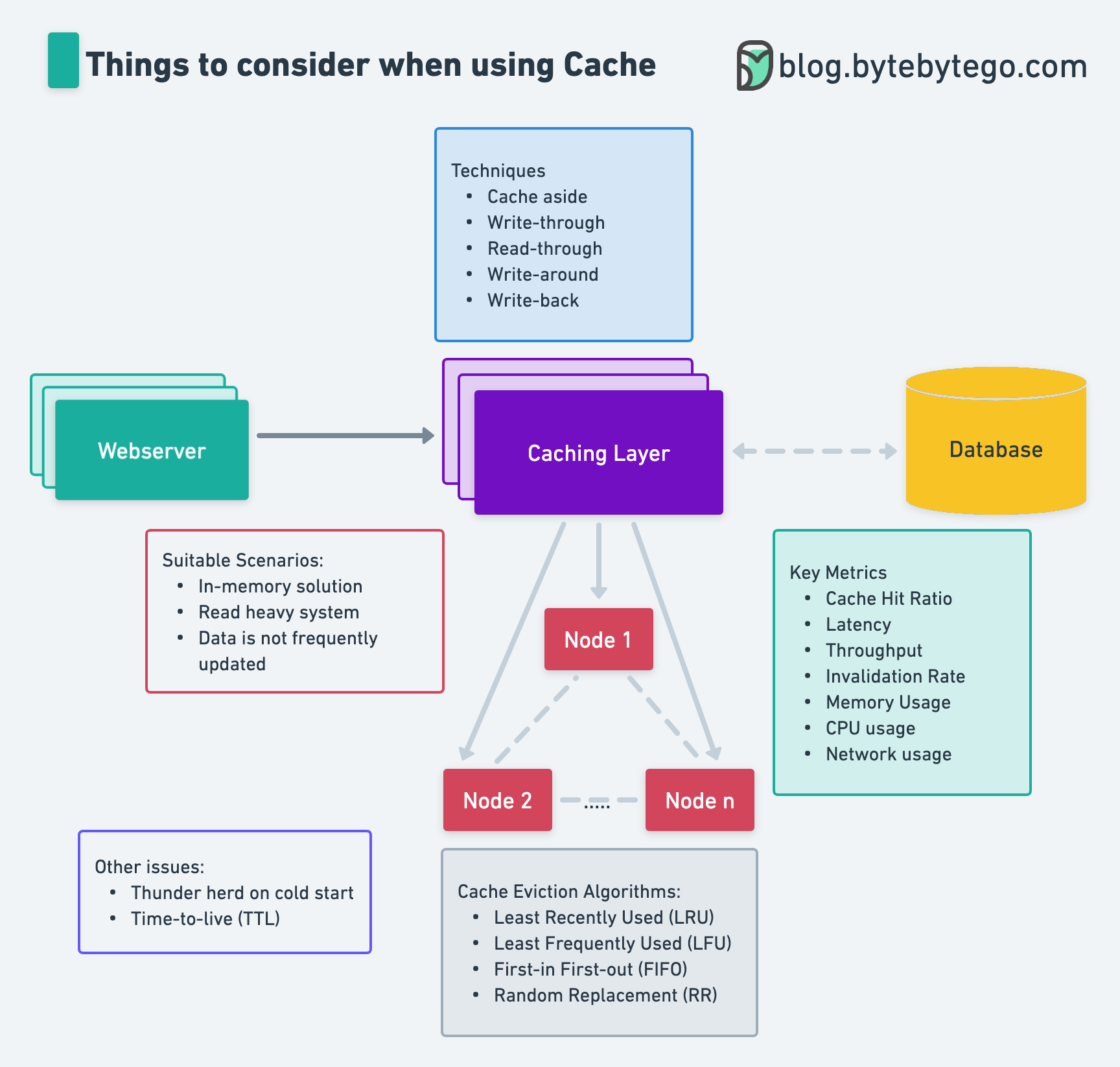
𝐒𝐮𝐢𝐭𝐚𝐛𝐥𝐞 𝐒𝐜𝐞𝐧𝐚𝐫𝐢𝐨𝐬:
- In-memory solution
- Read heavy system
- Data is not frequently updated
𝐂𝐚𝐜𝐡𝐢𝐧𝐠 𝐓𝐞𝐜𝐡𝐧𝐢𝐪𝐮𝐞𝐬:
- Cache aside
- Write-through
- Read-through
- Write-around
- Write-back
𝐂𝐚𝐜𝐡𝐞 𝐄𝐯𝐢𝐜𝐭𝐢𝐨𝐧 𝐀𝐥𝐠𝐨𝐫𝐢𝐭𝐡𝐦𝐬:
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
- First-in First-out (FIFO)
- Random Replacement (RR)
𝐊𝐞𝐲 𝐌𝐞𝐭𝐫𝐢𝐜𝐬:
- Cache Hit Ratio
- Latency
- Throughput
- Invalidation Rate
- Memory Usage
- CPU usage
- Network usage
𝐎𝐭𝐡𝐞𝐫 𝐢𝐬𝐬𝐮𝐞𝐬:
- Thunder herd on cold start
- Time-to-live (TTL)
Over to you - Did we miss anything important?
Git Workflow & Immutability
Immutability here means that once data is written into Git, it cannot be changed. Modifications only create new data versions. The old data remains unchanged.
Immutable system designs are commonly used in systems that require high levels of auditability, such as financial systems and version control systems. Here's how it's used in Git design:
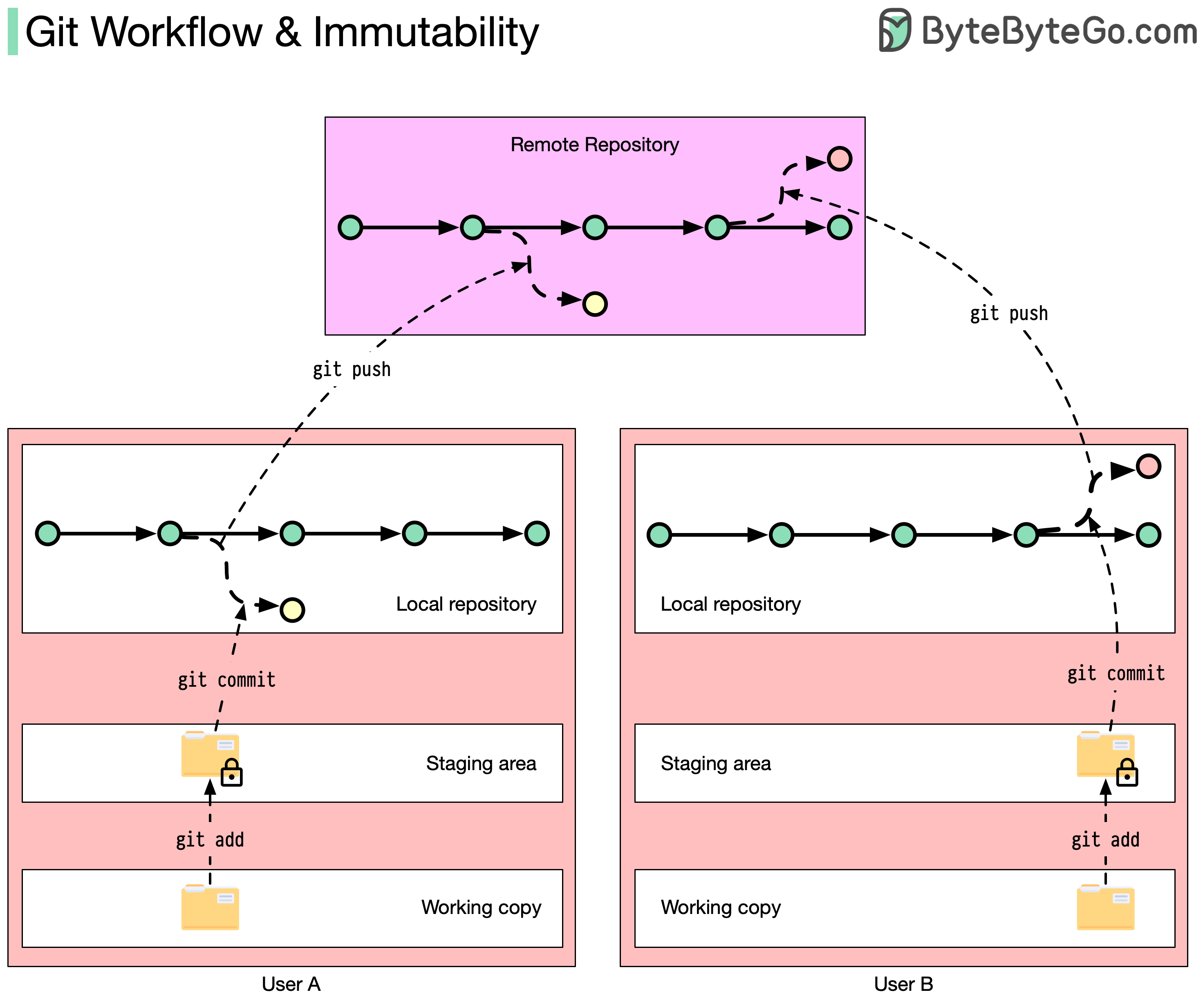
🔹Users' local Git storage consists of three sections: working copy, staging area, and local repository.
🔹Working copies contain the files you are currently working on. The data is mutable, so you can do whatever you want with it
🔹When you type "git add", your files will be added to the staging area. These files are now immutable. It is no longer possible to edit them
🔹When you type "git commit", your staging files are added to the local repository. Local repository is a tree version of the append-only write-ahead log (WAL). They are both immutable: you can only append to the end of the data structure.
🔹When you type "git push", your local repository data will be synced to the remote repository. As the remote repository uses the same data structure as your local repository, it is also immutable: you can only add data to it
👉 Over to you: there are two ways to save the history of a file: either save every version of the file, or save every delta change to the file and reconstruct the file by aggregating all delta changes. Would you recommend Git using one over another, and why?
ChatGPT, Jasper AI, Copy AI: How are AI writers different?
The diagram below shows how we can use popular AI writers.

In general, the tools cover the workflow of copywriting and content creation. They can choose topics, write content and optimize the content.
For example, we can first use SurferSEO to extract keywords and topics and then use Jasper or writesonic to generate marketing content.
If we want to customize the tone for different audiences, we can use wordtune to paraphrase the articles.
ChatGPT-like AI writers gain so much popularity because AI tools finally generate revenue!
👉 Over to you: Will you use AI writers to help you with daily work and how?
Did you mean to say OpenAI instead of ChatGPT?
As far as I know, OpenAI (founded in 2015) is the technology under all of the AI tools and ChatGPT (released 2022) is a tool from OpenAI built on top of the OpenAI API.
Hi Alex, is ByteByteGo episode 45 missing? Thanks!