
Facebook’s Database Handling Billions of Messages (Apache Cassandra® Deep Dive)

Google’s 7 predictions on AI, LLM, and Observability (Sponsored)

Read the 7 key takeaways from Google’s Director of AI and Datadog’s VP of Engineering as they break down their predictions of the future:
Smarter AI and LLM strategies for your org
Building customer trust in AI outputs
Scaling your tooling as LLM expertise grows
Disclaimer: The details in this post have been derived from Apache Cassandra® Research Paper and other sources. All credit for the technical details goes to the Facebook engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Apache Cassandra® is a powerful database system designed to store and manage massive amounts of data across many computers.
Facebook originally developed it to support a feature called Inbox Search, which allows users to quickly search through their messages. The goal was to support billions of messages sent by Facebook users every day.
Storing and efficiently searching through such a massive amount of data is a big challenge. Traditional databases, like MySQL, struggled to handle this workload because they were not designed to scale easily.
To solve this, Facebook engineers took inspiration from two existing technologies:
Amazon Dynamo: A system that makes sure data is always available, even if some nodes fail. It does this by copying data to multiple machines and using a peer-to-peer structure where every node (computer) is equal.
Google Bigtable: A database used by Google to store large amounts of structured data efficiently. It introduced the idea of a column-based storage model, which makes it faster to access specific pieces of data.

By combining the best parts of these two systems, Facebook created Apache Cassandra®, which became a decentralized, highly scalable, and fault-tolerant database. Later, it was released as open-source software, allowing companies like Netflix, Twitter, and Apple to use and improve it.
In this article, we’ll take a deep dive into Apache Cassandra® and understand what makes it special.
The Key Features of Apache Cassandra®
Some key features of Apache Cassandra® are as follows:
Distributed Storage: Data is spread across many machines instead of being stored on a single server.
High Availability: Even if some machines fail, Apache Cassandra® continues to work without interruption.
No Single Point of Failure: Since there is no central control system, there is no weak spot that can bring everything down.
Scalability: It can easily handle increasing amounts of data by simply adding more machines to the network.
Setting targets for developer productivity metrics — March 24th (Sponsored)

Setting targets for developer productivity metrics takes careful consideration: we need to think through the potential tradeoffs or incentives created (hello Goodhart's law!), whether the targets are realistic, and which goals are appropriate at different levels of the organization. Join Abi Noda and Laura Tacho, DX CEO and CTO, for a discussion about how to properly set targets for productivity metrics so you can continue to push for improvement and accountability from your own teams.
Join this discussion to learn:
How to think about potential pitfalls, like Goodhart’s Law and Campbell’s Law
How to set goals at different levels: frontline team, group, and organization level
Real-world examples of good and bad approaches to setting goals and targets for productivity metrics
Apache Cassandra®’s Data Model
Apache Cassandra®’s data model is quite different from traditional relational databases like MySQL.
At its core, Apache Cassandra®’s data model is like a multi-dimensional map (or dictionary), where each piece of data is indexed by a row key. This means that instead of rigidly defining tables and columns in advance, data can be stored in a way that best suits the needs of the application.
The data is organized into column families that are of two types:
Simple Column Family: It is a collection of standard key-value pairs where each key points to a set of columns. For example, if storing user information, the row key could be the User ID, and the columns could be name, email, phone number, etc.
Super Column Family: It is a more complex, nested structure that groups multiple columns under a "Super Column." This allows hierarchical data organization. For example, if storing a user’s messages, the row key could be User ID. Super Columns could be different conversations, and within each Super Column, individual messages could be stored.

Columns can be sorted by timestamp or name, depending on the application’s needs. Primary key lookup is the main way to retrieve data. Instead of running complex queries like in SQL databases, Apache Cassandra® retrieves data by directly accessing the row key.
The structure of a column consists of the following parts:
Name: The identifier for the column.
Value: The actual data stored in the column.
Timestamp: A timestamp that records when the data was written, helping in managing updates and conflict resolution.
Apache Cassandra® API Overview
Apache Cassandra® follows a key-based lookup approach, meaning every operation revolves around the row key. Unlike relational databases that support complex queries (like JOINs or subqueries), Apache Cassandra® prioritizes speed and scalability by keeping its API lightweight.
Therefore, Apache Cassandra® provides a simple API structure that allows applications to interact with the database using three main operations.
1 - Insert Data
The interface is insert(table, key, rowMutation). This command adds new data to Apache Cassandra®.
The “table” is where the data will be stored and the “key” uniquely identifies the row. The rowMutation represents the changes made to the row, such as adding new columns or updating existing ones.
2 - Retrieve Data
The API interface is get(table, key, columnName). It fetches data from the database.
The “table” specifies where to look and the “key” identifies which row to retrieve. The “columnName” specifies which part of the row is needed.
3 - Delete Data
The interface is delete(table, key, columnName).
This command removes data from the database. It can delete an entire row or just a specific column within a row.
Apache Cassandra® System Architecture
Apache Cassandra® is designed as a highly scalable and fault-tolerant distributed database.
It does not rely on a single central server but instead follows a peer-to-peer model, where all nodes in the system are equal.
Apache Cassandra® organizes its nodes (servers) in a ring structure. Each piece of data is assigned to a node using consistent hashing, which ensures even distribution across all nodes. When new nodes are added, Apache Cassandra® automatically rebalances the data without requiring a complete reorganization.
See the diagram below that shows how consistent hashing works.
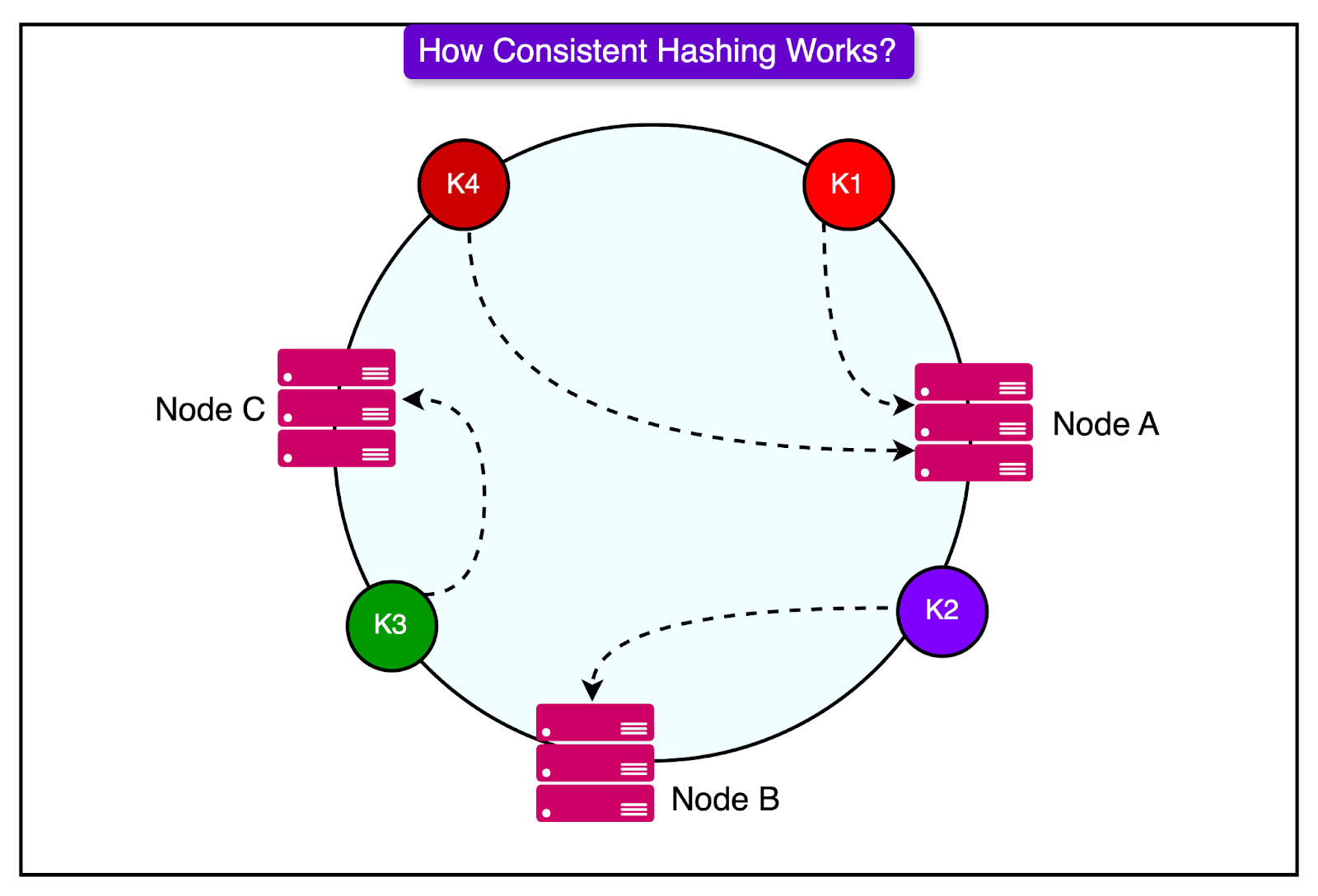
There is no master node, meaning any node can handle read and write requests. Since all nodes are equal, there is no single point of failure. If a node fails, other nodes in the system can continue handling requests without disruption.
Replication Mechanisms
Apache Cassandra® ensures that data is copied across multiple nodes to prevent data loss and improve availability. Developers can choose between different replication strategies:
Rack-Unaware Replication: Data is copied to N-1 successor nodes in the ring, meaning if one node goes down, its neighbors still have a copy. This method works well for small-scale deployments but does not account for hardware or network failures across different locations.
Rack-Aware Replication: Uses Zookeeper, a coordination service, to manage which nodes store replicas. This ensures that data copies are distributed across different racks (physical groupings of servers) in a data center.
Datacenter-Aware Replication: Distributes data copies across multiple data centers to ensure high availability even if an entire data center goes offline.
Gossip Protocols in Apache Cassandra®
Apache Cassandra® uses a gossip protocol to allow nodes (servers) in the system to communicate with each other efficiently.
This protocol is inspired by how rumors spread in real life. Instead of requiring a central system to keep track of everything, information is passed from one node to another in small, periodic updates.
Gossip protocols are great because they have a low network overhead. Instead of flooding the system with updates, nodes exchange small bits of information at regular intervals. Even if some nodes go offline, others can still function because they share information across the network.
Apache Cassandra® uses Scuttlebutt, a specialized Gossip Protocol, to keep track of which nodes are active or inactive. Each node periodically exchanges information about itself and other nodes with its neighbors, ensuring that the entire cluster remains up to date.
Instead of a simple "up or down" status, Apache Cassandra® assigns a suspicion level to each node.
If a node stops responding, its suspicion value starts increasing over time.
If the value crosses a certain threshold, the system considers the node as "dead" and reroutes traffic to other nodes.
In other words, Apache Cassandra®’s failure detection is probabilistic, meaning it adapts to network conditions instead of rigid timeout rules. This helps prevent false alarms caused by temporary delays or slow responses.
Query Execution in Apache Cassandra®
Apache Cassandra® is designed to handle high-speed data writes and efficient reads while ensuring durability and fault tolerance.
Instead of storing data like traditional relational databases, which write changes immediately to disk, Apache Cassandra® follows a log-structured storage model that optimizes speed and reliability.
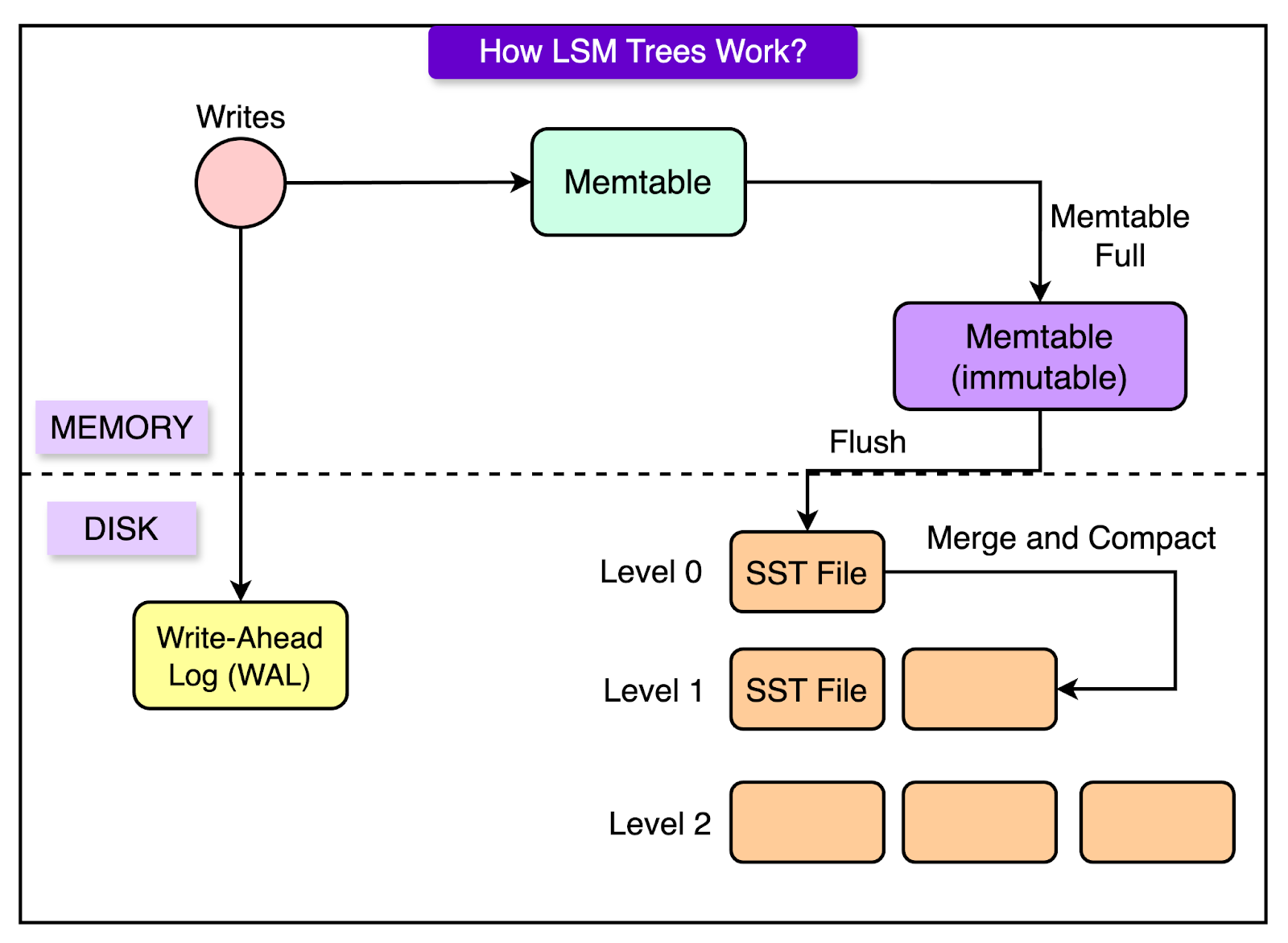
How Apache Cassandra® Handles Writes?
Apache Cassandra® follows a multi-step process when writing data. The process consists of three main components:
Commit Log (Disk): Every time data is written to Apache Cassandra®, it is first recorded in the Commit Log. The Commit Log is stored on disk and ensures that data is not lost even if the system crashes before it is fully processed. This step makes Apache Cassandra® fault-tolerant.
Memtable (RAM): After writing to the Commit Log, the data is stored in memory in a structure called the Memtable. The Memtable acts as a temporary, in-memory cache for fast access. Because reading from RAM is faster than reading from disk, this speeds up query performance.
SSTables (Disk): When the Memtable reaches a certain size, it is flushed to disk as an SSTable (Sorted String Table). SSTables are immutable, meaning they are never modified after being written. Instead of updating existing files, Apache Cassandra® writes new SSTables and merges them later through a compaction process to optimize storage.

This write process is efficient because, unlike traditional databases that modify data in place (causing random disk writes), Apache Cassandra® writes data sequentially, which is much faster and more efficient. Since SSTables are never modified, Apache Cassandra® avoids the overhead of complex locking mechanisms found in relational databases. Also, Apache Cassandra® can recover lost data if a node crashes because every write is first recorded in the Commit Log.
How Apache Cassandra® Handles Reads?
Unlike traditional databases that rely on complex indexing, Apache Cassandra® optimizes read performance using a combination of in-memory lookups and efficient disk scans.
Here’s a step-by-step look at the read process:
Check Memtable: When a read request comes in, Apache Cassandra® first checks the Memtable because it contains the most recent data. If the data is found in the Memtable, the result is returned immediately, making the read extremely fast.
Check SSTables on Disk: If the requested data is not in the Memtable, Apache Cassandra® searches for it in the SSTables stored on disk. Since SSTables are never updated, multiple versions of a row may exist in different SSTables, so Apache Cassandra® must scan multiple files.
Use Bloom Filters: To improve efficiency, Apache Cassandra® uses Bloom Filters, which are probabilistic data structures that help quickly determine if an SSTable might contain the requested data. If the Bloom Filter suggests that an SSTable does not contain the data, Apache Cassandra® skips that file entirely, reducing the number of disk reads. If the Bloom Filter indicates that an SSTable might contain the data, Apache Cassandra® checks the file for the requested row.
Merge and Return Most Recent Data: Since Apache Cassandra® writes new SSTables instead of modifying existing ones, multiple versions of a row might exist across different SSTables. The system merges all versions of the row, applying the latest updates based on timestamps, and returns the final result to the client.
Facebook Inbox Search Use Case
As mentioned, Apache Cassandra® was originally developed at Facebook to solve the challenge of storing and searching billions of messages efficiently. Before Apache Cassandra®, Facebook used MySQL for storing these messages, but as the platform grew, MySQL struggled to handle the increasing volume of data and high query load.
To address this, Facebook deployed Apache Cassandra® on a 150-node cluster, which stored over 50 terabytes (TB) of messages. The system needed to support fast and scalable searches while handling constant write operations as users sent and received messages.
Facebook’s Inbox Search allows users to find messages using two types of queries:
Term Search (Keyword-Based Search): It allows users to search for messages that contain specific words or phrases. For example, if a user searches for "project update," Apache Cassandra® retrieves all messages containing those words. The system stores word-to-message mappings using Super Column Families, where the row key is the user ID, the super columns are the words and the sub-columns store message IDs that contain those words.
Interaction Search (User-Based Search): It allows users to find messages exchanged with a specific person. For example, if a user searches for "Alice," Apache Cassandra® retrieves all messages exchanged between the user and Alice. This is implemented using another Super Column Family, where the row key is the user ID, the super columns are the contacts, and the sub-columns contain the message IDs exchanged with that contact.

One of the biggest challenges in Facebook’s messaging system was ensuring low-latency searches across a massive dataset. Apache Cassandra®’s highly optimized architecture allowed it to achieve impressive performance:
Minimum Latency: As low as 7-8 milliseconds, meaning some searches return almost instantly.
Median Latency: Around 15-18 milliseconds, ensuring consistently fast responses for most queries.
Maximum Latency: In worst-case scenarios, searches could take up to 44 milliseconds, which is still very fast given the large dataset.
Join the NVIDIA GTC Event (Virtual GTC is Free!) [Sponsored]

Join your fellow engineers at GTC25 in San Jose, California (March 17-21). This flagship event by NVIDIA is bringing you more than 1000 session, 400+ exhibits, technical hands-on training, and tons of unique networking events.
Conclusion
Apache Cassandra® is a highly scalable, distributed database system designed to handle large volumes of data while ensuring fault tolerance and high availability.
Its peer-to-peer architecture and ring-based design make it particularly well-suited for applications that require continuous uptime and seamless scaling across multiple data centers. One of Apache Cassandra®’s key strengths is its ability to handle high write-throughput efficiently, making it ideal for real-time applications, such as messaging platforms, recommendation systems, and IoT data storage.
However, Apache Cassandra® is not a replacement for traditional relational databases. It is not optimized for complex queries, joins, or transactional consistency, which makes it less suitable for applications requiring strong relational integrity.
For businesses and developers building large-scale, distributed systems, Apache Cassandra®provides a robust, flexible, and highly available solution that can grow with demand while maintaining performance and reliability.
Note: Apache Cassandra® is a registered trademark of the Apache Software Foundation.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
This is very outdated for a 2025 post. Super Column is no longer a thing, Cassandra now supports composite keys: https://issues.apache.org/jira/browse/CASSANDRA-3237
Nice article