Factors to Consider in Database Selection

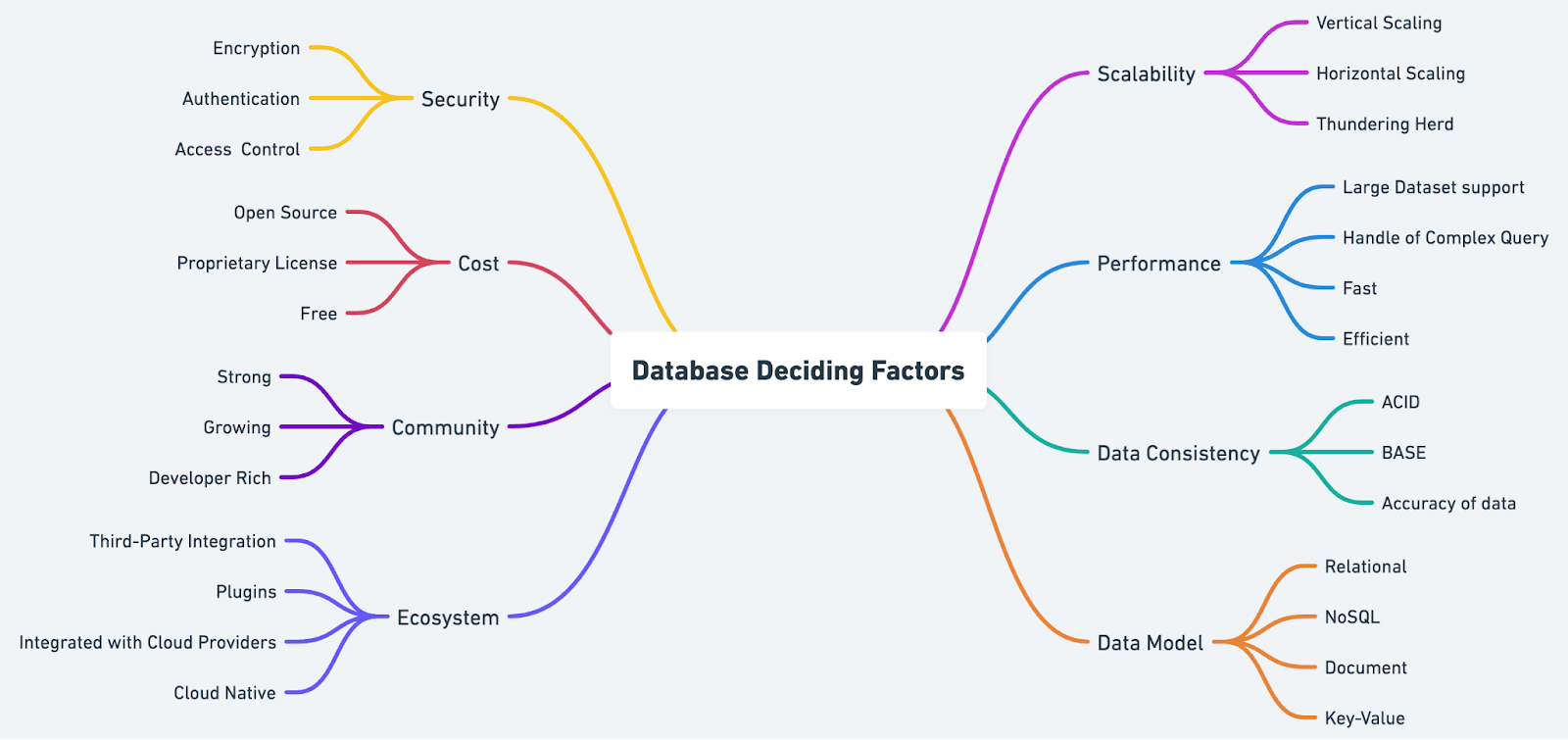
In the first part of our series, we laid the foundation for understanding the various types of databases and their use cases. As we continue to explore the art of database selection, we will now dive deeper into the critical factors that influence this decision-making process. By examining each factor in greater detail, we can better equip ourselves to make informed choices that align with our project requirements and drive the success of our software development projects.
Scalability
Scalability is a critical aspect of any database. It determines how well the system can accommodate growth. Two primary methods of scaling exist: vertical and horizontal. Vertical scaling involves increasing the capacity of a single server by adding resources such as memory or CPU. Horizontal scaling, on the other hand, involves adding more servers to the system.

Different database types handle scaling in various ways. For instance, relational databases can struggle with horizontal scaling, while NoSQL databases often excel in this area. When selecting a database, consider the expected growth of the project and how well the database can handle such expansion.
To evaluate a database's scalability, we must first understand its architecture and design principles. Relational databases, for example, store data in tables with a predefined schema, and they may struggle to scale horizontally due to the need to maintain consistency across multiple servers. This challenge can lead to performance bottlenecks when dealing with large amounts of data or high-traffic workloads.
NoSQL databases, on the other hand, were designed with scalability in mind. They employ various strategies, such as sharding and partitioning, to distribute data across multiple servers. This approach allows for more efficient horizontal scaling and can better handle growing data volumes and traffic loads. However, NoSQL databases may sacrifice some level of data consistency to achieve this scalability.
NewSQL databases aim to combine the best of both worlds by offering the scalability of NoSQL databases and the transactional consistency of relational databases. These databases employ innovative architectures and techniques to distribute data and maintain consistency across multiple servers. It enables efficient horizontal scaling without compromising on consistency. However, there are drawbacks to consider. NewSQL databases may lack the maturity of traditional systems, leading to limited community support and resources. Their complexity can create a steeper learning curve for developers, increasing the time and effort needed for implementation and maintenance.
Time-series databases, designed for handling time-based data, can also scale well as the volume of data grows. They use specialized indexing and compression techniques to efficiently store and query large volumes of time-series data, making them an ideal choice for applications that generate a high volume of time-stamped information, such as IoT or monitoring systems.
When selecting a database, consider the expected growth of the project and how well the database can handle such expansion. Assess the database's ability to scale vertically or horizontally, and evaluate its performance under increasing data volumes and traffic loads.
Performance
Performance is another essential factor in choosing a database. It directly impacts the user experience. Query efficiency and the balance between read and write performance should be considered. Some databases may be optimized for read-heavy workloads, while others may prioritize write performance. Understanding your project's specific performance requirements will help you identify the most suitable database type.
To evaluate a database's performance, we should start by examining its query efficiency. Relational databases usually provide efficient querying capabilities due to their structured schema and support for SQL. Their performance is often optimized for complex queries involving joins and aggregations. However, as data volume and complexity increase, query performance may degrade, especially when dealing with large datasets.
NoSQL databases, on the other hand, can offer faster write speeds due to their simpler data models and more flexible schemas. This performance advantage can be particularly beneficial in scenarios where data is constantly being generated and updated, such as streaming applications or real-time analytics. However, NoSQL databases may not be as efficient when it comes to complex queries or aggregations, as they lack the same level of support for SQL and structured schemas.
NewSQL databases aim to provide both efficient querying capabilities and high write performance by combining the strengths of relational and NoSQL databases. They often employ innovative techniques, such as distributed query processing and advanced indexing, to deliver high-performance querying and write capabilities. As a result, NewSQL databases can be a good choice for applications that require both complex querying and high write performance.
Time-series databases are designed for handling time-based data, and their performance is optimized for this specific use case. They employ specialized indexing and compression techniques to efficiently store and query large volumes of time-series data. This focus on time-based data allows time-series databases to deliver high performance for applications that generate a high volume of time-stamped information, such as IoT or monitoring systems.
When selecting a database, it is crucial to understand the performance requirements of the project. This will directly impact the user experience. Consider the balance between read and write performance, as well as the efficiency of query processing. By carefully evaluating the performance characteristics of different database types in the context of the project's needs, we can choose a database that will deliver the optimal user experience and support the success of the application.
Data Consistency
Data consistency ensures that the information in the database remains accurate and up-to-date. To achieve consistency, databases often rely on the ACID properties (Atomicity, Consistency, Isolation, and Durability) and the CAP theorem (Consistency, Availability, and Partition tolerance). Different databases prioritize these aspects differently, resulting in various consistency levels.
To assess a database's approach to data consistency, we should begin by examining its adherence to the ACID properties. Relational databases typically emphasize strong consistency. It ensures that every transaction maintains the integrity of the data. They achieve this by implementing the ACID properties, which specify that transactions are atomic, consistent, isolated, and durable.
The CAP theorem states that a distributed database system can only achieve two out of the three properties: consistency, availability, and partition tolerance. This theorem highlights the trade-offs that databases must make when it comes to consistency, and it can be a useful tool for understanding the consistency model of various database types.

While the CAP theorem is well-known, a better mental model to follow when evaluating a database is the PACELC theorem. The PACELC theorem states that if a system is Partition tolerant, it must choose between Availability and Consistency during a network partition and between Latency and Consistency when the network is operating normally. This theorem highlights the trade-offs that databases must make when it comes to consistency and can be a useful tool for understanding the consistency model of various database types.
NoSQL databases often lean towards eventual consistency. Updates to the data will eventually propagate across all nodes in the system, but they may not be immediately visible. This approach allows for higher availability and better performance in distributed systems, but it can result in temporary inconsistencies between nodes.

When selecting a database, consider the importance of consistency in the project and how it might impact the user experience. For some applications, such as financial transactions, strong consistency is essential to ensure data integrity and avoid errors. In contrast, for other applications, like social media feeds or search indexes, eventual consistency may be sufficient, as temporary inconsistencies are less likely to negatively impact the user experience.
It is crucial to understand the trade-offs between consistency, availability, and partition tolerance when selecting a database. By carefully considering the consistency requirements of the project and evaluating the consistency models of different database types, we can choose a database that meets the needs while providing the best possible user experience.
Data Model
The data model of a database is another critical factor to consider when selecting a database. It defines how data is structured, stored, and queried. Factors such as schema flexibility and support for complex data relationships should be taken into account when evaluating a database's data model.
Relational databases use a fixed schema. It enforces a consistent structure across all records. This schema can be beneficial for ensuring data integrity. It prevents the insertion of data that does not conform to the specified structure. However, it can also be a limitation when dealing with diverse or rapidly changing data, as schema changes can be time-consuming and may require downtime.