
From 0 to Millions: A Guide to Scaling Your App - Part 1

In this four-part series, we'll discuss a typical architectural evolution of a website/app, and how/why we make technical choices at different stages.
Do we build a monolithic application at the beginning?
When do we add a cache?
When do we add a full-text search engine?
Why do we need a message queue?
When do we use a cluster?
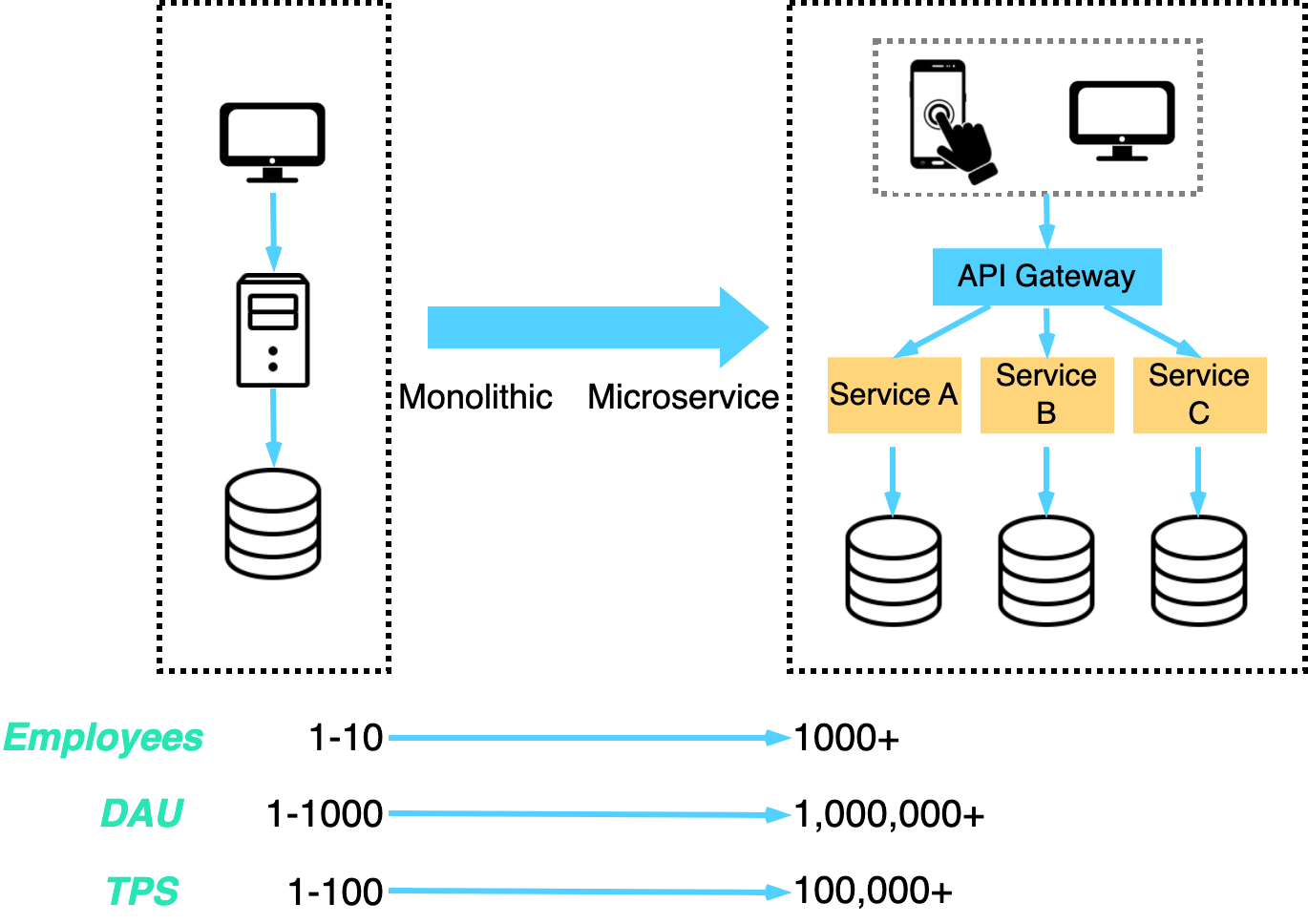
In the first two segments, we examine the traditional approach to building an application, starting with a single server and concluding with a cluster of servers capable of handling millions of daily active users. The basic principles are still relevant.
In the final two segments, we examine the impact of recent trends in cloud and serverless computing on application building, how they change the way we build applications, and provide insights on how to consider these modern approaches when creating your next big hit.
Let’s examine how a typical startup used to build its first application. This basic approach was common up until about 5 years ago. Now with serverless computing, it is much easier to start an application that could scale to tens of thousands of users with very little upfront investment. We will talk about how we should take advantage of this trend later in the series.
For now, we will dive into how an application (Llama) is traditionally built at the start. This lays a firm foundation for the rest of our discussion.
Llama 1.0 - Monolithic Application, Single Server
In this first architecture, the entire application stack lives on a single server.
The server is publicly accessible over the Internet. It provides a RESTful API to handle the business logic and for the mobile and web client applications to access. It serves static contents like images and application bundles that are stored directly on the local disk of the server. The application server is connected to the database which also runs on the same server.

With the architecture, it could probably serve hundreds, maybe even thousands, of users. The actual capacity depends on the complexity of the application itself.
When the server begins to struggle with a growing user load, one way to buy a bit more time is to scale up to a larger server with more CPU, memory, and disk space. This is a temporary solution, and eventually, even the biggest server will reach its limit.
Additionally, this simple architecture has significant drawbacks for production use. With the entire stack running on a single server, there is no failover or redundancy. When the server inevitably goes down, the resulting downtime could be unacceptably long.
As the architecture evolves, we will discover how to solve these operational issues.
