
How Agentic RAG Works?

The hidden reality of AI-Driven development (Sponsored)

There is a new “velocity tax” in software development. As AI adoption grows, your teams aren’t necessarily working less—they are spending 25% of their week fixing and securing AI-generated code. This hidden cost creates a verification bottleneck that stalls innovation. Sonar provides the automated, trusted analysis needed to bridge the gap between AI speed and production-grade quality.
The main problem with standard RAG systems isn’t the retrieval or the generation. It’s that nothing sits in the middle deciding whether the retrieval was actually good enough before the generation happens.
Standard RAG is a pipeline where information flows in one direction, from query to retrieval to response, with no checkpoint and no second chance. This works fine for simple questions with obvious answers.
However, the moment a query gets ambiguous, or the answer is spread across multiple documents, or the first retrieval pulls back something that looks good but isn’t, RAG starts losing value.
Agentic RAG attempts to fix this problem. It is based on a single question: what if the system could pause and think before answering?
In this article, we will look at how agentic RAG works, how it improves upon standard RAG, and the trade-offs that should be considered.
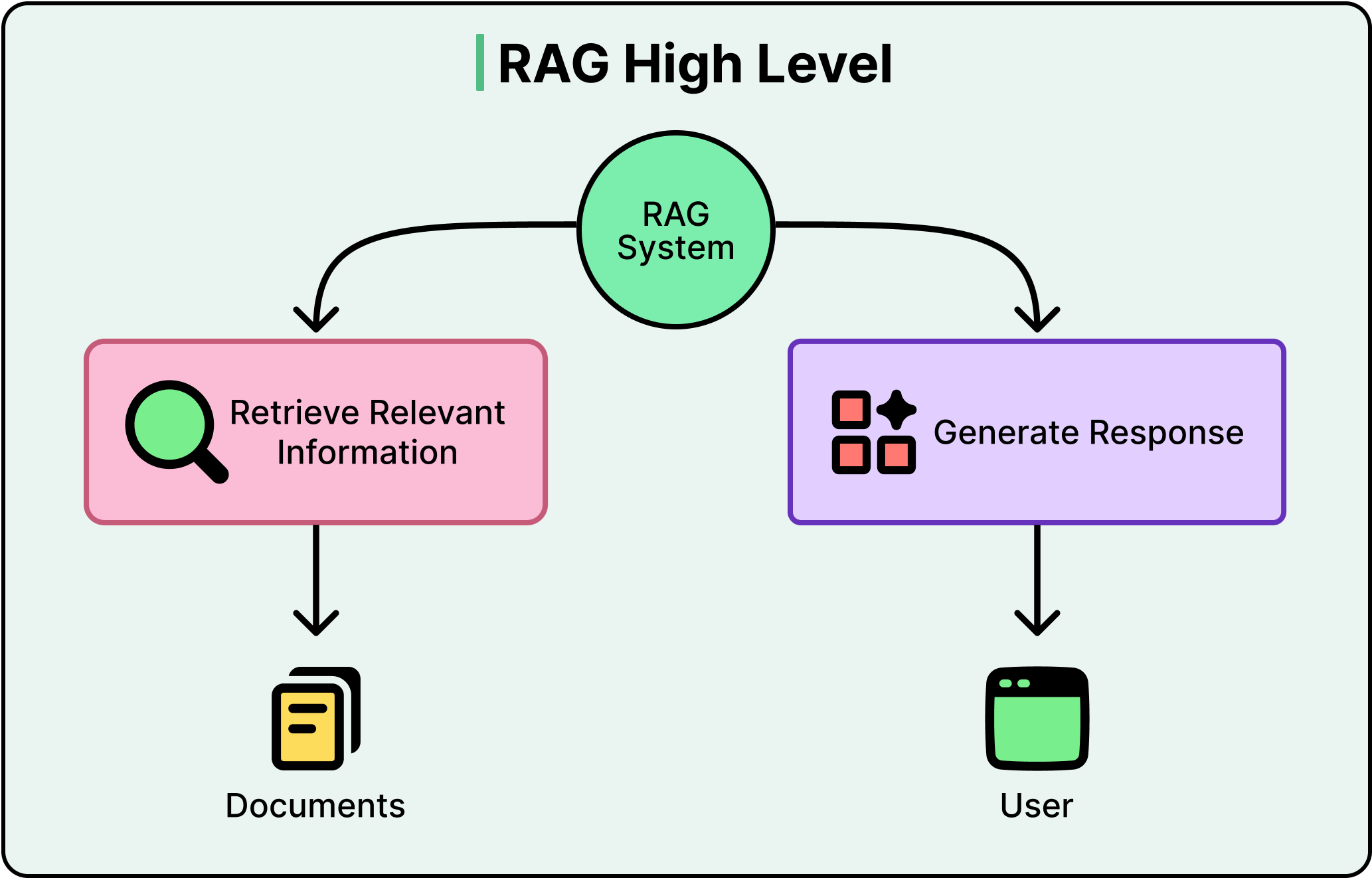
One Query and One Retrieval
To understand what Agentic RAG fixes, we need to be clear about how standard RAG works and where it falls short.
A standard RAG pipeline has a straightforward flow:
A user asks a question.
The system converts that question into a numerical representation called an embedding, which captures the semantic meaning of the query.
It then searches a vector database, a database optimized for finding content with similar meaning, and retrieves the top matching chunks of text.
Those chunks get passed to a large language model along with the original question, and the LLM generates an answer grounded in the retrieved context.
See the diagram below:
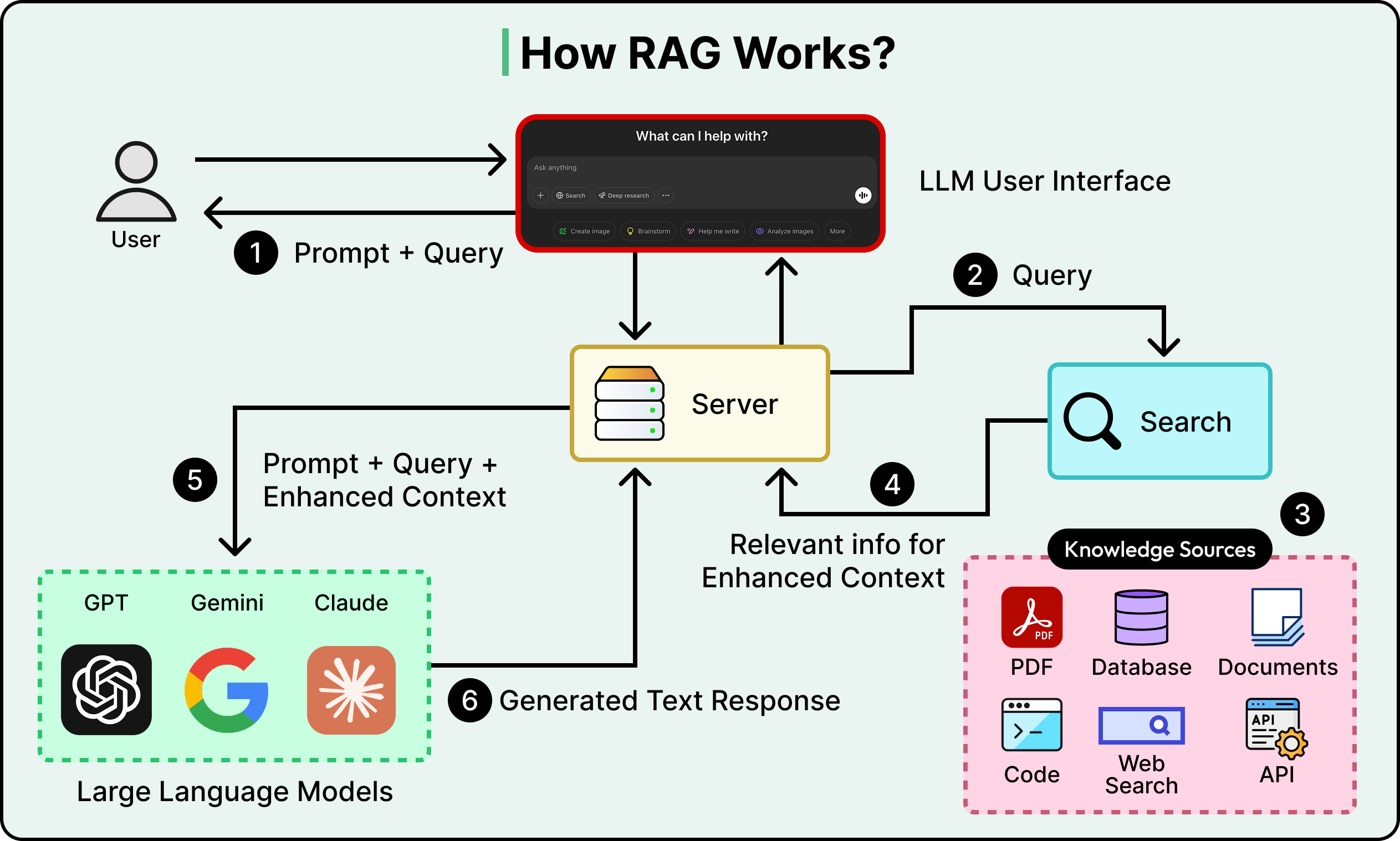
The diagram below shows what embeddings typically look like:
This works extremely well for direct and unambiguous questions against a well-organized knowledge base. Think of questions like “What’s our return policy?” A clean documentation corpus will get a solid answer almost every time.
Here’s how typical query flow looks like:
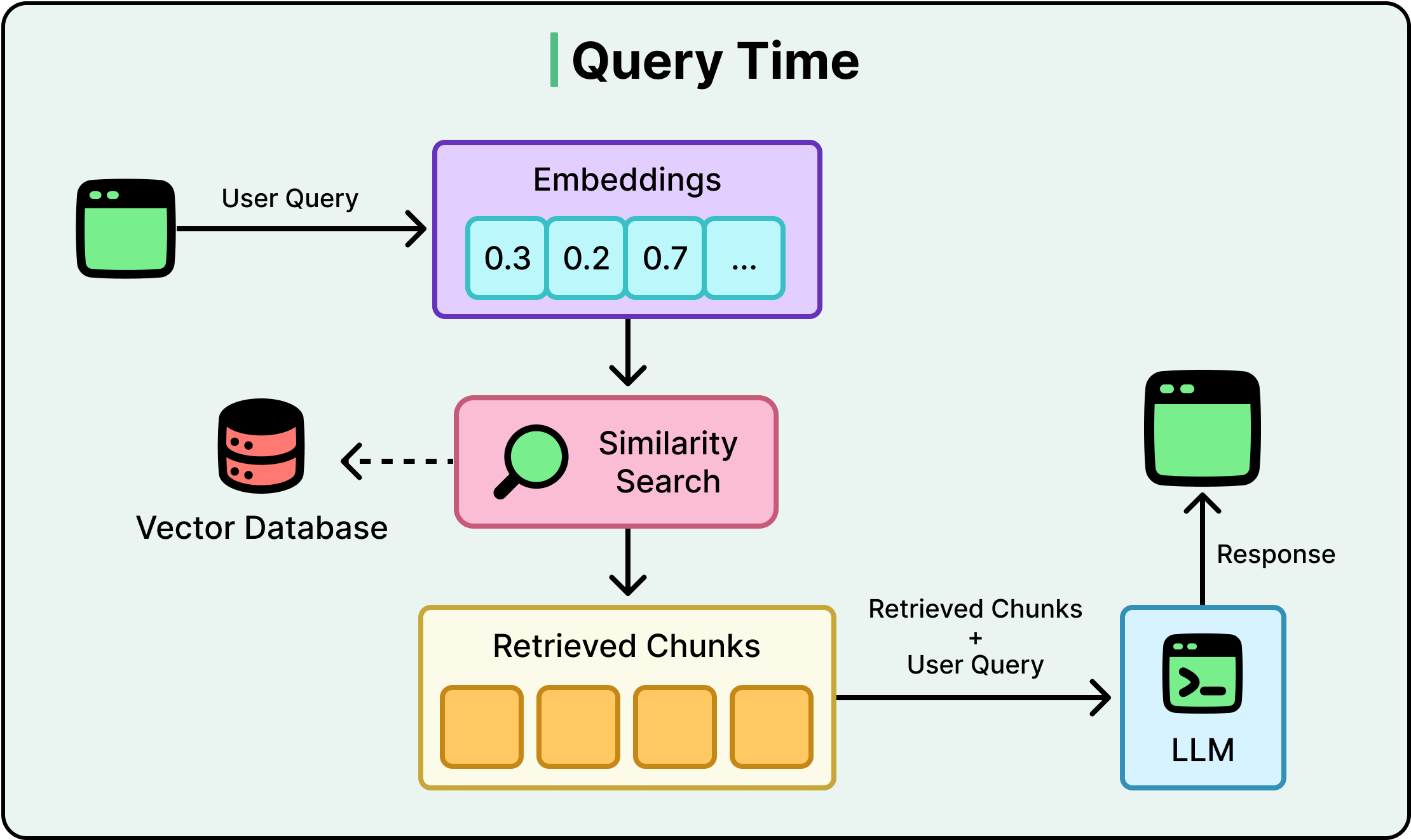
The problems show up when queries get more complex. Here are a few scenarios:
Ambiguous queries: When a user asks, “How do I handle taxes?” they could mean personal income taxes, business taxes, or tax-exempt status for a nonprofit. Standard RAG can’t clarify or rewrite. It takes the query as-is, retrieves whatever scores highest on similarity, and hopes for the best.
Scattered evidence: Sometimes the answer lives across multiple documents. An employee asking “What’s the policy on remote work for contractors?” needs information from both the remote work policy and the contractor agreement. Standard RAG typically retrieves from one pool of chunks and has no concept of checking a second source if the first one comes up short.
False confidence: The retrieval returns something that looks relevant based on similarity scores, but doesn’t actually answer the question. Maybe it’s about the right topic, but from an outdated version of a document. The system has no mechanism to tell the difference between “relevant” and “actually correct.” It generates a confident response either way.
These three failure modes share the same root cause. The system does not reflect what it retrieved. It can’t ask itself whether the results were good enough.
AI companies aren’t scraping Google (Sponsored)

They’re using SerpApi: the industry-standard Web Search API that shares access to search engines with a simple API. Trusted by Uber, NVIDIA, and more. Start with 250 free credits/month.
From Pipeline to Control Loop
Agentic RAG replaces that linear pipeline with a loop by bringing the capabilities of AI agents into the mix.
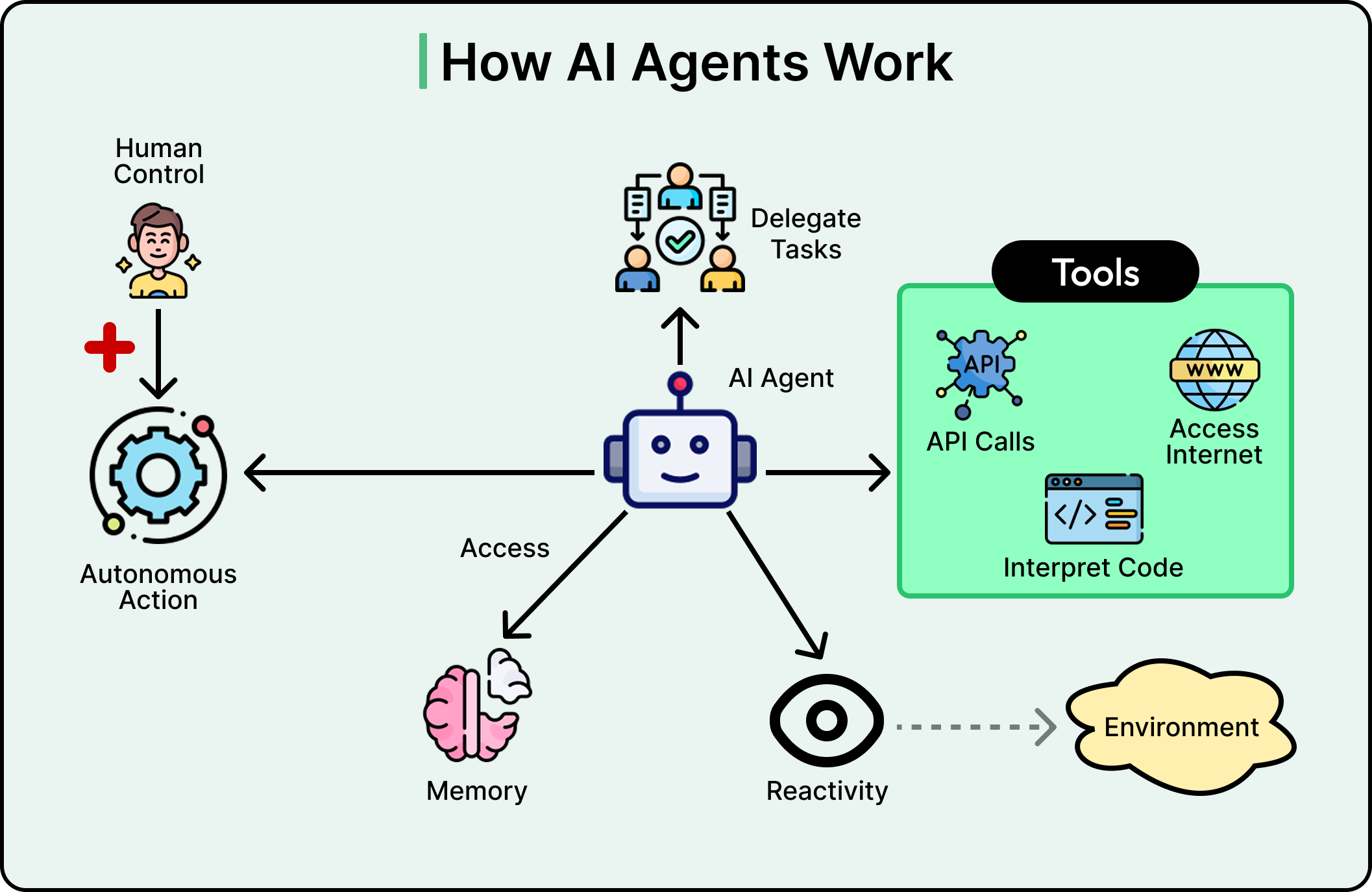
At its core, an AI agent is a software system that can perceive its environment, make decisions, and take actions to achieve specific goals with some degree of independence. The word “agent” is key here. Just as a travel agent acts on our behalf to find flights and negotiate deals, an AI agent acts on behalf of users or systems to accomplish tasks without needing constant guidance for every single step.
See the diagram below that illustrates the concept of an AI agent:
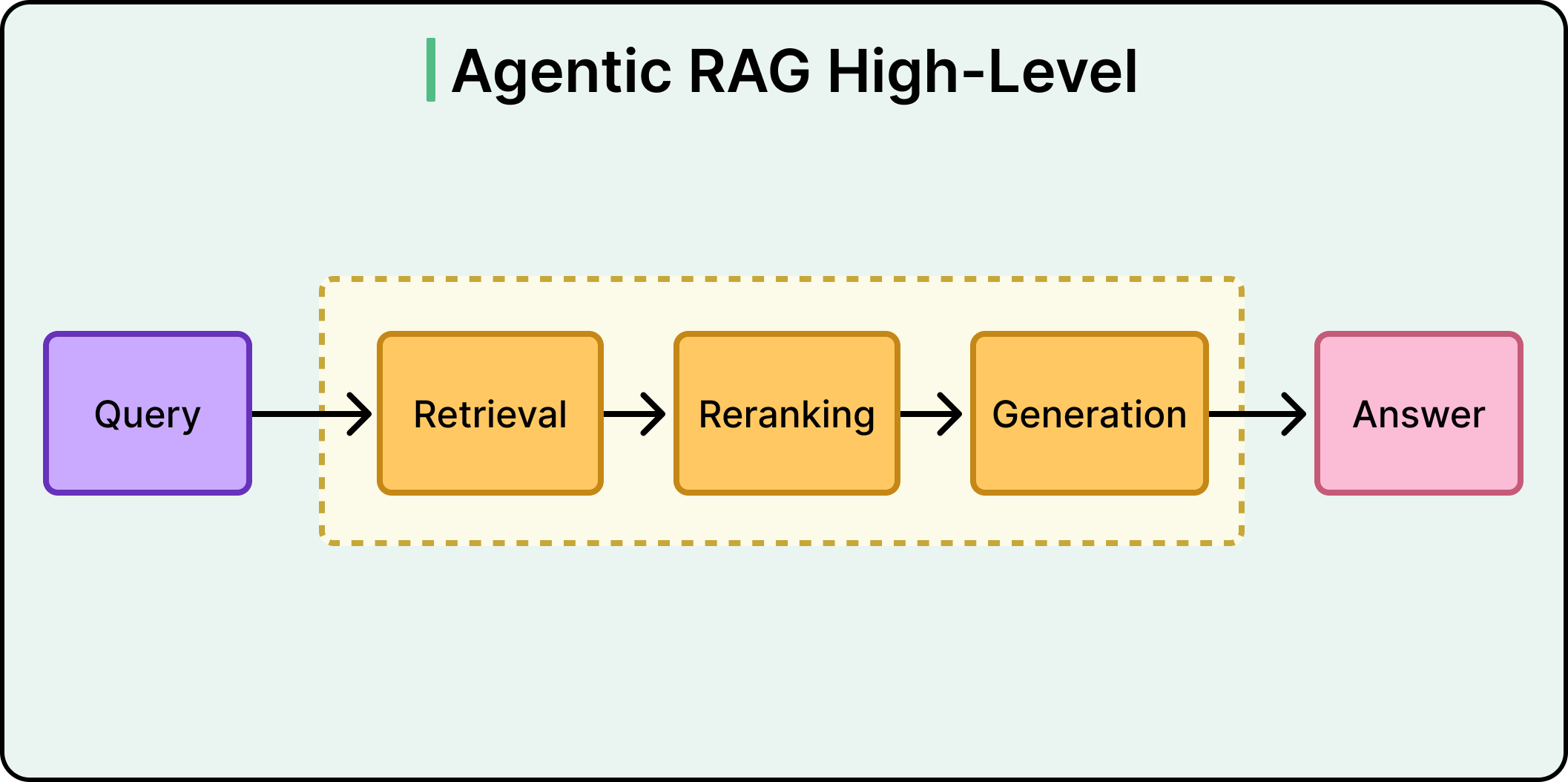
In Agentic RAG, instead of retrieve-then-generate, the flow becomes: retrieve, evaluate what came back, decide whether to answer or try again, and if needed, retrieve differently.
See the diagram below:
The word “agentic” might sound like a marketing push, but in this context, an agent is an LLM that has been given the ability to make decisions and call tools. Think of it as an LLM that, instead of just generating text, can also choose to take actions such as running a search, querying a database, calling an API, or deciding that it needs more information before responding.
This gives the system three capabilities that standard RAG lacks.
Tool use and routing: The agent can decide which knowledge source to query based on the question. A financial question might go to a SQL database. A policy question might go to a document store. A product question might need both. In short, an agentic system picks the right place, or searches multiple places.
Query refinement: Before searching, the agent can rewrite an ambiguous query into something more specific. After searching, if the results look weak, it can reformulate and try again. The agent acts on the query both before and after retrieval.
Self-evaluation: After getting results back, the agent examines them by asking questions such as “Is this relevant?” or “Is it complete?” or “Does it conflict with other information?” If the answer to any of these is no, the agent can retry with a different query, a different source, or both. This directly addresses the “one-shot problem.”
See the diagram below that shows Agentic RAG approach on a high-level:
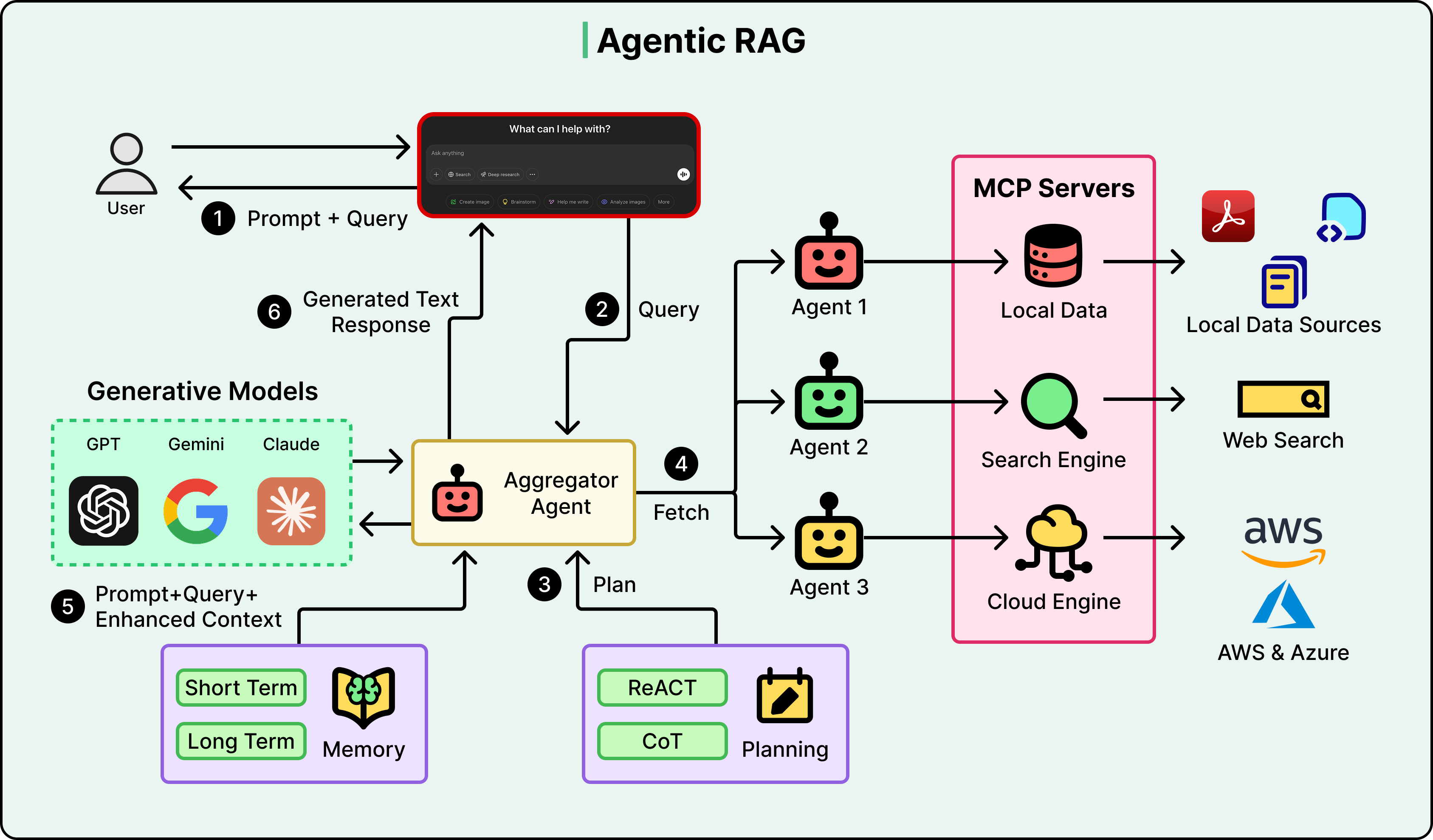
However, it’s misleading to think of Agentic RAG as a binary switch. In its simplest form, it’s like a router that decides which of two or three knowledge bases to query. That’s already a meaningful upgrade over standard RAG for multi-source environments.
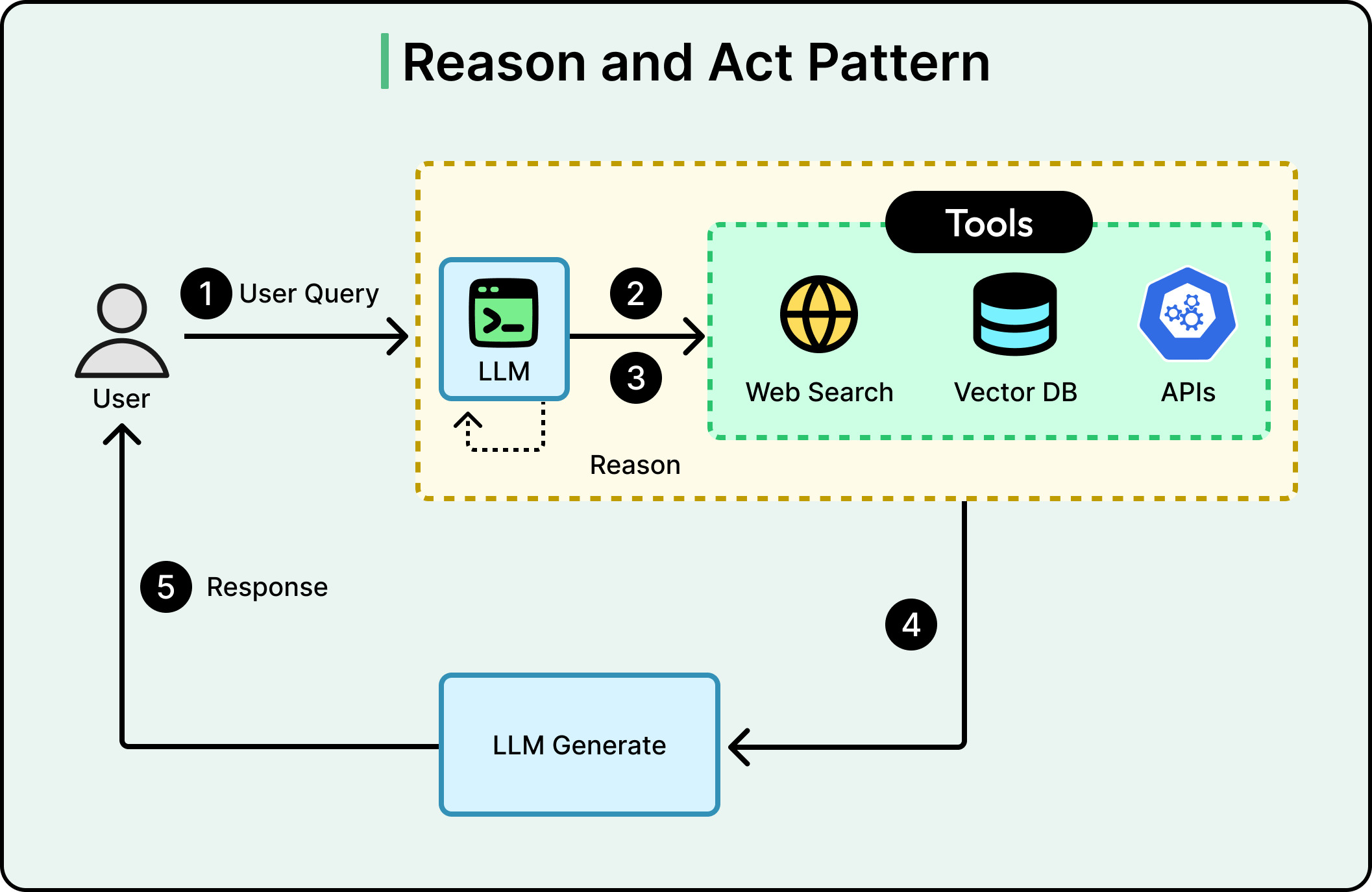
Further along the spectrum, you get systems like ReAct (short for Reasoning + Acting), a framework where the agent alternates between reasoning about what it knows and taking actions to learn more, running multiple retrieval steps with evaluation between each one.
See the diagram below:
At the far end sit multi-agent systems where specialized agents collaborate, coordinated by an orchestrator.
Query Refinement, Routing, and Self-Correction
The control loop is a useful mental model. However, it can be understood better when mapped back to the failure modes from earlier.
Ambiguity solved by query refinement: The “How do I handle taxes?” question goes through the agent first. The agent can decompose it into sub-questions based on context, or rewrite it into something more targeted before any retrieval happens. If the first retrieval comes back with results about personal income tax but the context suggests the user is asking about business tax, the agent can refine and search again.
Scattered evidence solved by routing: The remote work policy question for contractors now goes through an agent that recognizes it needs two sources. It routes the query to the HR policy document store, retrieves what it finds, then routes to the contractor agreements, retrieves from there, and synthesizes both sets of results before generating an answer.
False confidence solved by self-evaluation: The agent retrieves a chunk that looks relevant but comes from a document last updated two years ago. The evaluation step flags this. Maybe the agent then searches for a more recent version, or it searches a different source entirely, or it includes a caveat in its response. The system no longer blindly trusts similarity scores.
These three capabilities map directly to the three failure modes.
Agentic RAG was designed specifically to address the gaps where standard RAG’s one-shot approach falls short. There are additional agentic capabilities beyond these three, like memory and semantic caching, which allow the system to retain context across multiple queries in a conversation.
The Trade-Offs
Everything above might make Agentic RAG sound like a straight upgrade over standard RAG. However, every iteration of that loop has a cost, and those costs can be significant enough that many systems shouldn’t use it. Here are a few considerations to have:
Latency: Every loop iteration means another LLM call, another retrieval, another evaluation. A standard RAG query might take 1-2 seconds. An agentic query with three or four loops could take 10 seconds or more. For real-time chat applications, that’s usually unacceptable.
Cost: Each agent decision consumes tokens. A system handling thousands of queries per day can see costs multiply 3-10x compared to standard RAG. Even if 80% of those queries are simple FAQ lookups, that’s a lot of money spent on unnecessary reasoning.
Debugging and predictability: Standard RAG is relatively deterministic. However, Agentic RAG introduces variability because the agent can make different decisions based on what it finds at each step. This makes it harder to reproduce issues, harder to write tests, and harder to explain to stakeholders why the same question produced different answers in different situations.
The evaluator paradox: The self-evaluation step uses an LLM to judge whether retrieval was good enough. The system’s ability to self-correct is only as good as the LLM’s ability to judge relevance. A weak evaluator might reject perfectly good results and send the system on a wild goose chase, or accept poor results and generate a bad answer anyway. Basically, we’re trusting one LLM call to oversee another.
Overcorrection: Sometimes the agentic loop is smarter than it needs to be. It might discard useful retrieved information during the evaluation step, keep searching for something “better,” and end up with a worse answer than if it had just gone with the first result.
None of this means Agentic RAG should not be used. It means that deciding to use it should be an engineering decision and not a default choice.
Direct factual lookups against a clean and single-source knowledge base don’t need a reasoning loop. Neither do high-volume, low-complexity query patterns where latency and cost matter more than handling edge cases. If most of the failures in an existing RAG system come from retrieval quality issues like bad chunking or stale data, fixing those will do more good than adding an agentic layer.
Conclusion
The core mental model for Agentic RAG is straightforward.
Agentic RAG turns retrieval from a one-shot pipeline into a loop with decision points. Those decision points are the entire value add.
When evaluating or building RAG systems, three questions can help cut through the noise:
Is the system retrieving from the right source?
Can it evaluate whether what it retrieved is good enough?
Does it have the ability to try again if it’s not?
If the answer to all three is “no” and the queries are complex, that’s the signal to consider the agentic approach. If the queries are simple and the knowledge base is clean, standard RAG is probably the right call.
The pipeline-to-loop shift also isn’t unique to RAG. It reflects a broader pattern in how AI systems are evolving, moving from rigid pipelines toward systems with feedback loops and decision-making capabilities.
References:
The "evaluator paradox" is the most underrated point here: asking the same LLM that might hallucinate to judge retrieval quality is a fundamental circular dependency.
In practice, you don't need the full ReAct loop to get 80% of the value. Just adding a single relevance checkpoint between retrieval and generation cuts down on confidently wrong answers dramatically.
And for production, a hybrid approach of standard RAG for simple lookups, agentic only for ambiguous queries, escalating to a human when only necessary is the practical sweet spot given the latency/cost trade-offs.
“Agentic RAG turns retrieval from a one-shot pipeline into a loop with decision points. Those decision points are the entire value add”
excellent takeaway. it’s been really interesting watching everything go agentic in 2026. this was a great breakdown.