
How AI Agents Manage Memory and Avoid Forgetfulness

Who’s actually reviewing all that AI-generated code? (Sponsored)

When devs use AI to generate thousands of lines of unverified code, you risk a codebase slopocalypse. The review step becomes your team’s bottleneck, and the last thing standing between a subtle bug and production.
Greptile reviews each PR with full repo context and learns your team’s conventions over time from comments, reactions, and what gets merged. It flags real issues and suggests fixes that match your team, not generic best practices.
✅ Recently launched TREX runs your code, not just reads it. Greptile executes the change in a sandbox and returns screenshots, logs, and traces as proof of what actually broke.
✅ Review from your terminal. The Greptile CLI runs the same review locally, before you ever open a PR.
✅ Trusted by engineering teams at NVIDIA, Scale AI, and Brex.
✅ Now integrated with Claude Code: install via /plugin.
✅ Free for open source.
Even the most sophisticated AI agent in your stack starts every single message from a blank slate.
The model itself sees only the text placed in front of it at that exact moment, and the rest of the conversation lives outside its awareness entirely. Whatever continuity we feel when chatting with Claude or ChatGPT is something the surrounding platform is engineering on the model’s behalf, by inserting the right context back into every call. Once we understand this crucial distinction, the entire field of agent memory becomes a very different engineering problem from what it first appears to be.
In this article, we will try to understand how that architecture gets built, from the constraint that forces it to exist all the way to the tradeoffs that follow.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
Statelessness
A call to a large language model follows a simple pattern. The system sends a prompt, the model returns a response, and the exchange concludes there. Each subsequent call, even one made a millisecond later, begins from a completely fresh slate. This is the API contract for every commercial LLM and reflects how transformers serve traffic.
See the diagram below:
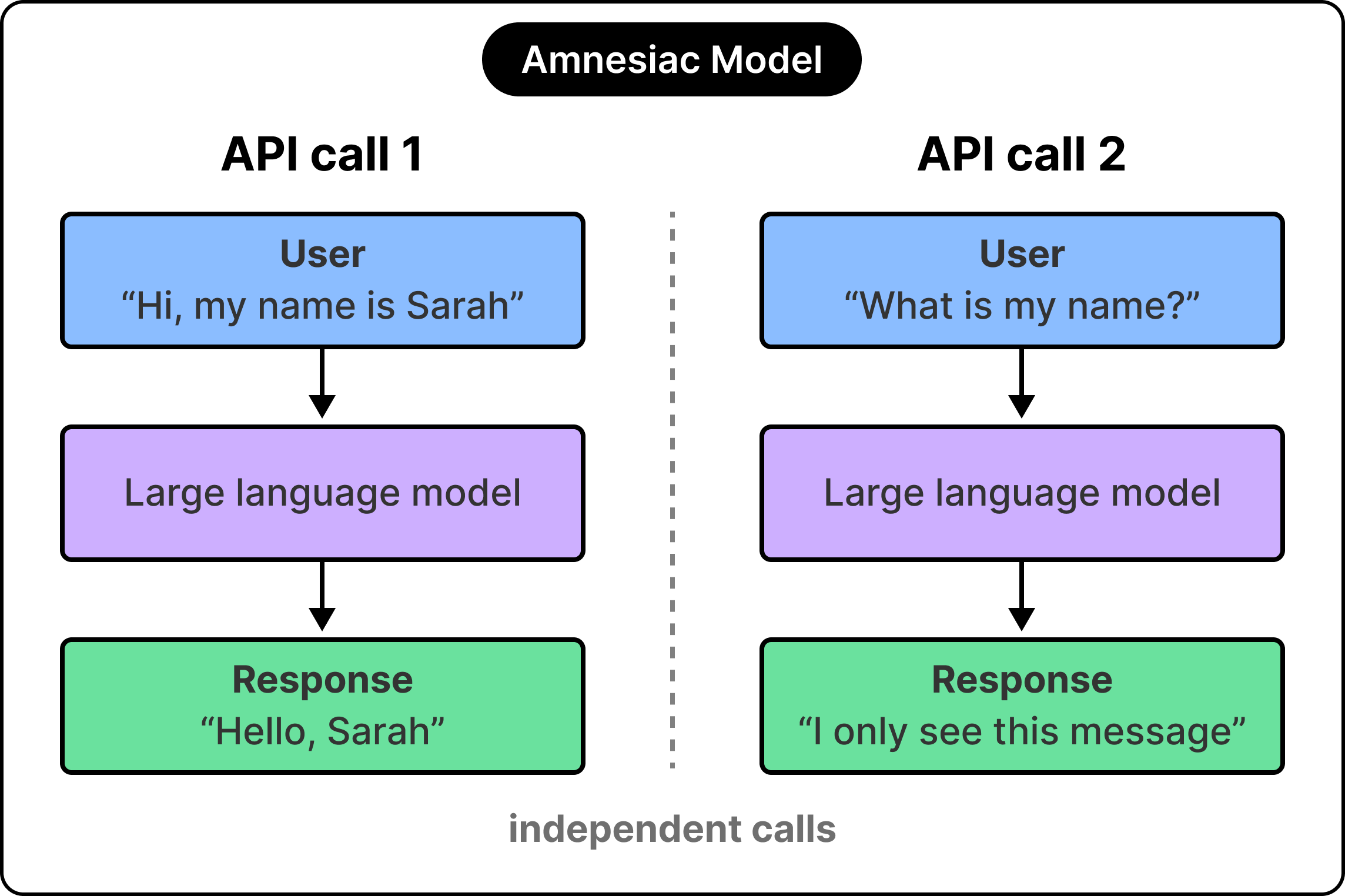
When we say things like “Claude remembers our conversation from yesterday,” we are describing a property of the product rather than a property of the actual model itself. The platform writes things down on the model’s behalf, then reads them back into the prompt at exactly the right moment, so the model can reason as if it had been there all along. The intelligence resides within the model itself, while the memory resides in the system surrounding it.
If the model itself works this way, the next question is whether we can solve the memory problem by writing everything into the model’s view on every call? The way this approach breaks gives us a better insight into how to solve this problem.
Context
Every API call has a context window. It is basically the bounded slab of text that the model reads when generating its response. This includes the system prompt, the user’s current message, and anything else the developer has placed there. The model has full visibility into the contents of the window, while whatever sits outside it might as well live on a different machine.
See the diagram below:
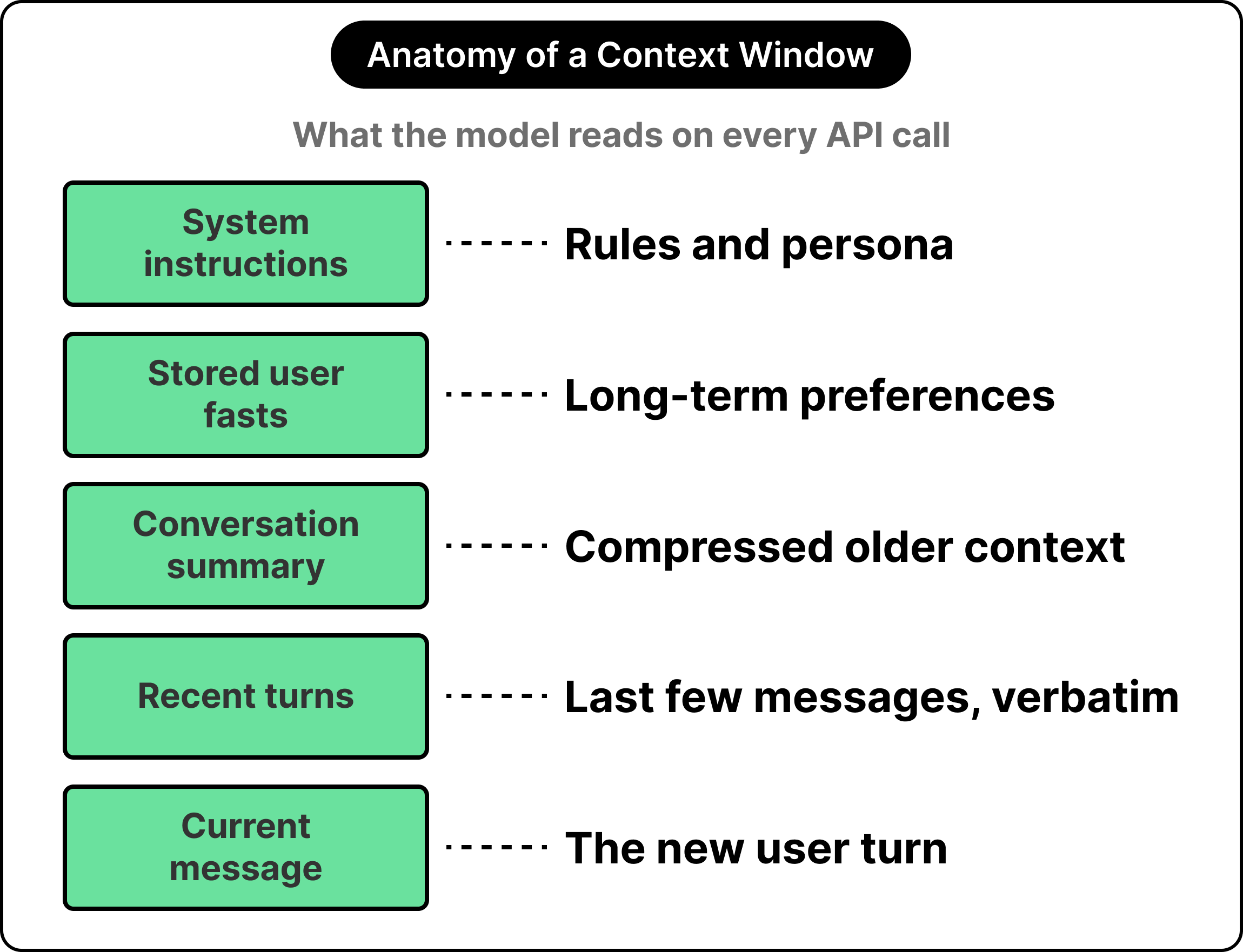
An obvious approach to memory involves writing the entire conversation history into the context window on every call. This works well for the first few turns of a chat. Once the conversation grows longer, however, three significant problems emerge at once:
The first problem is cost. Every token in the context window is paid for on each call, in both money and latency, so a linearly growing conversation produces a linearly growing bill. By message eighty, the system might be re-sending tens of thousands of tokens on every turn just to maintain continuity.
The second problem is latency. Larger contexts take longer to process, and a model that responds in two seconds on a short prompt may take ten or fifteen on one that has filled most of its window.
The third problem is the most counterintuitive of the three. The model’s attention degrades inside long contexts, and information placed in the middle of a long prompt is recalled less reliably than information at the beginning or the end. Researchers refer to this as the lost-in-the-middle effect.
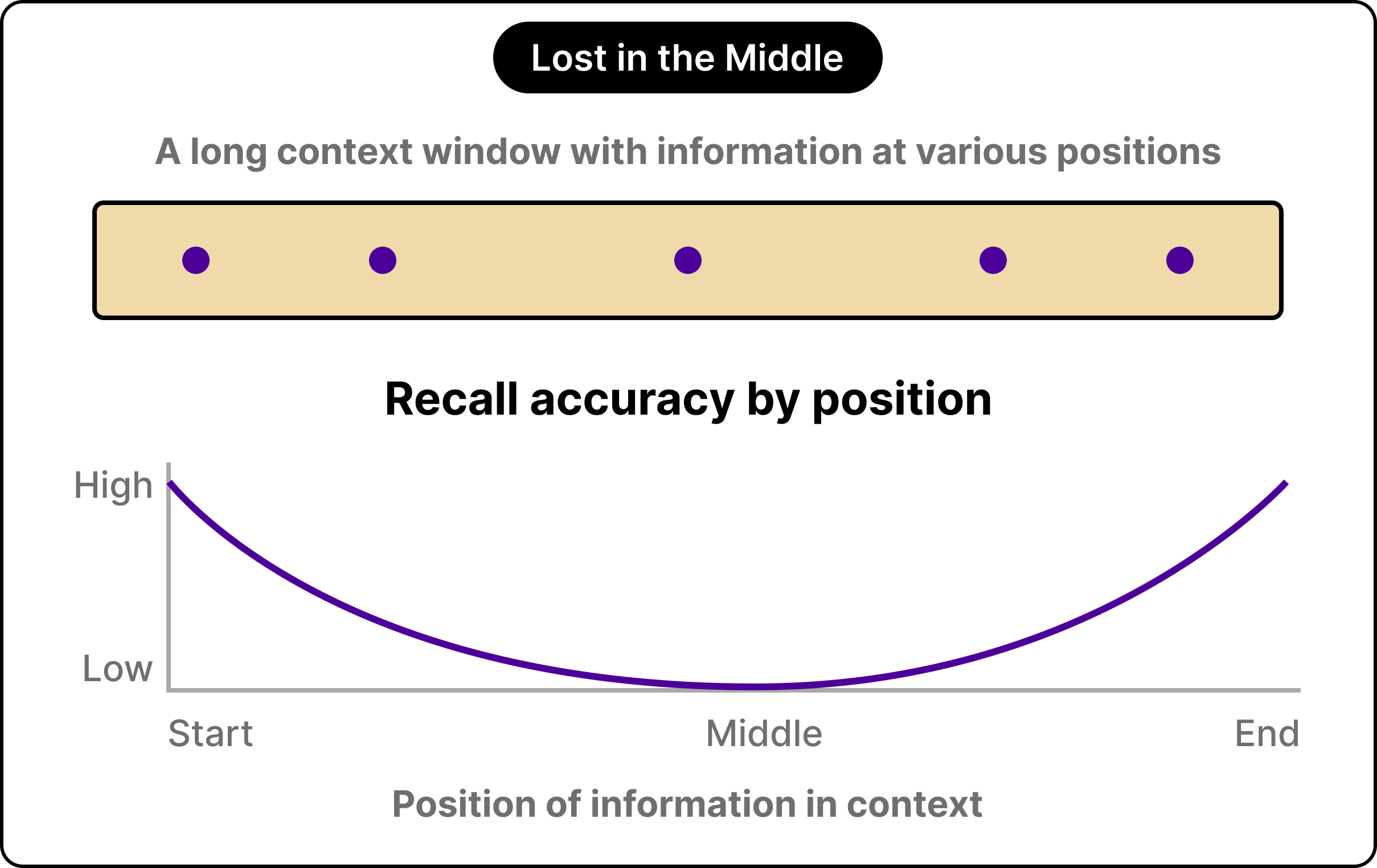
Bigger context windows feel like they should solve memory entirely. In reality, they expand the room while leaving the navigation problem fully intact. Important information can sit right inside the window and still get ignored by the model.
Since a bigger window alone is the wrong tool, we need an architecture that decides what belongs in the window at any given moment.
When Rules Fail, AI Picks Up the Slack (Sponsored)

What happens when deterministic code hits the edge of its knowledge? In this live webinar, you’ll see a working plant health monitor built on Temporal’s entity workflow pattern where each plant is a long-running, crash-proof workflow that polls sensors, fires alerts, and falls back to GPT-4o only when the rules run out.
The architecture is clean: structured data first, AI second. The boundary is auditable. The state survives everything. Whether you’re building patient monitors, supply chain detectors, or any long-running process that occasionally needs a smarter answer, the patterns here translate directly.
Hierarchy
Real production systems organize memory in tiers, each trading off speed of access, total capacity, and cost per token. The context window sits at the top, with progressively slower, larger, and cheaper stores below it.
The analogy to operating system memory is evident. Modern agent memory systems draw heavily on the way operating systems page data between fast RAM and slower disk, promoting and demoting information as its relevance rises and falls.
A typical four-tier hierarchy starts with the context window at the top, fast and tightly bounded, with every token expensive at scale. Below it sits short-term or session memory, holding recent activity that has yet to be summarized or evicted. Beneath that is the long-term store, where persistent facts, embeddings, and structured summaries live across sessions. At the bottom is the cold archive, used for rarely-accessed material kept for audit or future reference.
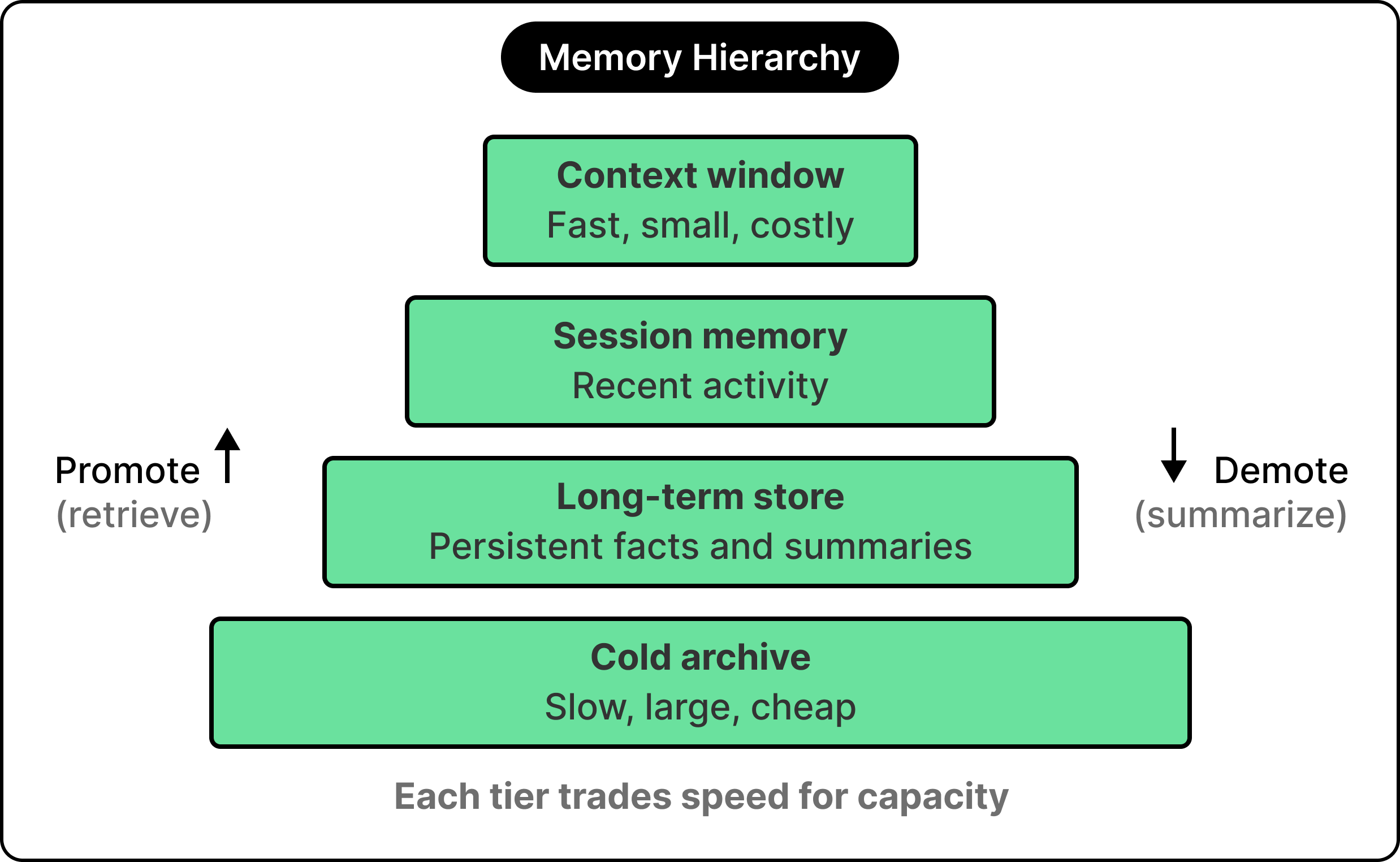
Information moves up and down this hierarchy as the agent works. A fact stated three sessions ago might be sitting in the long-term store, and the moment it becomes relevant, the system retrieves it and promotes it back into the context window. Conversely, when a session ends, the most useful parts of the context window get summarized and written down into the lower tiers.
ChatGPT’s memory feature uses a simple version of this idea. Stored user facts and summaries of recent conversations get prepended to every new prompt, while the current session occupies the working tier. The sophistication lies in what gets promoted to long-term memory in the first place, rather than in elaborate retrieval at read time.
A hierarchy describes where memory lives. The kinds of memory we are storing are a separate question, organized along a different axis.
Types
The field has converged on four functional categories of agent memory, drawing on concepts from cognitive science adapted for language model agents:
Working memory holds whatever sits in the live context window for the current task. For example, if the agent is helping us debug a function right now, the function code and our recent messages occupy working memory. The moment this task ends, working memory clears.
Episodic memory holds records of specific past interactions, anchored in time. A statement like “Three days ago, this user asked about onboarding new engineers, and we discussed checklist templates” represents an episodic memory, capturing a particular event with its context.
Semantic memory stores facts and knowledge that stand independent of any specific interaction. Statements like “Adam prefers Python over JavaScript” and “his team uses GitHub Actions for CI” function as semantic memories, surviving across sessions and applying wherever they are relevant.
Procedural memory captures learned ways of doing things. If the agent has figured out that this user prefers a three-section format for status updates, that preference becomes procedural memory, and the next time a status update is requested, the agent applies the format automatically.
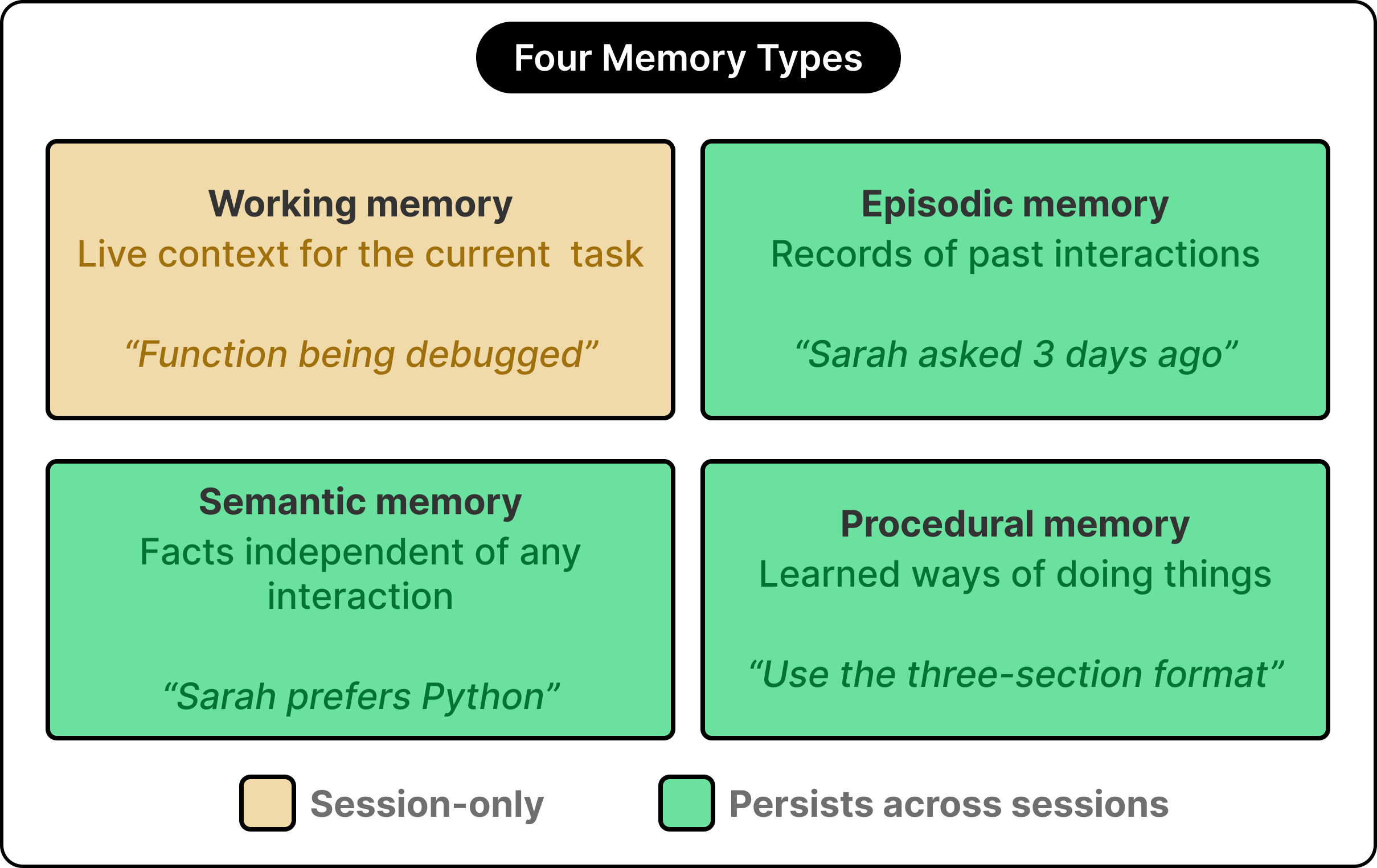
These four types are orthogonal to the hierarchy from the previous section.
A piece of semantic memory might live physically in the long-term store and get pulled into the context window the moment it becomes relevant. Most production agents implement at least three of these types, with the mix depending on what the agent is built to do. A customer support agent leans heavily on episodic and semantic memory, while a coding agent leans more on procedural memory. The right blend is a design choice rather than a fixed formula.
All of this still leaves one important question open.
How does the agent actually decide, on each turn, what to retrieve and place in the model’s view?
Retrieval
Storage can possibly be thought of as the easy half of agent memory. Writing a fact to a database or indexing a summary in a vector store are solved problems with mature tooling. The harder half is retrieval, which is the act of deciding on every new turn what belongs in the model’s awareness.
Retrieval is hard because it requires judgment about relevance, and relevance shifts from one message to the next. For example, the user’s preference for Python matters when they are asking about a new project, while that same preference fades in importance when they are asking about pizza recipes. A good retrieval system surfaces relevant items at exactly the moment they are useful, and leaves the rest sitting quietly in storage.
See the diagram below:
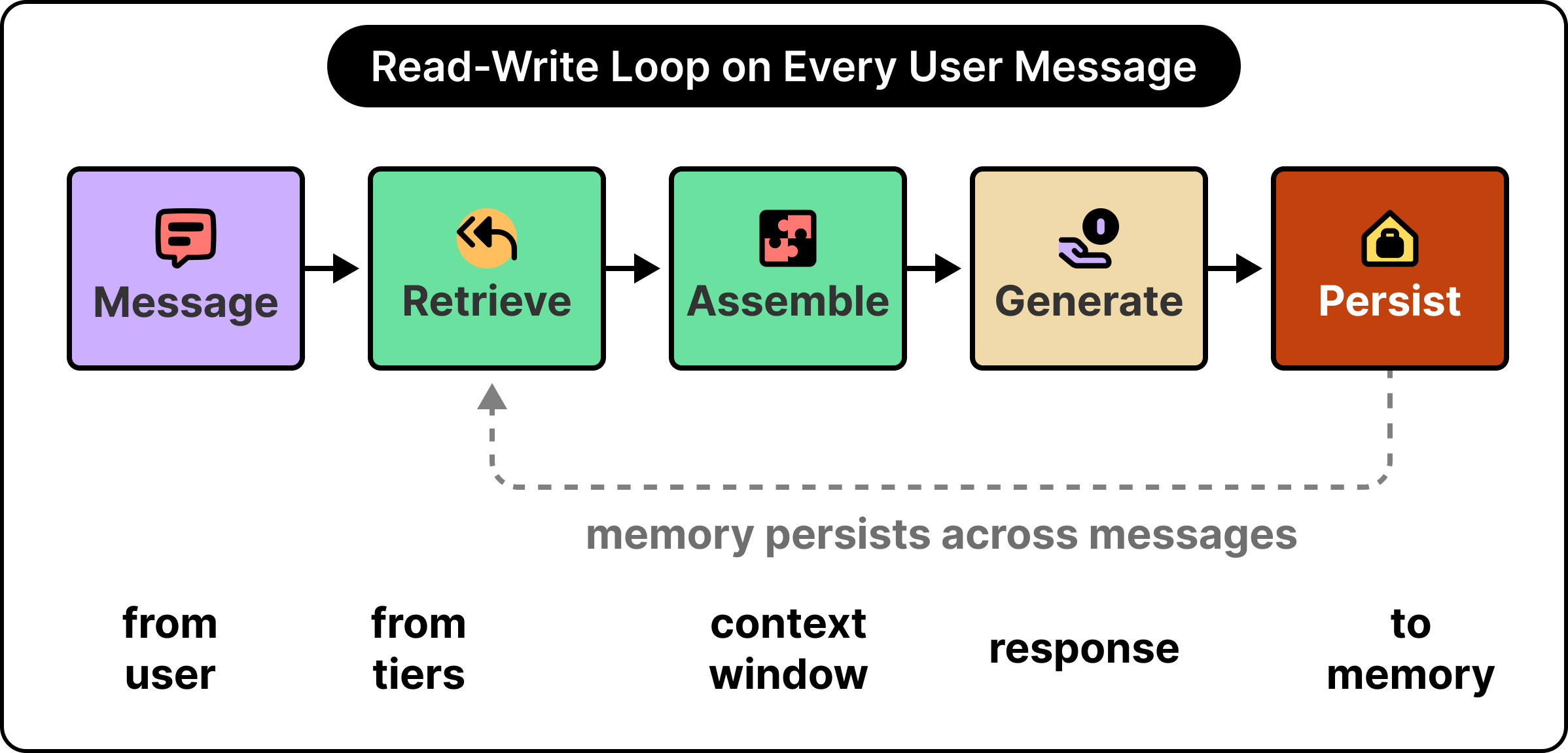
The full loop runs on every user message.
The user sends a message, and the system retrieves relevant items from each memory tier using a mix of keyword search, semantic similarity, and recency signals. It assembles a context window in a deliberate order, often placing the most important material near the beginning and the end where the model’s attention is strongest. The model runs and returns a response, after which the system writes part of the new exchange back into memory, often as a summary, sometimes with a decay score so that importance fades over time.
Consider two agents to see why retrieval matters so much.
The first has a perfect database of past interactions paired with a retrieval system that frequently picks the wrong record. The second has an empty memory store and operates only on what the user tells it in the current session. The second often outperforms the first, because it understands the bounds of what it can rely on, while the first surfaces stale or irrelevant information confidently and reasons on top of it as though it were ground truth.
In other words, memory failures in production are typically retrieval failures in disguise.
Tradeoffs
The memory architecture described above involves several tradeoffs that engineering teams must navigate carefully. Four stand out as particularly important:
Recency versus relevance: Do we retrieve the most recent items from memory, or the most semantically similar ones? Most systems do both, and blending them well is an ongoing engineering puzzle. Leaning too far on recency means the agent forgets useful older context, while leaning too far on relevance means the agent fixates on a strong-but-stale match.
Summarization versus fidelity: Compressing old context into summaries saves tokens, which makes everything cheaper and faster. The compression is also lossy, and the loss is uneven. Names, dates, and specific commitments get smoothed away in summarization, while general themes survive. The agent stays confident even after the precise detail has quietly disappeared.
Staleness: A fact that was true six months ago can be confidently wrong today. For example, the user who may have told the agent “I am a vegetarian” in 2024 might be eating non-vegetarian again in 2026. The memory system has only blunt heuristics for guessing that the world has moved on, so it keeps serving the old fact with full confidence. Staleness in high-relevance memories remains an open research problem.
Memory poisoning: Long-term memory is also a long-term attack surface. A subtly malicious instruction written into the store six months ago will sit there influencing every retrieval until somebody notices. The same property that makes memory useful, persistence, also makes it dangerous when the contents are wrong or hostile.
A memory system makes sense when the agent needs continuity across sessions or runs long-horizon tasks where context compounds. For one-shot tasks, it adds complexity beyond what the task requires.
Conclusion
Five core ideas from this article are as follows:
The model is stateless. Every API call begins from a fresh slate, and any continuity we observe is the work of the surrounding system rather than the model itself.
The context window is the model’s only surface of awareness. Writing everything into it fails for reasons of cost, latency, and degraded attention in long prompts.
Real systems organize memory in a hierarchy of tiers, with the context window at the top and progressively slower, larger, cheaper stores below it.
Different kinds of information call for different kinds of memory, with working, episodic, semantic, and procedural memory each serving a distinct purpose.
The main engineering problem in this area is retrieval, which is the question of what deserves to enter the model’s awareness on each new turn, with tradeoffs around staleness, summarization loss, and security.
The practical takeaway from all of this is simple.
The next time we see a product feature labeled “memory” or read about an agent that “remembers across sessions,” the right question moves away from “can the model remember this?” and toward “what does the memory architecture around this model actually do, and what tradeoffs has it accepted?”
References:
Memory failures are retrieval failures. Worth adding: not everything an agent reads is memory. CLAUDE.md, AGENTS.md, project rules. Those load on every turn whether relevant or not. They are config layer, not memory layer. They do not fail by bad retrieval. They fail by dilution as you add more files. Different failure modes, same plumbing. Wrote about this lately: https://jugeni.substack.com/p/your-agents-markdown-file-is-becoming
The left-vs-right diagram is the whole argument for why the model isn’t the moat. A stateless model can answer; it can’t execute a multi-step task without somewhere to hold state. So memory becomes the layer where reliability and lock-in actually accrue, the agent that remembers your context across sessions is far stickier than the one that’s merely smarter. Does the durable advantage sit in the memory architecture itself, or in the proprietary data that memory quietly accumulates?