
How Amazon S3 Stores 350 Trillion Objects with 11 Nines of Durability

🚀Faster mobile releases with automated QA

Manual testing on personal devices is too slow and too limited. It forces teams to cut releases a week early just to test before submitting them to app stores. And without broad device coverage, issues slip through.
QA Wolf’s AI-native service delivers 80% automated test coverage in weeks, with tests running on real iOS devices and Android emulators—all in 100% parallel with zero flakes.
✅ QA cycles reduced to just 15 minutes
✅ Multi-device + gesture interactions fully supported
✅ Reliable test execution with no flakes or false positives
✅ Zero flakes, human-verified bug reports
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Rated 4.8/5 ⭐ on G2
Disclaimer: The details in this post have been derived from Amazon Engineering Blog and other sources. All credit for the technical details goes to the Amazon engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Amazon Simple Storage Service (S3) is a highly scalable and durable object storage service designed for developers, businesses, and enterprises.
Launched in 2006, S3 revolutionized cloud computing by enabling on-demand storage that is cost-effective, highly available, and reliable. Over the years, it has become a cornerstone of modern cloud infrastructure, supporting everything from small startups to Fortune 500 companies.
S3 allows users to store any amount of data at any time, making it a foundational service for industries ranging from media and entertainment to finance and healthcare. Whether hosting static website files, storing massive datasets for machine learning, or backing up critical business data, S3 provides a secure, scalable, and easy-to-use storage solution.
Amazon S3 plays a vital role in the cloud computing ecosystem for several reasons:
S3 automatically scales storage to accommodate growing data needs without requiring infrastructure management.
S3 offers multiple storage classes, such as S3 Standard, S3 Intelligent-Tiering, S3 Glacier, and S3 Express One Zone, optimizing costs based on data access frequency.
Features like encryption (server-side and client-side), bucket policies, IAM roles, and access control lists (ACLs) ensure secure data storage.
S3 integrates with other AWS services like AWS Lambda, Amazon CloudFront, Amazon Athena, AWS Glue, Amazon SageMaker, and more.
Designed for 99.999999999% durability (11 nines), ensuring minimal data loss risk.
In this article, we’ll take a deeper look at the architecture of Amazon S3 and understand how it works. We will also learn about the challenges faced by the Amazon engineering team while building S3.
Evolution of Amazon S3
Amazon Simple Storage Service (S3) was launched in March 2006 as one of the first AWS cloud services. At the time, businesses were struggling with traditional on-premises storage limitations, including high costs, complex scalability issues, and unreliable backup solutions.
Since its launch, Amazon S3 has undergone continuous improvements, adapting to technological advancements and evolving customer needs.

Here’s how it has grown over the years:
2006 - The Birth of S3
Launched as one of the first cloud services from AWS.
Provided a simple API for storing and retrieving files.
Limited to a single global namespace.
2010 - Regional Storage Model
Shifted from a global model to a regional model, improving performance and availability.
Enhanced disaster recovery capabilities.
2012 - Glacier Introduced
Amazon Glacier launched for long-term archival storage at a low cost.
Marked AWS’s first major move toward tiered storage solutions.
2015 - Performance and Security Enhancements
Introduced cross-region replication (CRR) and event notifications for automation.
Strengthened security with default encryption and access logging.
2018 - AI & Analytics Capabilities
Integrated with Amazon Athena, AWS Glue, and SageMaker, transforming S3 into a platform for AI-driven data processing.
2020 - Intelligent-Tiering & S3 Select
Added S3 Intelligent Tiering, allowing automatic movement of data to lower-cost storage based on access patterns.
S3 Select enabled querying data directly within S3 without moving it to a database.
2023 - S3 Express One Zone
Introduced S3 Express One Zone, optimizing performance for high-speed workloads.
Enhanced durability and efficiency with multi-part upload improvements and new security mechanisms.
Amazon never guessed how popular S3 was going to become.
In its early days, they underestimated the explosive demand for cloud storage. Initially projected to store a few gigabytes per customer, they had to quickly scale to support exabytes of data due to the rapid adoption of digital transformation.
As S3 usage grew exponentially, AWS had to shift its strategy from reactive problem-solving to proactive scaling.
Phase 1: The Reactive Model (2006 - 2010)
In the early years, S3 operated with a reactive approach, responding to storage needs as they arose. However, this led to several challenges:
Storage capacity had to be expanded frequently, sometimes leading to delays.
Traffic spikes caused occasional bottlenecks due to unanticipated demand.
Engineering teams worked around the clock to mitigate sudden issues.
Phase 2: Predictive Scaling and Threat Modeling (2010 - Present)
Recognizing the growing unpredictability of storage needs, Amazon transitioned to a proactive model, focusing on automation, scalability, and predictive demand forecasting.
Some key improvements were as follows:
Amazon S3 engineers started using threat modeling to predict potential system failures and optimize performance before problems occurred.
AWS implemented AI-driven forecasting to predict storage demands months in advance. Auto-scaling storage clusters allowed Amazon to add capacity dynamically before customers even realized they needed it.
Amazon introduced multi-AZ storage to ensure high availability and disaster resilience.
AWS designed lexicographical key partitioning to distribute workload efficiently.

The Architecture of Amazon S3
Amazon S3 is one of the world's largest and most complex distributed storage systems. It processes millions of requests per second and stores over 350 trillion objects, all while maintaining 11 nines (99.999999999%) durability and low-latency access.
To achieve this level of scalability, fault tolerance, and performance, AWS architected S3 using a microservices-based design.
Amazon S3 is not a single storage system. Instead, it is a collection of over 350 microservices, each responsible for specific storage tasks. These microservices are spread across multiple AWS regions and availability zones (AZs) and work together to store, retrieve, and protect data at scale.
See the diagram below that shows a high-level view of the S3 service architecture.
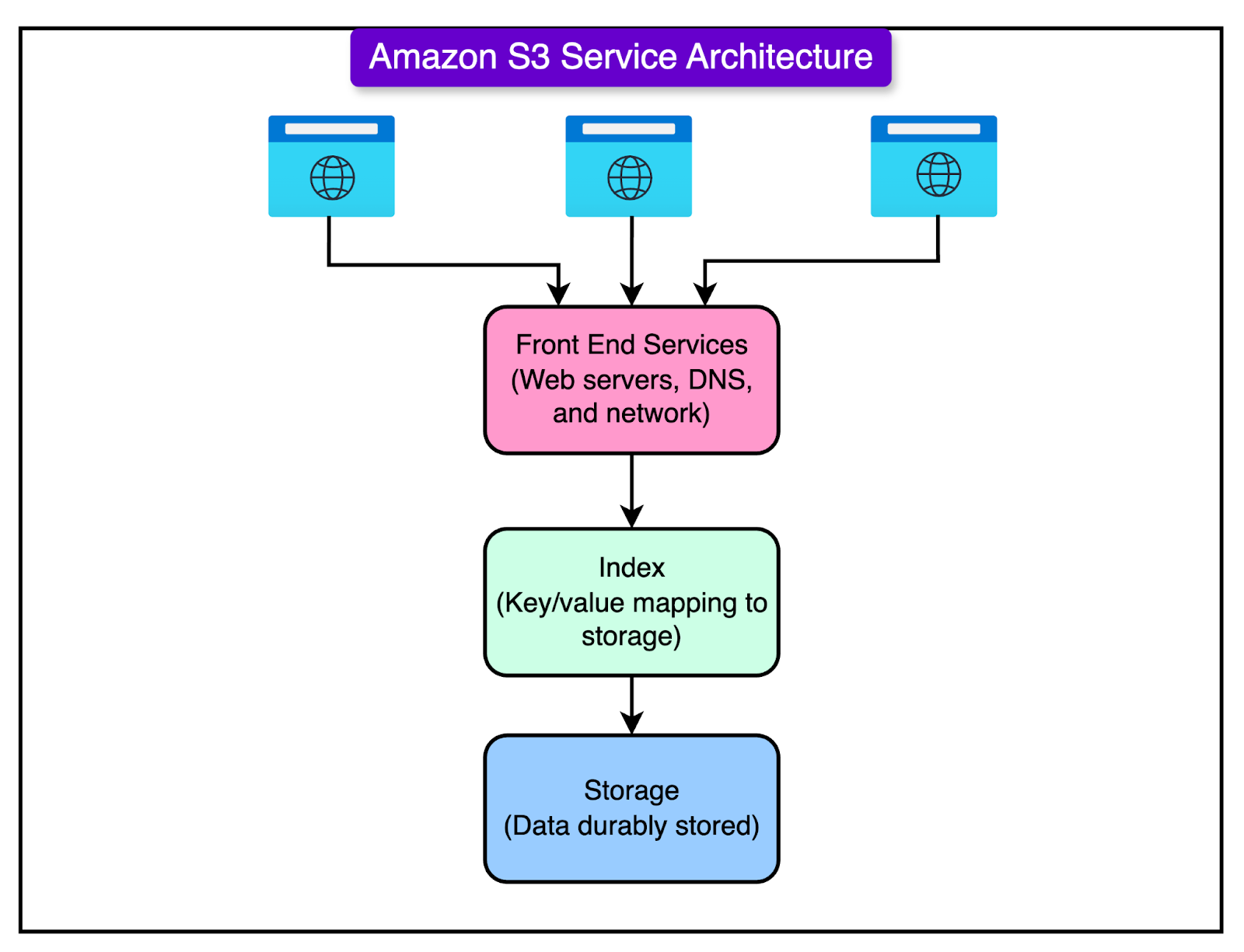
Here’s how the overall system works:
Front-End Request Handling Services
These microservices receive API requests from clients, SDKs, and AWS CLI. They authenticate users, validate requests, and route them to the correct storage service.
This includes:
DNS Routing Service: Determines which AWS region should process the request.
Authentication Service: Validates IAM permissions and bucket policies.
Load Balancers: Distribute traffic across thousands of S3 storage nodes.
For example, when a user uploads a file, these services determine the best S3 storage node to store the object while balancing load across AWS regions.
Indexing and Metadata Services
Every object stored in S3 is assigned a unique identifier and metadata. The indexing microservices track object locations without storing the data itself.
The metadata is sharded, ensuring that billions of objects can be indexed efficiently.
The various components involved are as follows:
Global Metadata Store: Maps object keys to physical storage locations.
Partitioning Engine: Distributes index data to optimize retrieval speed.
Lifecycle Management Service: Tracks versioning, retention policies, and expiration.
For example, when you request a file, S3 doesn’t scan billions of objects. Instead, the metadata service instantly finds the correct storage location.
Storage and Data Placement Services
This part handles the physical storage of objects across multiple S3 nodes. To protect against data loss, it uses erasure coding and multi-AZ replication.
These services include the following components:
Data Placement Engine: Determines where to store an object based on size, region, and redundancy settings.
Replication Services: Ensures multi-AZ and cross-region replication to prevent data loss.
Compression & Encryption Services: Applies server-side encryption (SSE) and optional compression.
For example, when a user uploads a file, the storage engine decides where to store it, applies encryption, and ensures copies exist in multiple regions.
Read and Write Optimization Services
Amazon S3 is optimized for high-speed data retrieval and writing. To achieve this, it uses techniques like multi-part uploads and parallelized retrieval.
This includes:
Multi-Part Upload Manager: Splits large files into chunks, allowing faster uploads.
Prefetching & Caching Services: Improves performance for frequently accessed data.
Data Streaming Service: Optimizes bandwidth usage for high-throughput applications.
For example, a video streaming company can use multi-part downloads to retrieve sections of a file in parallel, speeding up playback.
Durability and Recovery Services
These services ensure data integrity and fault recovery, helping S3 achieve 99.999999999% durability.
They include services like:
Checksum Verification Service: Continuously verifies stored data against integrity checksums.
Background Auditors: Scans storage nodes for corrupted files and automatically repairs them.
Disaster Recovery Engine: Automatically reconstructs lost or damaged data from backup nodes.
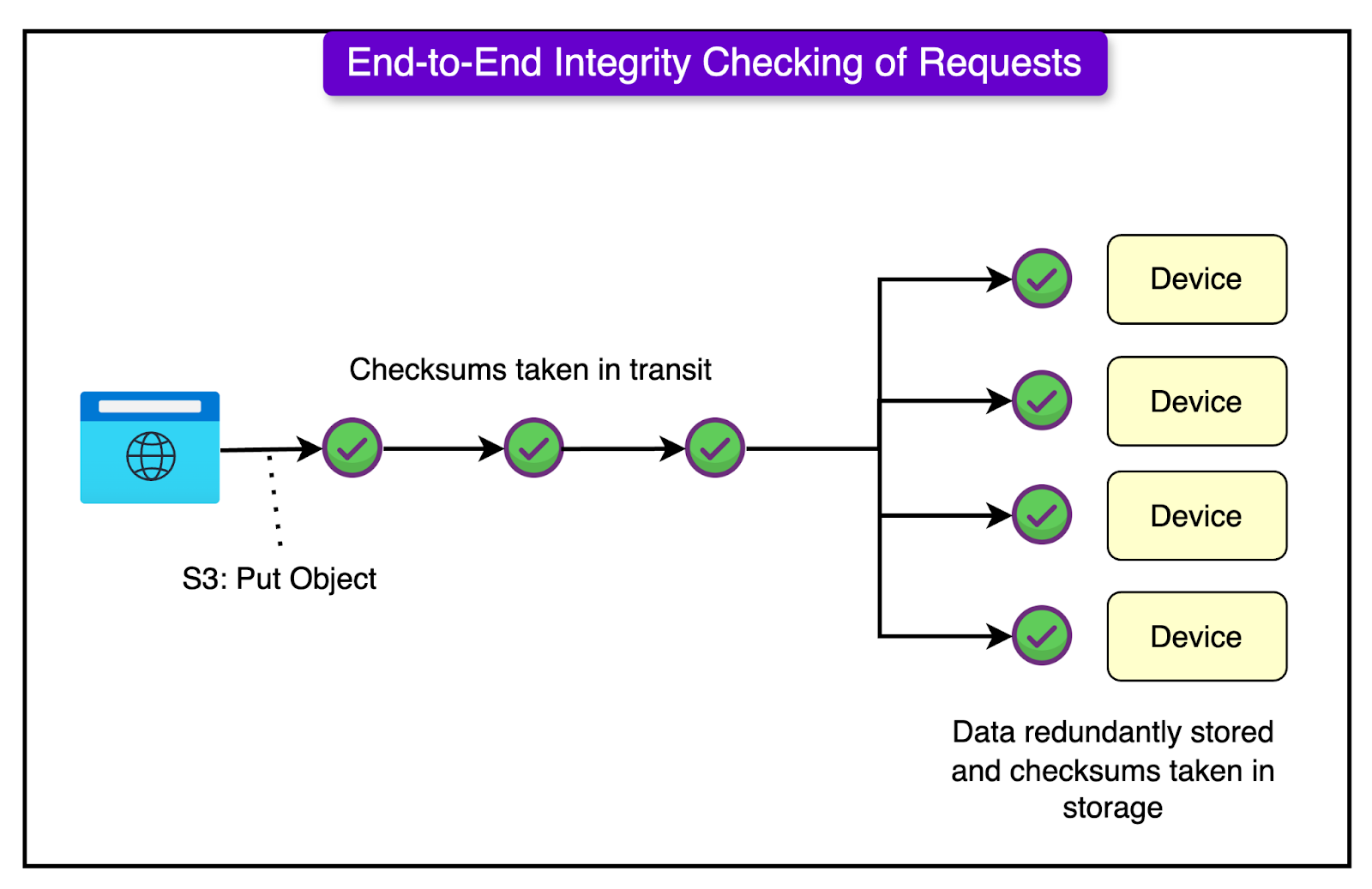
For example, if a hard drive storing S3 objects fails, the background auditors detect the issue and trigger an automatic rebuild of the missing data.
Security and Compliance Services
These services aim to protect S3 from unauthorized access and cyber threats. They also ensure compliance with regulations such as HIPAA, GDPR, and SOC 2.
These services support features like:
IAM & Bucket Policy Enforcement: Enforces fine-grained access controls.
DDoS Mitigation Service: Protects against malicious attacks.
Object Lock & Versioning Service: Prevents accidental or malicious deletions.
How Data Is Written to Amazon S3?
Writing data to S3 involves a series of well-orchestrated processes that ensure speed, consistency, and security while distributing data across multiple availability zones (AZs).
Here’s a step-by-step breakdown:
Step 1: The Client Sends a Write Request to S3
A client (user application) can send a request to write data into Amazon S3 using different interfaces such as AWS SDKs (available in multiple programming languages), AWS CLI, or the S3 REST API.
S3 also supports multi-part upload for large files (>5 MB). For such files, S3 splits the data into chunks and uploads them in parallel.

Step 2: DNS Resolution and Routing
Once the request is sent, Amazon S3 needs to determine two things:
Which AWS region should handle the request?
Which storage node should store the object?
The client’s request is sent to Amazon Route 53, AWS’s DNS service. Route 53 resolves the bucket’s domain (my-bucket.s3.amazonaws.com) into an IP address. The request is then directed to the nearest AWS edge location for processing.
In this stage, S3 also performs some optimizations. For example, multi-region access points can route the request to the lowest-latency region. Also, AWS Global Accelerator ensures optimal routing across networks.
Step 3: Load Balancers and Web Servers Process the Request
Once the request reaches AWS, it is processed by a fleet of S3 web servers.
Some key events that happen at this stage are as follows:
S3 verifies IAM permissions, bucket policies, and ACLs. If unauthorized, the request is rejected with HTTP 403 Forbidden.
The request is validated for correct headers, signatures, and data integrity.
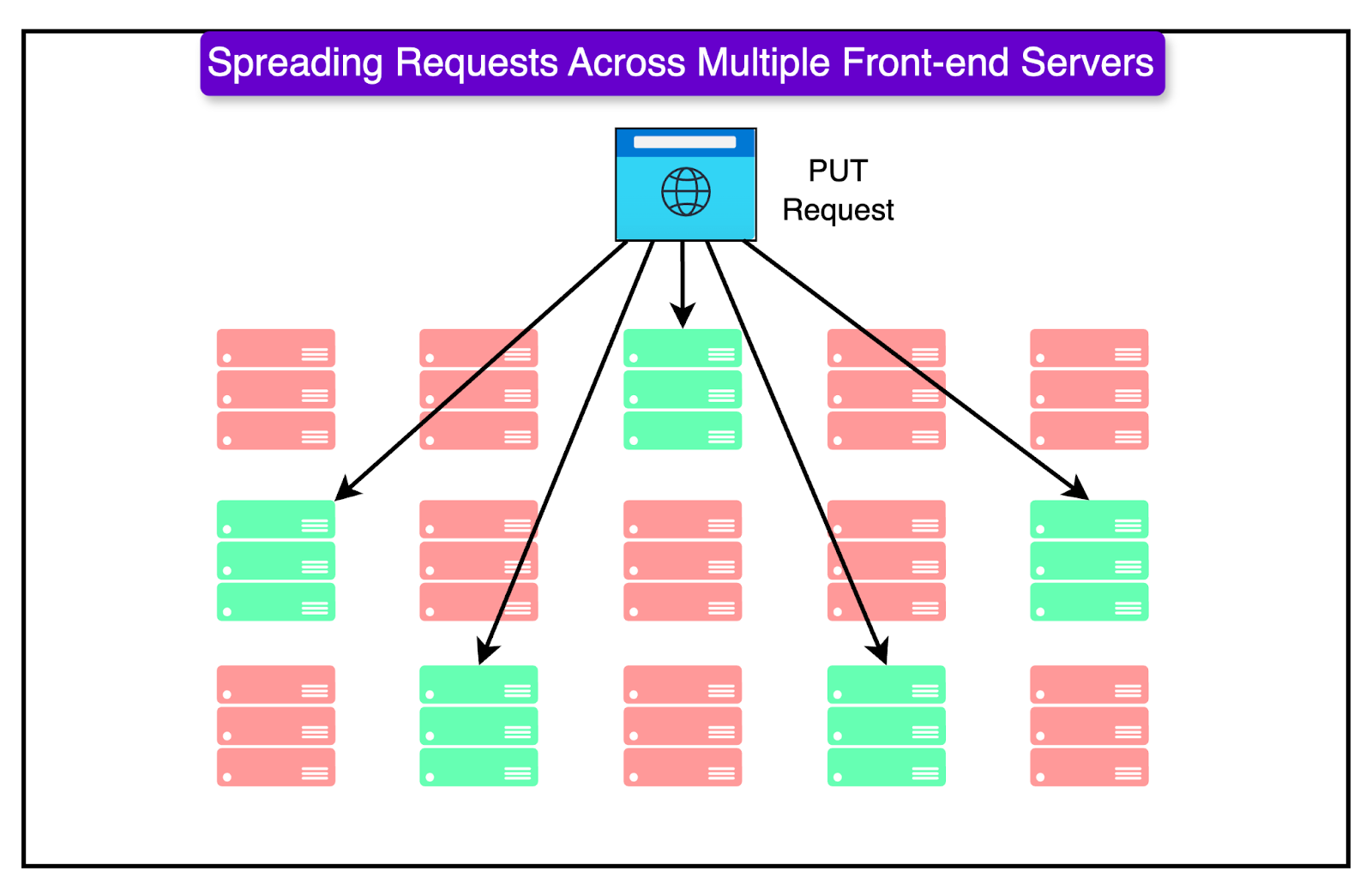
The request is forwarded to one of thousands of S3 front-end servers. These servers distribute traffic to minimize hotspots and avoid overload. Requests are load-balanced using Elastic Load Balancers (ELB).
AWS uses multi-value DNS to spread requests across multiple front-end servers. Also, global load balancing ensures that requests are routed to the nearest available S3 region.
Step 4: Object Indexing in the Metadata Store
Before storing the object, S3 needs to record its location in a distributed index.
The metadata store is responsible for tracking object names, sizes, storage locations, and permissions. Each S3 object key is mapped to a physical storage location. Lexicographic partitioning is used to distribute high-load buckets across multiple indexing servers.
The indexing plays a key role in fast retrieval. Instead of scanning billions of objects, S3 retrieves objects using index lookups. Background indexing ensures updates are consistent across all availability zones. Sharding distributes metadata across multiple servers to avoid bottlenecks.
Step 5: Data Placement and Storage
Once the metadata is recorded, the data must be physically stored in S3.
The object is split into multiple fragments and stored across multiple disks. AWS uses Erasure Coding (Reed-Solomon algorithms) to improve durability.
S3 automatically replicates the object across at least 3 availability zones. If one AZ goes offline, the data is still available from other locations. S3 also supports server-side encryption if required.
Step 6: Response Sent to the Client
Once the data is securely stored, Amazon S3 sends a response to the client. For example, the following snippet shows a successful response.
{
"ETag": "d41d8cd98f00b204e9800998ecf8427e",
"VersionId": "3i4aUVmMNBzHj1aJChF7sHG.jP0tGdrd"
}Here, ETag is the unique checksum of the stored object and VersionId is the object’s version.
The failure responses could be 403 (Forbidden), 503 (Slow Down), or 500 (AWS server issue). From an optimization point of view, features like S3 Select can query objects directly without downloading.
The Amazon S3 Index
Amazon S3 is one of the most scalable and high-performance storage services in the world, managing over 350 trillion objects and handling more than 100 million requests per second.
To achieve this massive scale while maintaining low-latency access, S3 employs sophisticated indexing mechanisms.
Indexing every object efficiently is crucial for:
Fast lookups
Consistent performance while handling billions of queries simultaneously
Scalability
Unlike traditional databases, S3’s indexing system is distributed across thousands of nodes to manage and retrieve billions of object metadata entries without bottlenecks.
Amazon S3's indexing infrastructure consists of three primary layers:
Global Metadata Store: Tracks object metadata, including bucket name, object key, and permissions.
Distributed Key Partitioning Engine: Spreads object keys across multiple index servers for load balancing.
Lexicographic Key Distribution: Ensures evenly distributed workloads across index partitions.
Unlike traditional databases that rely on sequential indexes, S3 dynamically partitions its index structure to scale infinitely.
How S3 Distributes Index Data?
S3 organizes object metadata using key partitioning, which ensures that lookup operations are fast and scalable.
Each object stored in S3 has a unique key (for example, “customer-data/reports/2025/rep.json”). S3 partitions the index based on key prefixes, spreading the load across thousands of storage nodes. These partitions allow S3 to retrieve objects in parallel, avoiding bottlenecks.
Without partitioning, a single index server would be overloaded, slowing down performance. For example, if S3 stored 1 billion objects in a single index, searching for an object would be extremely slow. Partitioning spreads the objects across thousands of smaller indexes, allowing rapid lookups.
Amazon S3’s indexing system is designed for 11 nines durability, ensuring data remains always available.
Index data is replicated across multiple availability zones. If an AZ goes down, requests are rerouted automatically. Background processes monitor and repair corrupt index entries. Index partitions dynamically expand as new objects are added, ensuring zero performance degradation.
Lexicographic Distribution: Avoiding Hotspots
Amazon S3 further optimizes partitioning using lexicographic key distribution, ensuring that workloads remain balanced.
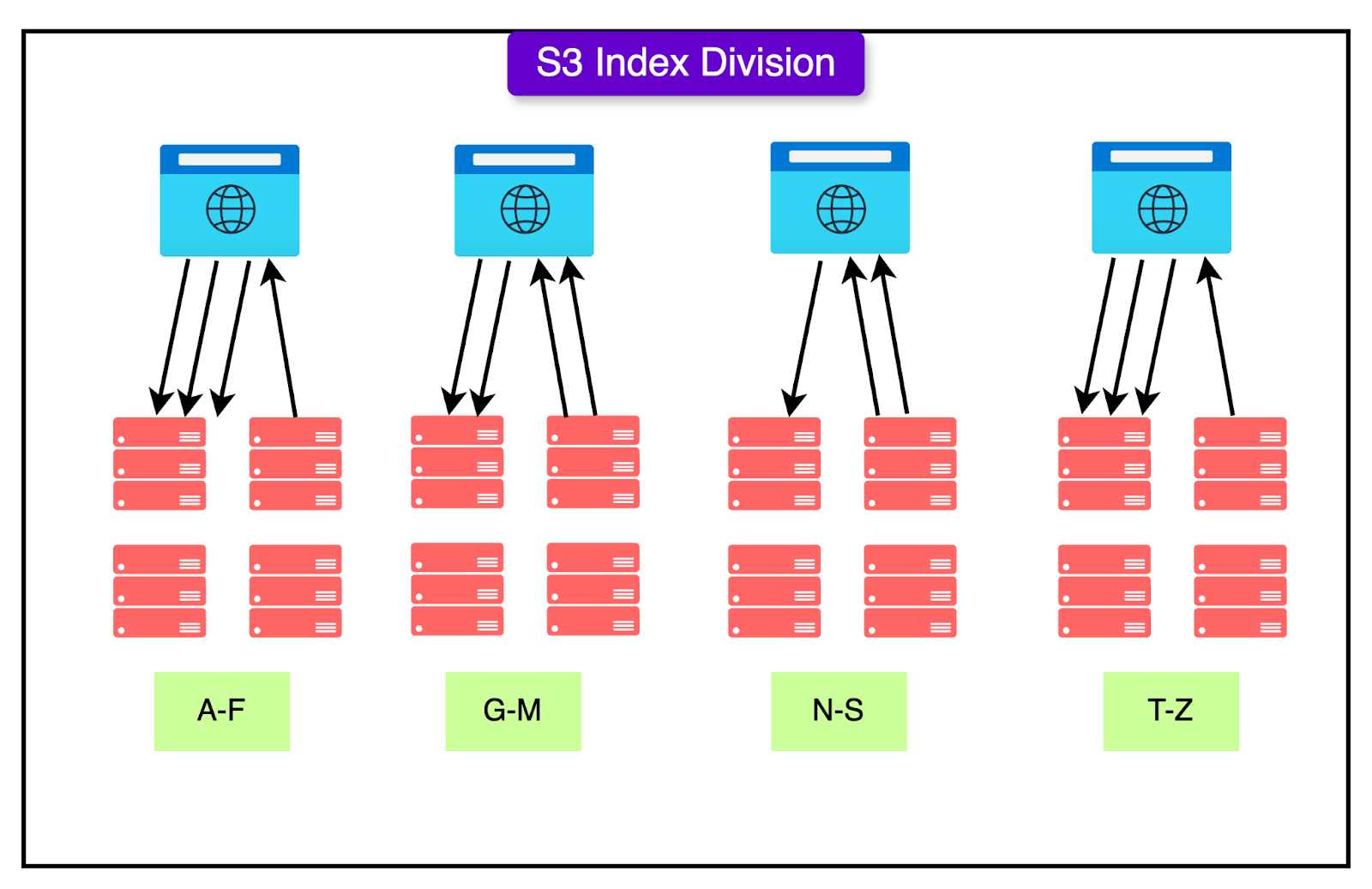
S3 sorts and distributes object keys alphabetically across storage nodes. This prevents overloading specific servers with frequently accessed objects. If certain key patterns become hotspots, S3 rebalances them dynamically.
For example, consider the following bad partitioning strategy:
/2024/reports/file1.json
/2024/reports/file2.json
/2024/reports/file3.jsonSince all keys start with "2024", S3 would route all requests to the same partition, creating a performance bottleneck.
Instead, a better partitioning strategy involves introducing more randomness.
By distributing keys more evenly, S3 ensures that requests are spread across multiple storage nodes. As a best practice, AWS recommends adding high-cardinality prefixes (random characters) at the beginning of keys to improve load balancing and retrieval speed.
Handling 100 Million+ Requests Per Second
Amazon S3’s distributed architecture allows it to handle millions of concurrent requests without slowing down.
Some specific points S3 takes care of are as follows:
S3 divides queries across thousands of index partitions, processing multiple requests at once.
Frequently accessed objects are cached for ultra-fast retrieval.
S3 continuously monitors request patterns and rebalances partitions dynamically to prevent bottlenecks.
Requests are routed to the lowest-latency region, optimizing response times.
Conclusion
Amazon S3 is a technological marvel. It can handle over 350 trillion objects and process more than 100 million requests per second with sub-millisecond latency.
S3’s ability to store and retrieve vast amounts of data at unprecedented speeds has made it the foundation for businesses, startups, and enterprises worldwide. Whether supporting media streaming, AI workloads, real-time analytics, or mission-critical applications, S3 continues to evolve, pushing the boundaries of what’s possible in cloud storage.
Some key takeaways are as follows:
By replicating metadata and storage across multiple AWS Availability Zones, S3 achieves 99.999999999% durability, ensuring data remains accessible even in the event of infrastructure failures.
S3 dynamically routes requests across the lowest-latency paths and spreads workloads efficiently to maintain high throughput.
Automated background processes monitor, rebalance, and repair indexing structures to ensure seamless scalability.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
nice
2024 - S3 Tables