
How Atlassian Migrated 4 Million Jira Databases to AWS Aurora

✂️ Cut your QA cycles down to minutes with QA Wolf (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Atlassian Engineering Team. All credit for the technical details goes to the Atlassian Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Most companies struggle to migrate a handful of databases without causing downtime. Atlassian routinely migrates about 1,000 databases every day as part of its regular operations, and its users never notice.
However, in 2024, they tackled something far more ambitious: migrating 4 million databases with minimal user impact.
The numbers alone are staggering. Atlassian's Jira platform uses a one-database-per-tenant approach, spreading 4 million PostgreSQL databases across 3,000 server instances in 13 AWS regions worldwide. Each database contains everything for a Jira tenant: issues, projects, workflows, and custom fields.
Their goal was to move everything from AWS RDS PostgreSQL to AWS Aurora PostgreSQL. The benefits were compelling:
Better cost efficiency
Improved reliability (upgrading from 99.95% to 99.99% uptime)
Enhanced performance through Aurora's ability to automatically scale up to 15 reader instances during peak loads.
The constraints were equally challenging. They needed to keep downtime under 3 minutes per tenant, control infrastructure costs during the migration, and complete the entire project within months rather than years.
In this article, we will look at how Atlassian carried out this migration and the challenges they faced.
Migration Strategy
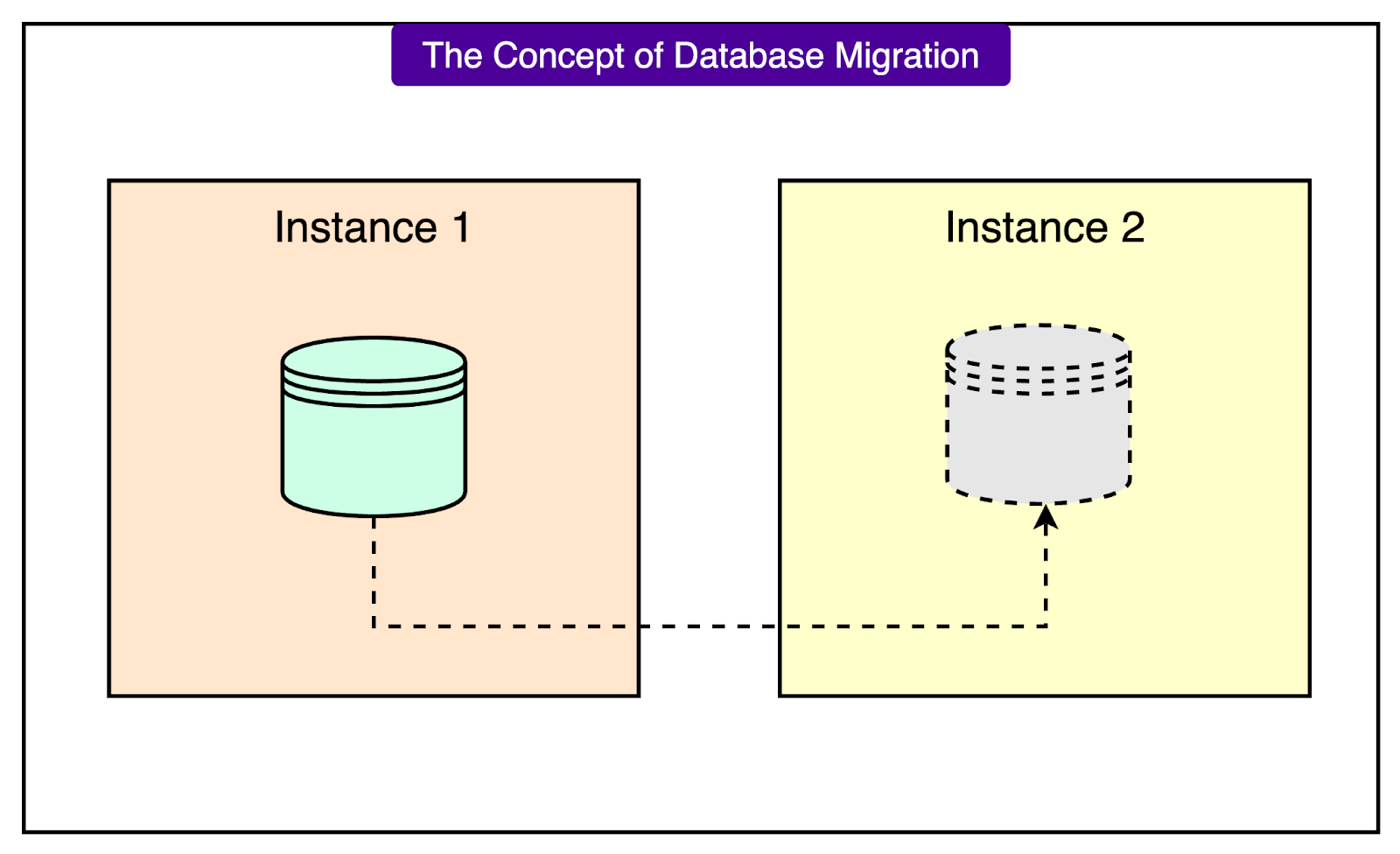
Atlassian's team chose what seemed like a textbook approach for migrating from RDS to Aurora. This process is also known as “conversion”.
See the diagram below:
Here's how the process was designed to work:
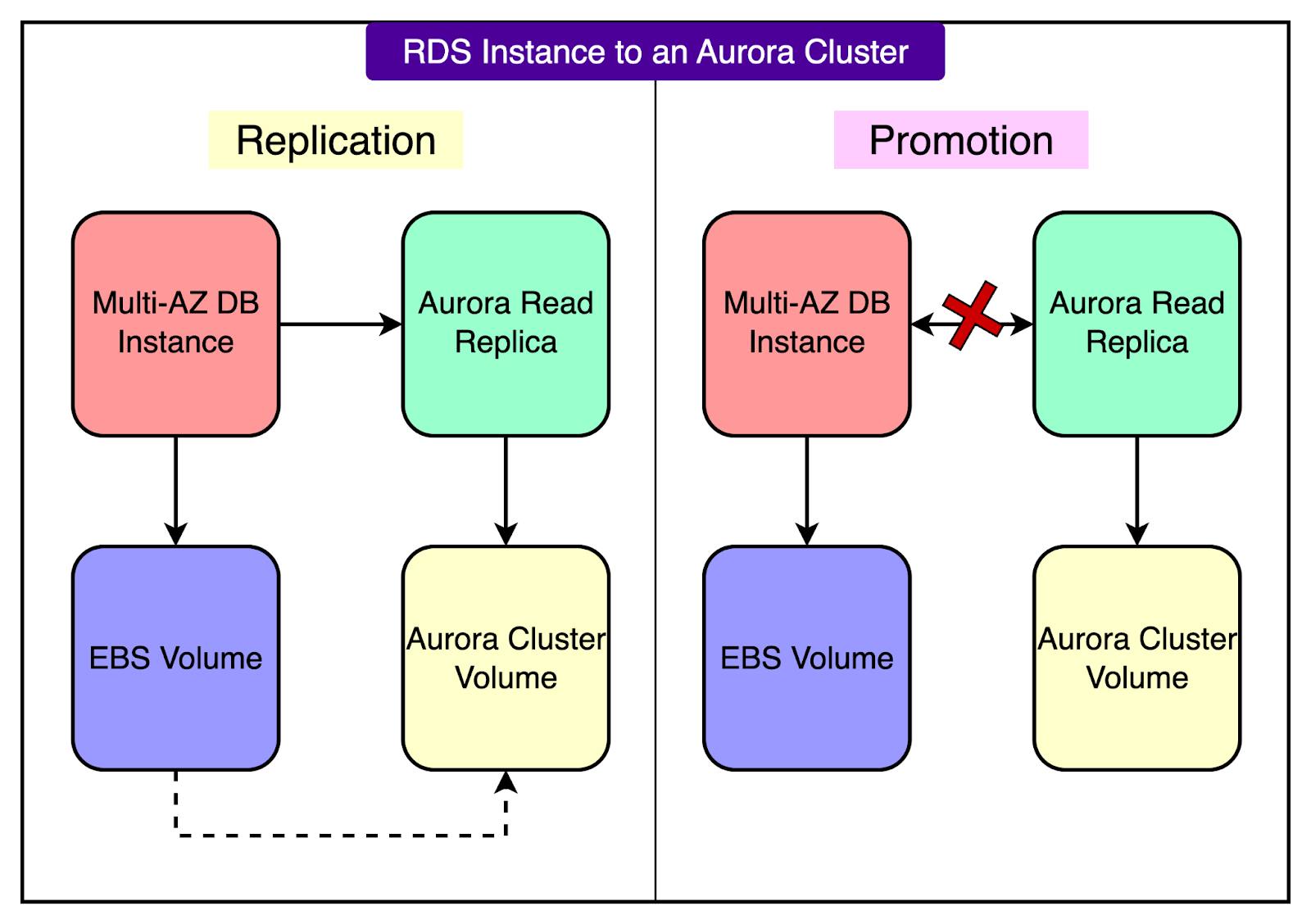
Step 1 (Create a Read Replica): Instead of trying to copy databases while they're actively being used, they created read replicas. Think of a read replica as a live, constantly-updated copy of the original database. AWS RDS has a built-in feature that lets you create an Aurora read replica from an existing RDS PostgreSQL instance. This replica automatically synchronizes all the data to a new Aurora cluster volume in the background while the original database continues serving users normally.
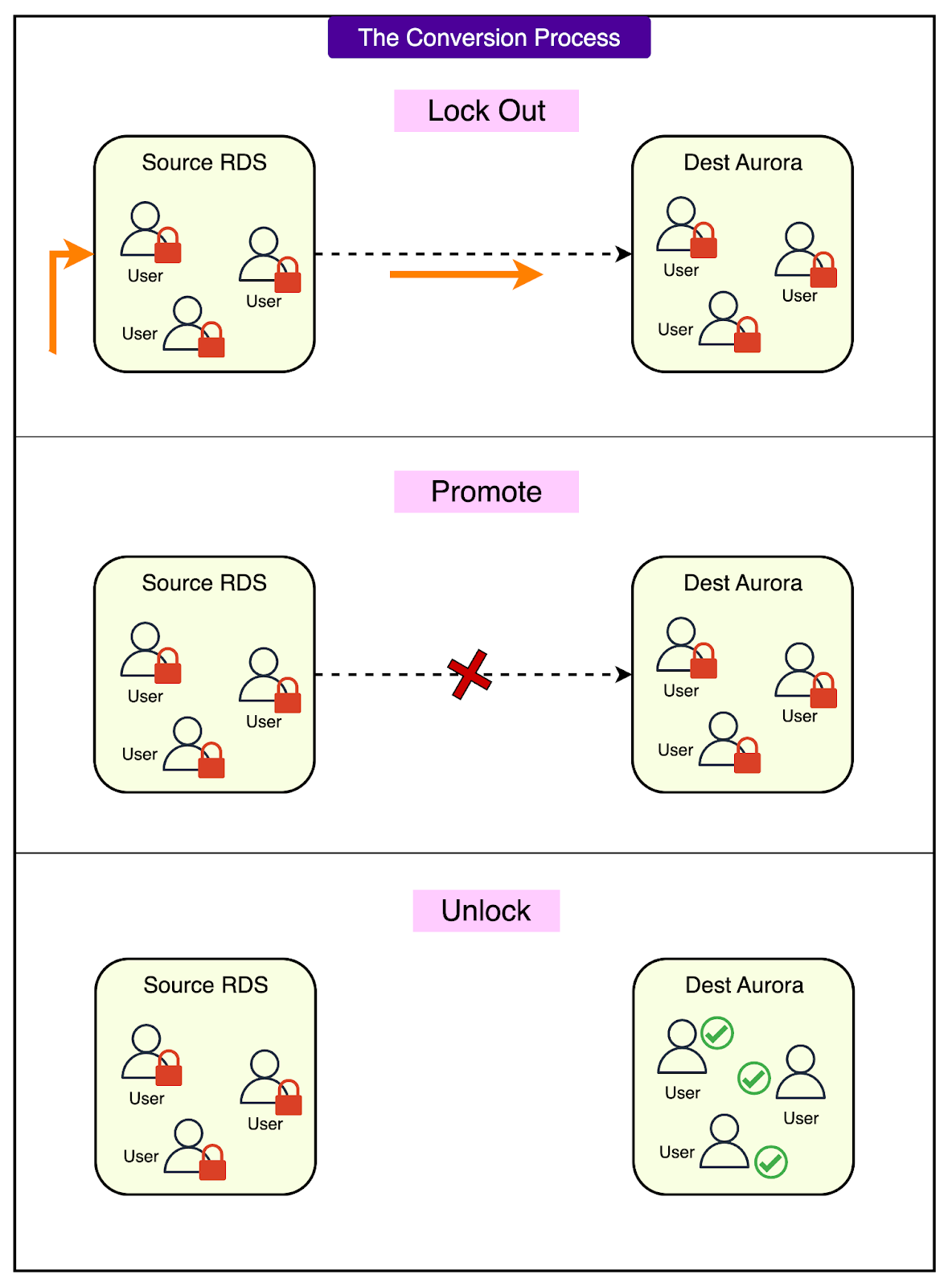
Step 2 (The Coordinated Cutover): Here's where things get complex. Each database cluster at Atlassian hosts up to 4,000 individual tenant databases. That means when it's time to switch from the old RDS instance to the new Aurora cluster, they need to coordinate the cutover for all 4,000 tenants simultaneously. The cutover process worked like this:
Lock out all users on the source RDS database (preventing any new writes)
Promote the read replica to become a standalone Aurora cluster
Update all application connections to point to the new Aurora endpoints
Unlock users only on the new Aurora destination
Step 3 (Orchestration with AWS Step Functions): To manage this complex process, they used AWS Step Functions, which is like a sophisticated workflow engine that can coordinate multiple AWS services. The Step Functions handled all the safety checks before, during, and after the conversion. If anything went wrong at any stage, it could automatically roll back to the previous state.
See the diagram below for a detailed look at the conversion process.
Lastly, they also used feature flags that let them instantly redirect database connections. Instead of waiting for applications to slowly discover the new database endpoints (which could take time), feature flags allowed them to override the tenant database endpoints immediately across all application servers.
The most impressive part was that they managed to keep the actual cutover time to less than 3 minutes, even for their largest instances. This was possible because the heavy lifting (data synchronization) happened ahead of time through the read replica, and the feature flags enabled instant endpoint switching.
The Advantages of Aurora
The key advantages of using Aurora were as follows:
The RDS Limitation Problem: With their existing RDS setup, Atlassian could only use one database instance (the primary) at a time. Even though RDS technically supports read replicas, their configuration didn't allow them to effectively use both the writer and reader instances simultaneously for production workloads.
Aurora's Dual-Instance Advantage: Aurora changed this completely. With Aurora, they could access both the writer instance and the reader instances (multiple readers if necessary) at the same time.
Smart Instance Downsizing: This dual-instance capability enabled them to downsize their instances from m5.4xlarge (16 vCPUs, 64 GB RAM) to r6.2xlarge (8 vCPUs, 64 GB RAM). Normally, halving your CPU would hurt performance, but since Aurora let them use both writer and reader instances, they effectively had the same total CPU power available (or more during scale-out events). It's like trading one large server for two smaller servers that cost less to run.
Auto-Scaling Magic: During peak business hours, Aurora can automatically spin up additional reader instances, up to 15 total. During off-peak hours, it scales back down, dramatically reducing the instance footprint and costs.
Reliability Upgrade: The move also upgraded their Service Level Agreement (SLA) from 99.95% (RDS) to 99.99% (Aurora). That might seem like a tiny difference, but it means Aurora can have 75% less downtime per year, dropping from about 4.4 hours of allowable downtime annually to just 52 minutes.
The Economics: While they ended up with nearly triple the number of Aurora cluster instances compared to their original RDS instances, the combination of smaller instance sizes, auto-scaling behavior, and dual-instance utilization meant significantly better cost efficiency.
The File Count Limit Problem
Just when everything seemed to be going smoothly, Atlassian hit a wall that nobody saw coming.
During their testing phase, AWS support contacted them with concerning news: one of their large test RDS instances had successfully synchronized all its data to Aurora, but the new Aurora cluster had failed to start up properly.
From Atlassian's perspective, everything looked fine in the AWS console. The replica appeared healthy and still replicating. However, AWS's internal monitoring had detected that the Aurora instance's startup process had timed out and failed, even though the surface indicators suggested everything was working normally.
To understand what went wrong, we need to know how PostgreSQL stores data on disk. In PostgreSQL, every high-level database object gets stored as at least one file on the server's hard drive:
Every table = at least 1 file
Every index = at least 1 file
Every sequence (used for auto-incrementing IDs) = at least 1 file
Plus, various other database objects
However, Jira applications have particularly complex database schemas because they need to handle:
Issues and their custom fields
Projects and workflows
User permissions and configurations
Search indexes for fast queries
Audit logs and history tracking
All this complexity means that a single Jira database needs approximately 5,000 files on disk to store all its tables, indexes, and sequences. For 4000 tenants per cluster, this means 20 million files per Aurora cluster.
When an Aurora instance starts up, it performs various status checks to ensure everything is healthy. One of these checks involves enumerating (counting and cataloging) all the files in the cluster volume. This process is normally quick and invisible to users.
However, when there are 20+ million files, this enumeration process takes a very long time. Aurora has internal timeout thresholds for how long startup processes are allowed to run. With Atlassian's massive file counts, the enumeration was taking longer than Aurora's startup timeout threshold, causing the instance to fail during boot-up.
To handle this problem, the team had only two options to reduce file counts:
Reduce files per database (not practical since Jira needs its complex schema to function).
Reduce the number of databases per cluster (the only viable path).
The solution they developed would become known as "draining".
The Draining Solution
Faced with the file count limitation, Atlassian developed an elegant solution that turned the problem into an opportunity. Instead of fighting the constraints, they embraced a new workflow that would improve their infrastructure efficiency.
See the diagram below:
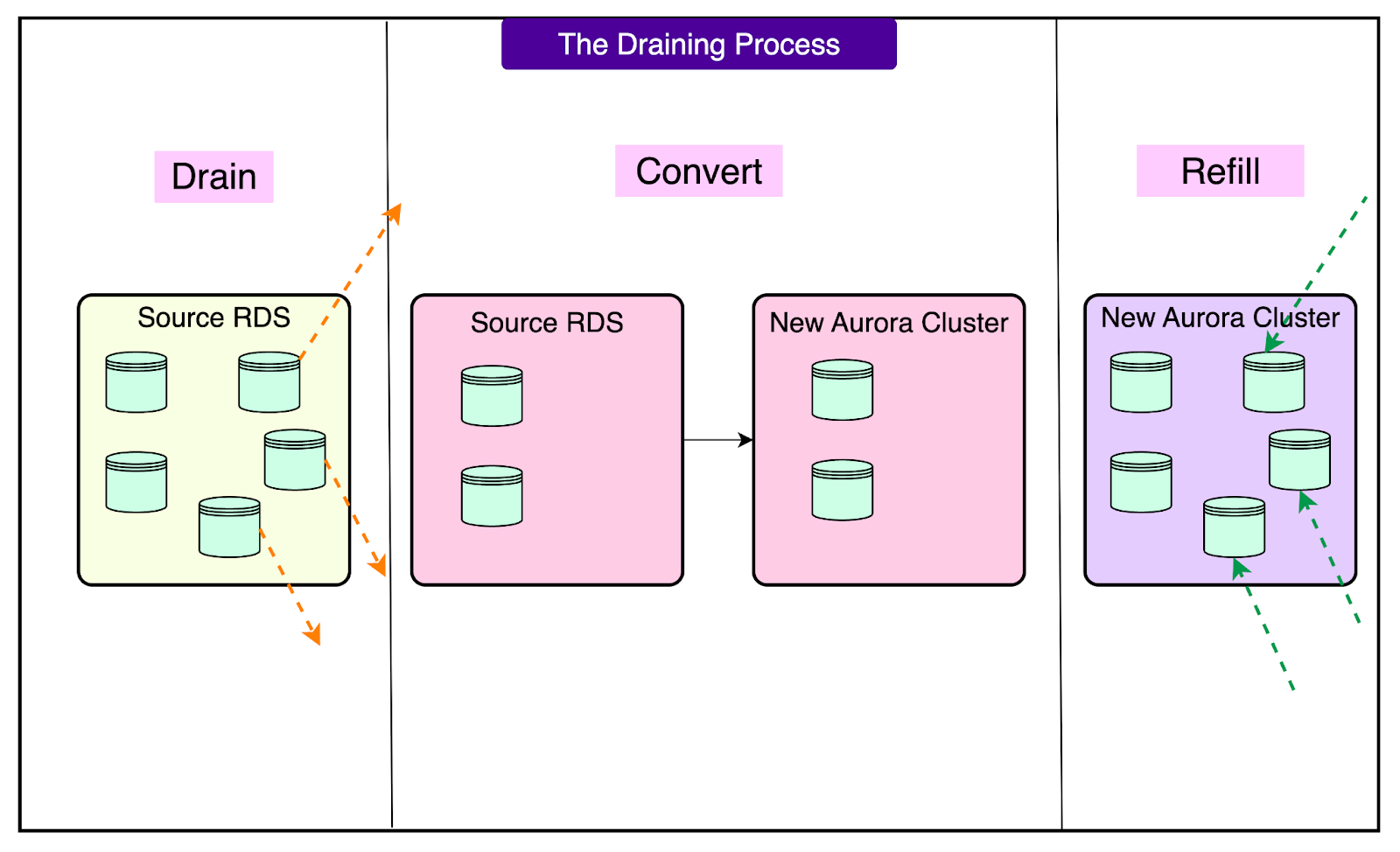
Step 1: Drain
"Draining" means moving tenant databases off an RDS instance until it reaches a safe file count threshold that Aurora can handle during startup. Instead of 4,000 tenants per instance (20 million files), they needed to reduce this to a much smaller number.
The draining process used their existing database migration tools, but at a completely different scale. They prioritized moving the smallest tenants with the least usage first because:
Smaller databases mean less data to transfer, which results in faster migrations.
Lower usage means less impact during the brief cutover windows.
Higher throughput overall since they could complete more migrations per day.
Step 2: Convert
Once an RDS instance was drained to safe file count levels, they could proceed with the standard RDS to Aurora conversion process:
Create the Aurora read replica
Let it synchronize
Perform the coordinated cutover
Clean up the old RDS instance after a safety period
With fewer tenants, this conversion process became much more reliable and predictable.
Step 3: Refill
Instead of leaving the new Aurora clusters half-empty, they immediately started using them as destinations for draining other RDS instances.
AWS had confirmed that once an RDS instance was successfully converted to Aurora, they could re-populate it with tenant databases up to sensible limits. This meant they didn't need to permanently reduce their tenant density. They just needed to reduce it temporarily during the conversion process.
The Daisy Chain Approach
This three-step process created what Atlassian called a "daisy chain" of conversions:
Instance A gets drained and converted to Aurora to become a refill target.
Instance B gets drained (tenants go to converted Instance A) and gets converted to become the next refill target
Instance C gets drained (tenants go to converted Instance B) and gets converted
And so on...
This approach had a huge advantage: minimal infrastructure overhead.
Instead of needing to provision massive amounts of temporary infrastructure to hold displaced tenants, they only needed enough extra capacity to accommodate the tenants from one or two instances being converted at any given time.
Through careful optimization and tooling improvements, they achieved remarkable scaling:
Average draining performance: 38,000 daily migrations (38× normal capacity).
Peak draining performance: 90,000 daily migrations (90× normal capacity).
Maintained high reliability targets throughout the entire scale-up.
Conclusion
In the end, Atlassian had accomplished something remarkable in the world of database migrations. The final statistics paint a picture of an operation that succeeded on every measure:
Here’s a quick look at the migration scale:
2403 RDS instances successfully converted to Aurora clusters.
2.6 million databases were migrated during the conversion processes.
1.8 million additional databases were moved during the draining operations.
27.4 billion individual files processed across the entire project.
The final Aurora infrastructure looked dramatically different from where they started, but in all the right ways:
They ended up with nearly triple the number of Aurora cluster instances compared to their original RDS setup. This resulted in 6482 Aurora instances active during peak business hours. At first glance, this might seem like a step backward, but the economics told a different story.
Through Aurora's auto-scaling capabilities, these instances automatically scale down during off-peak hours, dramatically reducing their infrastructure footprint when demand is low. During busy periods, they have more capacity available than ever before. During quiet periods, they're paying for a fraction of what they used to maintain.
The instance downsizing strategy (m5.4xlarge to r6.2xlarge) proved to be a masterstroke. By halving the instance size while gaining access to both writer and reader instances, they achieved the same or better performance at significantly lower cost.
Atlassian's Aurora migration represents more than just a successful database platform upgrade. Their collaboration with AWS throughout this process led to a better understanding of Aurora's operational limits and likely influenced future improvements to the platform.
The project delivered on all its original objectives: significant cost savings through better resource utilization, improved reliability through Aurora's superior SLA, and enhanced performance through auto-scaling capabilities. But perhaps most importantly, they accomplished all of this while maintaining their commitment to minimal user impact.
References:
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.

What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
What if the aurora instance needs to be started again after the migration? Are they going to run into the same file count limit.
I have a question about Atlassian’s database architecture to Atlassian developers. As I understand it, Atlassian keeps all tables aka domain entities (bounded contexts) in a single per tenant database. Does it make hard to develop services and not get into a trap of interconnected dependencies or hot databases? What are the pros and cons of this approach compared to splitting the data by logical parts (per context/service) and sharding each part, while hosting everything together? Is the latter more scalable and configurable in practice?