
How Cloudflare Eliminates Cold Starts for Serverless Workers

Cut Code Review Time & Bugs in Half (Sponsored)

Code reviews are critical but time-consuming. CodeRabbit acts as your AI co-pilot, providing instant Code review comments and potential impacts of every pull request.
Beyond just flagging issues, CodeRabbit provides one-click fix suggestions and lets you define custom code quality rules using AST Grep patterns, catching subtle issues that traditional static analysis tools might miss.
CodeRabbit reviews 1 million PRs every week across 3 million repositories and is used by 100 thousand Open-source projects.
CodeRabbit is free for all open-source repo’s.
Cloudflare has reduced cold start delays in its Workers platform by 10 times through a technique called worker sharding.
A cold start occurs when serverless code must initialize completely before handling a request. For Cloudflare Workers, this initialization involves four distinct phases:
Fetching the JavaScript source code from storage
Compiling that code into executable machine instructions
Executing any top-level initialization code
Finally, invoking the code to handle the incoming request
See the diagram below:
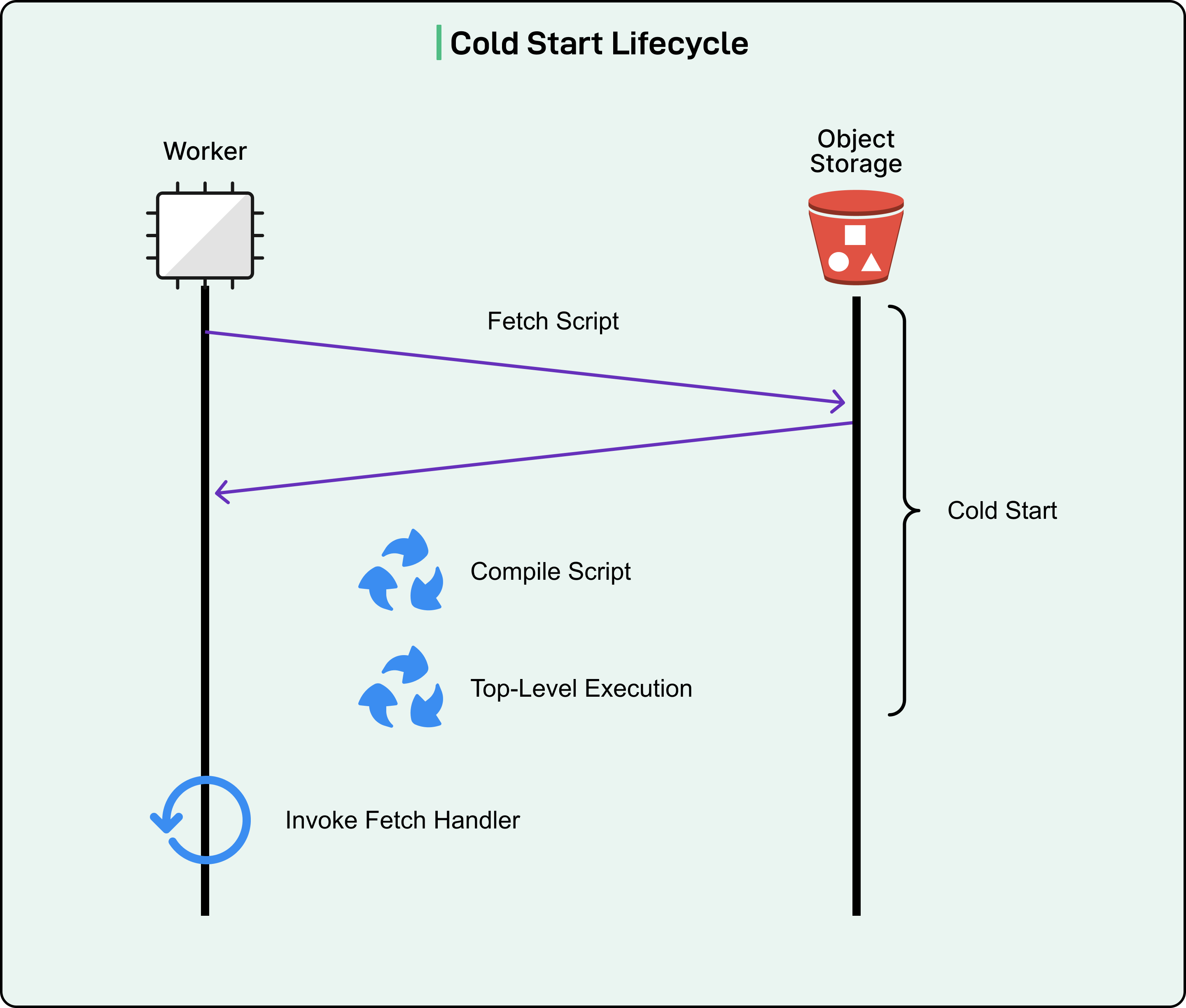
The improvement around cold starts means that 99.99% of requests now hit already-running code instances instead of waiting for code to start up.
The overall solution works by routing all requests for a specific application to the same server using a consistent hash ring, reducing the number of times code needs to be initialized from scratch.
In this article, we will look at how Cloudflare built this system and the challenges it faced.
Disclaimer: This post is based on publicly shared details from the Cloudflare Engineering Team. Please comment if you notice any inaccuracies.
The Initial Solution
In 2020, Cloudflare introduced a solution that masked cold starts by pre-warming Workers during TLS handshakes.
TLS is the security protocol that encrypts web traffic and makes HTTPS possible. Before any actual data flows between a browser and server, they perform a handshake to establish encryption. This handshake requires multiple round-trip messages across the network, which takes time.
The original technique worked because Cloudflare could identify which Worker to start from the Server Name Indication (SNI) field in the very first TLS message. While the rest of the handshake continued, they would initialize the Worker in the background. If the Worker finished starting up before the handshake completed, the user experienced zero visible delay.
See the diagram below:
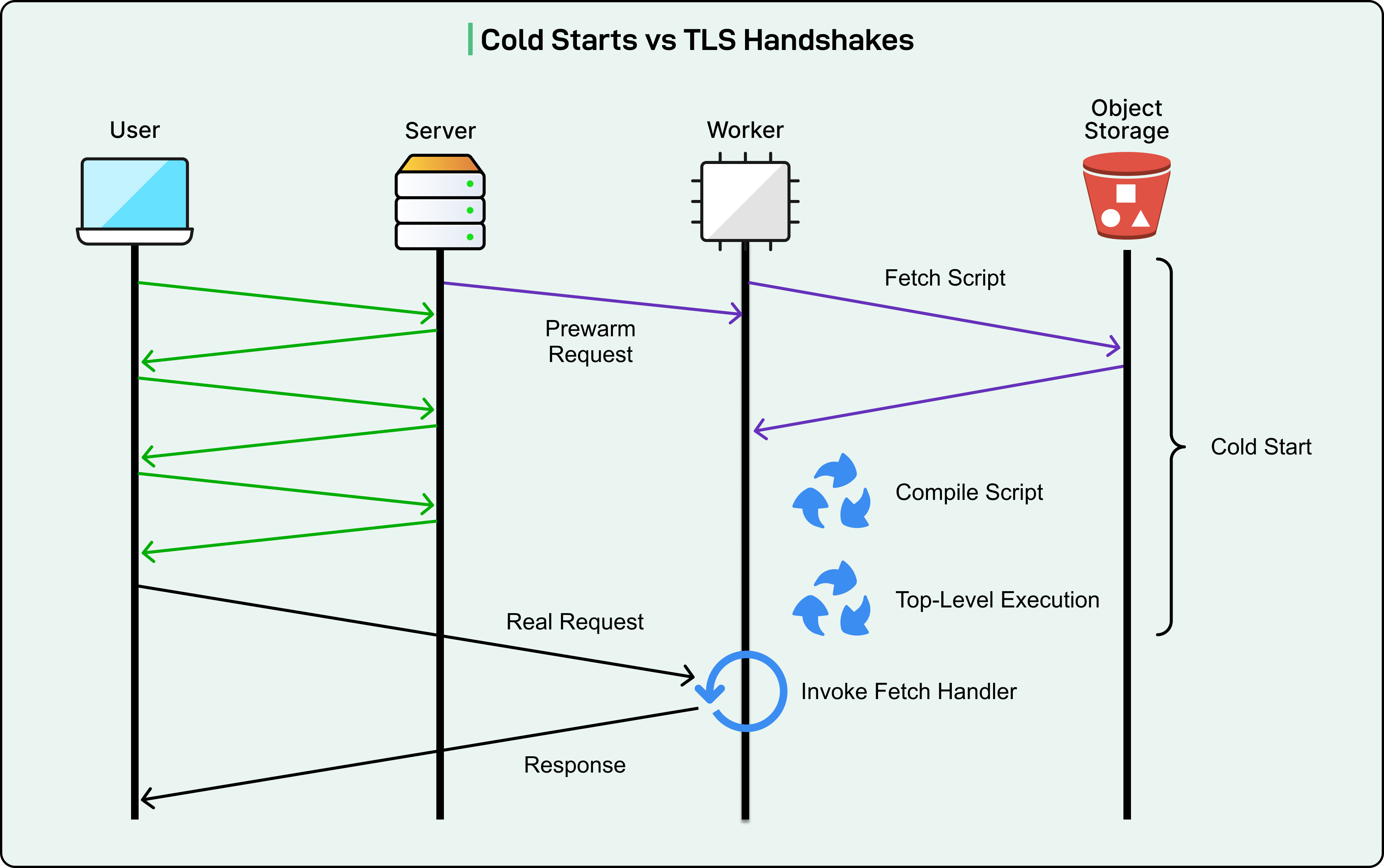
This technique succeeded initially because cold starts took only 5 milliseconds while TLS 1.2 handshakes required three network round-trips. The handshake provided enough time to hide the cold start entirely.
Why Cold Starts Became a Problem Again
The effectiveness of the TLS handshake technique depended on a specific timing relationship in which cold starts had to complete faster than TLS handshakes. Over the past five years, this relationship broke down for two reasons.
First, cold starts became longer. Cloudflare increased Worker script size limits from 1 megabyte to 10 megabytes for paying customers and to 3 megabytes for free users. They also increased the startup CPU time limit from 200 milliseconds to 400 milliseconds. These changes allowed developers to deploy much more complex applications on the Workers platform. Larger scripts require more time to transfer from storage and more time to compile. Longer CPU time limits mean initialization code can run for longer periods. Together, these changes pushed cold start times well beyond their original 5-millisecond duration.
Second, TLS handshakes became faster. TLS 1.3 reduced the handshake from three round-trips to just one round-trip. This improvement in security protocols meant less time to hide cold start operations in the background.
The combination of longer cold starts and shorter TLS handshakes meant that users increasingly experienced visible delays. The original solution no longer eliminated the problem.
Reducing Cold Starts Through Better Request Routing
Cloudflare realized that further optimizing cold start duration directly would be ineffective. Instead, they needed to reduce the absolute number of cold starts happening across their network.
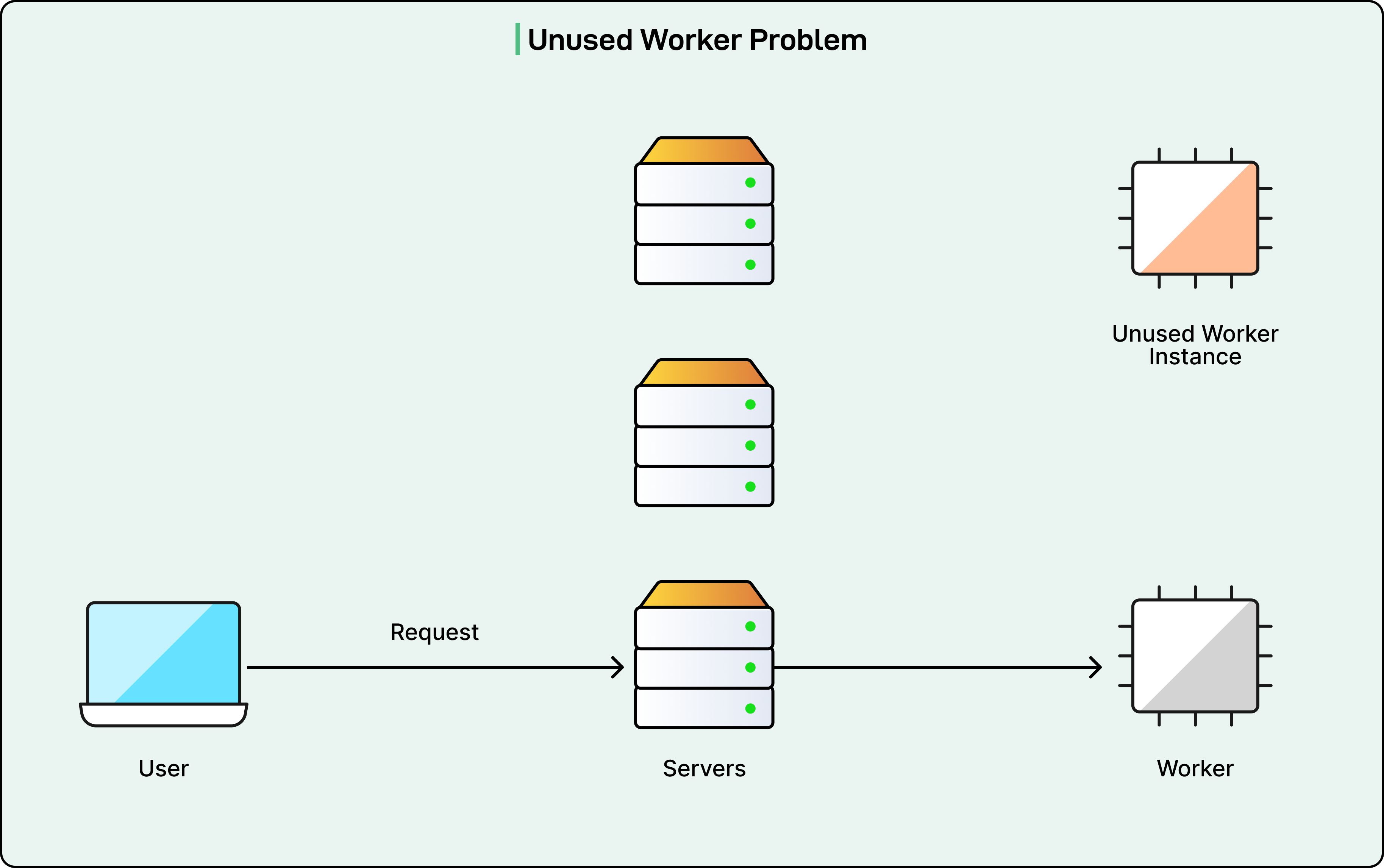
The key insight involved understanding how requests were distributed across servers. Consider a Cloudflare data center with 300 servers. When a low-traffic application receives one request per minute, load balancing distributes these requests evenly across all servers. Each server receives one request approximately every five hours.
This distribution creates a problem. In busy data centers, five hours between requests is long enough that the Worker must be shut down to free memory for other applications. When the next request arrives at that server, it triggers a cold start. The result is a 100% cold start rate for low-traffic applications.
The solution involves routing all requests for a specific Worker to the same server within a data center. If all requests go to one server, that server receives one request per minute rather than one request every five hours. The Worker stays active in memory, and subsequent requests find it already running.
This approach provides multiple benefits. The application experiences mostly warm requests with only one initial cold start. Memory usage drops by over 99% because 299 servers no longer need to maintain copies of the Worker. This freed memory allows other Workers to stay active longer, creating improved performance across the entire system.
How Consistent Hash Rings Enable Efficient Sharding
Cloudflare borrowed a technique from its HTTP caching system to implement worker sharding. The core data structure is called a consistent hash ring.
A naive approach to assigning Workers to servers would use a standard hash table. In this approach, each Worker identifier maps directly to a specific server address. This works fine until servers crash, get rebooted, or are added to the data center. When the number of servers changes, the entire hash table must be recalculated. Every Worker would get reassigned to a different server, causing universal cold starts.
A consistent hash ring solves this problem. Instead of directly mapping Workers to servers, both are mapped to positions on a number line that wraps around from end to beginning. Think of a clock face where positions range from 0 to 359 degrees.
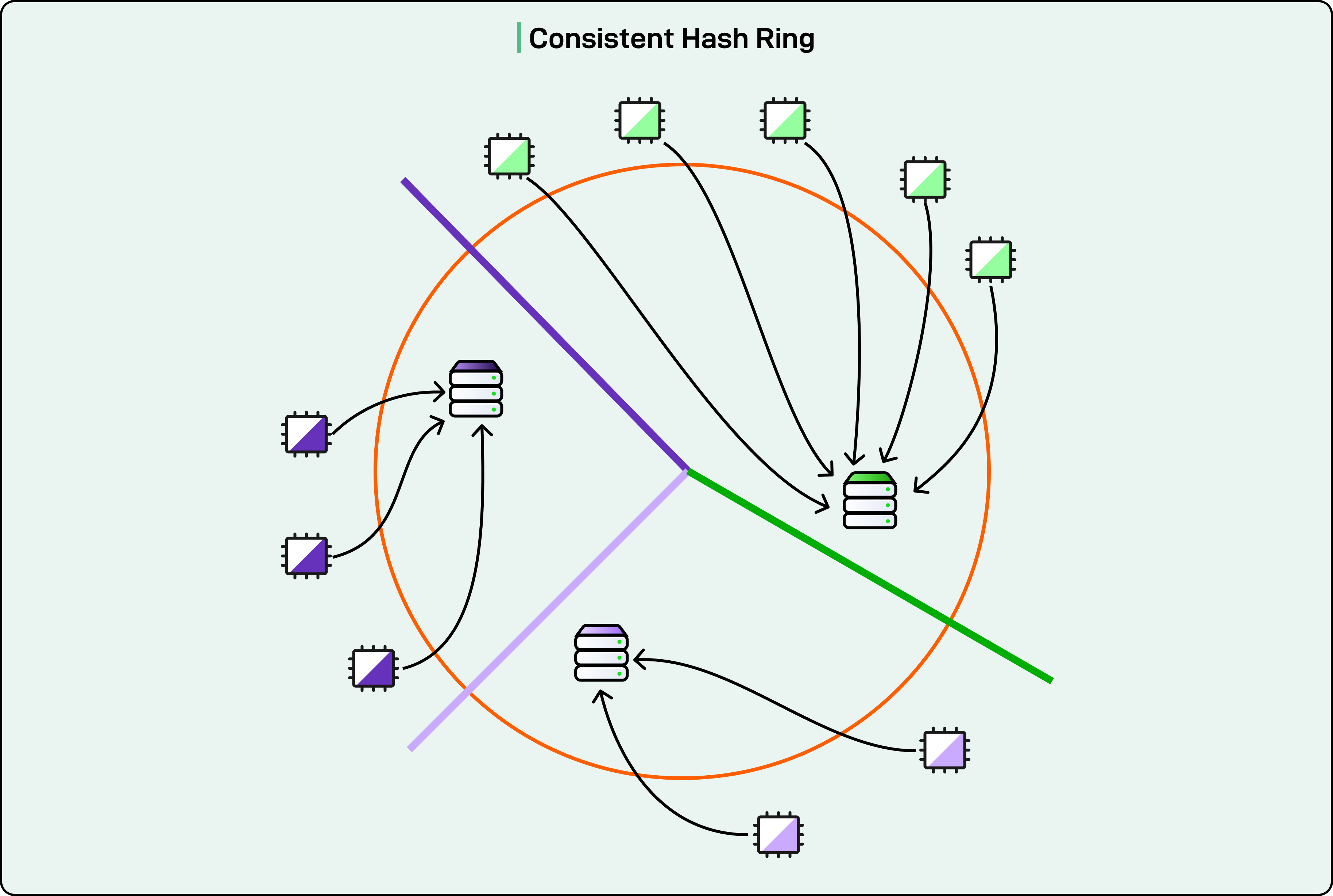
The assignment process works as follows:
Hash each server address to a position on the ring
Hash each Worker identifier to a position on the ring
Assign each Worker to the first server encountered, moving clockwise from the Worker’s position
When a server disappears from the ring, only the Workers positioned immediately before it need reassignment. All other Workers remain with their current servers.
Similarly, when a new server joins, only Workers in a specific range move to the new server.
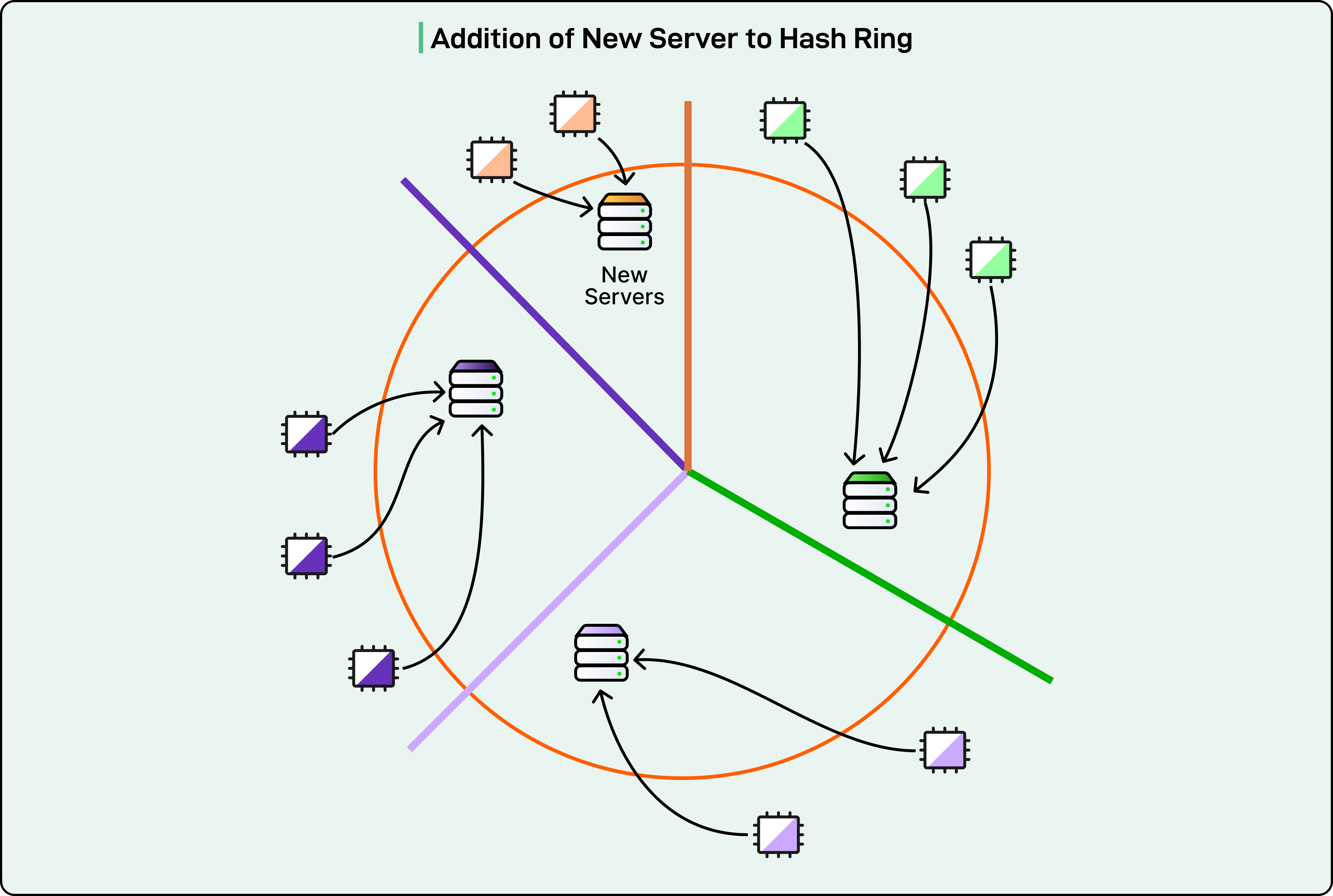
This stability is crucial for maintaining warm Workers. If the server constantly reshuffled Worker assignments, the benefits of routing requests to the same server would disappear.
Request Flow with Worker Sharding
The sharding system introduces two server roles in request handling:
The shard client is the server that initially receives a request from the internet.
The shard server is the home server for that specific Worker according to the consistent hash ring.
When a request arrives, the shard client looks up the Worker’s home server using the hash ring. If the shard client happens to be the home server, it executes the Worker locally. Otherwise, it forwards the request to the appropriate shard server over the internal data center network.
Forwarding requests between servers adds latency. Each forwarded request must travel across the data center network, adding approximately one millisecond to the response time. However, this overhead is much less than a typical cold start, which can take hundreds of milliseconds. Forwarding a request to a warm Worker is always faster than starting a cold Worker locally.
Handling Server Overload Without Errors
Worker sharding can concentrate traffic onto fewer servers, which creates a new problem. Individual Workers can receive enough traffic to overload their home server. The system must handle this situation gracefully without serving errors to users.
Cloudflare evaluated two approaches for load shedding:
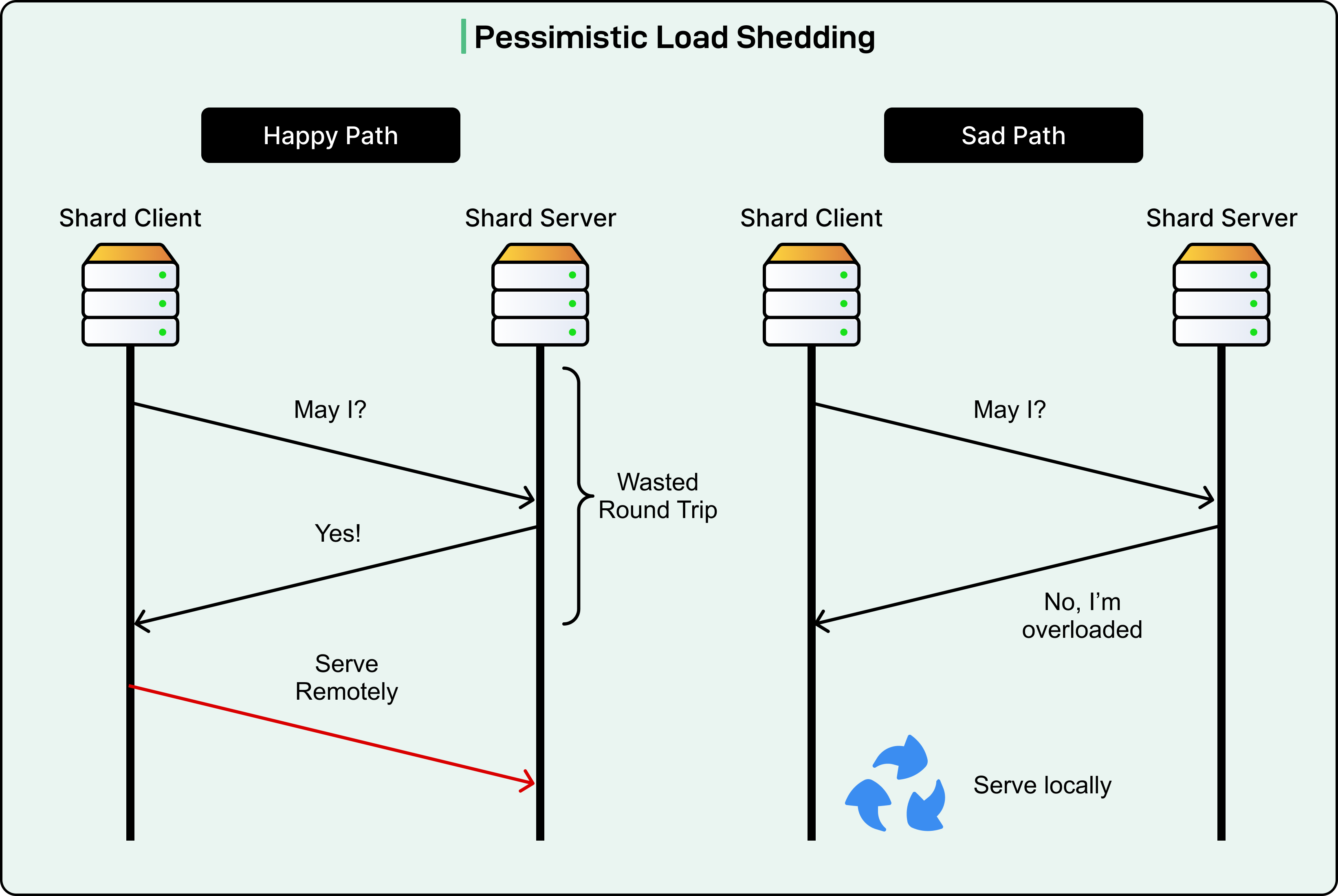
The first approach has the shard client ask permission before sending each request. The shard server responds with either approval or refusal. If refused, the shard client handles the request locally by starting a cold Worker. This permission-based approach introduces an additional latency of one network round-trip on every sharded request. The shard client must wait for approval before sending the actual request data.
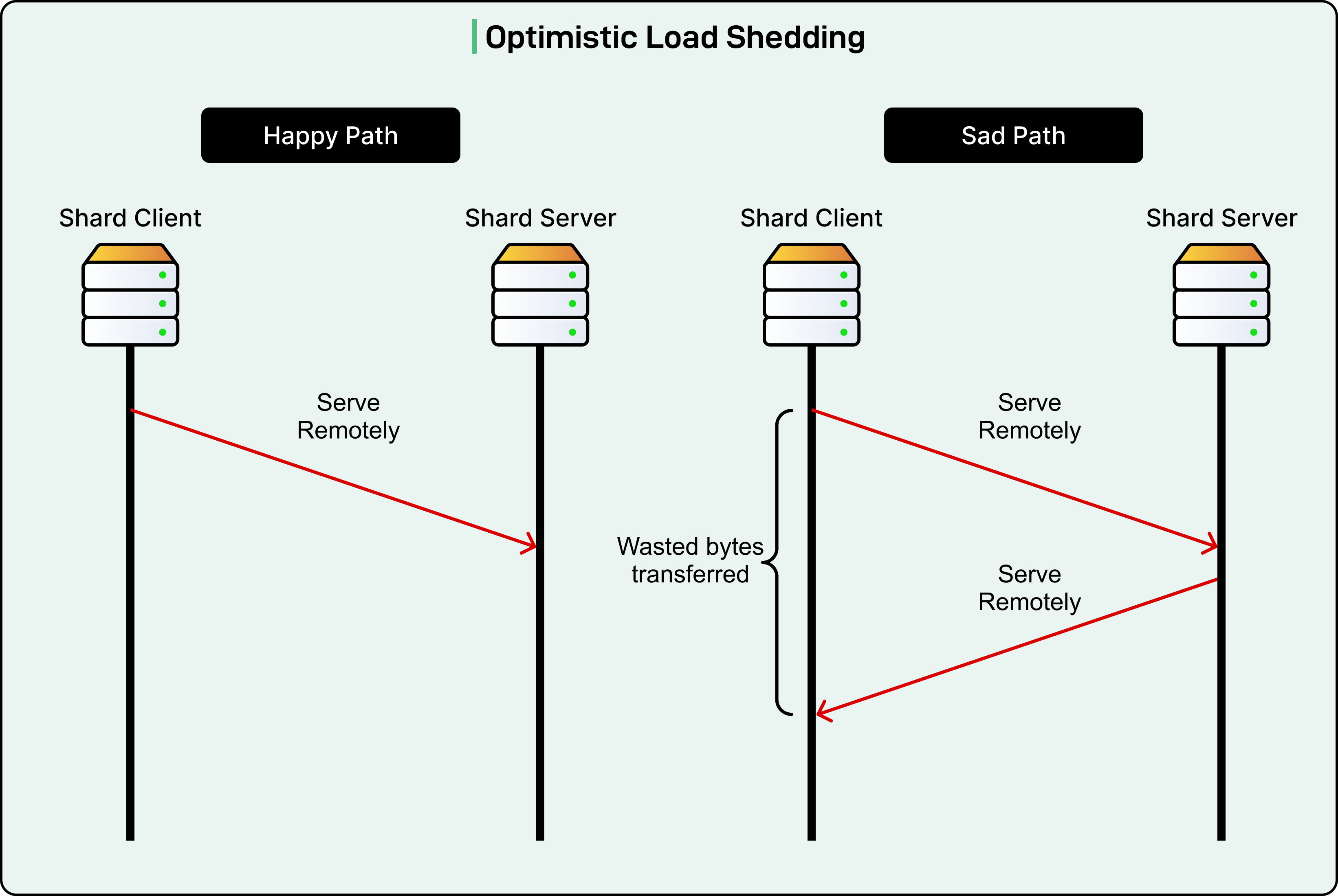
The second approach sends the request optimistically without waiting for permission. If the shard server becomes overloaded, it forwards the request back to the shard client. This avoids the round-trip latency penalty when the shard server can handle the request, which is the common case.
See the diagram below that shows the pessimistic approach:
Cloudflare chose the optimistic approach for two reasons.
First, refusals are rare in practice. When a shard client receives a refusal, it starts a local Worker instance and serves all future requests locally. After one refusal, that shard client stops sharding requests for that Worker until traffic patterns change.
Second, Cloudflare developed a technique to minimize the cost of forwarding refused requests back to the client.
See the diagram below:
Using Cap’n Proto RPC for Efficient Request Handling
The Workers runtime uses Cap’n Proto RPC for communication between server instances.
Cap’n Proto provides a distributed object model that simplifies complex scenarios. When assembling a sharded request, the shard client includes a special handle called a capability. This capability represents a lazy Worker instance that exists on the shard client but has not been initialized yet. The lazy Worker has the same interface as any other Worker, but only starts when first invoked.
If the shard server must refuse the request due to overload, it does not send a simple rejection message. Instead, it returns the shard client’s own lazy capability as the response.
The shard client’s application code receives a Worker capability from the shard server. It attempts to invoke this capability to handle the request. The RPC system recognizes that this capability actually points back to a local lazy Worker. Once it realizes the request would loop back to the shard client, it stops sending additional request bytes to the shard server and handles everything locally.
This mechanism prevents wasted bandwidth. Without it, the shard client might send a large request body to the shard server, only to have the entire body forwarded back again. Cap’n Proto’s distributed object model automatically optimizes this pattern by recognizing local capabilities and short-circuiting the communication path.
Supporting Complex Worker Invocation Patterns
Many Cloudflare products involve Workers invoking other Workers.
Service Bindings allow one Worker to call another directly. Workers KV, despite appearing as a storage service, actually involves cross-Worker invocations. However, the most complex scenario involves Workers for Platforms.
Workers for Platforms enables customers to build their own serverless platforms on Cloudflare infrastructure. A typical request flow involves three or four different Workers.
First, a dynamic dispatch Worker receives the request and selects which user Worker should handle it.
The user Worker processes the request, potentially invoking an outbound Worker to intercept network calls.
Finally, a tail Worker might collect logs and traces from the entire request flow.
These Workers can run on different servers across the data center. Supporting sharding for nested Worker invocations requires passing the execution context between servers.
The execution context includes information like permission overrides, resource limits, feature flags, and logging configurations. When Workers ran on a single server, managing this context was straightforward. With sharding, the context must travel between servers as Workers invoke each other.
Cloudflare serializes the context stack into a Cap’n Proto message and includes it in sharded requests. The shard server deserializes the context and continues execution with the correct configuration.
The tail Worker scenario demonstrates Cap’n Proto’s power. A tail Worker must receive traces from potentially many servers that participated in handling a request. Rather than having each server know where to send traces, the system includes a callback capability in the execution context. Each server simply invokes this callback with its trace data. The RPC system automatically routes these calls back to the dynamic dispatch Worker’s home server, where all traces are collected together.
Conclusion
After deploying worker sharding globally, Cloudflare measured several key metrics:
Only 4% of total enterprise requests are sharded to a different server. This low percentage reflects that 96% of requests go to high-traffic Workers that run multiple instances across many servers.
Despite sharding only 4% of requests, the global Worker eviction rate decreased by 10 times. Eviction rate measures how often Workers are shut down to free memory. Fewer evictions indicate that memory is being used more efficiently across the system.
The 4% sharding rate achieving 10 times efficiency improvement stems from the power law distribution of internet traffic. A small number of Workers receive the vast majority of requests.
These high-traffic Workers already maintained warm instances before sharding. A large number of Workers receive relatively few requests. These low-traffic Workers suffered from frequent cold starts and are exactly the ones helped by sharding.
The warm request rate for enterprise traffic increased from 99.9% to 99.99%. This improvement represents going from three nines to four nines of reliability. Equivalently, the cold start rate decreased from 0.1% to 0.01% of all requests. This is a 10 times reduction in how often users experience cold start delays.
The warm request rate also became less volatile throughout each day. Previous patterns showed significant variation as traffic levels changed. Sharding smoothed these variations by ensuring low-traffic Workers maintained warm instances even during off-peak hours.
Cloudflare’s worker sharding system demonstrates how distributed systems techniques can solve performance problems that direct optimization cannot address. Rather than making cold starts faster, they made cold starts less frequent. Rather than using more computing resources, they used existing resources more efficiently.
References:
We’re dealing with GPU workloads, so the problem is quite different from CPU workers. Instead of relying on warm instances, we snapshot the full CPU and GPU execution state, so restore behaves like a resume rather than re-initialization.
https://github.com/inferx-net/inferx
Very Interesting take. I have written this article about Cloudlfare and would be happy if you can check it out :)
https://marketsminds.substack.com/p/deep-dive-cloudflare-the-internets?utm_campaign=post-expanded-share&utm_medium=post%20viewer