
How Datadog Redefined Data Replication

Your cache isn’t the problem. How you’re using it is. (Sponsored)

If your cache only speeds up a few endpoints, your cache strategy is too narrow.
That model doesn’t scale. It creates stale data, extra complexity, and more load on your database than you think.
Modern systems treat cache differently. It’s seen as a real-time data layer that’s structured, queryable, and always in sync with source data.
This guide walks through how teams make that shift—from basic key-value storage to a cache that can actually carry production workloads.
Inside, you’ll learn:
How to cut database pressure without adding more infrastructure
How to serve more queries at sub-millisecond latency
How to keep data fresh without stitching together brittle pipelines
If you’re running into performance or cost limits, this guide is for you.
Datadog’s Metrics Summary page had a problem. For one customer, every time someone loaded the page, the database had to join a table of 82,000 active metrics with 817,000 metric configurations. The p90 latency hit 7 seconds. Every time a user clicked a filter, it triggered another expensive join.
The team tried the usual fixes, such as query optimization, indexing, and tuning. However, the problem wasn’t the query. They were asking a database designed for transactions to do the job of a search engine. Fixing that one page set off a chain of architectural decisions that didn’t just solve the performance issue. It led Datadog to fundamentally redefine how data replication works across its entire infrastructure.
In this article, we will look at how Datadog implemented the changes and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the Datadog Engineering Team. Please comment if you notice any inaccuracies.
The Database Was Simply Doing the Wrong Job
Datadog operates thousands of services, many of them backed by a shared Postgres database. For a long time, that shared database was the right call. Postgres is reliable, well-understood, and cost-effective at small to medium scale. However, as data volumes grew, the cracks started to show, and the Metrics Summary page was just the most visible symptom.
The team’s first instinct was to optimize the database. They tried adjusting join order, adding multi-column indexes, and using query heuristics based on table size. None of it held up and there were several issues:
Disk and index bloat slowed inserts and updates.
VACUUM and ANALYZE operations added maintenance overhead.
Memory pressure drove up I/O wait times.
Monitoring with Datadog’s own APM confirmed that these queries were consuming a disproportionate share of system resources, and getting worse as the data grew. By the time multiple organizations crossed the 50,000-metrics-per-org threshold, the warning signs were everywhere, such as slow page loads, unreliable filters, and mounting operational overhead.
See the diagram below:
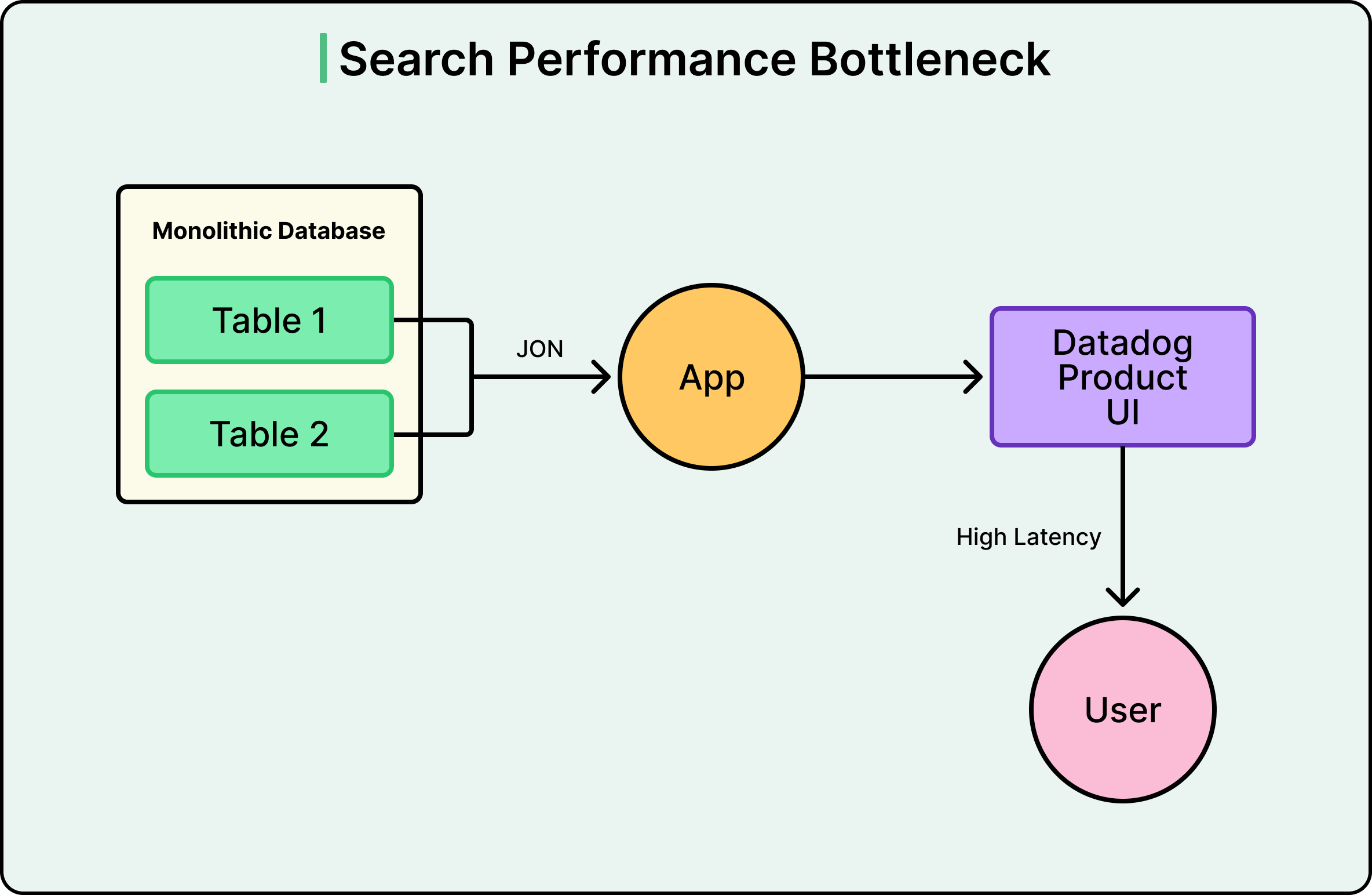
Postgres was being asked to do two fundamentally different jobs at once. OLTP workloads are what relational databases are designed for. However, real-time search with filtering across massive denormalized datasets is a completely different workload, one that search engines like Elasticsearch are purpose-built to handle.
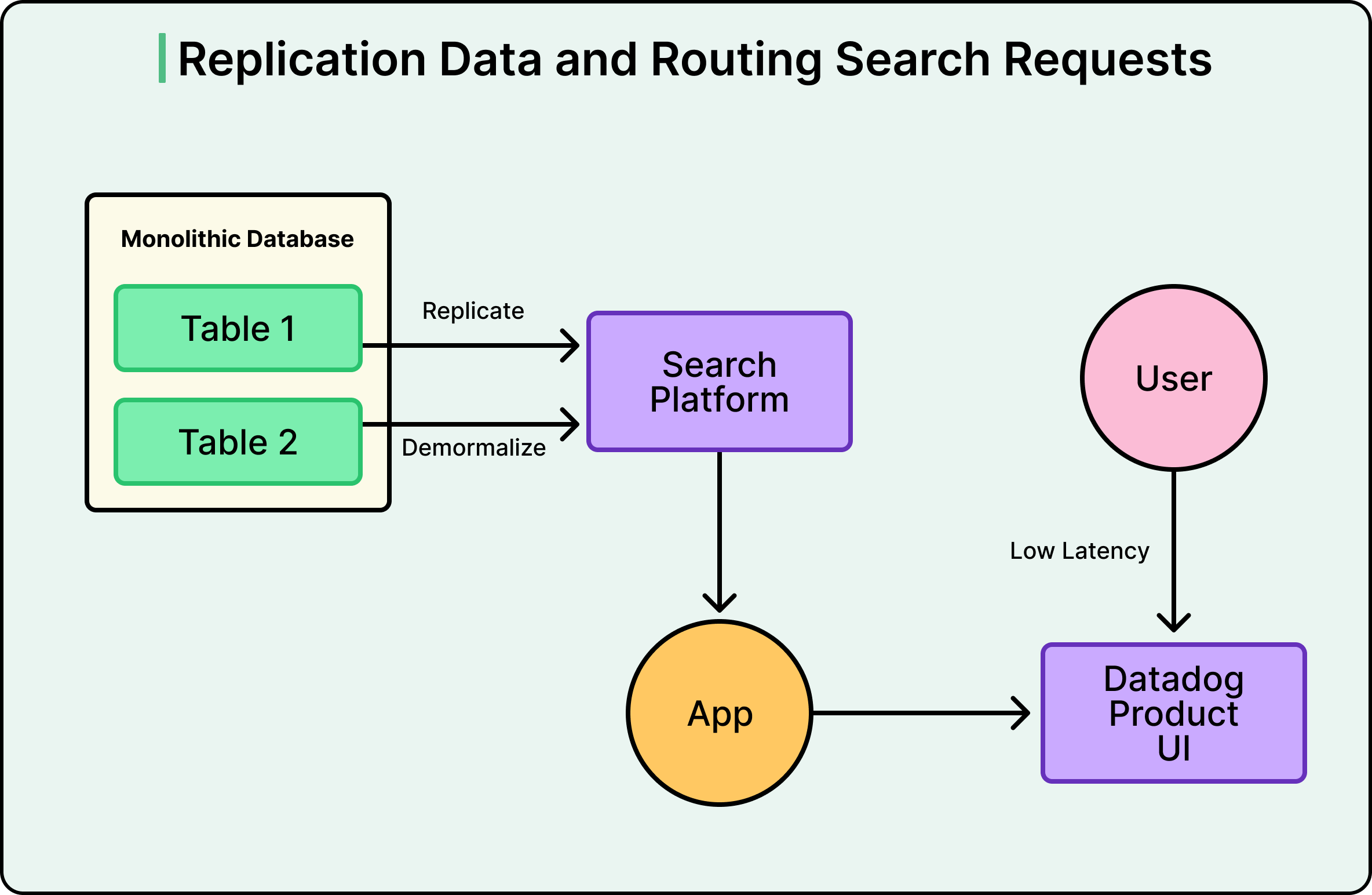
Therefore, instead of making Postgres better at searching, Datadog stopped making it search at all. They replicated data from Postgres into a dedicated search platform, flattening the relational structure into denormalized documents along the way. The mechanism behind this is Change Data Capture, or CDC.
Postgres already records every change (every insert, update, and delete) in its Write-Ahead Log, or WAL. This log exists primarily for crash recovery, but it can also be read by external tools. Datadog used Debezium, an open-source CDC tool, to read that log and stream changes into Kafka, a durable message broker. From Kafka, sink connectors pushed the data into the search platform.
The advantage of this approach is that the application itself didn’t need to change how it wrote data. It still writes to Postgres as before. However, search queries now hit the search platform instead, which was purpose-built for exactly that workload.
See the diagram below:
Why Async?
Before scaling that pattern, the team faced a key design choice: synchronous or asynchronous replication.
In synchronous replication, the primary database doesn’t confirm a write to the application until every replica has acknowledged receiving it. This guarantees strong consistency, meaning every system has the same data at all times. But it’s slow. If one replica is across the network or temporarily unhealthy, the entire write pipeline stalls waiting for confirmation. One slow consumer becomes a bottleneck for everything.
Asynchronous replication flips this. The primary database confirms the write immediately, and replicas catch up afterward. The application never waits for downstream systems. This is faster and more resilient, but it introduces a window where the replica is behind the source. This gap is what’s known as replication lag. The data will get there, but not instantly.
See the diagram below:
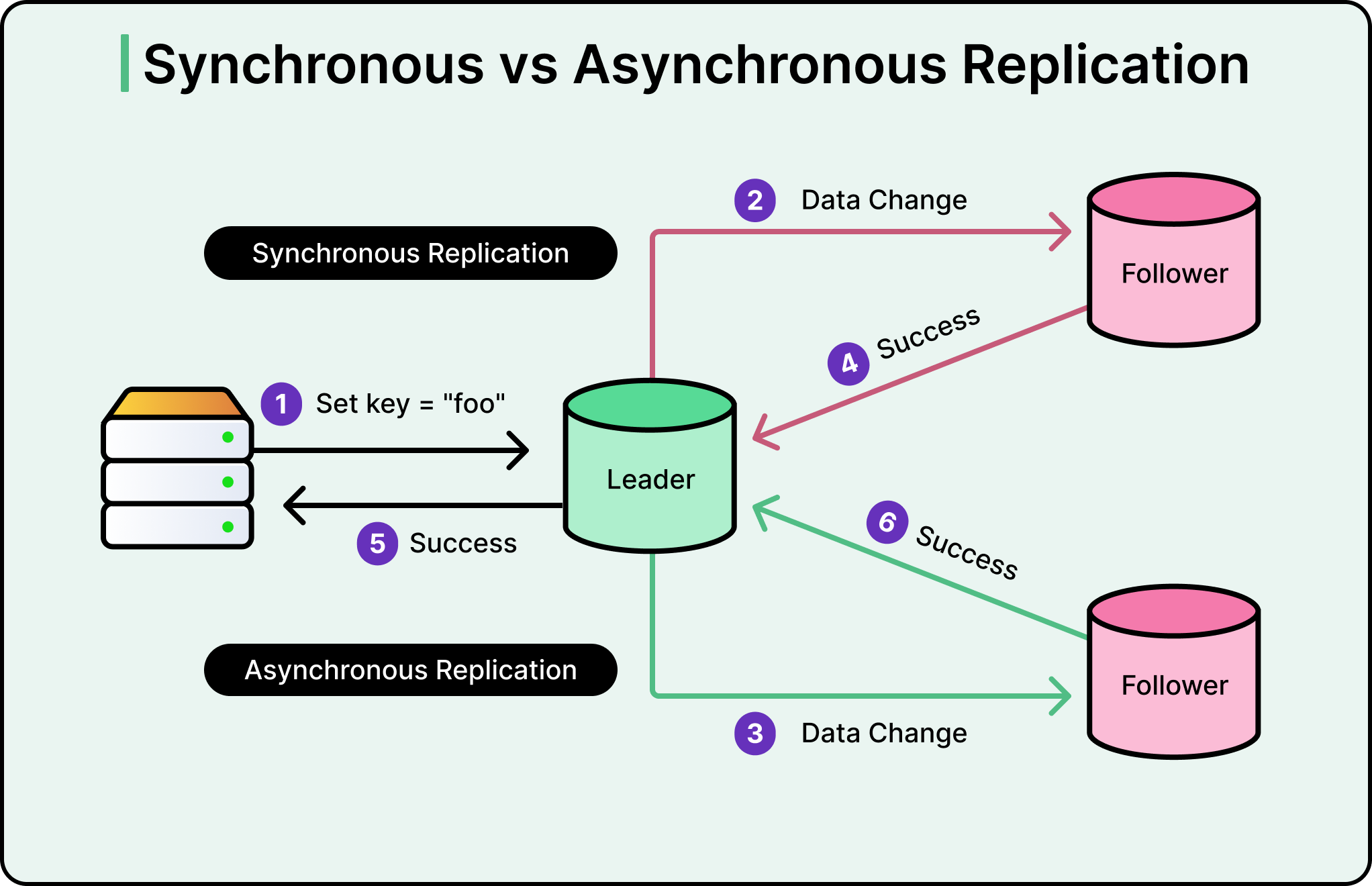
Datadog chose async. At their scale, with thousands of services spread across multiple data centers, synchronous replication would have coupled their application’s performance to the network latency and health of every downstream consumer. That was a non-starter.
One factor that helped in the decision-making was the cost being concrete. For a brief window after a write, the search platform might show slightly stale results. If a user adds a new metric configuration and immediately searches for it, the search platform might not have the update yet. For Datadog’s use cases (search, filtering, analytics dashboards), a few hundred milliseconds of lag was a perfectly acceptable tradeoff compared to 7-second page loads.
Debezium captures changes from the WAL, and Kafka acts as a durable buffer between the source and all consumers. Since Kafka persists messages to disk and supports replay, changes aren’t lost even if a consumer goes down temporarily. The consumer just picks up where it left off.
This tradeoff between consistency and availability shows up everywhere in distributed systems. It’s a practical instance of the CAP theorem, which describes the fundamental tension between consistency, availability, and partition tolerance.
Async replication solved the performance problem. However, it introduced a new challenge. What happens when the shape of your data changes?
The Problem With Schema Evolution
In a normal application, changing a database schema is between you and your database. You run a migration, add a column, change a type, and move on. With CDC, every schema change propagates to every downstream consumer, and if those consumers aren’t ready for the change, the pipeline breaks.
Let us consider a concrete example. A team adds a required region field to a table using ALTER TABLE ... ALTER COLUMN ... SET NOT NULL. Debezium starts producing messages that include this field. But messages already sitting in Kafka were written under the old schema and don’t have it. Consumers expecting every message to have a non-null region field start failing, and the pipeline goes down.
Datadog built a two-part defense against this.
The first line of defense is an automated validation system that analyzes schema migration SQL before it’s applied to the database. It catches risky changes, like adding NOT NULL constraints, and blocks them from being deployed without coordination. Most migrations pass through automatically. The ones that don’t get flagged require the team to work directly with the platform team to coordinate a safe rollout.
The second line of defense is a multi-tenant Kafka Schema Registry configured for backward compatibility. This means any new schema must still be readable by consumers that only understand the old schema. In practice, this restricts schema changes to safe operations, such as adding optional fields or removing existing ones. When Debezium captures an updated schema, it serializes the data in Avro format and pushes both the data and the schema update to the Registry.
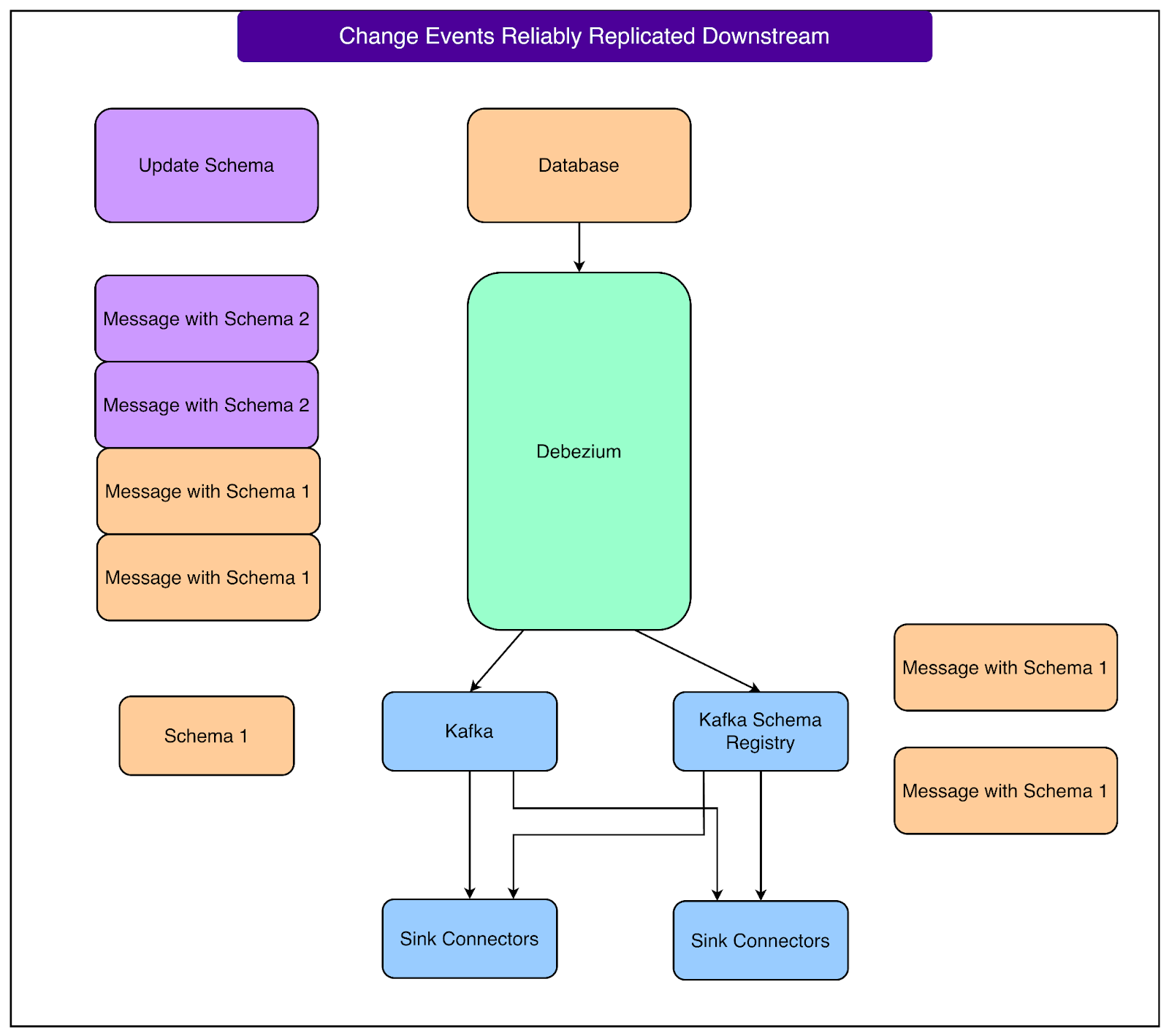
The Registry checks the new schema against the existing one and either accepts or rejects it based on the backward compatibility rules. Datadog uses Avro serialization specifically because it supports this kind of schema negotiation natively. The Confluent Schema Registry documentation covers the mechanics of backward, forward, and full compatibility modes.
Together, these two systems mean that most schema changes flow through automatically, breaking changes get caught early, and downstream consumers don’t wake up to broken pipelines.
With async replication running and schema evolution under control, Datadog had a working pipeline. However, setting up each new pipeline still required an engineer to manually configure seven or more components across multiple systems. That’s where automation changed the game.
From One Pipeline to a Platform
A single CDC pipeline involves a number of moving parts. For example, you need to enable logical replication on Postgres by setting wal_level to logical. Also, you need to create Postgres users with the right permissions, establish replication slots and publications, deploy Debezium instances, create Kafka topics with correct mappings, set up heartbeat tables for monitoring, and configure sink connectors to push data into the destination.
Doing all of that manually for one pipeline is tedious. But doing it across many pipelines and multiple data centers means the operational burden compounds quickly.
See the diagram below:
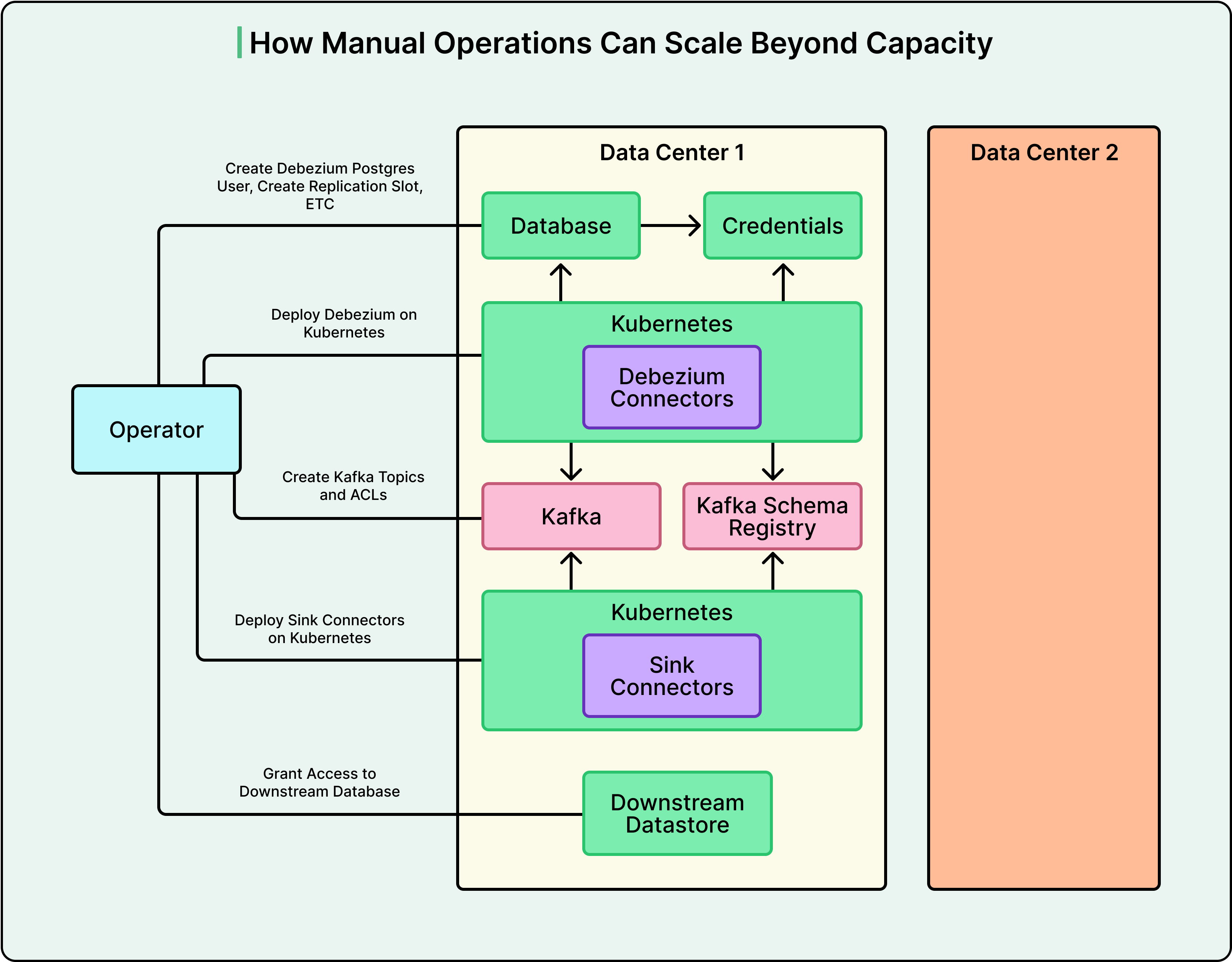
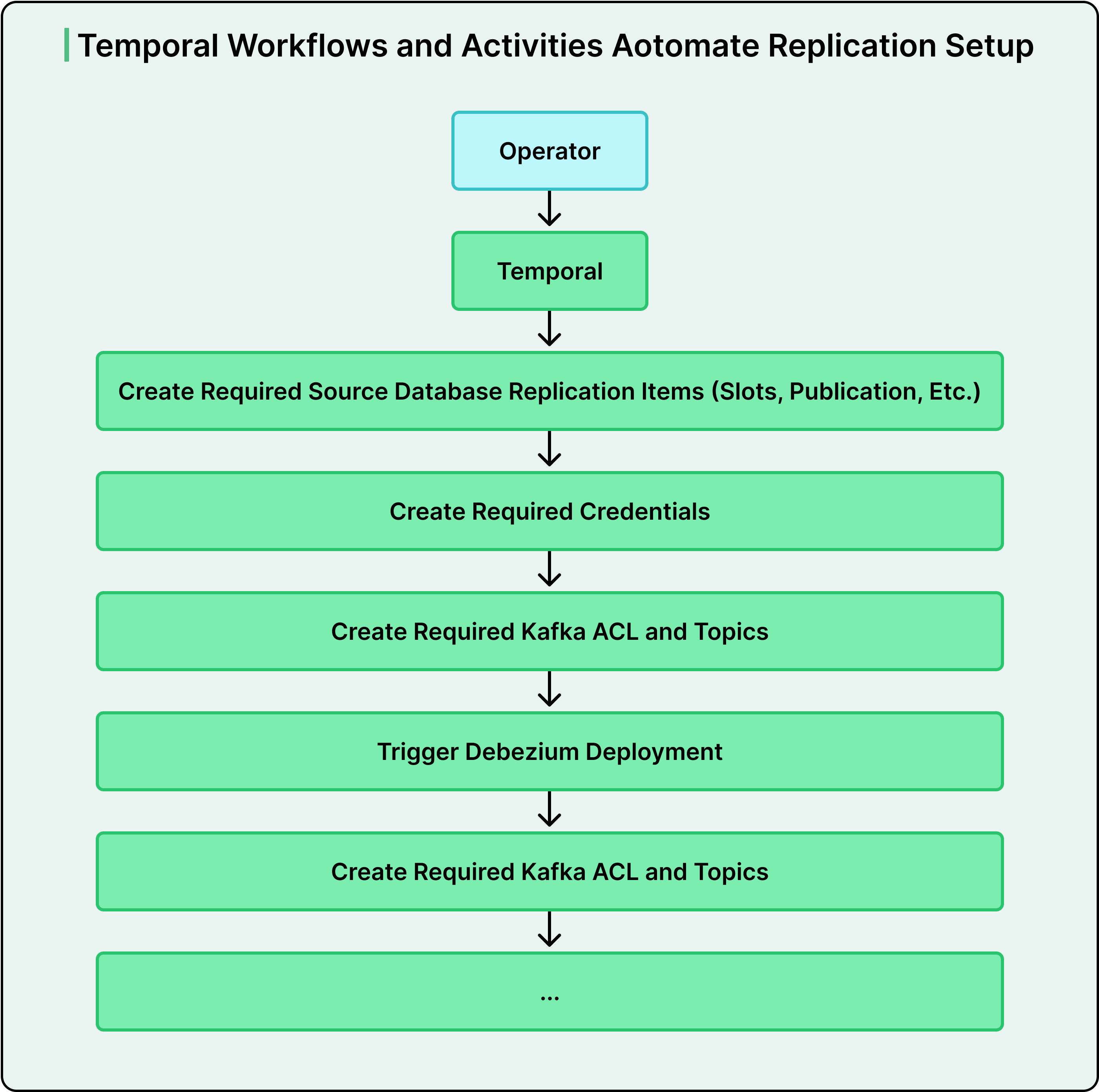
Datadog made automation a foundational principle. Using Temporal, a workflow orchestration engine, they broke the provisioning process into modular, reliable tasks and stitched them into higher-level workflows. If a step fails, the workflow retries or rolls back cleanly. Teams don’t touch infrastructure directly. They request a pipeline through the platform, and the automation handles everything end-to-end.
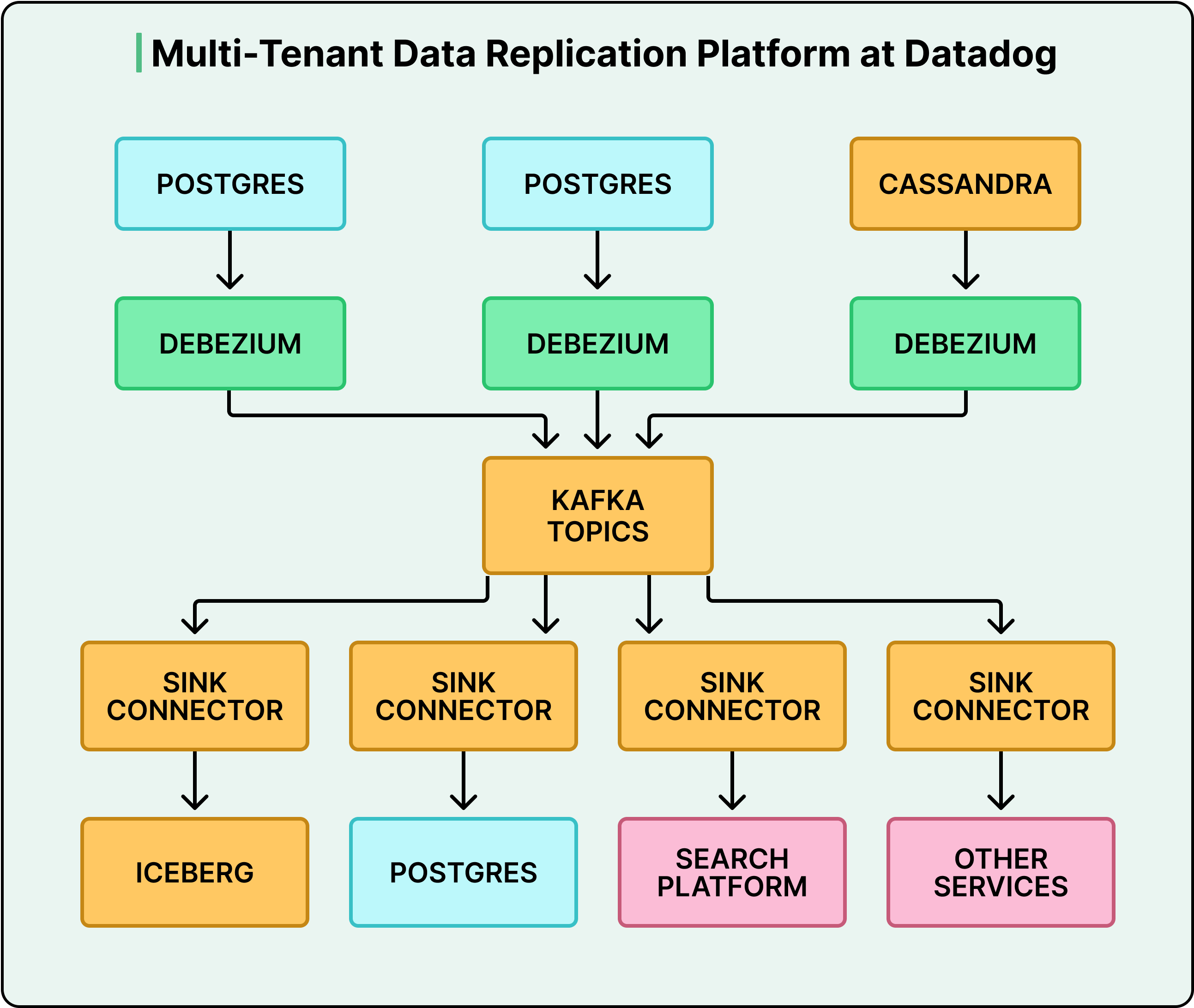
This is what turned a single fix into a company-wide capability. What started as “replicate this one Postgres table to a search engine” expanded to Postgres-to-Postgres replication for unwinding their large shared monolithic database, Postgres-to-Iceberg pipelines for event-driven analytics, Cassandra replication to support non-SQL data sources, and cross-region Kafka replication to improve data locality for products like Datadog On-Call.
See the diagram below:
Conclusion
Every architectural choice Datadog made came with a cost:
Asynchronous replication means downstream systems are always slightly behind the source.
Schema evolution constraints mean you can’t freely change your database without considering the pipeline.
The infrastructure itself (Debezium, Kafka, Schema Registry, Temporal) represents a lot of moving parts to operate, monitor, and maintain.
Lastly, building all of this into a platform requires a dedicated team to own it.
This approach makes sense when you have workloads that genuinely don’t belong in your primary database, when multiple teams need the same data in different shapes, and when your scale makes manual pipeline management untenable. Datadog checked all three boxes. However, if you have a handful of simple data flows, the overhead isn’t justified. A periodic batch sync or a straightforward read replica might be all you need. Not every problem requires a platform.
References:
What stands out here is the decision to stop forcing a system to do something it was never designed to handle.
That mistake shows up everywhere, especially in markets. People keep asking one framework to explain everything—valuation, momentum, macro—and when it starts breaking, the instinct is to optimize it further instead of stepping back and changing the structure entirely.
The shift usually comes when the cost of patching becomes higher than the cost of rethinking. That’s when you see real change—not incremental improvements, but a full reallocation of how things are processed.
And once that happens, the old system doesn’t gradually fade. It just stops being the place where the important decisions are made.