
How Discord Stores Trillions of Messages with High Performance

MCP Authorization in 5 Easy OAuth Specs (Sponsored)

Securely authorizing access to an MCP server used to be an open question. Now there's a clear answer: OAuth. It provides a path with five key specs covering delegation, token exchange, and scoped access.
WorkOS packages the full stack into one API, so you can add MCP authorization without building your own OAuth infrastructure.
Disclaimer: The details in this post have been derived from the articles shared online by the Discord Engineering Team. All credit for the technical details goes to the Discord Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Many chat platforms never reach the scale where they have to deal with trillions of messages. However, Discord does. And when that happens, a somewhat manageable data problem can quickly turn into a major engineering challenge that involves millions of users sending messages across millions of channels.
At this scale, even the smallest architectural choices can have a big impact. Things like hot partitions can turn into support nightmares. Garbage collection pauses aren’t just annoying, but can lead to system-wide latency spikes. The wrong database design can lead to wastage of developer time and operational bandwidth.
Discord’s early database solution (moving from MongoDB to Apache Cassandra®) promised horizontal scalability and fault tolerance. It delivered both, but at a significant operational cost. Over time, keeping Apache Cassandra® stable required constant firefighting, careful compaction strategies, and JVM tuning. Eventually, the database meant to scale with Discord had become a bottleneck.
In this article, we will walk through how Discord rebuilt its message storage layer from the ground up. We will learn the issues Discord faced with Apache Cassandra® and their shift to ScyllaDB. Also, we will look at the introduction of Rust-based data services to shield the database from overload and improve concurrency handling.
Go from Engineering to AI Product Leadership (Sponsored)

As an engineer or tech lead, you know how to build complex systems. But how do you translate that technical expertise into shipping world-class AI products? The skills that define great AI product leaders—from ideation and data strategy to managing LLM-powered roadmaps—are a different discipline.
This certification is designed for technical professionals. Learn directly from Miqdad Jaffer, Product Leader at OpenAI, in the #1 rated AI certificate on Maven. You won't just learn theory; you will get hands-on experience developing a capstone project and mastering the frameworks used to build and scale products in the real world.
Exclusive for ByteByteGo Readers: Use code BBG500 to save $500 before the next cohort sells out.
Initial Architecture
Discord's early message storage relied on Apache Cassandra®. The schema grouped messages by channel_id and a bucket, which represented a static time window.
This schema allowed for efficient lookups of recent messages in a channel, and Snowflake IDs provided natural chronological ordering. A replication factor of 3 ensured each partition existed on three separate nodes for fault tolerance.

Within each partition, messages were sorted in descending order by message_id, a Snowflake-based 64-bit integer that encoded creation time.
The diagram below shows the overall partitioning strategy based on the channel ID and bucket.

At a small scale, this design worked well. However, scale often introduces problems that don't show up in normal situations.
Apache Cassandra® favors write-heavy workloads, which aligns well with chat systems. However, high-traffic channels with massive user bases can generate orders of magnitude more messages than quiet ones.
A few things started to go wrong at this point:
Hot partitions emerged when a popular channel received a surge of reads or writes. Since Apache Cassandra® was configured to partition data by channel_id and bucket, one node can potentially get overloaded trying to serve queries for that partition. These hot spots increased latency not just locally but across the cluster.
Reads had to check in-memory memtables and potentially scan across multiple on-disk SSTables. As data grew and compaction lagged, reads became slower and more expensive.
The diagram below shows the concept of hot partitions:
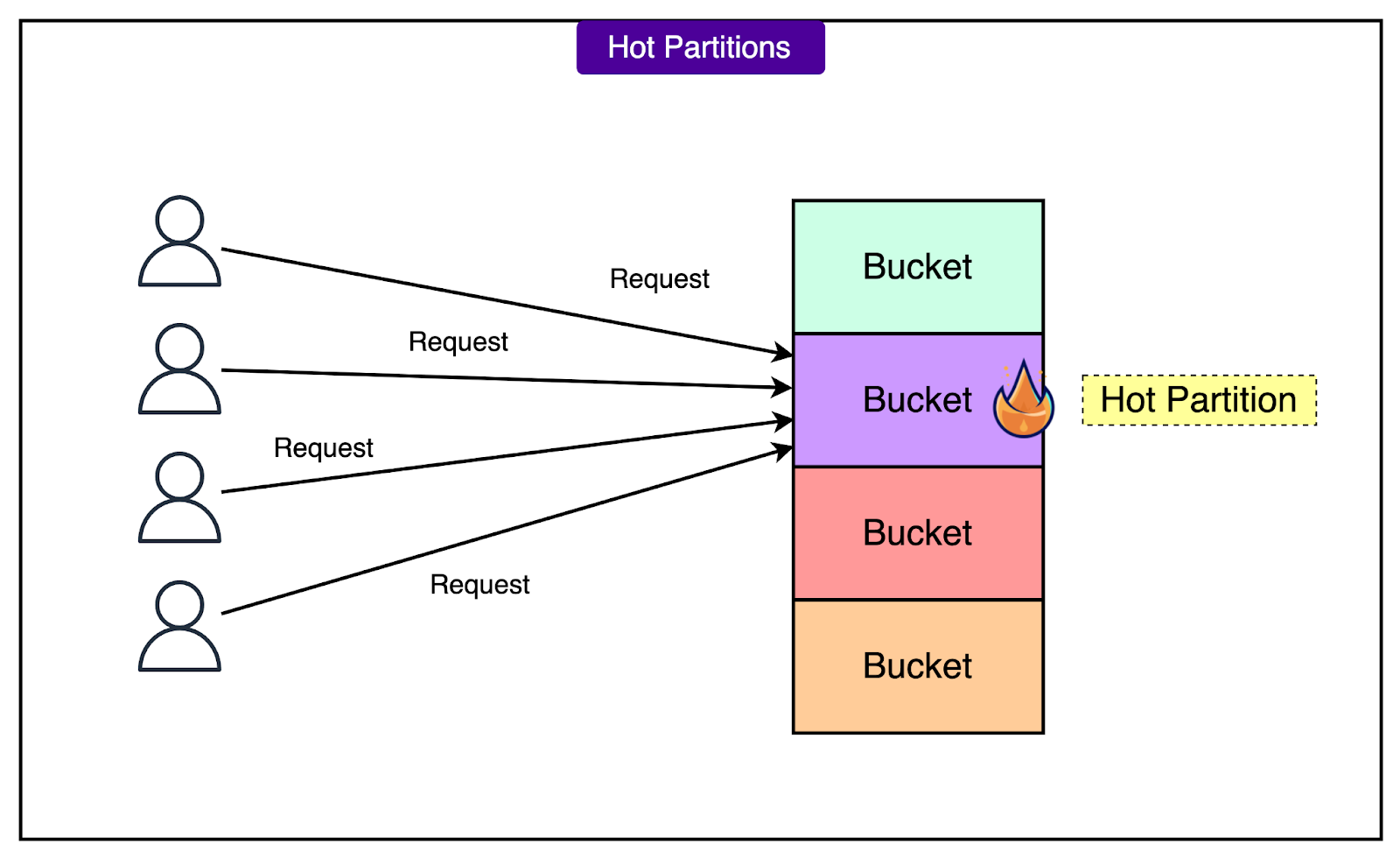
Performance wasn't the only issue. Operational overhead also ballooned.
Compactions, which merge and rewrite SSTables, fell behind, increasing disk usage and degrading read performance. The team often had to take nodes out of rotation and babysit them back to health.
JVM garbage collection became a recurring source of instability. GC pauses could stretch long enough to cause timeouts or trigger failovers. Tuning heap sizes and GC parameters became a full-time task for on-call engineers.
As the message load grew, so did the cluster. What began with 12 nodes eventually reached 177 nodes, each one a moving part that required care and coordination.

At this point, Apache Cassandra® was being scaled manually, by throwing more hardware and more engineer hours at the problem. The system was running, but it was clearly under strain.
Switching to ScyllaDB
ScyllaDB entered the picture as a natural alternative. It preserved compatibility with the query language and data model of Apache Cassandra®, which meant the surrounding application logic could remain largely unchanged. However, under the hood, the execution model was very different.
Some key characteristics were as follows:
ScyllaDB is written in C++, which eliminates the need for a garbage collector. That immediately removed one of the most painful sources of latency in the Apache Cassandra® setup.
It uses a shard-per-core architecture, assigning each CPU core its subset of data and handling requests independently. This design improved isolation between workloads and avoided many of the coordination bottlenecks seen in multi-threaded JVM-based systems.
Repair operations and consistency handling were performed more efficiently, thanks to lower overhead in ScyllaDB’s internals.
One key blocker during evaluation was reverse query performance. Discord’s message history scanning sometimes requires scanning in ascending order, the opposite of the default descending sort. Initially, ScyllaDB struggled with this use case. However, the ScyllaDB engineering team prioritized improvements, making the operation fast enough for production needs.
Overall, ScyllaDB offered the same interface with a far more predictable runtime.
Rust-Based Data Services Layer
To reduce direct load on the database and prevent repeated query amplification, Discord also introduced a dedicated data services layer. These services act as intermediaries between the main API monolith and the ScyllaDB clusters. They are responsible solely for data access and coordination, and no business logic is embedded here.
The goal behind them was simple: isolate high-throughput operations, control concurrency, and protect the database from accidental overload.
Rust was chosen for the data services for both technical and operational reasons. This is because it brings together low-level performance and modern safety guarantees.
Some key advantages of choosing Rust are as follows:
Native performance comparable to C and C++, which is critical in latency-sensitive paths.
Safe concurrency through Rust’s ownership and type system. This avoids the class of bugs common in multithreaded C++ or Java systems.
Asynchronous I/O is powered by the Tokio ecosystem, which allows efficient handling of thousands of simultaneous requests without blocking threads.
Native drivers for both Apache Cassandra® and ScyllaDB, enabling direct, efficient access to the underlying data.
Each data service exposes gRPC endpoints that map one-to-one with database queries. This keeps the architecture clean and transparent. The services do not embed any business logic. They are designed purely for data access and efficiency.
Request Coalescing
One of the most important features in this layer is request coalescing.
When multiple users request the same piece of data, such as a popular message in a high-traffic channel, the system avoids hammering the database with duplicate queries.
The first incoming request triggers a worker task that performs the database query.
Any subsequent requests for the same data check for an active worker and subscribe to its result instead of issuing a new query.
Once the database responds, the result is broadcast to all subscribers, completing all requests with a single round trip to the database.
See the diagram below:

To support this pattern at scale, the system uses consistent hash-based routing. Requests are routed using a key, typically the channel_id. This allows all traffic for the same channel to be handled by the same instance of the data service.
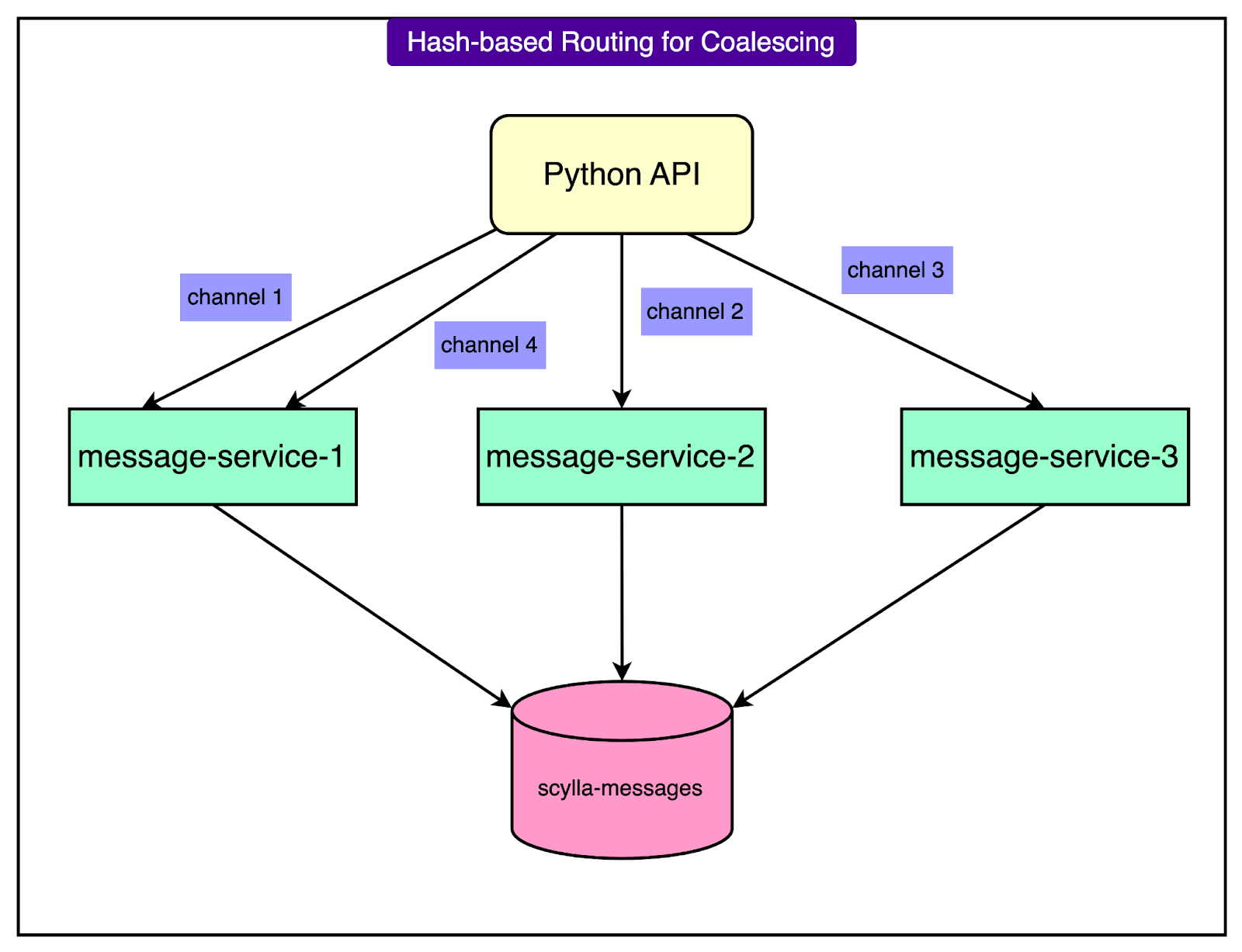
Ultimately, the Rust-based data services help offload concurrency and coordination away from the database. They flatten spikes in traffic, reduce duplicated load, and provide a stable interface to ScyllaDB.
The result for Discord was higher throughput, better latency under load, and fewer emergencies during traffic surges.
Migration Strategy
Migrating a database that stores trillions of messages is not a trivial problem. The primary goals of this migration were clear:
There should be no downtime. The messaging system had to remain fully available throughout the process.
The migration should have high throughput. The process had to be completed quickly. The longer two systems remain active, the higher the complexity and risk.
The entire migration process was divided into phases:
Phase 1: Dual Writes with a Cutover Point
The team began by setting up dual writes. Every new message was written to both Apache Cassandra® and ScyllaDB. A clear cutover timestamp defined which data belonged to the "new" world and which still needed to be migrated from the "old."
This allowed the system to adopt ScyllaDB for recent data while leaving historical messages intact in Apache Cassandra® until the backfill completed.
Phase 2: Historical Backfill Using Spark
The initial plan for historical migration relied on ScyllaDB’s Spark-based migrator.
This approach was stable but slow. Even after tuning, the projected timeline was three months to complete the full backfill. That timeline wasn't acceptable, given the ongoing operational risks with Apache Cassandra®.
Phase 3: A Rust-Powered Rewrite
Instead of accepting the delay, the team extended their Rust data service framework to handle bulk migration. This new custom migrator:
Read token ranges from Apache Cassandra®, identifying contiguous data blocks.
Stored progress in SQLite, allowing for checkpoints and resumability.
Wrote directly into ScyllaDB using high-throughput, concurrent write operations.
The result was a dramatic improvement. The custom migrator achieved a throughput of 3.2 million messages per second, reducing the total migration time from months to just 9 days. This change also simplified the plan. With fast migration in place, the team could migrate everything at once instead of splitting logic between "old" and "new" systems.
Final Step: Validation and Cutover
To ensure data integrity, a portion of live read traffic was mirrored to both databases, and the responses were compared. Once the system consistently returned matching results, the final cutover was scheduled.
In May 2022, the switch was flipped. ScyllaDB became the primary data store for Discord messages.
Post-Migration Results
After the migration, the system footprint shrank significantly. The Apache Cassandra® cluster had grown to 177 nodes to keep up with storage and performance demands. ScyllaDB required only 72 nodes to handle the same workload.
This wasn’t just about node count. Each ScyllaDB node ran with 9 TB of disk space, compared to an average of 4 TB on Apache Cassandra® nodes. The combination of higher density and better performance per node translated into lower hardware and maintenance overhead.
Latency Improvements
The performance gains were clear and measurable.
The historical message reads, previously unpredictable became consistent. The earlier p99 latency ranged between 40 and 125 milliseconds, depending on compaction status and read amplification. ScyllaDB brought that down to a steady 15 milliseconds at p99.
Message inserts latency flattened out. Apache Cassandra® showed p99 insert latencies between 5 and 70 milliseconds, while ScyllaDB held stable at 5 milliseconds.
Operational Stability
One of the biggest wins was operational calm.
There was no more need for GC tuning. With ScyllaDB written in C++, the team no longer had to spend hours tweaking JVM settings to avoid unpredictable pauses.
Weekend firefights became less frequent. Compaction backlogs and hot partitions during the earlier design regularly triggered alerts and manual interventions. ScyllaDB with the data services handled the same load without the need for such interventions.
The system gained enough headroom to support new product features and larger bursts of traffic. The database no longer held back application growth.
Conclusion
The real test of any system comes when traffic patterns shift from expected to chaotic. During the 2022 FIFA World Cup Final, Discord’s message infrastructure experienced exactly that kind of stress test and passed cleanly.
As Argentina and France battled through regular time, extra time, and penalties, user activity surged across the platform. Each key moment (goals by Messi, Mbappé, the equalizers, the shootout) created massive spikes in message traffic, visible in monitoring dashboards almost in real time.

Message sends surged, and read traffic ballooned. The kind of workload that used to trigger hot partitions and paging alerts during the earlier design now ran smoothly. Some key takeaways were as follows:
Rust-based data services absorbed the concurrent request load through coalescing and consistent routing.
ScyllaDB sustained peak throughput with stable latencies.
Engineers didn’t need to intervene. The platform stayed quiet and responsive throughout one of the most globally watched sporting events in history.
Note: Apache Cassandra® is a registered trademark of the Apache Software Foundation.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
This is such a well written article about practical considerations for large scale distributed systems. Valuable insight, thanks for sharing.
I'd be curious to hear Discord's comments on Scylla's new licensing structure. Also, it's been a long time since I've heard of anyone having GC issues with Apache Cassandra. G1GC helped a lot with that, and the collectors available in the more recent JDKs (ZGC, Shenandoah) make it even more of a non-issue.