
How DoorDash uses AI Models to Understand Restaurant Menus

Make tribal knowledge self-serve (Sponsored)

Cut onboarding time, reduce interruptions, and ship faster by surfacing the knowledge locked across GitHub, Slack, Jira, and Confluence (and more). You get:
Instant answers to questions about your architecture, past workarounds, and current projects.
An MCP Server that supercharges Claude and Cursor with your team knowledge so they generate code that makes sense in your codebase.
Agent that posts root cause and fix suggestions for CI failures directly in your Pull Request.
A virtual member of your team that automates internal support without extra overhead.
Disclaimer: The details in this post have been derived from the official documentation shared online by the DoorDash Engineering Team. All credit for the technical details goes to the DoorDash Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When we order food online, the last thing we want is an out-of-date or inaccurate menu.
However, for delivery platforms, keeping menus fresh is a never-ending challenge. Restaurants constantly update items, prices, and specials, and doing all of this manually at scale is costly and slow.
DoorDash tackled this problem by applying large language models (LLMs) to automate the process of turning restaurant menu photos into structured, usable data. The technical goal of their project was clear: achieve accurate transcription of menu photos into structured menu data while keeping latency and cost low enough for production at scale.
On the surface, the idea is straightforward: take a photo, run it through AI, and get back a clean digital menu. In practice, though, the messy reality of real-world images (cropped photos, poor lighting, cluttered layouts) quickly exposes the limitations of LLMs on their own.
But the key insight was that LLMs, while strong at summarization and organization, break down when faced with noisy or incomplete inputs. To overcome this, DoorDash designed a system with guardrails. These are mechanisms that decide when automation is reliable enough to use and when a human needs to step in.
In this article, we will look at how DoorDash designed such a system and the challenges they faced.
Baseline MVP
The first step was to prove whether menus could be digitized at all in an automated way.
The engineering team started with a simple pipeline: OCR to LLM. The OCR system extracted raw text from menu photos, and then a large language model was tasked with converting that text into a structured schema of categories, items, and attributes.
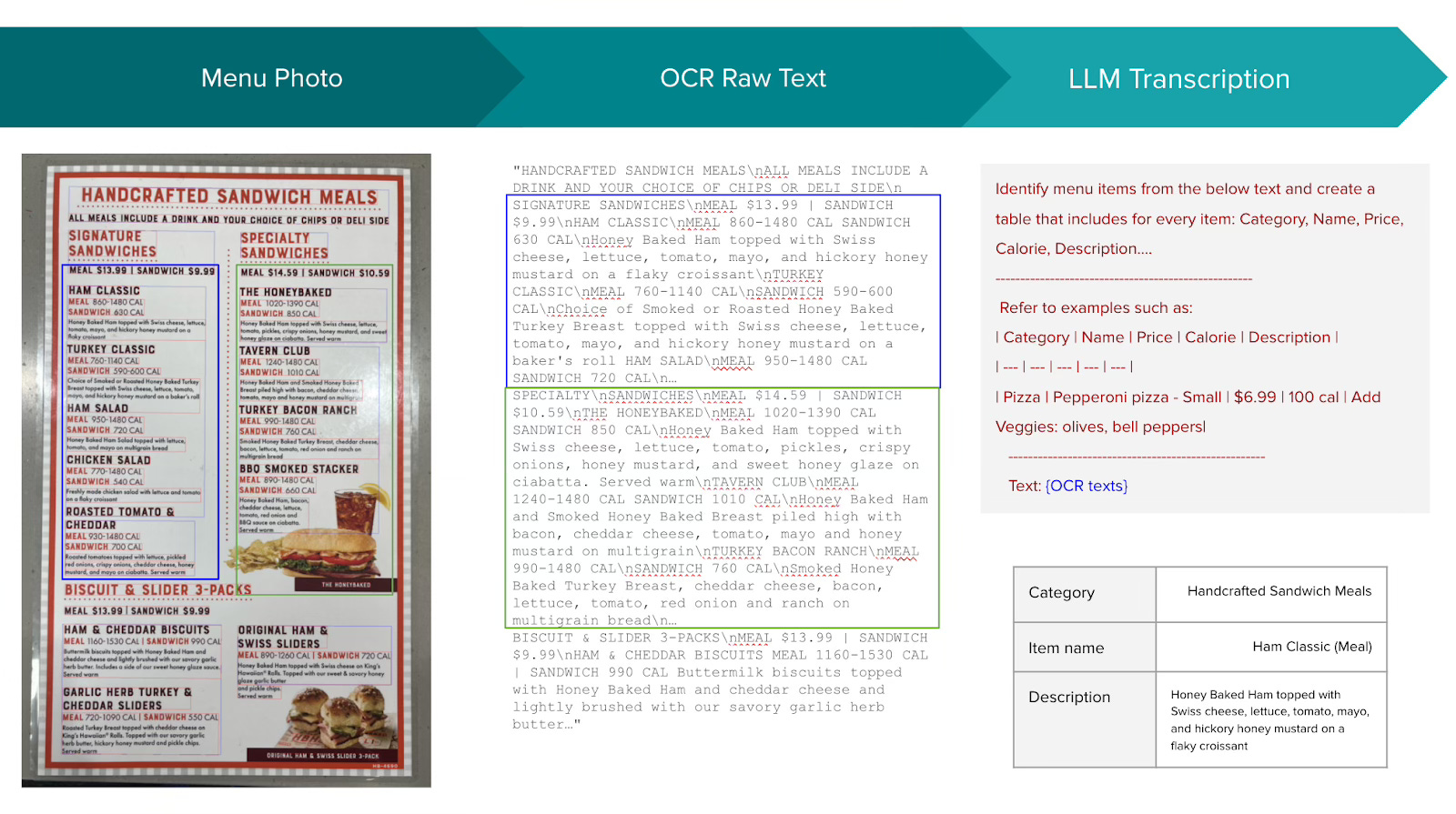
This approach worked well enough as a prototype.
It showed that a machine could, in principle, take a photo of a menu and output something resembling a digital menu. But once the system was tested at scale, cracks began to appear. Accuracy suffered in ways that were too consistent to ignore.
The main reasons were as follows:
Inconsistent menu structures: Real-world menus are not neatly ordered lists. Some are multi-column, others use mixed fonts, and many scatter categories and items in unpredictable ways. OCR tools often scramble the reading order, which means the LLM ends up pairing items with the wrong attributes or misplacing categories entirely.
Incomplete menus: Photos are often cropped or partial, capturing only sections of a menu. When the LLM receives attributes without their parent items, or items without their descriptions, it makes guesses. These guesses lead to mismatches and incorrect entries in the structured output.
Low photographic quality: Many menu photos are taken in dim lighting, with glare from glass frames or clutter in the background. Small fonts and angled shots add to the noise. Poor image quality reduces OCR accuracy, and the errors cascade into the LLM stage, degrading the final transcription.
Through human evaluation, the team found that nearly all transcription failures could be traced back to one of these three buckets.
The Gold standard for AI news (Sponsored)

AI is the most essential technical skill of this decade.
CEOs of GitHub, Box, and others are prioritising hiring engineers with AI skills.
Engineers, devs, and technical leaders at Fortune 1000s + leading Silicon Valley startups read Superhuman AI to stay ahead of the curve and future-proof their skills.
LLM Guardrail Model
To solve the accuracy problem, the engineering team introduced what they call a guardrail model.
At its core, this is a classifier that predicts whether the transcription produced from a given menu photo will meet the accuracy bar required for production. The logic is straightforward:
If the guardrail predicts that the output is good enough, the structured menu data is automatically published.
If the guardrail predicts a likely failure, the photo is routed to a human for transcription.
Building the guardrail meant more than just looking at the image.
The team realized the model needed to understand how the photo, the OCR system, and the LLM all interacted with each other. So they engineered features from three different sources:
Image-level features: These capture the quality of the photo itself, whether it is dark, blurry, has glare, or is cluttered with background objects.
OCR-derived features: These measure the reliability of the text extraction, such as how orderly the tokens are, whether confidence scores are high, or if the system has produced fragments and junk text.
LLM-output features: These reflect the quality of the structured transcription, such as how internally consistent the categories and attributes are, or whether the coverage looks incomplete.
This multi-view approach directly targets the three failure modes identified earlier: inconsistent menu structure, incomplete menus, and poor photographic quality.
By combining signals from the image, the OCR process, and the LLM itself, the guardrail learns to separate high-confidence transcriptions from those that are likely to go wrong.
Guardrail Model Training and Performance
Designing the guardrail model opened up the question of which architecture would actually work best in practice.
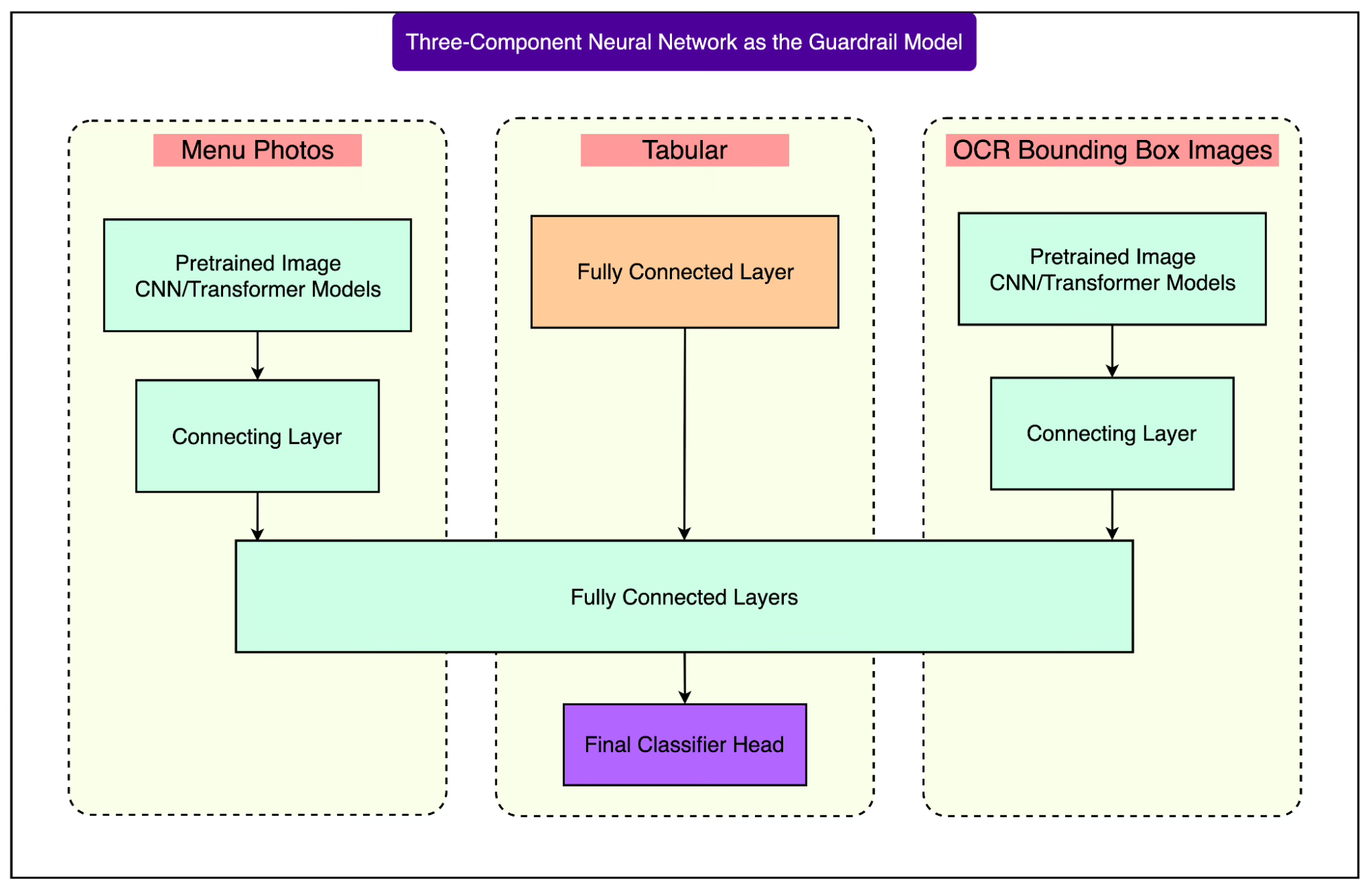
The team experimented with a three-component neural network design that looked like this:
Image encoding: The raw menu photo was passed through a pretrained vision backbone. They tried CNN-based models like VGG16 and ResNet, as well as transformer-based models such as ViT (Vision Transformer) and DiT (Document Image Transformer).
Tabular features: Alongside the image encoding, the network ingested features derived from the OCR output and the LLM transcription.
Fusion and classification: These inputs were combined through fully connected layers, ending in a classifier head that predicted whether a transcription was accurate enough.
The diagram below illustrates this design: an image model on one side, OCR/LLM tabular features on the other, both feeding into dense layers and then merging into a final classifier. It’s a standard multimodal fusion approach designed to capture signals from multiple sources simultaneously.
The results, however, were surprising.
Despite the sophistication of the neural network, the simplest model (LightGBM: a gradient-boosted decision tree) outperformed all the deep learning variants.
LightGBM not only achieved higher accuracy but also ran faster, which made it far more suitable for production deployment. Among the neural network variants, ResNet-based encoding came closest, while ViT-based models performed worst. The main reason was data: limited labeled samples made it difficult for the more complex architectures to shine.
Production Pipeline
Once the guardrail model was in place, the team built a full production pipeline that balanced automation with human review. It works step by step:
Photo validation: Every submitted menu photo goes through basic checks to ensure the file is usable.
Transcription stage: The candidate model (initially the OCR + LLM pipeline) generates a structured transcription from the photo.
Guardrail inference: Features from the photo, OCR output, and LLM summary are fed into the guardrail model, which predicts whether the transcription meets accuracy requirements.
Routing decisions: If the guardrail predicts the transcription is accurate, the structured data is published automatically. If the guardrail predicts likely errors, the photo is escalated to human transcription.
The diagram below shows this pipeline as a flow: menu photos enter, pass through the transcription model, then are evaluated by the guardrail. From there, accurate cases flow directly into the system, while uncertain ones branch off toward human operators.
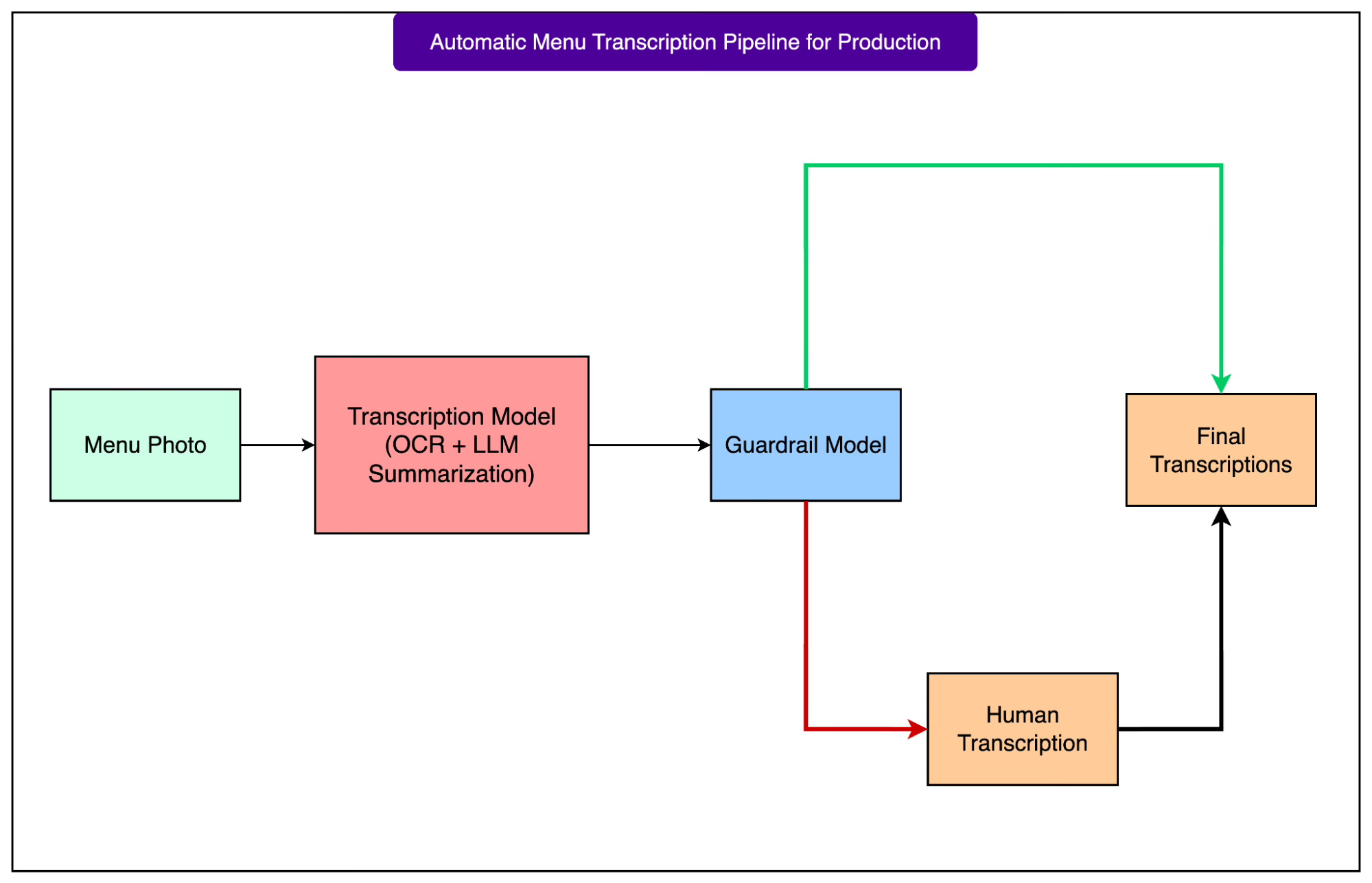
This setup immediately raised efficiency. Machines handled the straightforward cases quickly, while humans focused their effort on the difficult menus. The result was a balanced process: automation sped up operations and cut costs without lowering the quality of the final menu data.
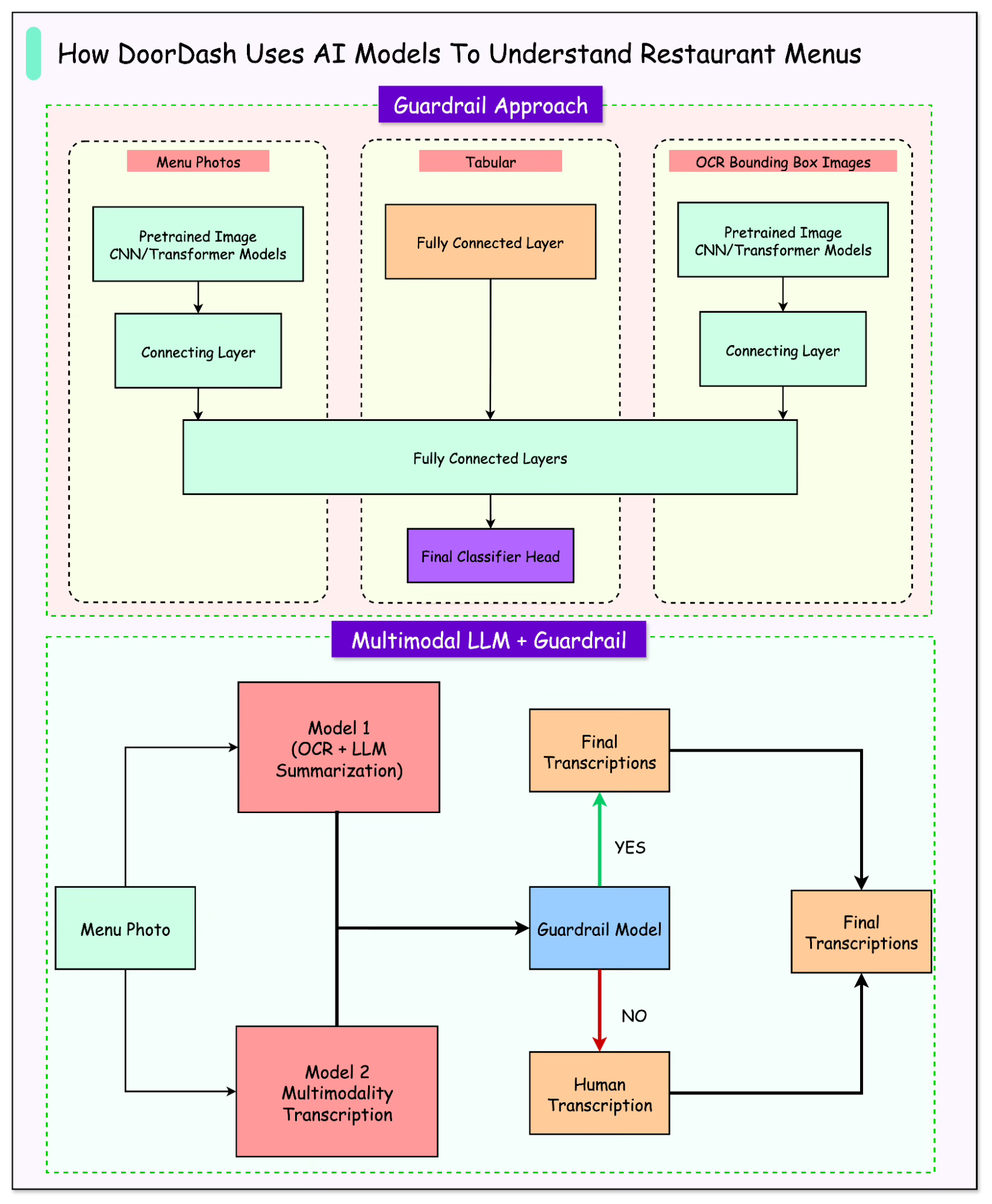
Rapid Evolution with Multimodal GenAI
The pace of AI research did not stand still. In the months after the first guardrail model went live, multimodal LLMs (models that could process both images and text directly) became practical enough to try in production. Instead of relying only on OCR to extract text, these models could look at the raw photo and infer structure directly.
The DoorDash engineering team integrated these multimodal models alongside the existing OCR + LLM pipeline. Each approach had clear strengths and weaknesses:
Multimodal LLMs proved excellent at understanding context and layout. They could better interpret menus with unusual designs, multi-column layouts, or visual cues that OCR often scrambled. However, they were also more brittle when the photo itself was of poor quality, with dark lighting, glare, or partial cropping.
OCR and LLM models were more stable across noisy or degraded inputs, but they struggled with nuanced layout interpretation, often mislinking categories and attributes.
The diagram below shows how the two pipelines now coexist under the same guardrail system.
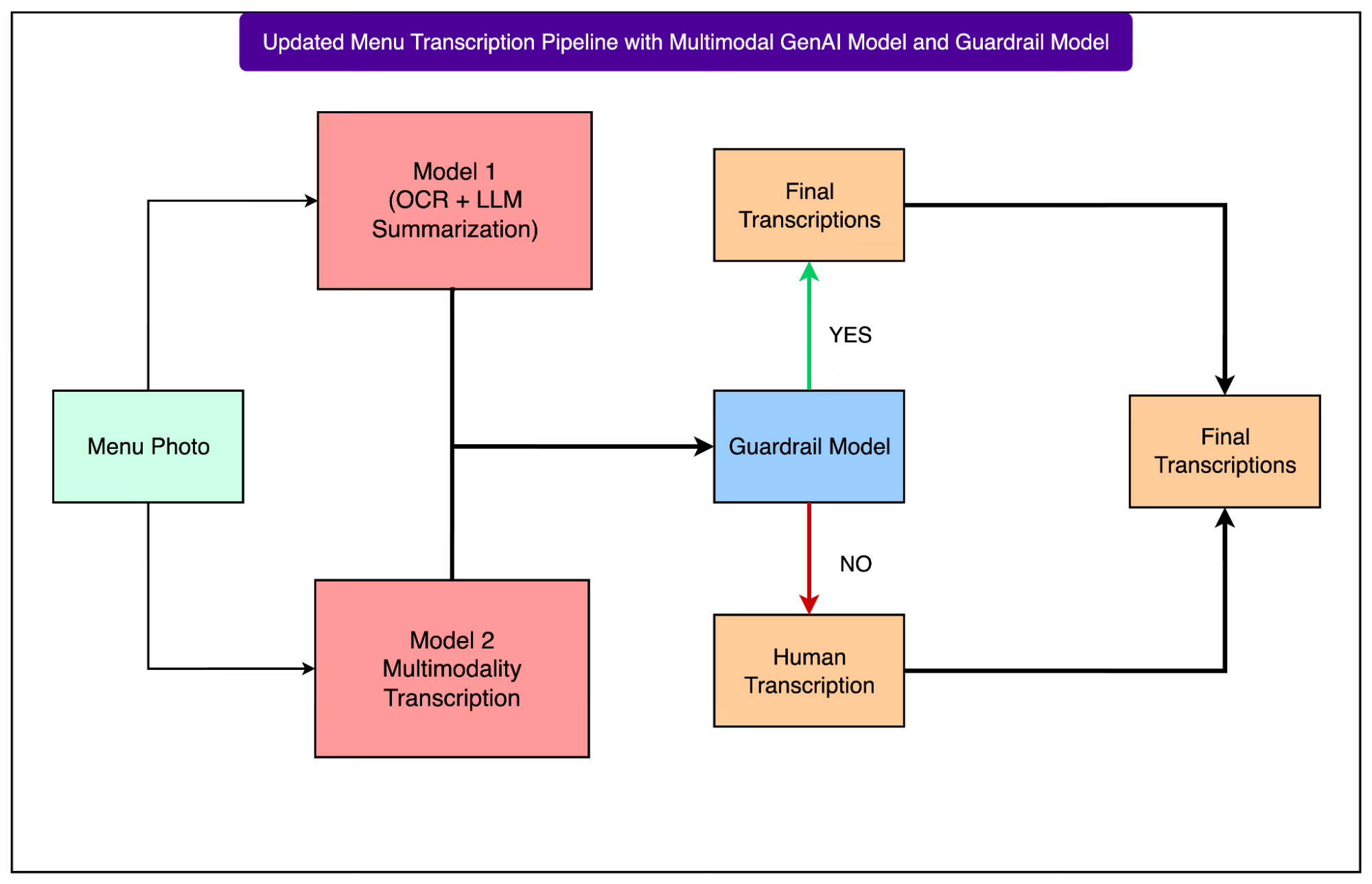
Both models attempt transcription, and their outputs are evaluated. The guardrail then decides which transcriptions meet the accuracy bar and which need human review.
This hybrid setup led to the best of both worlds. By letting the guardrail arbitrate quality between multimodal and OCR-based models, the system boosted automation rates while still preserving the high accuracy required for production.
Conclusion
Automating the transcription of restaurant menus from photos is a deceptively complex problem. What began as a simple OCR-to-LLM pipeline quickly revealed its limits when confronted with messy, real-world inputs: inconsistent structures, incomplete menus, and poor image quality.
The engineering team’s solution was not just to push harder on the models themselves, but to rethink the system architecture. The introduction of a guardrail classifier allowed automation to scale responsibly, ensuring that customers and restaurants always saw accurate menus while machines handled the simpler cases.
As the field of generative AI evolved, the system evolved with it.
By combining OCR and LLM models with newer multimodal approaches under the same guardrail framework, DoorDash was able to harness the strengths of both families of models without being trapped by their weaknesses.
Looking ahead, several opportunities remain open:
Domain fine-tuning: The growing dataset of human-verified transcriptions can be used to fine-tune LLMs and multimodal models for the specific quirks of restaurant menus.
Upstream quality controls: Investing in photo preprocessing with techniques like de-glare, de-noising, de-skewing, and crop detection will lift the accuracy of both OCR-based and multimodal systems.
Guardrail refinement: As models continue to improve, so can the guardrail. Expanding its feature set, retraining LightGBM, or even exploring hybrid architectures will push safe automation further.
References:
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.

What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
why can't they use the guardrail model itself? why we need to use LLM here?
A api call to a Vision Language Model would do the task.
Am I missing something ?