
How DoorDash’s In-House Search Engine Achieved a 50% Drop in Latency

🚀Faster mobile releases with automated QA (Sponsored)

Manual testing on mobile devices is too slow and too limited. It forces teams to cut releases a week early just to test before submitting them to app stores. And without broad device coverage, issues slip through.
QA Wolf’s AI-native service delivers 80% automated test coverage in weeks, with tests running on real iOS devices and Android emulators—all in 100% parallel with zero flakes.
QA cycles reduced to just 15 minutes
Multi-device + gesture interactions fully supported
Reliable test execution with zero flakes
Human-verified bug reports
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Rated 4.8/5 ⭐ on G2
Disclaimer: The details in this post have been derived from the articles written by the DoorDash engineering team. All credit for the technical details goes to the DoorDash Engineering Team. The links to the original articles are present in the references section at the end of the post. Some details related to Apache Lucene® have been taken from the Apache Lucene® official documentation. Apache Lucene® is a registered trademark of The Apache Software Foundation. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Elasticsearch is a proven, battle-tested search engine used by thousands of companies.
However, what works at one scale can fall apart at another. And for a company like DoorDash, operating across continents with a complex marketplace of stores, items, and logistics, things get complicated fast.
By early 2022, the cracks in the foundation were hard to ignore.
Originally, DoorDash's global search was focused on stores. For example, you would search for “pizza” and get nearby pizzerias. That’s a straightforward lookup: return documents tagged with pizza, sorted by location. But over time, user expectations evolved. People wanted to search for specific items, which meant the search had to understand not just where to order, but what they wanted.
To accommodate this shift, the system needed to:
Search across multiple document types.
Handle many-to-one and parent-child relationships.
Filter and rank results based on real-time availability, geo-location, user context, and business logic.
Elasticsearch wasn’t built for this. And though it could be forced to work for these requirements, it needed a lot of work from the engineering team.
Why Elasticsearch Wasn’t Sufficient?
Elasticsearch is a widely adopted solution across modern enterprises. See the diagram below that shows a typical Elasticsearch setup with Logstash and Kibana:
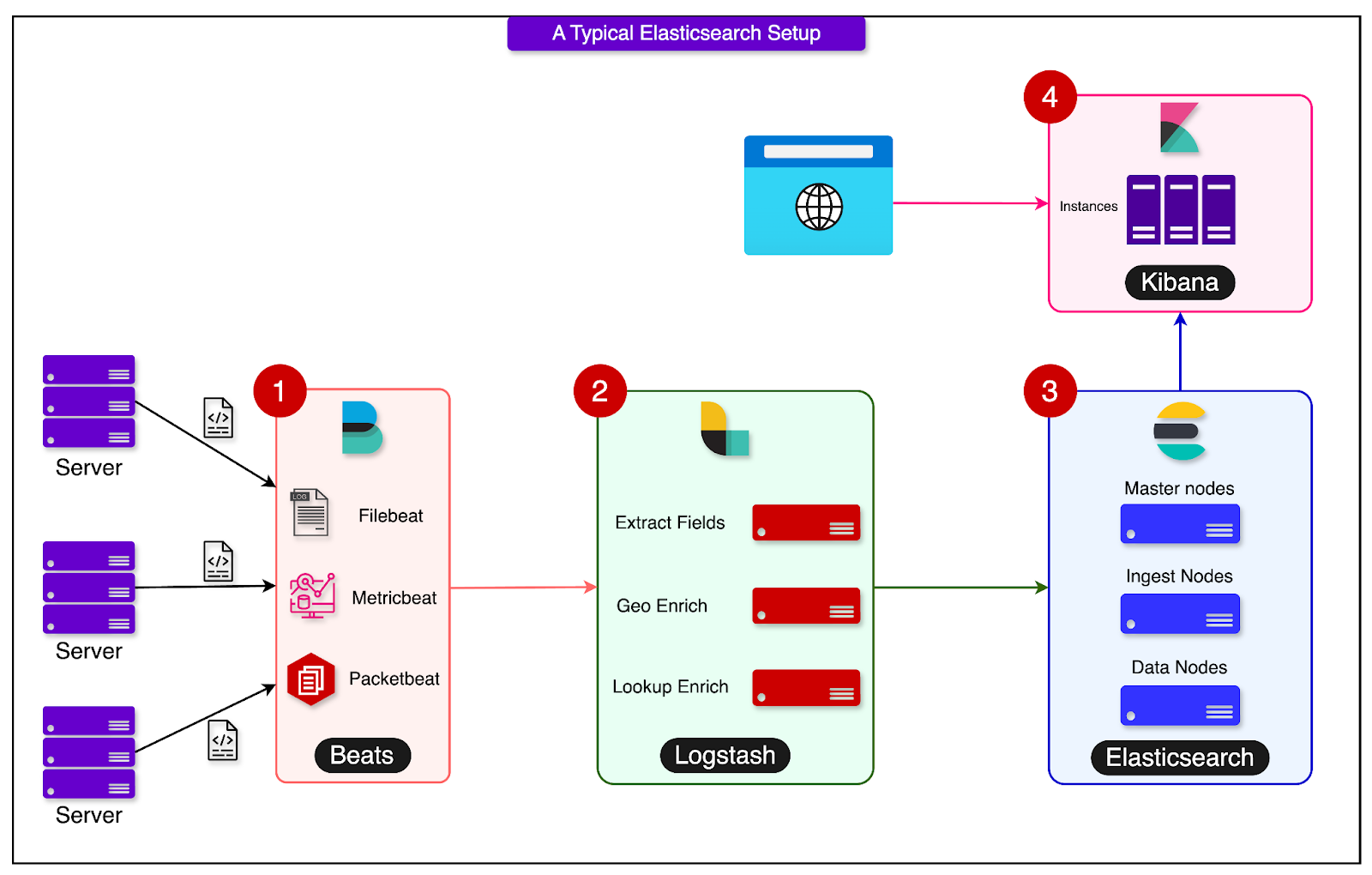
However, for DoorDash, it wasn’t sufficient for a few reasons.
At the heart of the issue was Elasticsearch’s document replication model.
In theory, this model ensures redundancy and resilience. In practice, it introduced significant overhead that made it hard to scale horizontally under DoorDash’s workload. Every document indexed needed to be replicated across nodes, which meant more disk I/O, more network chatter, and more coordination overhead. This became especially painful as the platform grew and indexing volumes spiked.
The second problem was deeper: Elasticsearch doesn’t natively understand relationships between documents. It treats each document as an island, which is fine if you’re searching blog posts or log files. But DoorDash needed to connect the dots between stores and items, and those relationships were critical. For example, if a store goes offline, its items shouldn't show up in search results.
And then, there’s query understanding and ranking. DoorDash needed custom ranking logic, ML-powered relevance tuning, and geo-personalized scoring. With Elasticsearch, all of that had to live outside the engine (in client code, pipelines, or upstream systems), making it fragile and hard to evolve.
Design Principles Behind DoorDash’s In-House Search
To solve the challenges with Elasticsearch, DoorDash decided to build a search engine that could meet their requirements.
However, DoorDash didn’t want to reinvent information retrieval from scratch.
Instead, they built a focused, high-performance engine on top of a battle-tested core and architected everything around flexibility, scalability, and isolation.
Apache Lucene® at the Core
Apache Lucene® is not a search engine. It’s a low-level library for indexing and querying text. Think of it like a database engine without the database: no cluster management, no networking, no APIs.
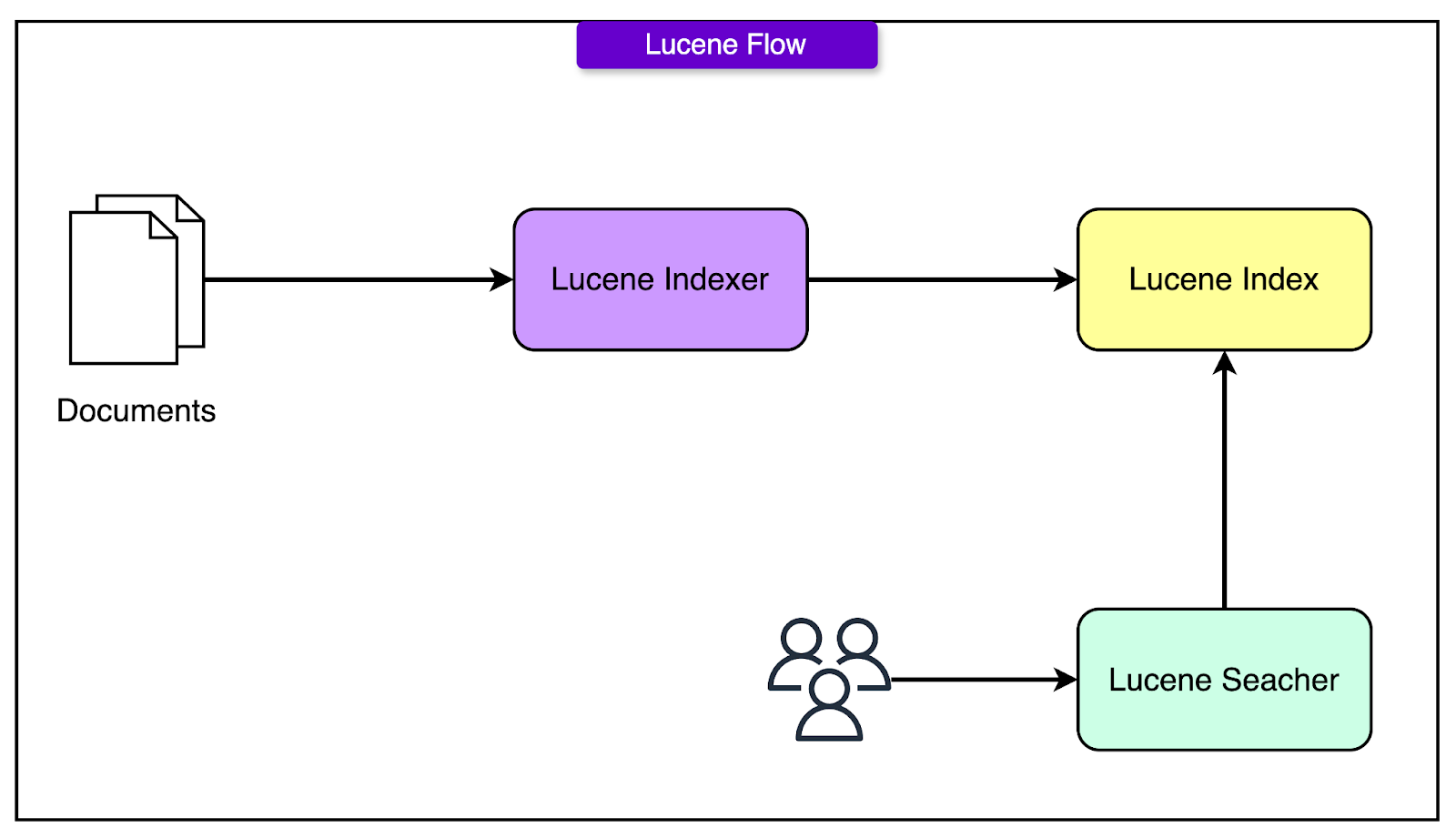
DoorDash picked Apache Lucene® for multiple reasons:
It’s fast, mature, and widely understood.
Apache Lucene® gives you primitives to build exactly what you want.
It’s already trusted by Elasticsearch and Solr under the hood.
However, Apache Lucene® was just the foundation. DoorDash wrapped it in their opinionated services, custom-built for how they think about search, traffic, scaling, and business logic. This gave them full control over performance, extensibility, and cost.
From Document Replication to Segment Replication
In Elasticsearch, every update means replicating full documents across nodes. That sounds fine until you’re processing thousands of changes per second.
DoorDash found a better way: segment replication.
Instead of duplicating documents, they replicate Apache Lucene® index segments: the actual on-disk structures built during indexing. This gave them some benefits:
Optimize indexing and search performance
Reduced compute cost since the work of indexing only happens on the primary node, not on all replicas.
Increased indexing throughput
By treating segments as the unit of replication, the system was able to cut down on churn and keep search nodes lean and stable.
Decoupling Indexing and Search
A common failure pattern in search systems is coupling the write and read paths too tightly. If indexing spikes, search slows down. If queries pile up, indexing stalls. DoorDash didn’t want that.
So they split things cleanly:
The Indexer Service builds Apache Lucene® segments and writes them to Amazon S3. It is a non-replicated service because horizontally scaling the indexer means increasing the number of index shards, which could be expensive.
The Searcher Service (fully replicated) downloads segments from S3 and serves queries.
The payoff from this was huge. Indexers scaled based on write load while searchers scaled based on read traffic. Neither was able to bring the other down.
Key Components of DoorDash’s Search Engine
The diagram below shows the high-level search stack architecture implemented by DoorDash:

There are four main components within the DoorDash Search Engine. Let’s look at each in detail:
1 - The Indexer
The indexer is the part of the system that turns raw data, menus, store info, and item availability into Lucene® segments that can be queried efficiently. It doesn’t serve any queries. It’s a write-only pipeline, pushing finalized Apache Lucene® segments to S3, where searchers can pick them up.
But not all data is created equal. Some changes need to go live now (like a store going offline). Others can wait (like a new menu item added for next week). DoorDash handles this with two-tiered indexing:
High-priority updates: Think availability toggles, store closures, or price changes. These updates go in immediately and are critical to the user experience.
Bulk updates: These are less time-sensitive and processed during scheduled full index rebuilds, typically every six hours.
This strategy balances freshness with performance. If everything were indexed immediately, it could choke the pipeline. If everything were batch, the results might be stale. Splitting the path lets the system stay fast and accurate.
2 - The Searcher
Searchers are replicated services that download prebuilt segments from S3 and use them to answer user queries.
Here are some key points about them:
Searchers never deal with indexing traffic. In other words, they’re not impacted by write spikes.
Scale horizontally based on read traffic
Can be swapped in and out without reindexing since segments are immutable and versioned.
This separation of concerns keeps the system stable. Even when indexing is busy, search stays fast. When search traffic spikes, indexing stays on track.
3 - The Broker
In a distributed search system, results live across many shards. So when someone searches for a term, the system has to:
Fan out the query to every relevant shard.
Collect and merge the results.
Rank and return them.
That’s the broker’s job.
But the broker doesn’t just forward the query. Before it does anything, it runs the input through a Query Understanding and Planning Service. That means the raw user input, misspellings, synonyms, and location context get transformed into a clean, semantically rich query that makes sense to the engine.
4 - Query Planning and Understanding
Search is only as good as your query. Users don’t always type what they mean. Also, different business units might need different ranking models or filter rules.
Rather than pushing all this logic to clients (which would create duplication, drift, and pain), DoorDash centralized it in a Query Planning & Understanding service.
This layer:
Rewrites user queries based on business logic, schema knowledge, and user context.
Applies rules and transformations specific to the index type (item vs. store).
Encodes ranking strategies and computed field logic.
This way, the clients don’t need to micromanage the query structure. They send high-level intent, and the query planner handles the complexity.
Index Schema and Query Language
Search systems tend to break down in one of two ways:
The schema is too rigid, so every new use case needs a hack.
The query language is too abstract, so business logic ends up buried in unreadable config or client code.
DoorDash tackled both problems head-on. They built a declarative, expressive, and extensible schema system, one that treats search not as text matching, but as structured, contextual information retrieval.
Declarative Index Configuration
The first principle was the separation of concerns: business logic belongs in the schema, not scattered across codebases. So DoorDash lets teams define their search behavior declaratively, using three core concepts:
1 - Indexed Fields
These are the raw ingredients that get stored in Apache Lucene®’s inverted index. They can be:
Text fields: Tokenized and scored with models like BM25.
Numeric values or doc values: Used for filtering, sorting, or boosting.
KNN vectors: For semantic search or embedding-based matching.
Dimensional points: Useful for things like geo-search or price ranges.
These are processed at index time: fast to query, static until reindexed.
2 - Computed Fields
Computed fields are evaluated at query time, based on:
The query itself
Indexed field values
Other computed fields
3 - Query Planning Pipelines
This is the glue that connects intent to execution.
A query planning pipeline takes a raw user query, often incomplete, messy, or ambiguous, and transforms it into a structured, executable search query.
This logic lives in one place, not hardcoded into clients, so it’s easy to version, update, and reuse.
Namespaces and Relationships
You can’t build a real-world search engine without modeling relationships.
At DoorDash, stores contain items, and that relationship matters. You don’t want orphaned items showing up when the parent store is closed. To model this, the schema supports namespaces (strongly typed document classes) and relationships between them.
Each namespace represents a distinct document type, such as store, item, and category. These document types have their fields, index settings, and logic.
DoorDash supports two types of relationships between namespaces, each with trade-offs:
In local-join, the child is indexed only if the parent references it. This is used when flexibility matters.
In block-join, the parent and children are indexed together as one unit. This is used when optimizing for latency, and there’s no problem in reindexing batches.
SQL-Like Query Language
DoorDash built a SQL-like API that lets teams describe queries cleanly and clearly. This language supports:
Keyword groups: For example, search by synonyms, stems, categories
Filter constraints: Price range, geo-radius, rating threshold
Sorting: By score, distance, freshness, or any custom logic
Join and dedupe operations: Avoid duplicate listings or improperly scoped results
Field selection: Return only the necessary fields for downstream systems
The query language gives engineers a clean, readable way to build powerful queries. It also sets a consistent contract between teams.
Search Stack Isolation and Control Plane
Most shared systems eventually buckle under their weight, not because the core logic fails, but because tenants step on each other’s toes, deployments collide, and configuration drift creates subtle, hard-to-debug bugs.
DoorDash saw that coming and made a bold design call: every index gets its isolated search stack. It’s not the lightweight approach. But it’s one of the most reliable.
Think of a search stack as a self-contained search engine in a box. It includes:
An Indexer for building Apache Lucene® segments.
One or more Searchers for serving queries.
A Broker that fans out, aggregates, and ranks.
Schema, config, and version metadata that are scoped only to that index.
Each stack is tied to a specific index and use case, like global item search, store discovery, or promo campaign lookup.

This design brings a lot of operational ease due to the following reasons:
Stability: If a bad index config or corrupted segment takes down one stack, the others stay up.
Flexibility: Different teams can use different query planners, schemas, ranking models, or pipelines without coordination.
Traceability: Resource usage, query performance, and indexing lag can all be scoped to the owning team. No more finger-pointing during incident reviews.
One question, however, remains: if every team has its stack, how do you manage rollouts, schema changes, and new deployments without introducing chaos?
That’s where the control plane steps in. It’s an orchestration layer responsible for:
Rolling out new generations of a search stack.
Managing versioned deployments (code + schema + config).
Gradually scaling up new instances and decommissioning old ones.
Conclusion
Rebuilding core infrastructure is always risky and complex. So when DoorDash migrated off Elasticsearch, the stakes were high. But the outcome was worth it.
Here are some gains they achieved:
50% reduction in p99.9 latency. This isn’t average latency but tail latency that has the most impact during high-traffic moments. Halving p99.9 means fewer timeouts, smoother user experience, and less need to overprovision.
75% drop in hardware costs. By cutting down redundant computation, reducing replication overhead, and better workload isolation, DoorDash dramatically lowered the footprint of its search infrastructure.
Ultimately, DoorDash didn’t just build a search engine but an entire platform that runs faster, costs less, and adapts better to future needs.
Note: Apache Lucene® is a registered trademark of the Apache Software Foundation.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.