
How Dropbox Built an AI Product Dash with RAG and AI Agents

✂️ Cut your QA cycles down to minutes with QA Wolf (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobiles apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Dropbox Engineering Team. All credit for the technical details goes to the Dropbox Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Modern knowledge work doesn’t suffer from a lack of information. It suffers from too much of it, scattered across too many tools and media. For example, emails, documents, chats, project trackers, and meeting notes. Each tool solves a narrow problem, but together they create friction that slows teams down and increases operational risk.
Three things tend to break:
Productivity takes a hit. Teams waste hours jumping between apps, copying links, and asking around for specific documents.
Search becomes manual. Finding a specific decision or file often means scrolling, guessing keywords, or opening ten tabs at once.
Security boundaries blur. Sensitive data may appear in unintended locations, particularly when access control varies across different platforms.
Dropbox built Dash to untangle this mess, not by replacing individual tools, but by giving users a way to cut across them. Dash acts as a unified search and knowledge layer that sits on top of emails, files, chats, calendars, and other data sources.
At a high level, Dash provides:
Universal search that understands structure and context across formats.
Content organization without forcing people to change how they work.
Controlled sharing based on granular access policies.
Secure boundaries so only the right people see the right content.
AI-powered summarization and generation to reduce context-switching and speed up workflows.
In this article, we look at how Dropbox leveraged RAG and AI Agents to make Dash a reality.
Core Challenges
Building an AI product for consumer use is one thing. Building it for business environments introduces another layer of complexity entirely.
Three core challenges stand out:
Data Diversity: Business data doesn't come in a single format. Emails, documents, spreadsheets, project boards, calendar events, and meeting notes all use different structures. Each one carries its semantics. Extracting meaning requires custom logic for each type. A strategy that works well for parsing email threads doesn’t apply to task updates in a project board.
Data Fragmentation: Information is rarely in one place. It lives across tools such as Gmail, Slack, Notion, Jira, Dropbox, and dozens of other services. Each platform stores data differently and enforces different access rules. Stitching these sources together without losing context or violating permissions is a constant balancing act.
Data Modalities: Text is only part of the story. Knowledge workers deal with audio recordings, video calls, diagrams, and screenshots. A useful system needs to answer questions like "Summarize this call" or "Find the latest design sketch." That means understanding across modalities, not just within them.
Retrieval Augmented Generation (RAG)
Large Language Models (LLMs) are powerful, but they have a short memory. Out of the box, they guess based on training data and often hallucinate details when context is missing.
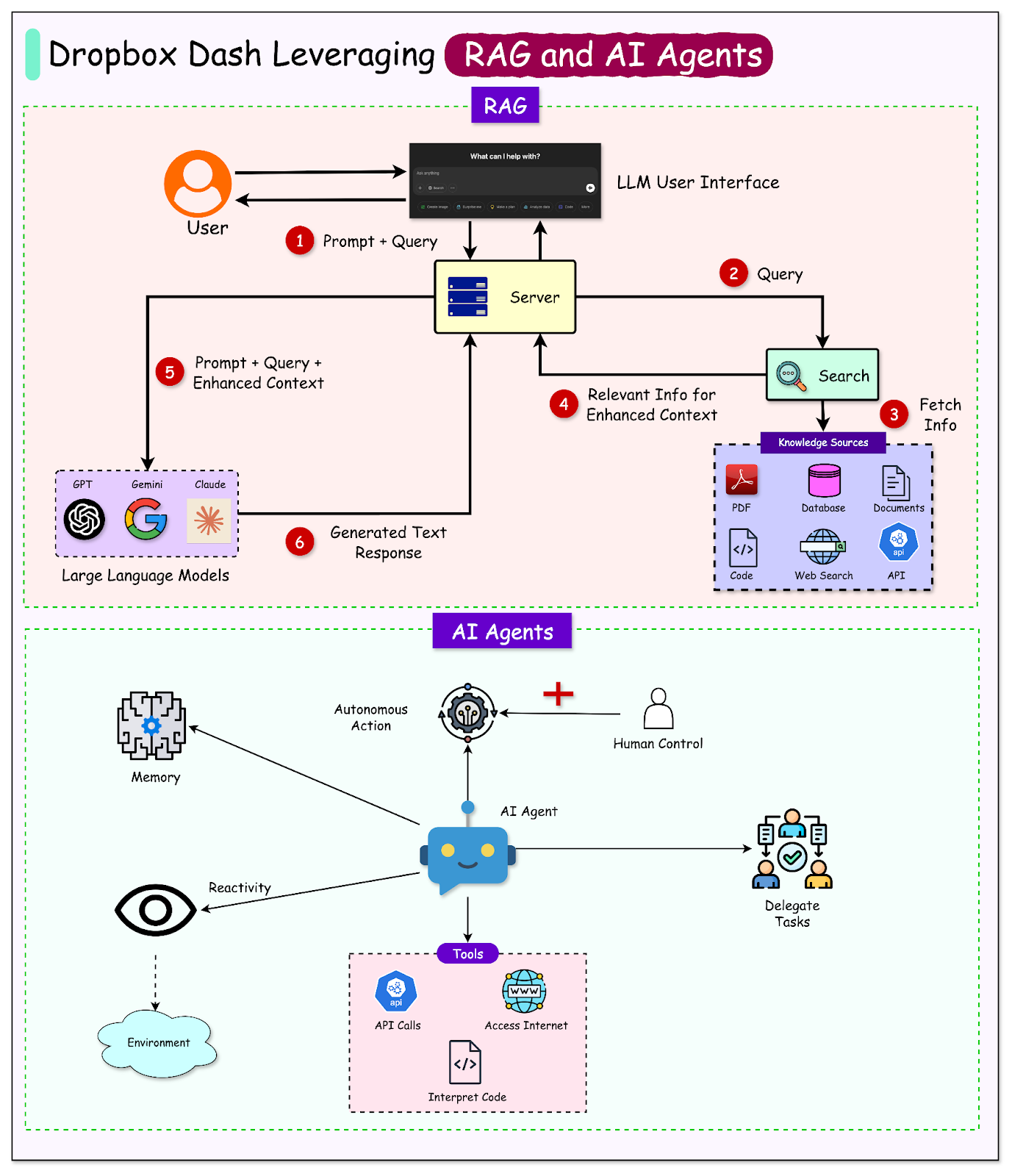
Retrieval-Augmented Generation, or RAG, fixes this by grounding generation in real documents. Here’s how it works:
The system first retrieves relevant documents from a knowledge base.
It then feeds those documents into the LLM, which generates a response using the retrieved context.
This two-step setup adds discipline to the generation process. The model can reference real data instead of improvising. In business settings, where incorrect answers can cause reputational or legal problems, this is a critical requirement.
See the diagram below that shows how RAG works on a high level:
RAG matters in the enterprise because answers reflect real content, not just what the model “remembers.” Context stays fresh, and updates in connected systems reflect in responses as soon as the underlying index is refreshed. The model is limited to generating from what it retrieved, without assumptions.
However, the retrieval component makes or breaks a RAG pipeline. It controls what the LLM sees and how fast it sees it. Three metrics define success:
Latency: How fast can the system find relevant documents?
Quality: Are those documents accurate and complete?
Coverage: Does the system consistently find the right set of documents for a given query?
However, some trade-offs have to be considered:
Latency vs. Quality: Larger embeddings or reranking improve quality but increase response time.
Freshness vs. Scalability: Real-time indexing or API calls ensure up-to-date data, but slow things down.
Budget vs. User Experience: High-quality retrieval costs more compute. Cut costs, and relevance may drop.
Dash avoids a one-size-fits-all solution.
It uses a hybrid retrieval strategy that blends traditional lexical information retrieval to match keywords quickly. There is on-the-fly chunking to extract only the most relevant text from documents at query time and semantic reranking using embeddings to re-order results by meaning, not just keyword match.
The goal is to deliver high-quality results in under 2 seconds for over 95 percent of queries. This balance keeps latency acceptable while maintaining accuracy and context fidelity.
After retrieval, the LLM still needs to generate clear, accurate responses from the retrieved data. For this purpose, Dropbox evaluated several models across different types of questions using public benchmarks:
Natural Questions: Real user queries with long, messy source docs
MuSiQue: Multi-hop questions that require combining information from multiple passages
Microsoft MRC: Short passages and queries based on search logs
Evaluation was based on custom metrics, such as:
LLM-scored correctness: Did the answer reflect the retrieved evidence accurately?
LLM-scored completeness: Did the answer cover all aspects of the question?
Source precision, recall, and F1: Did the retrieval system surface the right evidence?
The pipeline is intentionally model-agnostic and supports swapping in different LLMs, whether open-source or commercial, depending on evolving capabilities, licensing terms, or customer preferences.
AI Agents
Retrieval-Augmented Generation works well when the task is simple: ask a question, get a grounded answer. However, business workflows rarely look like that. More often, they involve a chain of decisions, conditionals, and context-specific logic. That is where AI agents take over.
An AI agent is not just a smarter chatbot. It is a system that can break down a user query into multiple sub-tasks and execute those sub-tasks in the right order or in parallel to return a structured, final result that solves the actual request.
See the diagram below to understand how AI agents work:
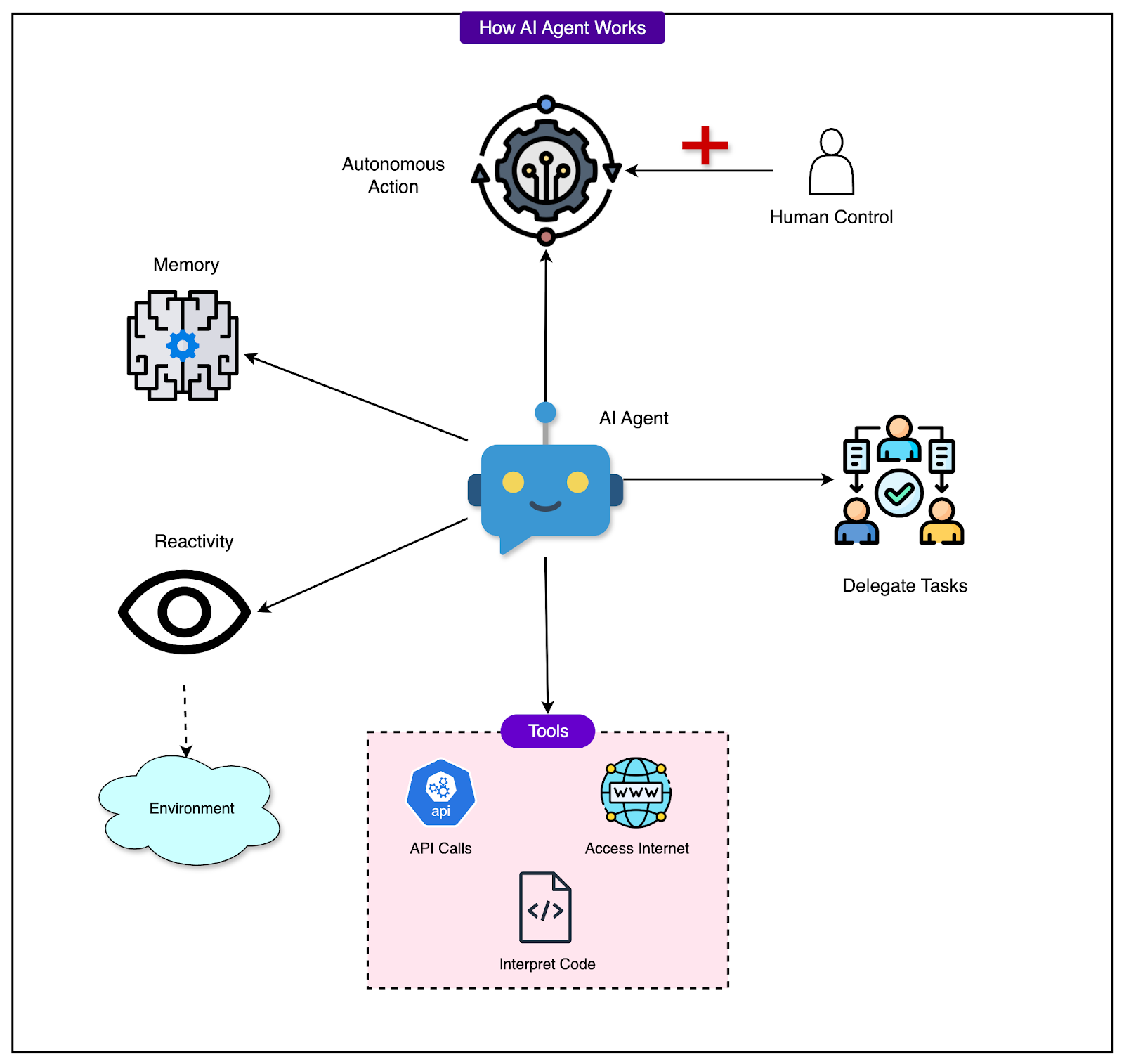
Dropbox agents operate in two main phases: planning and execution.
Stage 1: Planning the Task
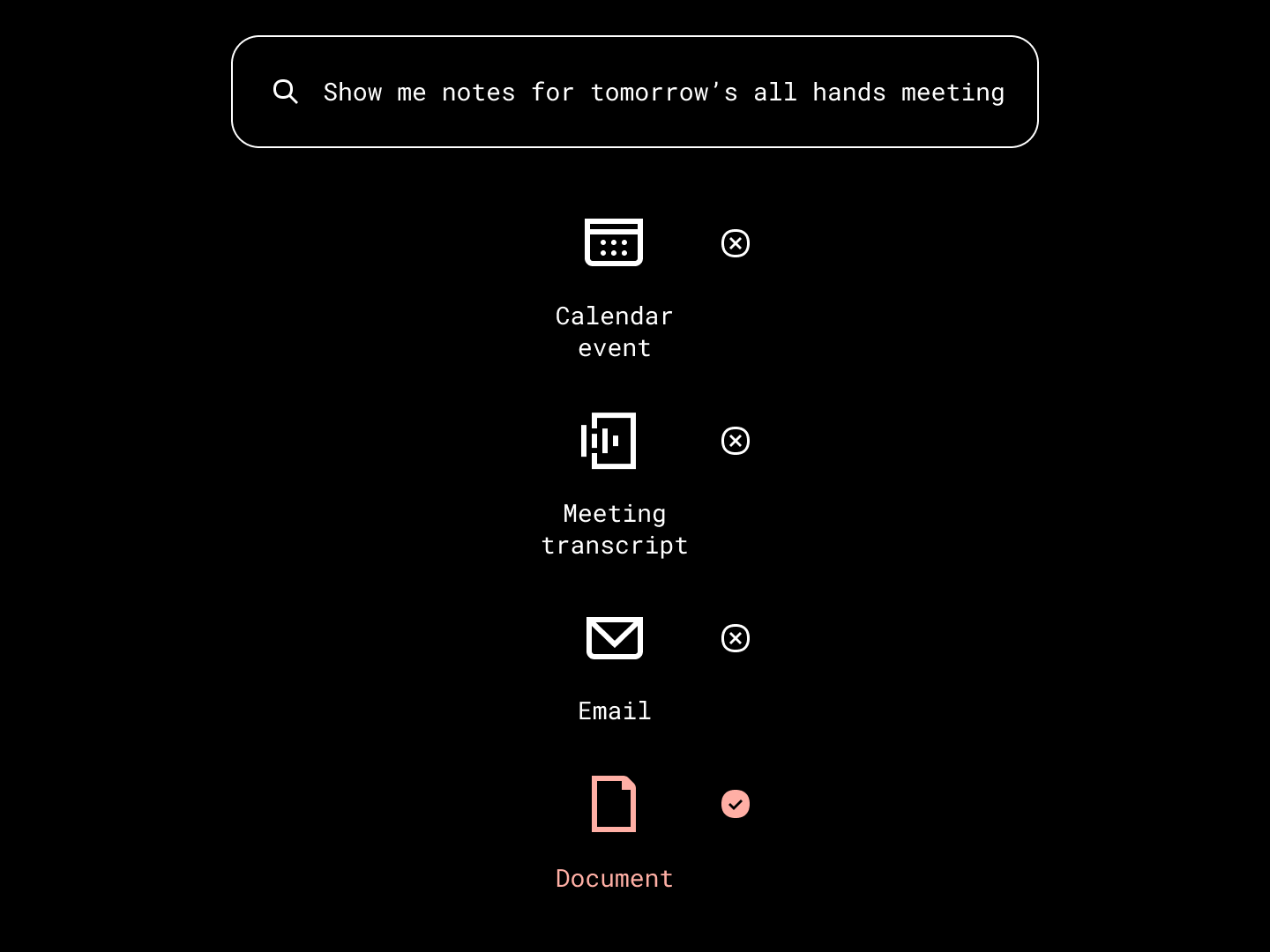
The agent starts with a query from the user. It passes that input to an LLM, which translates it into a sequence of logical steps expressed in code. This code is written in a Python-like domain-specific language (DSL) designed specifically for agent planning.
For example, the request “Show me the notes for tomorrow’s all-hands meeting” gets broken down as:
Resolve “tomorrow” into an actual date range.
Find a meeting whose title includes “all-hands” and occurs within that time window.
Retrieve the notes or documents attached to that meeting.
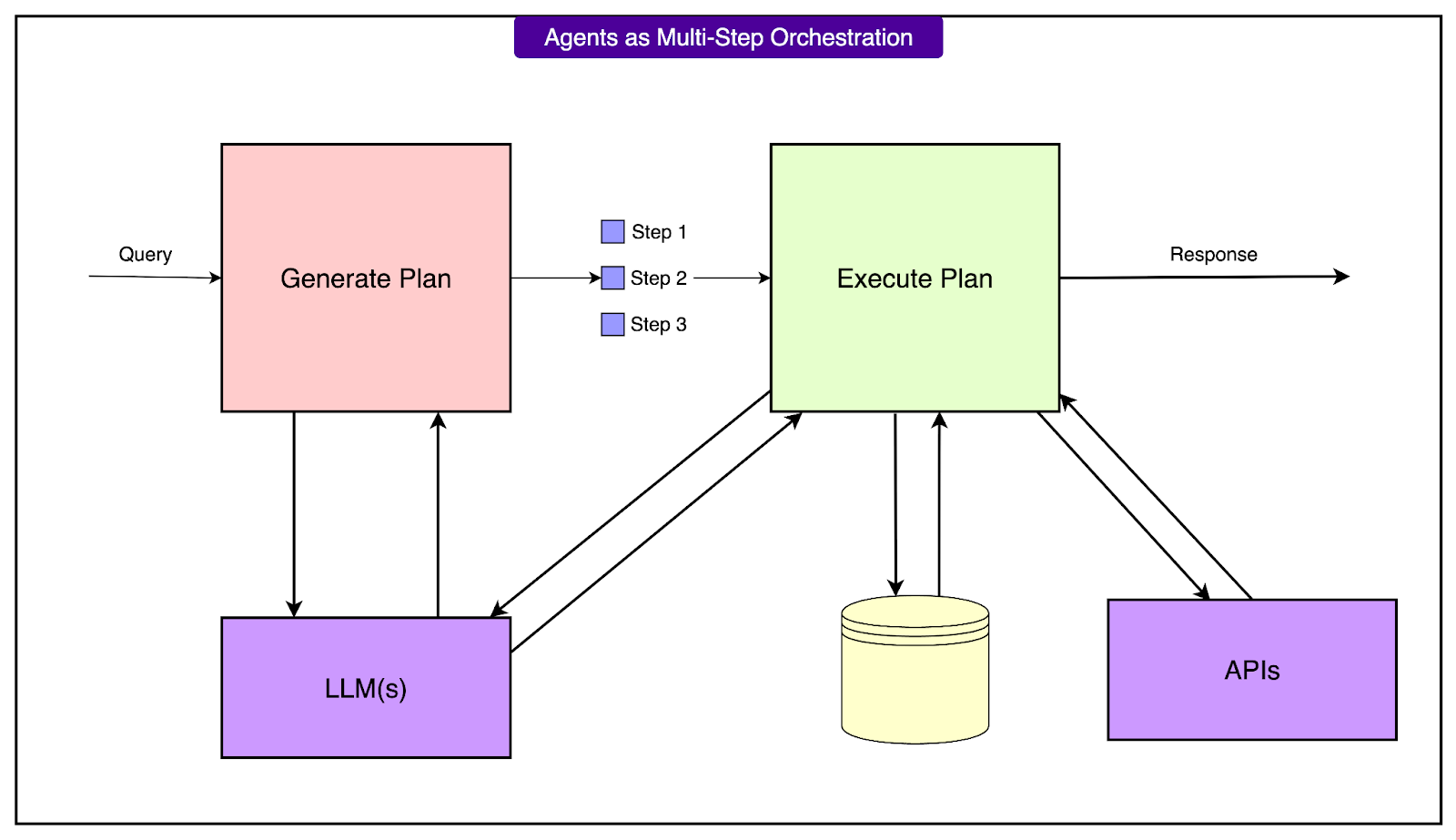
Stage 2: Executing the Plan
Once the plan is ready, the system validates it through static analysis.
This step checks the code for missing functions, incorrect types, and possible logic errors before anything runs. If the LLM generated a reference to a helper function that does not yet exist, the system can loop back and generate that function on demand.
Execution happens inside a custom-built interpreter created by Dropbox.
The Need for a Custom Interpreter
Running arbitrary Python code from an LLM introduces serious risks, from security vulnerabilities to unexpected behavior. That’s why the Dropbox team built a custom interpreter.
The Dropbox interpreter avoids these issues by:
Supporting only minimal, pre-approved functionality needed for agent tasks.
Enforcing strong typing at runtime to prevent type mismatches and broken data pipelines.
Allowing static validation and dry runs so the system can test the plan before touching real data.
Enabling deterministic debugging, with clear error reports like “Step 2 failed when locating meeting” rather than vague failure messages.
This level of structure makes the system reliable and testable. Engineers can track which exact step failed, why it failed, and whether the underlying helper functions are behaving as expected.
Lessons and Takeaways
Some key lessons are as follows:
RAG and AI agents serve different purposes. RAG works best for direct information lookup and summarization. Agents take over when the task involves reasoning, sequencing, or orchestration.
LLMs are not interchangeable. The same prompt can yield different results across models. Prompt tuning, output formatting, and error handling need to be tailored for each model’s quirks.
Every architectural choice has a cost. Larger models improve accuracy but slow down responses. Smaller models respond faster but may miss nuance. The right balance depends on what the product optimizes for in terms of speed, precision, or flexibility.
Conclusion
Building Dash forced a deeper understanding of how AI fits into real business workflows. Retrieval alone doesn’t cut it when tasks grow complex. Agents add structure, determinism, and execution logic where generative models fall short.
However, this is only a starting point. Future work pushes the boundary further. Some of the directions being explored are as follows:
Multi-turn agents with persistent memory will enable fluid, ongoing interactions instead of one-shot prompts.
Self-reflective agents that learn from their failures will reduce brittleness and improve reliability.
Fine-tuning models for domain-specific tasks will raise accuracy without adding latency.
And expanding multilingual capabilities will open Dash to global teams working across languages and formats.
The goal is to move from static Q&A toward adaptive, assistant-like systems that understand context, evolve, and respond intelligently across the full spectrum of knowledge work. Each step forward improves not just the answers AI can give, but how well it understands the work itself.
References:
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.

What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.