
How Facebook Live Scaled to a Billion Users

😘 Kiss bugs goodbye with fully automated end-to-end test coverage (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native service provides high-volume, high-speed test coverage for web and mobile apps, reducing your organizations QA cycle to less than 15 minutes.
They can get you:
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
Disclaimer: The details in this post have been derived from the articles/videos shared online by the Facebook/Meta engineering team. All credit for the technical details goes to the Facebook/Meta Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Facebook didn’t set out to dominate live video overnight. The platform’s live streaming capability began as a hackathon project with the modest goal of seeing how fast they could push video through a prototype backend. It gave the team a way to measure end-to-end latency under real conditions. That test shaped everything that followed.
Facebook Live moved fast by necessity. From that rooftop prototype, it took just four months to launch an MVP through the Mentions app, aimed at public figures like Dwayne Johnson. Within eight months, the platform rolled out to the entire user base, consisting of billions of users.
The video infrastructure team at Facebook owns the end-to-end path of every video. That includes uploads from mobile phones, distributed encoding in data centers, and real-time playback across the globe. They build for scale by default, not because it sounds good in a deck, but because scale is a constraint. When 1.2 billion users might press play, bad architecture can lead to issues.
The infrastructure needed to make that happen relied on foundational principles: composable systems, predictable patterns, and sharp handling of chaos. Every stream, whether it came from a celebrity or a teenager’s backyard, needed the same guarantees: low latency, high availability, and smooth playback. And every bug, every outage, every unexpected spike forced the team to build smarter, not bigger.
In this article, we’ll look at how Facebook Live was built and the kind of challenges they faced.
How Much Do Remote Engineers Make? (Sponsored)

Engineering hiring is booming again: U.S. companies with revenue of $50 million+ are anticipating a 12% hiring increase compared with 2024.
Employers and candidates are wondering: how do remote software engineer salaries compare across global markets?
Terminal’s Remote Software Engineer Salary Report includes data from 260K+ candidates across Latin America, Canada and Europe. Employers can better inform hiring decisions and candidates can understand their earning potential.
Our hiring expertise runs deep: Terminal is the smarter platform for hiring remote engineers. We help you hire elite engineering talent up to 60% cheaper than U.S. talent.
Core Components Behind Facebook Video
At the heart of Facebook’s video strategy lies a sprawling infrastructure. Each component serves a specific role in making sure video content flows smoothly from creators to viewers, no matter where they are or what device they’re using.
See the diagram below that shows a high-level view of this infrastructure:
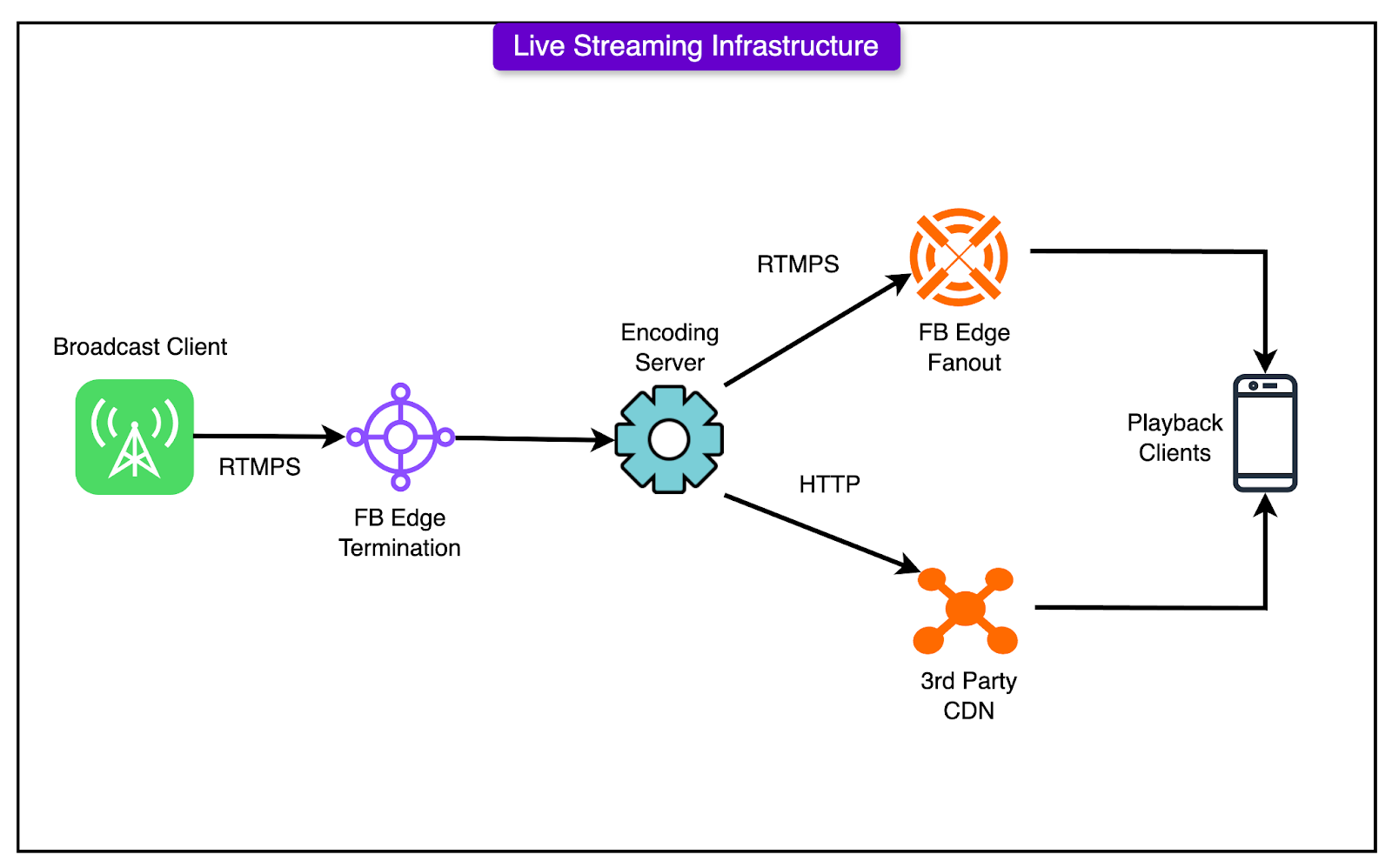
Fast, Fail-Tolerant Uploads
The upload pipeline is where the video journey begins.
It handles everything from a celebrity’s studio-grade stream to a shaky phone video in a moving car. Uploads must be fast, but more importantly, they must be resilient. Network drops, flaky connections, or device quirks shouldn’t stall the system.
Uploads are chunked to support resumability and reduce retry cost.
Redundant paths and retries protect against partial failures.
Metadata extraction starts during upload, enabling early classification and processing.
Beyond reliability, the system clusters similar videos. This feeds recommendation engines that suggest related content to the users. The grouping happens based on visual and audio similarity, not just titles or tags. That helps surface videos that feel naturally connected, even if their metadata disagrees.
Encoding at Scale
Encoding is a computationally heavy bottleneck if done naively. Facebook splits incoming videos into chunks, encodes them in parallel, and stitches them back together.
This massively reduces latency and allows the system to scale horizontally. Some features are as follows:
Each chunk is independently transcoded across a fleet of servers.
Bitrate ladders are generated dynamically to support adaptive playback.
Reassembly happens quickly without degrading quality or syncing.
This platform prepares content for consumption across every device class and network condition. Mobile users in rural zones, desktop viewers on fiber, everyone gets a version that fits their bandwidth and screen.
Live Video as a First-Class Citizen
Live streams add a layer of complexity. Unlike uploaded videos, live content arrives raw, gets processed on the fly, and must reach viewers with minimal delay. The architecture must absorb the chaos of real-time creation while keeping delivery tight and stable.
Broadcast clients (phones, encoders) connect via secure RTMP to entry points called POPs (Points of Presence).
Streams get routed through data centers, transcoded in real time, and dispatched globally.
Viewers watch through mobile apps, desktop browsers, or APIs.
This is like a two-way street. Comments, reactions, and viewer engagement flow back to the broadcaster, making live content deeply interactive. Building that loop demands real-time coordination across networks, services, and user devices.
Scalability Requirements
Scaling Facebook Live is about building for a reality where “peak traffic” is the norm. With over 1.23 billion people logging in daily, the infrastructure must assume high load as the baseline, not the exception.
Some scaling requirements were as follows:
Scale Is the Starting Point
This wasn’t a typical SaaS model growing linearly. When a product like Facebook Live goes global, it lands in every timezone, device, and network condition simultaneously.
The system must perform across the globe in varying conditions, from rural to urban. And every day, it gets pushed by new users, new behaviors, and new demands. Almost 1.23 billion daily active users formed the base load. Traffic patterns should follow cultural, regional, and global events.
Distributed Presence: POPs and DCs
To keep latency low and reliability high, Facebook uses a combination of Points of Presence (POPs) and Data Centers (DCs).
POPs act as the first line of connection, handling ingestion and local caching. They sit closer to users and reduce the hop count.
DCs handle the heavy lifting: encoding, storing, and dispatching live streams to other POPs and clients.

This architecture allows for regional isolation and graceful degradation. If one POP goes down, others can pick up the slack without a central failure.
Scaling Challenges That Break Things
Here are some key scaling challenges Facebook faced that potentially created issues:
Concurrent Stream Ingestion: Handling thousands of concurrent broadcasters at once is not trivial. Ingesting and encoding live streams requires real-time CPU allocation, predictable bandwidth, and a flexible routing system that avoids bottlenecks.
Unpredictable Viewer Surges: Streams rarely follow a uniform pattern. One moment, a stream has minimal viewers. Next, it's viral with 12 million. Predicting this spike is nearly impossible, and that unpredictability wrecks static provisioning strategies. Bandwidth consumption doesn’t scale linearly. Load balancers, caches, and encoders must adapt in seconds, not minutes.
Hot Streams and Viral Behavior: Some streams, such as political events, breaking news, can go global without warning. These events impact the caching and delivery layers. One stream might suddenly account for 50% of all viewer traffic. The system must replicate stream segments rapidly across POPs and dynamically allocate cache layers based on viewer geography.
Live Video Architecture
Streaming video live is about managing flow across an unpredictable, global network. Every live session kicks off a chain reaction across infrastructure components built to handle speed, scale, and chaos. Facebook Live’s architecture reflects this need for real-time resilience.
Live streams originate from a broad set of sources:
Phones with shaky LTE
Desktops with high-definition cameras
Professional setups using the Live API and hardware encoders
These clients create RTMPS (Real-Time Messaging Protocol Secure) streams. RTMPS carries the video payload with low latency and encryption, making it viable for casual streamers and production-level events.
Points of Presence (POPs)
POPs act as the first entry point into Facebook’s video pipeline. They’re regional clusters of servers optimized for:
Terminating RTMPS connections close to the source
Minimizing round-trip latency for the broadcaster
Forwarding streams securely to the appropriate data center
Each POP is tuned to handle a high volume of simultaneous connections and quickly routes streams using consistent hashing to distribute load evenly.
See the diagram below:

Data Centers
Once a POP forwards a stream, the heavy lifting happens in a Facebook data center. This is where the encoding hosts:
Authenticate incoming streams using stream tokens
Claim ownership of each stream to ensure a single source of truth
Transcode video into multiple bitrates and resolutions
Generate playback formats like DASH and HLS
Archive the stream for replay or on-demand viewing

Each data center operates like a mini CDN node, tailored to Facebook’s specific needs and traffic patterns.
Caching and Distribution
Live video puts pressure on distribution in ways that on-demand video doesn’t.
With pre-recorded content, everything is cacheable ahead of time. But in a live stream, the content is being created while it's being consumed. That shifts the burden from storage to coordination. Facebook’s answer was to design a caching strategy that can support this.
The architecture uses a two-tier caching model:
POPs (Points of Presence): Act as local cache layers near users. They hold recently fetched stream segments and manifest files, keeping viewers out of the data center as much as possible.
DCs (Data Centers): Act as origin caches. If a POP misses, it falls back to a DC to retrieve the segment or manifest. This keeps encoding hosts from being overwhelmed by repeated requests.
This separation allows independent scaling and regional flexibility. As more viewers connect from a region, the corresponding POP scales up, caching hot content locally and shielding central systems.
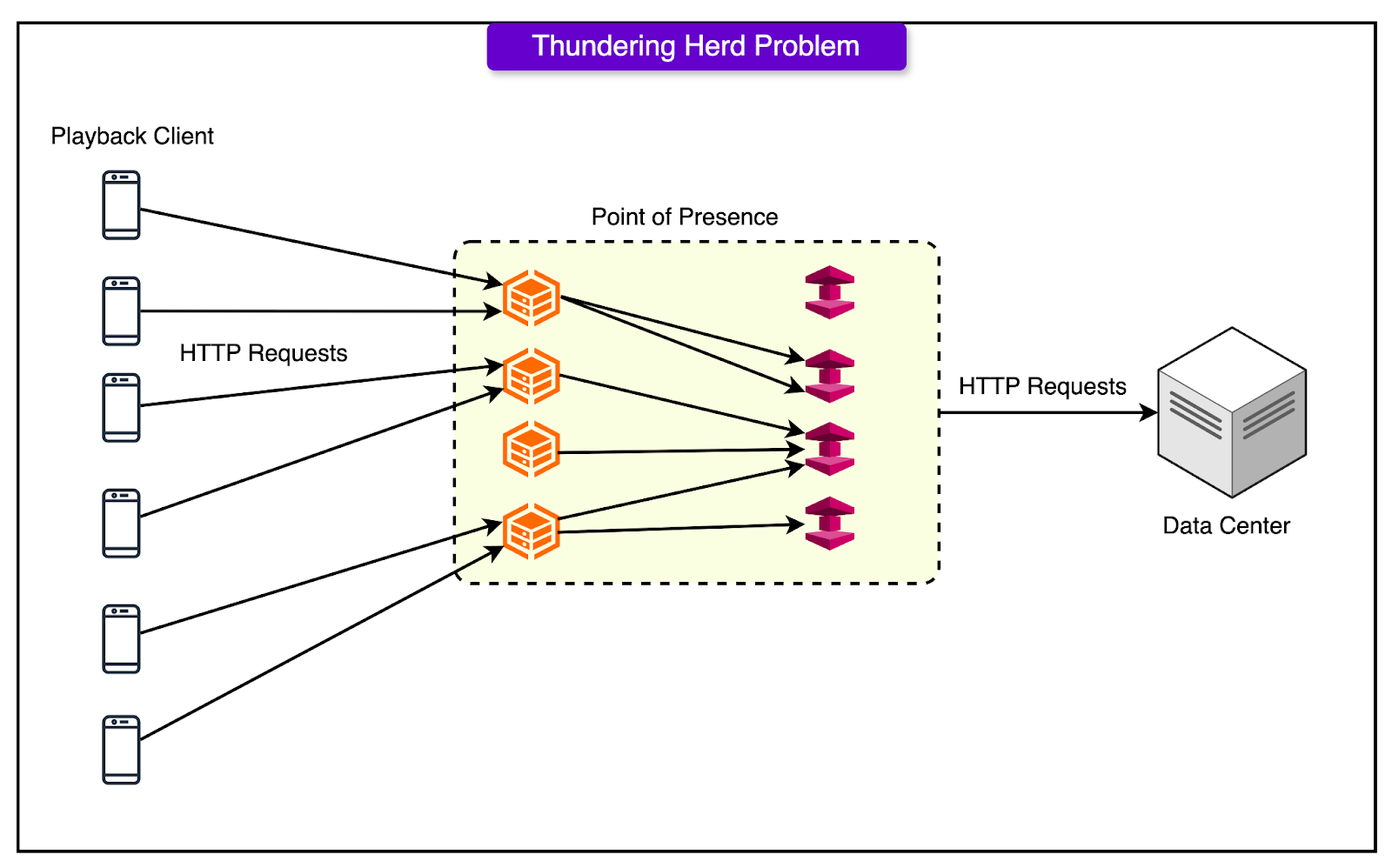
Managing the Thundering Herd
The first time a stream goes viral, hundreds or thousands of clients might request the same manifest or segment at once. If all those hit the data center directly, the system gets into trouble.
To prevent that, Facebook uses cache-blocking timeouts:
When a POP doesn’t have the requested content, it sends a fetch upstream.
All other requests for that content are held back.
If the first request succeeds, the result populates the cache, and everyone gets a hit.
If it times out, everyone floods the DC, causing a thundering herd.
The balance is tricky:
If the timeout is too short, the herd gets unleashed too often.
If the timeout is too long, viewers start experiencing lag or jitter.
Keeping Manifests Fresh
Live streams rely on manifests: a table of contents that lists available segments. Keeping these up-to-date is crucial for smooth playback.
Facebook uses two techniques:
TTL (Time to Live): Each manifest has a short expiry window, usually a few seconds. Clients re-fetch the manifest when it expires.
HTTP Push: A more advanced option, where updates get pushed to POPs in near real-time. This reduces stale reads and speeds up segment availability.
HTTP Push is preferable when tight latency matters, especially for streams with high interaction or fast-paced content. TTL is simpler but comes with trade-offs in freshness and efficiency.
Live Video Playback
Live playback is about consistency, speed, and adaptability across networks that don’t care about user experience.
Facebook’s live playback pipeline turns a firehose of real-time video into a sequence of reliable HTTP requests, and DASH is the backbone that makes that work.
DASH (Dynamic Adaptive Streaming over HTTP)
DASH breaks live video into two components:
A manifest file that acts like a table of contents.
A sequence of media files, each representing a short segment of video (usually 1 second).
The manifest evolves as the stream continues. New entries are appended, old ones fall off, and clients keep polling to see what’s next. This creates a rolling window, typically a few minutes long, that defines what’s currently watchable.
Clients issue HTTP GET requests for the manifest.
When new entries appear, they fetch the corresponding segments.
Segment quality is chosen based on available bandwidth, avoiding buffering or quality drops.
This model works because it’s simple, stateless, and cache-friendly. And when done right, it delivers video with sub-second delay and high reliability.
Where POPs Come In
Playback clients don’t talk to data centers directly. Instead, they go through POPs: edge servers deployed around the world.
POPs serve cached manifests and segments to minimize latency.
If a client requests something new, the POP fetches it from the nearest data center, caches it, and then returns it.
Repeat requests from nearby users hit the POP cache instead of hammering the DC.
This two-tier caching model (POPs and DCs) keeps things fast and scalable:
It reduces the load on encoding hosts, which are expensive to scale.
It localizes traffic, meaning regional outages or spikes don’t propagate upstream.
It handles unpredictable viral traffic with grace, not panic.
Conclusion
Facebook Live didn’t reach a billion users by accident. It got there through deliberate, pragmatic engineering. The architecture was designed to survive chaos in production.
The story begins with a clock stream on a rooftop, but it quickly shifts to decisions under pressure: picking RTMP because it worked, chunking uploads to survive flaky networks, and caching manifests to sidestep thundering herds.
A few lessons cut through all the technical layers:
Start small, iterate fast: The first version of Live aimed to be shippable. That decision accelerated learning and forced architectural clarity early.
Design for scale from day one: Systems built without scale in mind often need to be rebuilt. Live was architected to handle billions, even before the first billion arrived.
Bake reliability into architecture: Redundancy, caching, failover had to be part of the core system. Bolting them on later wouldn’t have worked.
Plan for flexibility in features: From celebrity streams to 360° video, the infrastructure had to adapt quickly. Static systems would’ve blocked product innovation.
Expect the unexpected: Viral content, celebrity spikes, and global outages aren’t edge cases but inevitable. Systems that can’t handle unpredictability don’t last long.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.