
How Facebook’s Distributed Priority Queue Handles Trillions of Items

AI AppGen that understands your business (Sponsored)

AI app builders can scaffold a UI from a prompt. But connecting it to your data, deploying it to your preferred environment, and securing it by default? That’s where most tools break down.
Retool takes you all the way—combining AI app generation with your live data, shared components, and security rules to build full-stack apps you can ship on day one.
Generate apps on top of your data, visually edit in context, and get enterprise-grade RBAC, SSO, and audit logs automatically built in.
Disclaimer: The details in this post have been derived from the details shared online by the Facebook/Meta Engineering Team. All credit for the technical details goes to the Facebook/Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Modern large-scale systems often need to process enormous volumes of work asynchronously.
For example, a social network like Facebook handles many different kinds of background jobs. Some tasks, such as sending a notification, must happen quickly. Others, like translating a large number of posts into multiple languages, can be delayed or processed in parallel. To manage this variety of workloads efficiently, the Facebook engineering team built a service called Facebook Ordered Queueing Service (FOQS).
FOQS is a fully managed, horizontally scalable, multi-tenant distributed priority queue built on sharded MySQL.
In simpler terms, it is a central system that can reliably store and deliver tasks to many different consumers, while respecting their priorities and timing requirements. It acts as a decoupling layer between services, allowing one service to enqueue work and another to process it later. This design keeps systems more resilient and helps engineers control throughput, retry logic, and ordering without building complex custom queues themselves.
The “distributed” part means FOQS runs on many servers at once, and it automatically divides data across multiple MySQL database shards to handle extremely high volumes of tasks. The “priority queue” part means that items can be assigned different importance levels, so the most critical tasks are delivered first. FOQS also supports delayed delivery, letting engineers schedule work for the future rather than immediately.
FOQS plays a key role in some of Facebook’s largest production workflows:
The Async platform uses FOQS to defer non-urgent computation and free up resources for real-time operations.
Video encoding systems use it to fan out a single upload into many parallel encoding jobs that need to be processed efficiently.
Language translation pipelines rely on it to distribute large amounts of parallelizable, compute-heavy translation tasks.
At Facebook’s scale, these background workflows involve trillions of queue operations per day. In this article, we look at how FOQS is structured, how it processes enqueues and dequeues, and how it maintains reliability.
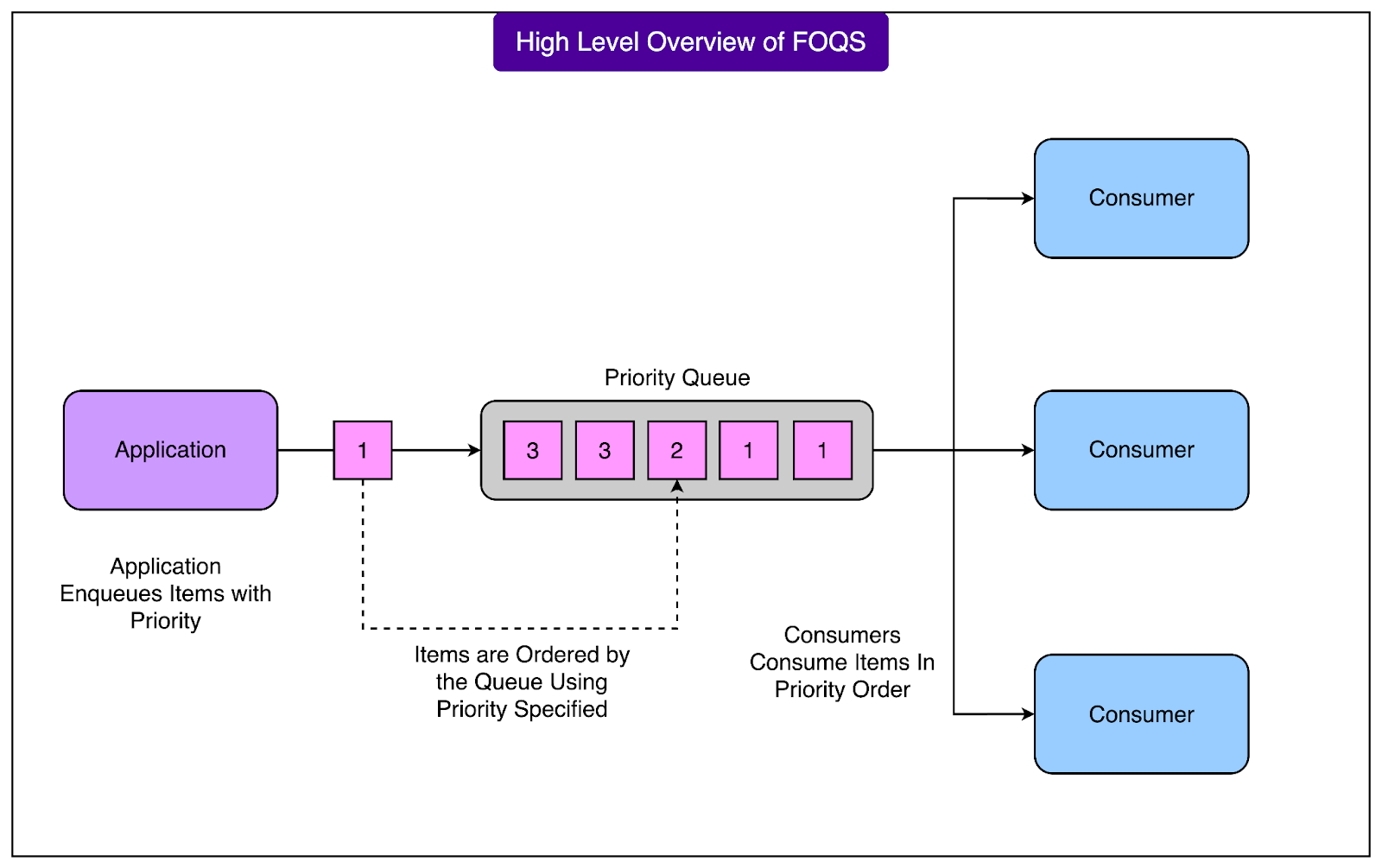
Core Concepts of FOQS
Before looking at how FOQS works internally, it is important to understand the core building blocks that make up the system. Each of these plays a distinct role in how FOQS organizes and delivers tasks at scale.
Namespace
A namespace is the basic unit of multi-tenancy and capacity management in FOQS. Each team or application that uses FOQS gets its own namespace. This separation ensures that one tenant’s workload does not overwhelm others and allows the system to enforce clear performance and quota guarantees.
Every namespace is mapped to exactly one tier. A tier consists of a fleet of FOQS hosts and a set of MySQL shards. You can think of a tier as a self-contained slice of the FOQS infrastructure. By assigning a namespace to a specific tier, Facebook ensures predictable capacity and isolation between different workloads.
Each namespace is also assigned a guaranteed capacity, measured in enqueues per minute. This is the number of items that can be added to the queue per minute without being throttled. These quotas help protect the underlying storage and prevent sudden spikes in one workload from affecting others.
Overall, this design allows FOQS to support many different teams inside Facebook simultaneously, each with its own usage pattern.
Topic
Within a namespace, work is further organized into topics.
A topic acts as a logical priority queue, identified by a simple string name. Topics are designed to be lightweight and dynamic. A new topic is created automatically when the first item is enqueued to it, and it is automatically cleaned up when it becomes empty. There is no need for manual provisioning or configuration.
To help consumers discover available topics, FOQS provides an API called GetActiveTopics. This returns a list of currently active topics in a namespace, meaning topics that have at least one item waiting to be processed. This feature allows consumers to easily find which queues have pending work, even in systems with a large and changing set of topics.
Dynamic topics make FOQS flexible. For example, a video processing system might create a new topic for each uploaded video to process its encoding tasks in isolation. Once the encoding finishes and the queue is empty, the topic disappears automatically.
Item
The item is the most important unit in FOQS because it represents a single task waiting to be processed. Internally, each item is stored as one row in a MySQL table, which allows FOQS to leverage the reliability and indexing capabilities of MySQL.
Each item contains several fields:
Namespace and topic identify which logical queue the item belongs to.
Priority is a 32-bit integer where a lower value means higher priority. This determines the order in which items are delivered.
Payload contains the actual work data. This is an immutable binary blob, up to around 10 KB in size. For example, it could include information about which video to encode or which translation task to perform.
Metadata is a mutable field containing a few hundred bytes. This is often used to store intermediate results, retry counts, or backoff information during the item’s lifecycle.
Deliver_after is a timestamp that specifies when the item becomes eligible for dequeue. This enables delayed delivery, which is useful for scheduling tasks in the future or applying backoff policies.
Lease_duration defines how long a consumer has to acknowledge or reject (ack/nack) the item after dequeuing it. If this time expires without a response, FOQS applies the namespace’s redelivery policy.
TTL (time-to-live) specifies when the item should expire and be removed automatically, even if it has not been processed.
FOQS ID is a globally unique identifier that encodes the shard ID and a 64-bit primary key. This ID allows FOQS to quickly locate the item’s shard and ensure correct routing for acknowledgments and retries.
Together, these fields give FOQS the ability to control when items become available, how they are prioritized, how long they live, and how they are tracked reliably in a distributed system. By storing each item as a single MySQL row, FOQS benefits from strong consistency, efficient indexing, and mature operational tools, which are crucial at Facebook’s scale.
Enqueue Path
The enqueue path in FOQS is responsible for adding new items into the queue reliably and efficiently.
Since FOQS processes trillions of enqueue operations per day, this part of the system must be extremely well optimized for write throughput while also being careful not to overload the underlying MySQL shards. Facebook designed the enqueue pipeline to use buffering, batching, and protective mechanisms to maintain stability under heavy load.
When a client wants to add a new task, it sends an Enqueue request to the appropriate FOQS host. Instead of immediately writing this item to the database, the host first places the request into an in-memory buffer. This approach allows FOQS to batch multiple enqueues together for each shard, which is much more efficient than inserting them one by one. As soon as the request is accepted into the buffer, the client receives a promise that the enqueue operation will be processed shortly.
See the diagram below:
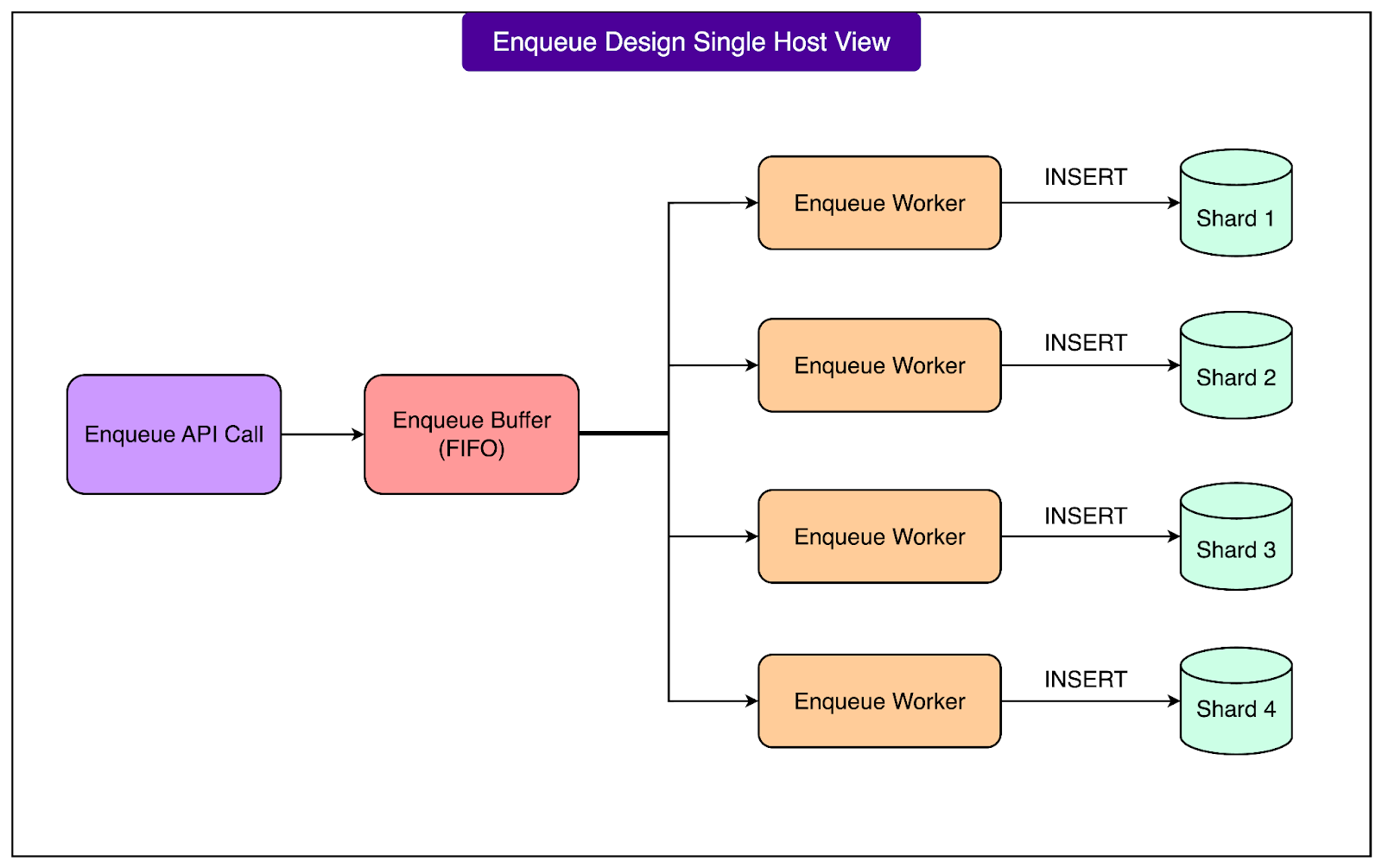
In the background, per-shard worker threads continuously drain these buffers. Each shard of the MySQL database has its own set of workers that take the enqueued items from memory and perform insert operations into the shard’s MySQL table. This batching significantly reduces the overhead on MySQL and enables FOQS to sustain massive write rates across many shards simultaneously. Once the database operation is completed, FOQS fulfills the original promise and sends the result back to the client. If the insert was successful, the client receives the FOQS ID of the newly enqueued item, which uniquely identifies its location. If there was an error, the client is informed accordingly.
An important part of this pipeline is FOQS’s circuit breaker logic, which helps protect both the service and the database from cascading failures. The circuit breaker continuously monitors the health of each MySQL shard. If it detects sustained slow queries or a spike in error rates, it temporarily marks that shard as unhealthy. When a shard is marked unhealthy, FOQS stops sending new enqueue requests to it until it recovers. This prevents a situation where a struggling shard receives more and more traffic, making its performance even worse. By backing off from unhealthy shards, FOQS avoids the classic “thundering herd” problem where too many clients keep retrying against a slow or failing component, causing further instability.
This careful combination of buffering, batching, and protective measures allows FOQS to handle extremely high write volumes without overwhelming its storage backend. It ensures that enqueues remain fast and reliable, even during periods of peak activity or partial database failures.
Dequeue Path
Once tasks have been enqueued, FOQS must deliver them to consumers efficiently and in the correct order.
At Facebook’s scale, the dequeue path needs to support extremely high read throughput while respecting task priorities and scheduled delivery times. To achieve this, FOQS uses a clever combination of in-memory indexes, prefetching, and demand-aware buffering. This design allows the system to serve dequeue requests quickly without hitting the MySQL databases for every single read.
Each MySQL shard maintains an in-memory index of items that are ready to be delivered. This index contains the primary keys of items that can be dequeued immediately, sorted first by priority (with lower numbers meaning higher priority) and then by their deliver_after timestamps. By keeping this index in memory, FOQS avoids repeatedly scanning large database tables just to find the next item to deliver. This is critical for maintaining low latency and high throughput when millions of dequeue operations happen every second.
On top of these per-shard indexes, each FOQS host runs a component called the Prefetch Buffer. This buffer continuously performs a k-way merge across the indexes of all shards that the host is responsible for.
For reference, A k-way merge is a standard algorithmic technique used to combine multiple sorted lists into one sorted list efficiently. In this case, it helps FOQS select the overall best items to deliver next, based on their priority and deliver_after time, from many shards at once. As the prefetcher pulls items from the shards, it marks those items as “delivered” in MySQL. This step prevents the same item from being handed out to multiple consumers simultaneously, ensuring correct delivery semantics. The selected items are then stored in the Prefetch Buffer in memory.
When a client issues a Dequeue request, FOQS simply drains items from the Prefetch Buffer instead of going to the database. This makes dequeue operations very fast, since they are served entirely from memory and benefit from the pre-sorted order of the buffer. The Prefetch Buffer is constantly replenished in the background, so there is usually a pool of ready-to-deliver items available at any moment.
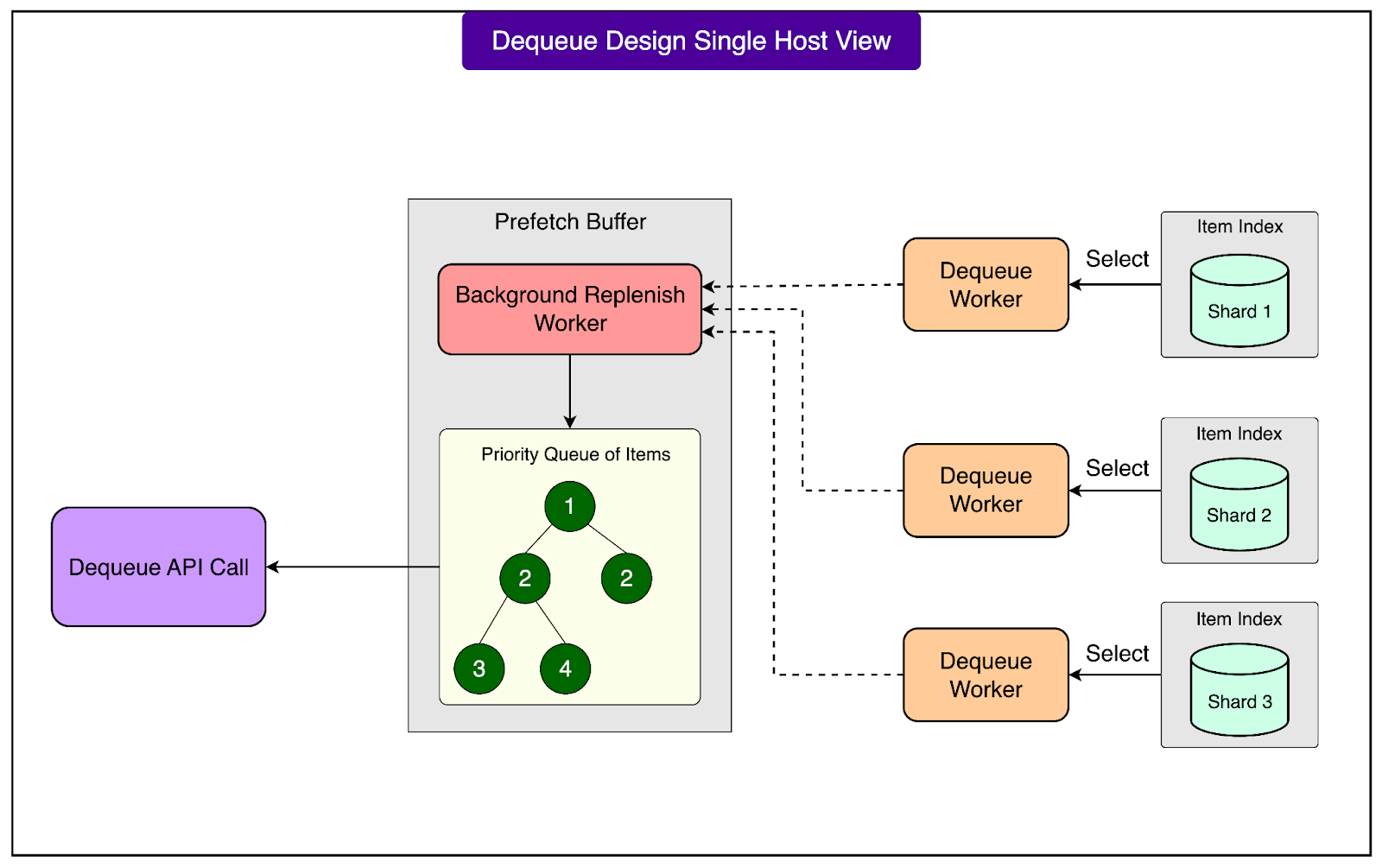
The prefetcher is also demand-aware, meaning it adapts its behavior based on actual consumption patterns. FOQS tracks dequeue rates for each topic and uses this information to refill the Prefetch Buffer proportionally to the demand. Topics that are being consumed heavily receive more aggressive prefetching, which keeps them “warm” in memory and ensures that high-traffic topics can sustain their dequeue rates without delay. This adaptive strategy allows FOQS to balance efficiency across a large number of topics with very different workloads.
Once an item is dequeued, its lease period begins. A lease defines how long the consumer has to either acknowledge (ack) or reject (nack) the item. If the lease expires without receiving either response, FOQS applies the namespace’s delivery policy.
There are two possible behaviors:
At-least-once delivery: The item is returned to the queue and redelivered later. This ensures no tasks are lost, but consumers must handle potential duplicates.
At-most-once delivery: The item is deleted after the lease expires. This avoids duplicates but risks losing tasks if the consumer crashes before processing.
This lease and retry mechanism allows FOQS to handle consumer failures gracefully. If a consumer crashes or becomes unresponsive, FOQS can safely redeliver the work to another consumer (or discard it if at-most-once is chosen).
Ack/Nack Path
Once a consumer finishes processing an item, it must inform FOQS about the result. This is done through acknowledgment (ack) or negative acknowledgment (nack) operations.
Every item in FOQS has a FOQS ID that encodes the shard ID and a unique primary key. When a client wants to acknowledge or reject an item, it uses this shard ID to route the request to the correct FOQS host. This step is crucial because only the host that currently owns the shard can modify the corresponding MySQL rows safely. By routing directly to the right place, FOQS avoids unnecessary network hops and ensures that updates are applied quickly and consistently.
When the FOQS host receives an ack or nack request, it does not immediately write to the database. Instead, it appends the request to an in-memory buffer that is maintained per shard. This buffering is similar to what happens during the enqueue path. By batching multiple ack and nack operations together, FOQS can apply them to the database more efficiently, reducing write overhead and improving overall throughput. See the diagram below:
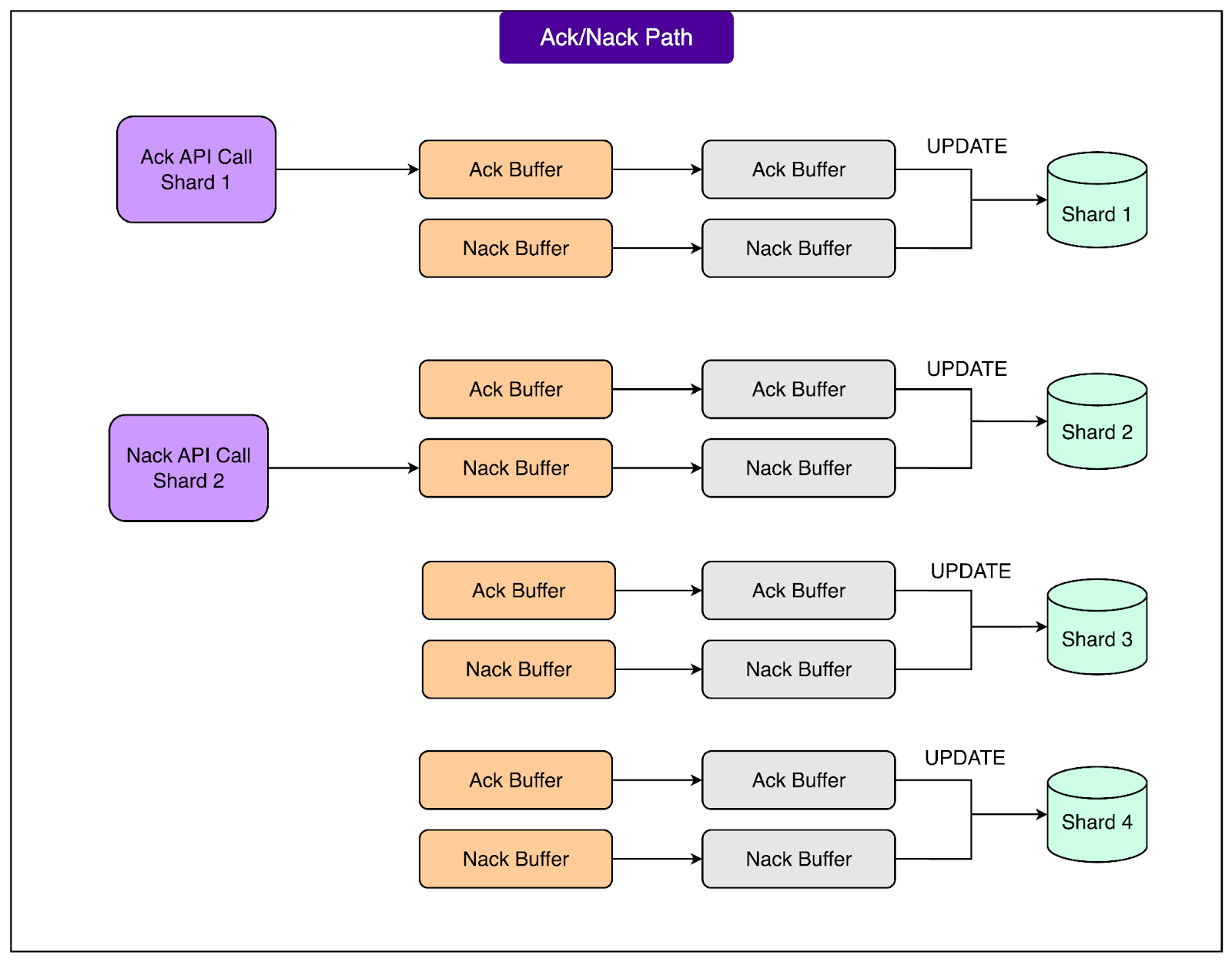
Worker threads on each shard continuously drain these buffers and apply the necessary changes to the MySQL database:
For ack operations, the worker simply deletes the row associated with the item from the shard’s MySQL table. This signals that the task has been successfully completed and permanently removes it from the queue.
For nack operations, the worker updates the item’s deliver_after timestamp and metadata fields. This allows the item to be redelivered later after the specified delay. Updating metadata is useful for tracking retry counts, recording partial progress, or implementing backoff strategies before the next attempt.
The ack and nack operations are idempotent, which means they can be retried safely without causing inconsistent states.
For example, if an ack request is sent twice by mistake or due to a network retry, deleting the same row again has no harmful effect. Similarly, applying the same nack update multiple times leads to the same final state. Idempotency is essential in distributed systems, where messages may be delayed, duplicated, or retried because of transient failures.
If an ack or nack operation fails due to a network issue or a host crash, FOQS does not lose track of the item. When the item’s lease expires, FOQS automatically applies the namespace’s redelivery policy. This ensures that unacknowledged work is either retried (for at-least-once delivery) or cleaned up (for at-most-once delivery), maintaining forward progress without requiring manual intervention.
Push vs Pull
One of the key design decisions in FOQS is its use of a pull-based model for delivering work to consumers.
In a pull model, consumers actively request new items when they are ready to process them, rather than the system pushing items to consumers automatically. Facebook chose this approach because it provides better control, flexibility, and scalability across many different types of workloads.
Workloads inside Facebook vary widely. Some require low latency and high throughput, while others involve slower, scheduled processing. A push model would require FOQS to track each consumer’s capacity and flow control in real time to avoid overwhelming slower workers. This becomes complicated and error-prone at Facebook’s scale, where consumers can number in the thousands and have very different performance characteristics.
The pull model simplifies this problem. Each consumer can control its own processing rate by deciding when and how much to dequeue. This prevents bottlenecks caused by overloaded consumers and makes the system more resilient to sudden slowdowns. It also allows consumers to handle regional affinity and load balancing intelligently, since they can choose where to pull work from based on their location and capacity.
However, the main drawback of pull systems is that consumers need a way to discover available work efficiently. FOQS addresses this with its routing layer and topic discovery API, which help consumers find active topics and shards without scanning the entire system.
Operating at Facebook Scale
FOQS is designed to handle massive workloads that would overwhelm traditional queueing systems.
See the diagram below that shows the distributed architecture for FOQS:
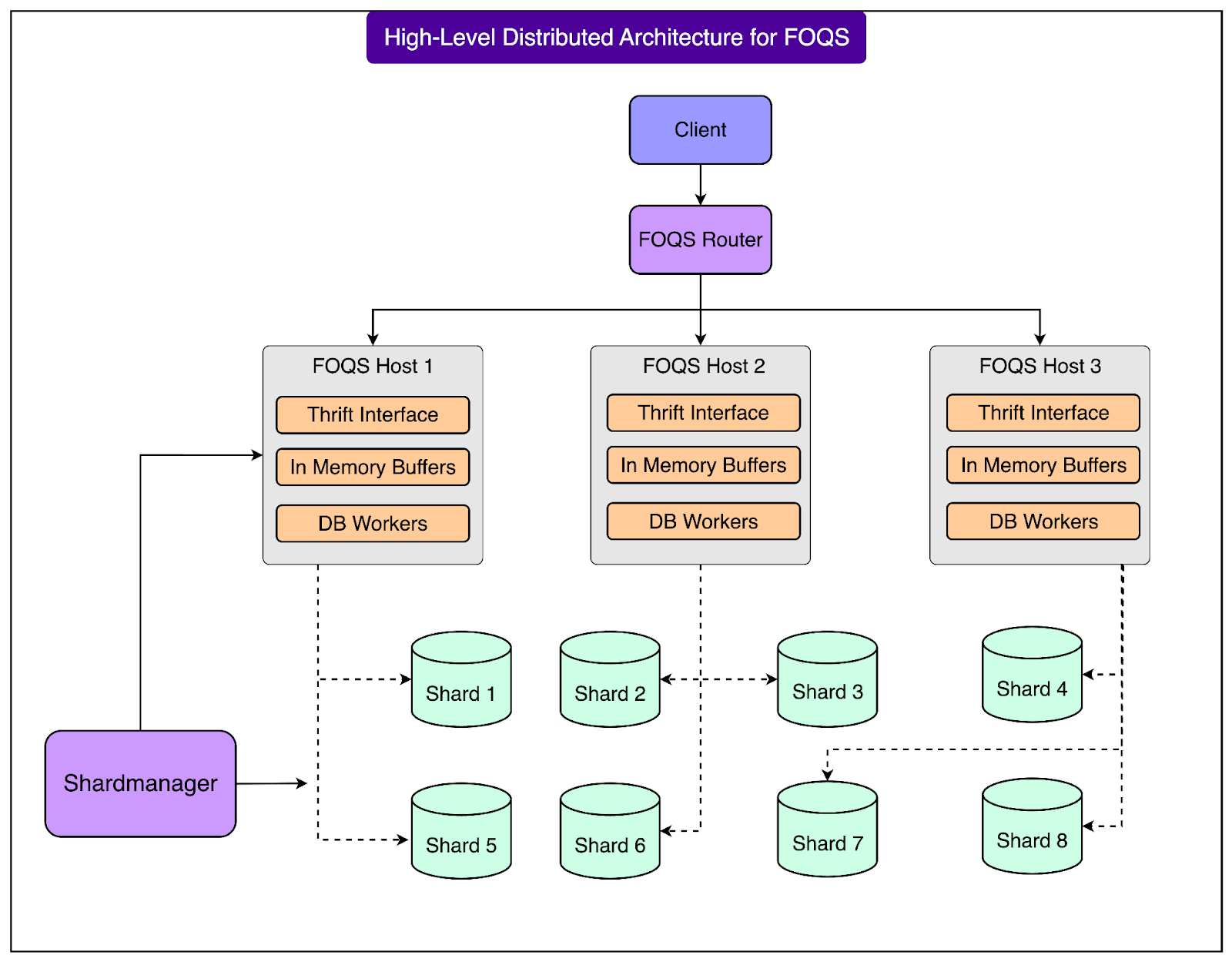
At Facebook, the service processes roughly one trillion items every day. This scale includes not only enqueuing and dequeuing tasks but also managing retries, delays, expirations, and acknowledgments across many regions.
Large distributed systems frequently experience temporary slowdowns or downstream outages. During these events, FOQS may accumulate backlogs of hundreds of billions of items. Instead of treating this as an exception, the system is built to function normally under backlog conditions. Its sharded MySQL storage, prefetching strategy, and routing logic ensure that tasks continue to flow without collapsing under the load.
A key aspect of this scalability is FOQS’s MySQL-centric design. Rather than relying on specialized storage systems, the Facebook engineering team optimized MySQL with careful indexing, in-memory ready queues, and checkpointed scans.
By combining sharding, batching, and resilient queue management, FOQS sustains enormous traffic volumes while maintaining reliability and predictable performance.
Conclusion
Facebook Ordered Queueing Service (FOQS) shows how a priority queue can support diverse workloads at a massive scale.
By building on sharded MySQL and combining techniques like buffering, prefetching, adaptive routing, and leases, FOQS achieves both high performance and operational resilience. Its pull-based model gives consumers control over their processing rates, while its abstractions of namespaces, topics, and items make it flexible enough to support many teams and use cases across the company.
A crucial part of FOQS’s reliability is its disaster readiness strategy. Each shard is replicated across multiple regions, and binlogs are stored both locally and asynchronously across regions. During maintenance or regional failures, Facebook can promote replicas and shift traffic to healthy regions with minimal disruption. This ensures the queue remains functional even when large parts of the infrastructure are affected.
Looking ahead, the Facebook engineering team continues to evolve FOQS to handle more complex failure modes and scaling challenges. Areas of active work include improving multi-region load balancing, refining discoverability as data spreads, and expanding workflow features such as timers and stricter ordering guarantees. These improvements aim to keep FOQS reliable as Facebook’s workloads continue to grow and diversify.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.