
How Fine-Tuning Transforms Generic AI Models into Specialists

Supercharge Cursor and Claude with your team’s knowledge (Sponsored)

AI coding tools become more reliable when they understand the "why" behind your code.
With Unblocked’s MCP server, tools like Cursor and Claude now leverage your team’s historical knowledge across tools like GitHub, Slack, Confluence, and Jira, so the code they generate actually makes sense in your system.
"With Claude Code + Unblocked MCP, I've finally found the holy grail of engineering productivity: context-aware coding. It's not hallucinating. It's pulling insight from everything I've ever worked on." — Staff Engineer @ Nava Benefits
Imagine hiring a brilliant employee who has read every book, article, and document ever written, but knows nothing about your specific company or industry needs. They have incredible general knowledge, but can't help with your particular challenges without additional training.
This is the situation developers can face with large language models like GPT, Claude, or LLaMA. These models possess vast knowledge from their training on internet-scale data, but they may not be optimized for specialized tasks out of the box.
Fine-tuning is the process of taking these generally capable AI models and teaching them specific skills for particular applications. Rather than starting from scratch and spending millions of dollars training a new model, fine-tuning allows you to adapt existing models to excel at your specific needs, whether that's medical diagnosis, legal document analysis, customer service, or code generation.
The economics are compelling.
Training a large language model from scratch costs millions of dollars and requires massive computational resources that only major tech companies can afford. Fine-tuning that same model for your specific use case might cost just hundreds or thousands of dollars, making specialized AI accessible to businesses and researchers with modest budgets.
In this article, we will understand how fine-tuning works at a conceptual level, the different approaches available, and breakthrough techniques like LoRA that have democratized access to AI customization.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo
Warp: The Coding Partner You Can Trust (Sponsored)

Too often, agents write code that almost works, leaving developers debugging instead of shipping.
With Warp you get:
#1 coding agent: Tops benchmarks, delivering more accurate code out of the box.
Tight feedback loop: Built-in code review and editing lets devs quickly spot issues, hand-edit, or reprompt.
1-2 hours saved per day with Warp: All thanks to Warp’s 97% diff acceptance rate.
See why Warp is trusted by over 700k developers → use code BYTEBYTEGO for a month of Warp Pro for just $1.
Understanding the Foundation: Pre-trained Models
Pre-training is the foundational education that large language models receive before they become useful for any specific task.
Think of it as providing a comprehensive general education, similar to how students spend years learning mathematics, science, language, and history before specializing in a particular field. During pre-training, models learn language patterns, facts about the world, reasoning abilities, and how to generate coherent text by processing enormous amounts of text from books, websites, academic papers, and other sources.
See the diagram below:
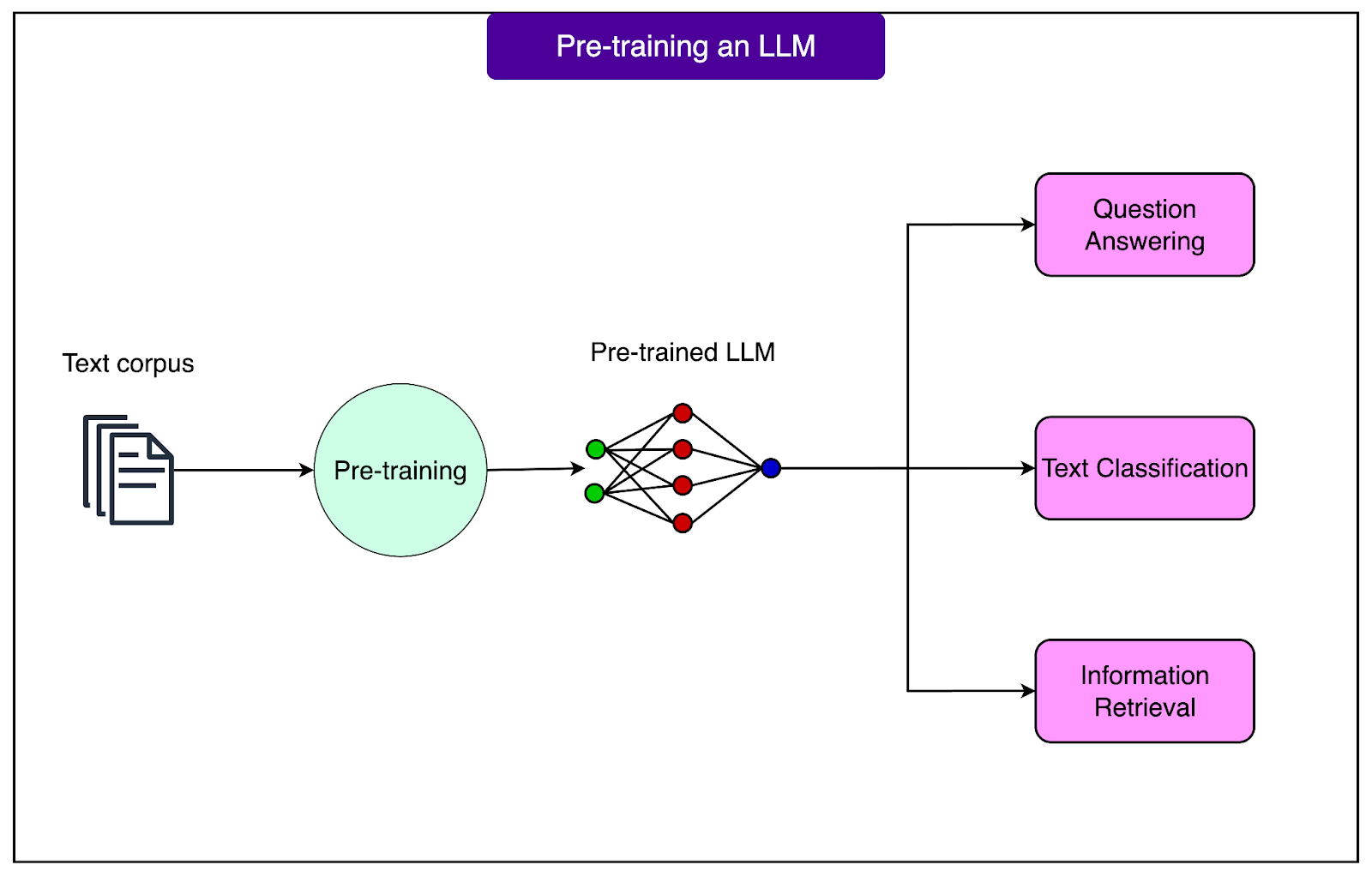
The scale of pre-training is staggering.
Training a model like GPT-3 reportedly costs over $4 million in computational resources alone. The process requires thousands of specialized processors running continuously for months, consuming enough electricity to power hundreds of homes for a year. These models train on datasets containing hundreds of billions of words, essentially reading more text than a human could consume in thousands of lifetimes. This massive investment creates models that understand language structure, can answer questions about diverse topics, and generate human-like text.
We start with pre-trained models because this foundational knowledge is incredibly valuable and expensive to replicate. It would be wasteful for every organization to spend millions creating its own language model from scratch when it can build upon existing ones.
However, this creates a challenge. Pre-trained models are impressive generalists but mediocre specialists. For example, GPT-4 can discuss medicine because it has read medical texts, but it wasn't optimized for medical consultation. It might confidently discuss symptoms, but it lacks the careful diagnostic approach a medical AI should have. Similarly, it knows legal terminology but might not structure arguments the way a legal assistant should.
These models need additional training to transform their broad knowledge into specialized expertise, which is where fine-tuning becomes essential.
The Mechanics of Fine-Tuning
To understand fine-tuning, we need to grasp what neural network weights are.
Weights are simply numbers that represent connection strengths between different parts of the model. Imagine an orchestra where each musician's volume knob affects the final sound. Some instruments need to be louder for jazz, others for classical music. Similarly, a language model has billions of these "volume knobs" (weights) that determine how it processes and generates text. Each weight is just a decimal number like 0.7 or -2.3, and the model's behavior emerges from billions of these numbers working together.
Fine-tuning adjusts these weights to change the model's behavior. Think of it like seasoning a dish that's already cooked. We are not starting from raw ingredients, but taking something already good and adjusting it for a specific taste. During fine-tuning, we show the model examples of specialized behavior, and it slightly adjusts its weights to match these examples better.
See the diagram below:
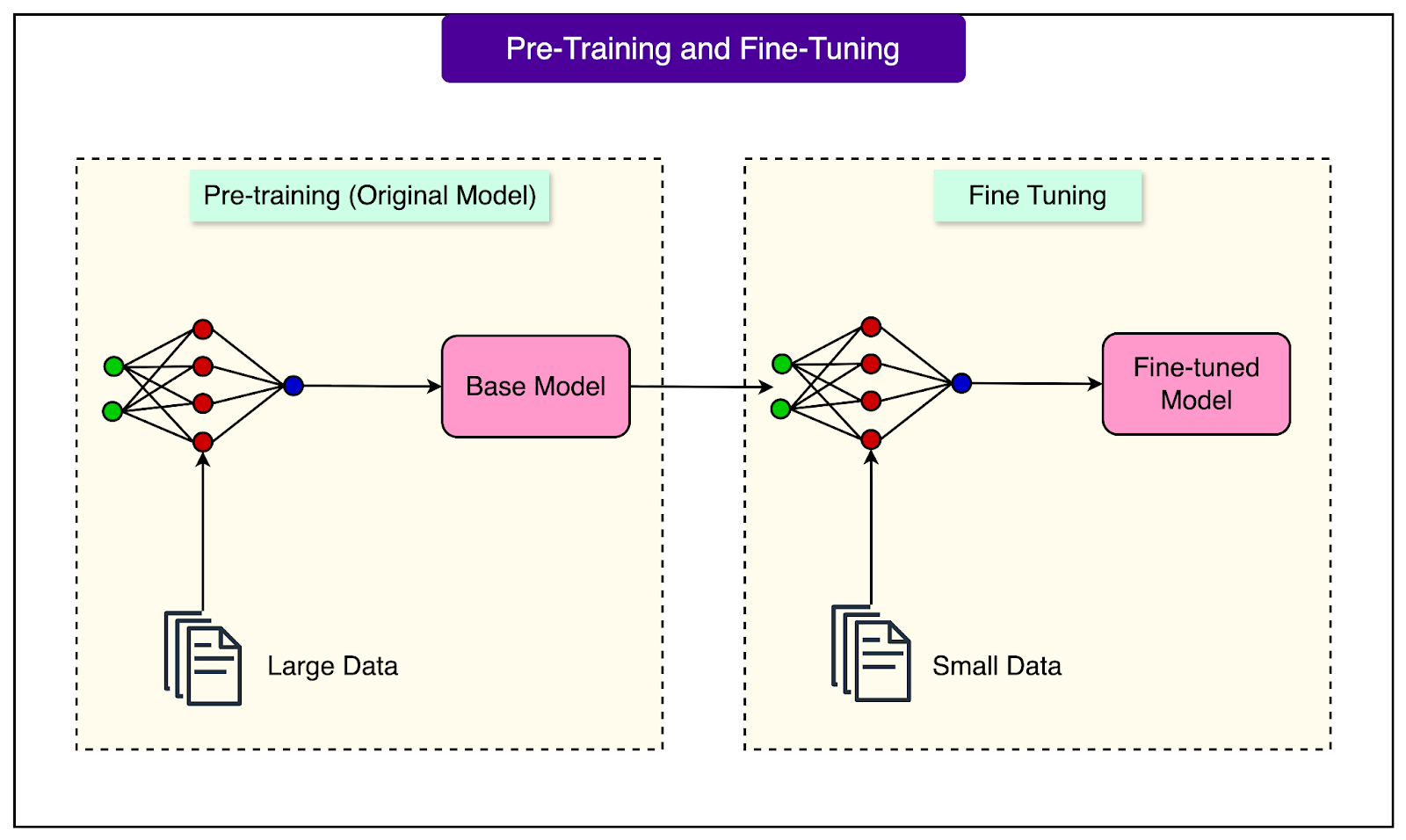
Let's look at a concrete example.
Consider how the model interprets the word "function" before and after fine-tuning for coding tasks. Initially, when the model sees "function," its weights might strongly connect to various meanings:
Mathematical functions
Biological functions,
Social events
Programming functions.
In simplified terms, the weights connecting "function" to what comes next might look like this: the weight for predicting "of" next could be 2.1 (strong connection, as in "function of the liver"), while the weight for predicting an opening parenthesis "(" might be just 0.9 (weak connection), and the weight for a curly brace "{" might be even lower at 0.3.
However, after fine-tuning the model on thousands of programming examples, these specific weights shift dramatically.
The weight connecting "function" to "of" might decrease from 2.1 to 0.7
On the other hand, the weight for "(" can increase from 0.9 to 3.2
The weight for "{" jumps from 0.3 to 2.8.
The fine-tuned model has now learned that in coding contexts, "function" is almost always followed by programming syntax rather than general English words. These aren't random changes, but systematic adjustments based on patterns in the training data. Every time the model saw "function" followed by parentheses in the training data, it slightly increased that weight. After thousands of examples, these tiny adjustments accumulate into significant behavioral changes.
But why does the model make tiny adjustments? This is where the concept of learning rate becomes important to understand.
The learning rate controls how much the weights change with each training example. Think of it like tuning a guitar that needs precision.
Turn the tuning peg too much, and you'll overshoot the correct pitch or even break the string.
Turn it too little, and you'll never reach the right note.
In fine-tuning, we use very small learning rates, typically making changes of just 0.01% to 0.1% per adjustment. This ensures the model doesn't lose its original capabilities while learning new ones.
This careful approach prevents catastrophic forgetting, where the model loses its original knowledge. For example, imagine someone fluent in English learning Spanish. If they immerse themselves too intensely and stop using English entirely, they might start forgetting English words. Similarly, if we adjust weights too aggressively during fine-tuning, the model might become excellent at coding tasks but forget that "function" can also mean a social gathering. The small learning rate ensures the model adds new capabilities while preserving existing knowledge.
Types of Fine-Tuning
Fine-tuning isn't a single technique but rather a collection of approaches, each designed to achieve different goals. While they all involve adjusting model weights to improve performance, they differ in what kind of improvement they target. Understanding these distinctions helps you choose the right approach for your specific needs.
These approaches often work together. For example, ChatGPT uses instruction fine-tuning to understand commands, then RLHF to align its responses with human preferences. On the other hand, a medical chatbot might combine all three: domain adaptation for medical knowledge, instruction fine-tuning to handle patient queries, and RLHF to ensure appropriately cautious and helpful responses.
Each type of fine-tuning contributes to transforming a general text predictor into a specialized, useful tool. Let’s look at each in more detail.
Instruction Fine-Tuning
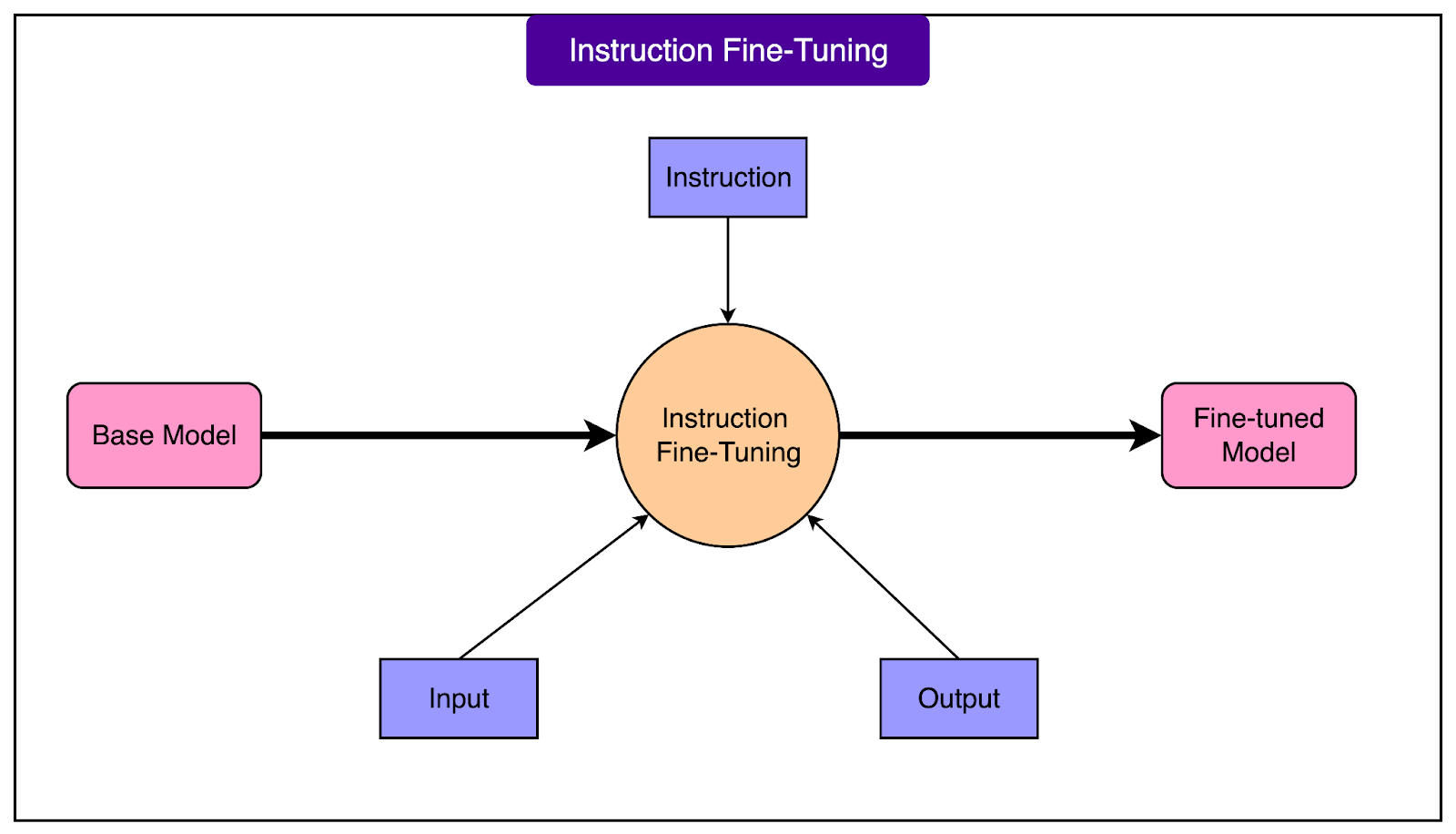
Instruction Fine-Tuning addresses a fundamental limitation of base models: they're trained to predict text, not to be helpful assistants.
A base model is like a parrot that can mimic speech patterns perfectly, but doesn't understand that it should actually help when asked a question. When you type "Write a poem about summer," a base model might continue with "was the assignment Mrs. Johnson gave to her third-grade class" because it's completing the text pattern, not following the instruction.
Instruction fine-tuning teaches the model to recognize commands and respond appropriately. After this training, the same prompt produces an actual poem about summer. The model learns through thousands of instruction-response pairs that when someone gives a directive, they want action, not text continuation.
See the diagram below:
RLHF
RLHF (Reinforcement Learning from Human Feedback) takes this further by teaching models what humans actually prefer, not just what's in the training data.
Think of a comedian refining their act based on audience reactions. They tell jokes, observe what gets laughs, and adjust their routine accordingly.
RLHF works through three stages.
First, the model generates multiple responses to the same prompt.
Then, humans rank these responses from best to worst.
Finally, this feedback trains a reward model that guides the language model toward generating responses similar to those humans preferred.
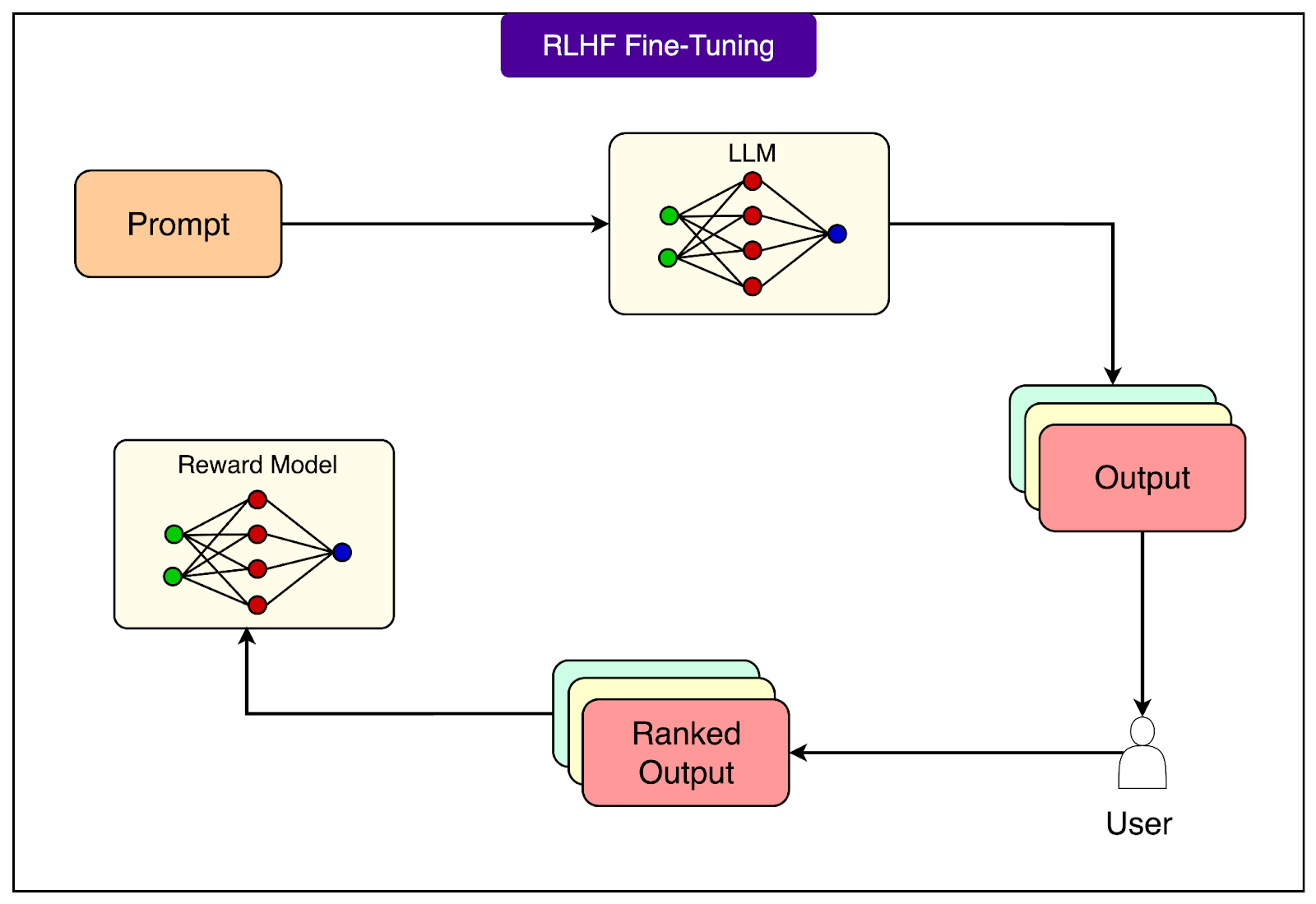
This process captures nuanced preferences that are hard to specify in training data, like being helpful without being verbose, or being honest about uncertainty rather than confidently wrong.
Domain-Adaptation
Domain Adaptation specializes the models for specific fields where generic knowledge isn't sufficient. For example:
A model fine-tuned for medical use learns that "discharge" usually means releasing a patient from the hospital, not electrical discharge.
Legal fine-tuning teaches that "motion" refers to formal court requests, not physical movement.
Coding-specialized models learn to prioritize syntax patterns and programming logic over natural language.
This type of fine-tuning is about shifting the entire context of understanding.
LoRA and Its Variants
Traditional fine-tuning faces a fundamental problem: it's prohibitively expensive for most organizations.
Fine-tuning a 70-billion-parameter model requires multiple high-end GPUs costing tens of thousands of dollars. The memory requirements alone can exceed 500GB, and training can cost thousands of dollars in cloud computing fees. This created a situation where only well-funded companies could customize large language models, leaving smaller organizations and researchers behind.
LoRA (Low-Rank Adaptation) changed this landscape dramatically.
Instead of updating all billions of parameters in a model, LoRA adds small, trainable components that modify the model's behavior. Imagine a massive general library with 10 million books. We want to customize this library for medical students. Traditional fine-tuning would require editing every single book, an enormous undertaking. That would take forever and cost a fortune. However, LoRA is like adding sticky notes to the most important pages. These notes guide how you read the books in a medical-specialized approach without rewriting them. The original books remain unchanged, but your reading experience is transformed by these strategic additions.
The technical innovation behind LoRA is recognizing that most fine-tuning changes follow patterns.
Rather than randomly adjusting millions of weights, the changes often have a simple underlying structure. LoRA captures this structure using two small matrices that work together.
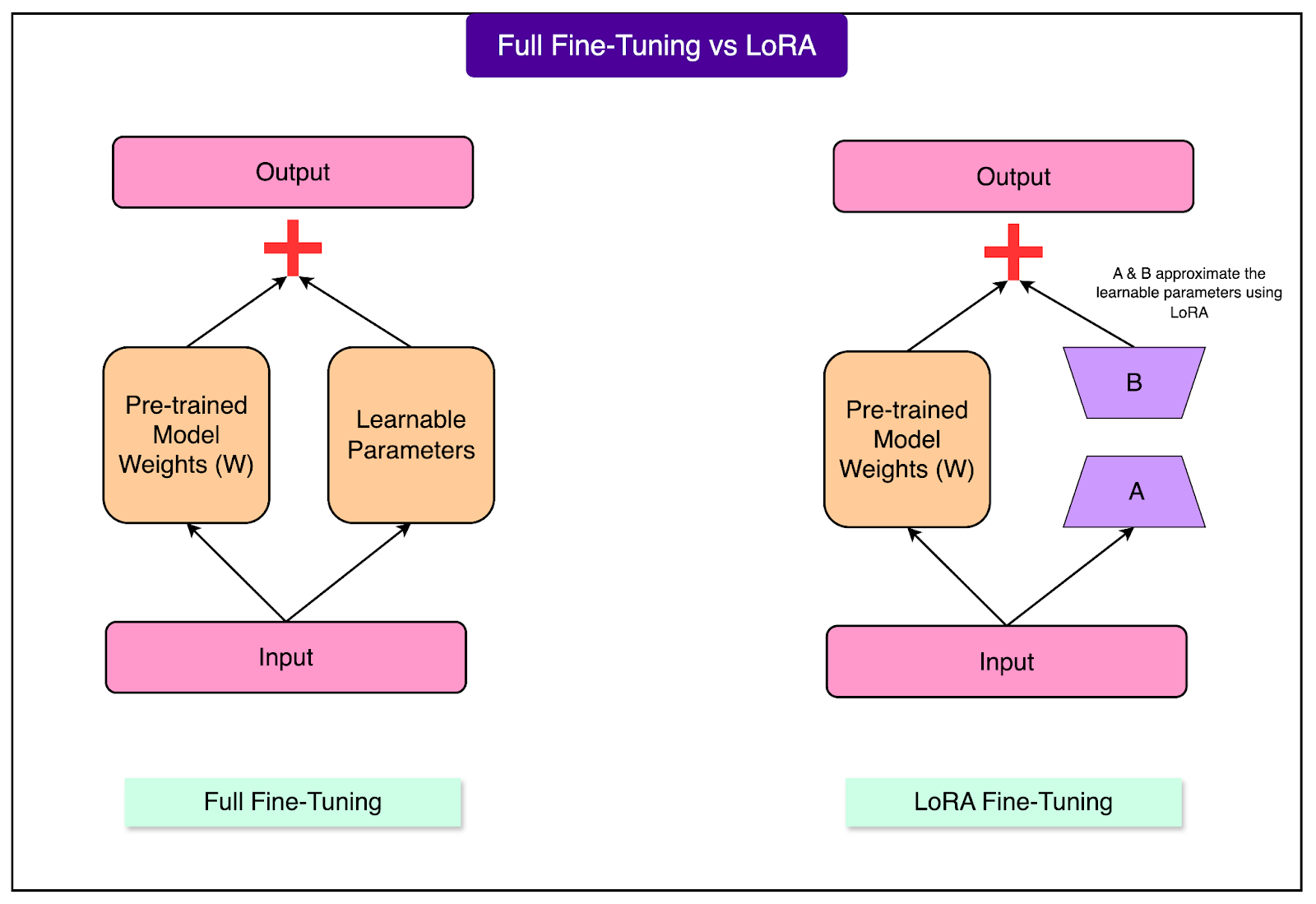
As a simple example, think of it like describing the difference between British and American English. We could list every single word that differs, creating a massive dictionary, or we could write a few simple rules like "remove 'u' from words ending in 'our'" and "change 'ise' to 'ize'." LoRA finds these "rules" for adapting model behavior.
The efficiency gains are staggering. Where traditional fine-tuning might update 70 billion parameters, LoRA might update only 50 million, less than 0.1% of the total. Despite this massive reduction, the performance often matches or comes very close to full fine-tuning. Memory requirements drop from 500GB to perhaps 20GB, training time reduces from weeks to hours, and costs plummet from thousands to tens of dollars.
QLoRA
QLoRA pushes efficiency even further by combining LoRA with quantization.
Quantization compresses the model by reducing the precision of numbers. Normal weights might be stored as 32-bit numbers that can represent values like 0.123456789, but quantization reduces these to 4-bit numbers that might only represent 0.12. It's like compressing a high-resolution photo to a smaller file size. We lose some detail but retain the essential information.
QLoRA keeps the main model compressed to 4-bit precision while maintaining the LoRA adapters at full precision. The model temporarily decompresses relevant sections when needed, adds the high-precision LoRA adjustments, and produces output. This is like having a ZIP file of that massive library, unzipping just the book you need, adding your sticky notes, and then compressing it back.
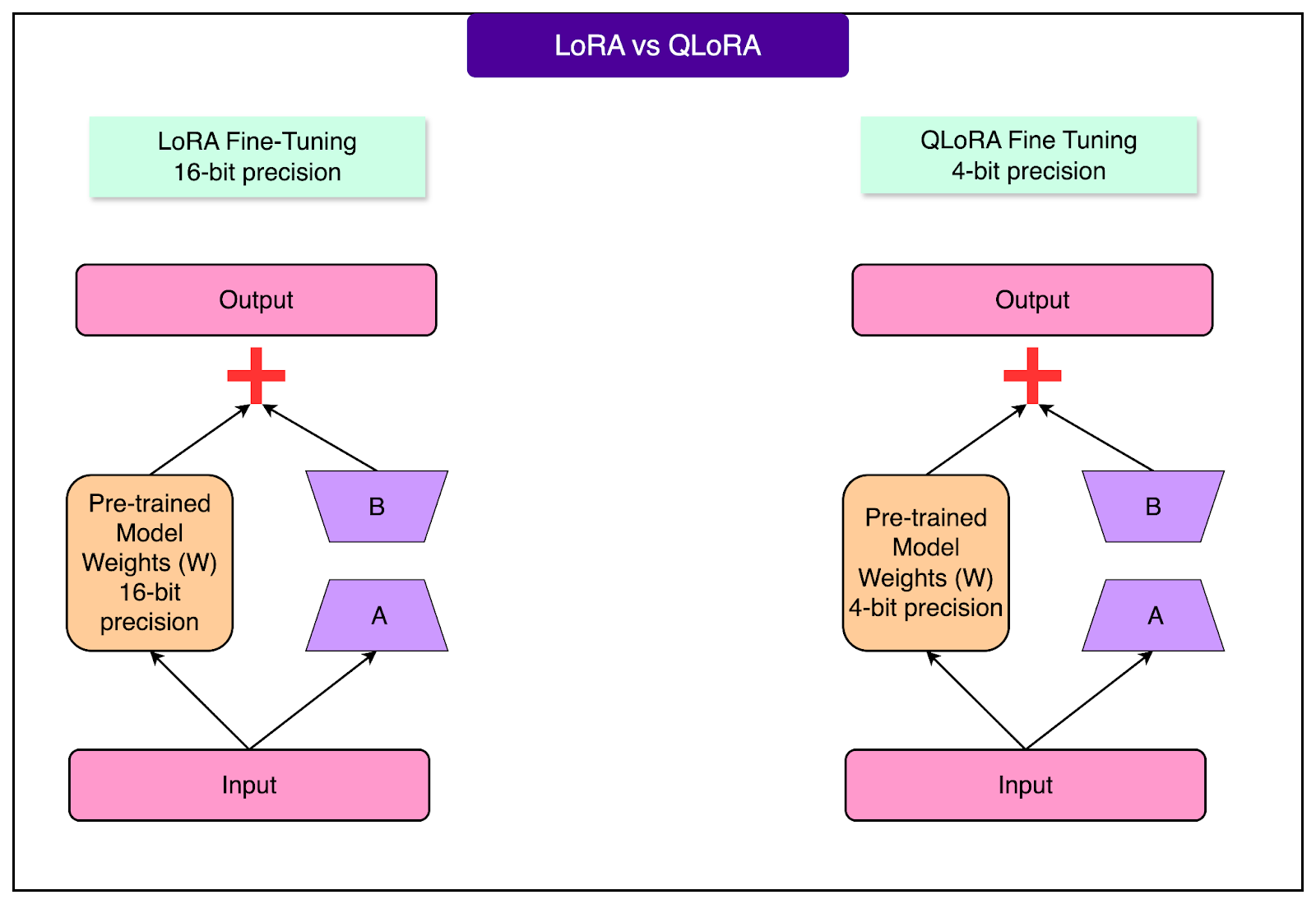
The practical impact of this cannot be overstated.
Just for reference, a model that may require a $30,000 server with specialized AI accelerators can now be fine-tuned on a $2,000 gaming computer with a consumer graphics card. QLoRA can enable fine-tuning a 65-billion-parameter model on a single GPU with 24GB of memory, hardware that many enthusiasts already own.
This isn't just about cost savings, but also about accessibility. Researchers at small universities, developers at startups, and even hobbyists can now experiment with customizing large language models.
DoRA
The innovation continues with newer variants like DoRA.
DoRA (Weight-Decomposed Low-Rank Adaptation) is a newer variant that came from an observation about how LoRA changes weights.
Imagine we’re adjusting the trajectory of a spacecraft. We could change both its speed and direction at once, or we could separate these concerns: first adjust the direction it's pointing, then adjust how fast it's going.
DoRA takes this second approach. In regular LoRA, when we adjust weights, we're changing both their "direction" (what patterns they recognize) and "magnitude" (how strongly they respond). DoRA separates these two types of changes. It uses LoRA-style updates for direction changes but handles magnitude changes differently.
This separation turns out to be more efficient. DoRA often achieves better results than LoRA with the same number of parameters, or similar results with fewer parameters.
The Fine-Tuning Process
Successfully fine-tuning a model requires careful planning and execution across several stages. Understanding this process helps you avoid common pitfalls and make informed decisions that align with your goals and constraints.
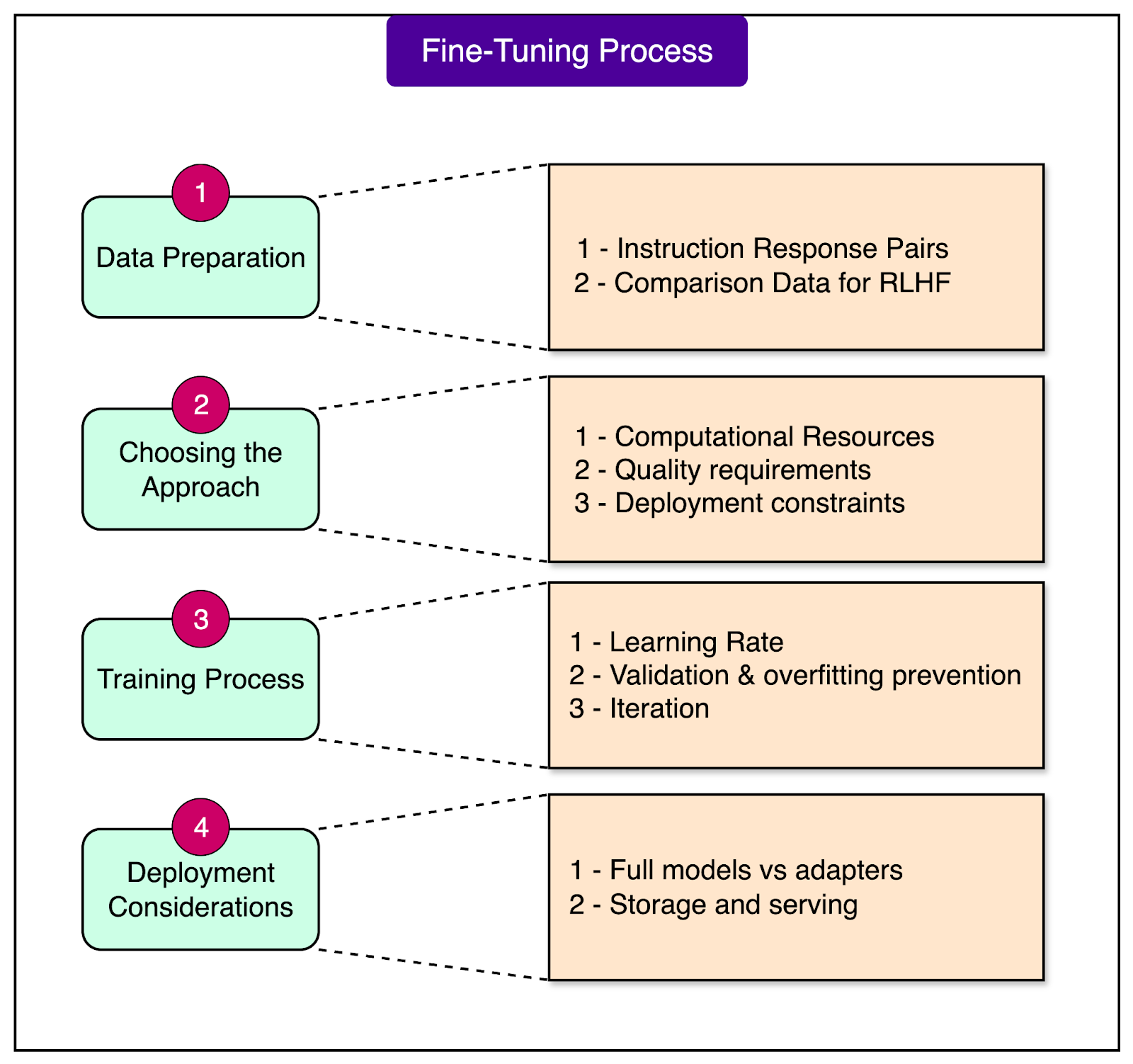
1 - Data Preparation
Data Preparation is the foundation of successful fine-tuning, where quality matters far more than quantity.
A carefully curated dataset of 1,000 high-quality examples often outperforms 100,000 noisy ones. For instruction fine-tuning, we need instruction-response pairs that clearly demonstrate the behavior you want. Each example should show the model exactly how to respond to specific types of requests. If we’re building a customer service bot, the data might include real customer questions paired with ideal agent responses.
For RLHF, you need comparison data where multiple responses to the same prompt are ranked by quality. This requires human reviewers to evaluate responses, making it more labor-intensive but ultimately producing models that better align with human preferences.
2 - Choosing the Approach
Choosing Your Approach depends on three key factors.
First, assess your computational resources. If we have a single consumer GPU with 24GB of memory, QLoRA is likely the only option for larger models. With access to multiple high-end GPUs, you might consider full fine-tuning for maximum quality.
Second, evaluate the quality requirements. Most applications work wonderfully with LoRA, achieving 95% of full fine-tuning performance, but mission-critical applications might justify the extra cost of full fine-tuning.
Third, consider deployment constraints. If we need to serve multiple model variants to different customers, LoRA's adapter approach allows you to maintain one base model with swappable specializations. If we’re deploying a single model with ample storage, full fine-tuning might be simpler to implement.
3 - The Train Process
The Training Process follows established principles regardless of your approach.
Learning rate scheduling is crucial. We typically start with a warmup period where the learning rate gradually increases, maintain it at an optimal level, then slowly decrease it toward the end of training. This helps the model settle into optimal configurations.
Validation is essential to prevent overfitting, where the model memorizes training data rather than learning generalizable patterns. Always reserve a portion of your data that the model never sees during training, using it to evaluate whether improvements on training data translate to real-world performance. The process is inherently iterative. The first attempt rarely produces the best results. Plan to experiment with different hyperparameters, data mixtures, and training durations.
4 - Deployment Considerations
Deployment Considerations vary significantly based on your fine-tuning approach.
Full fine-tuning produces a completely new model, typically 10-30GB for modern LLMs, which needs its own storage and memory allocation. This is straightforward but resource-intensive if you need multiple variants.
LoRA produces small adapter files, usually 50-200MB, that modify the base model's behavior. This enables hot-swapping, where you can switch between different specializations in seconds without reloading the entire model. A single server can serve a medical adapter for one request, then switch to a legal adapter for the next, all using the same base model in memory. This flexibility makes LoRA particularly attractive for multi-tenant applications or services that need to adapt to different contexts dynamically.
Conclusion
Fine-tuning has transformed large language models from impressive but generic tools into specialized assistants that can serve specific needs. We've explored how this process works, from adjusting billions of weights through careful training to breakthrough techniques like LoRA that have made customization accessible to organizations of all sizes. The ability to adapt powerful foundation models for specialized tasks, whether medical diagnosis, legal analysis, or customer service, represents a fundamental shift in how we deploy AI.
The democratization of fine-tuning through efficient methods means that innovation is no longer limited to tech giants with massive budgets. Small teams can now create specialized AI tools that rival those of major corporations. As techniques continue to improve and costs decrease further, we'll likely see an explosion of specialized AI applications across every industry.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Great job. Congrats.