
How Grab Built a Vision LLM to Scan Images

Kubernetes Quick-Start Guide (Sponsored)

Cut through the noise with this engineer-friendly guide to Kubernetes observability. Save this reference for fast-track access to essential kubectl commands and critical metrics, from disk I/O and network latency to real-time cluster events. Perfect for scaling, debugging, and tuning your workloads without sifting through endless docs.
Digital services require accurate extraction of information from user-submitted documents such as identification cards, driver’s licenses, and vehicle registration certificates. This process is essential for electronic know-your-customer (eKYC) verification. However, the diversity of languages and document formats across the region makes this task particularly challenging.
Grab Engineering Team faced significant obstacles with traditional Optical Character Recognition (OCR) systems, which struggled to handle the variety of document templates. While powerful proprietary Large Language Models (LLMs) were available, they often failed to adequately understand Southeast Asian languages, produced errors and hallucinations, and suffered from high latency. Open-source Vision LLMs offered better efficiency but lacked the accuracy required for production deployment.
This situation prompted Grab to fine-tune existing models and eventually build a lightweight, specialized Vision LLM from the ground up. In this article, we will look at the complete architecture, the technical decisions made, and the results achieved.
Disclaimer: This post is based on publicly shared details from the Grab Engineering Team. Please comment if you notice any inaccuracies.
Understanding Vision LLMs
Before diving into the solution, it helps to understand what a Vision LLM is and how it differs from traditional text-based language models.
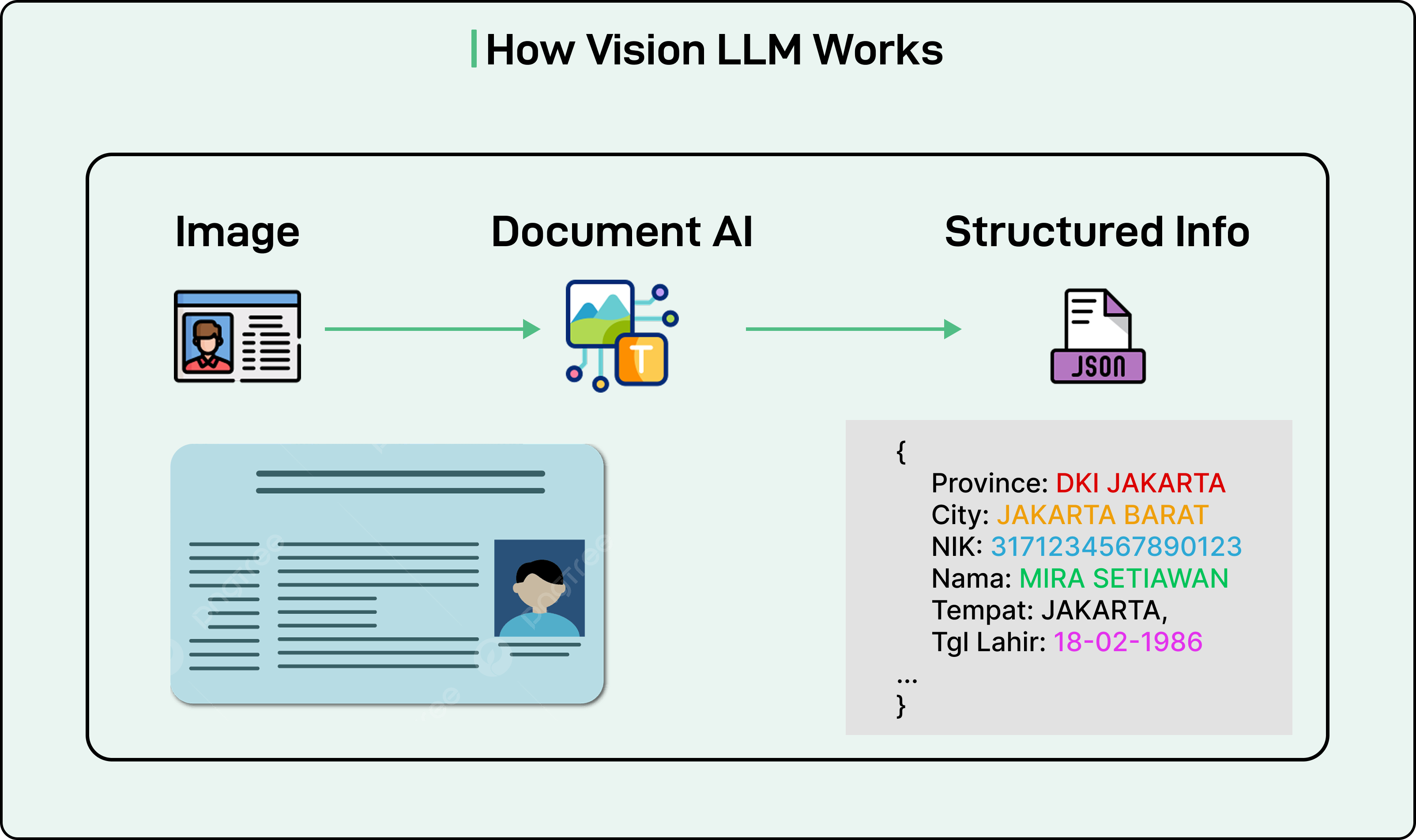
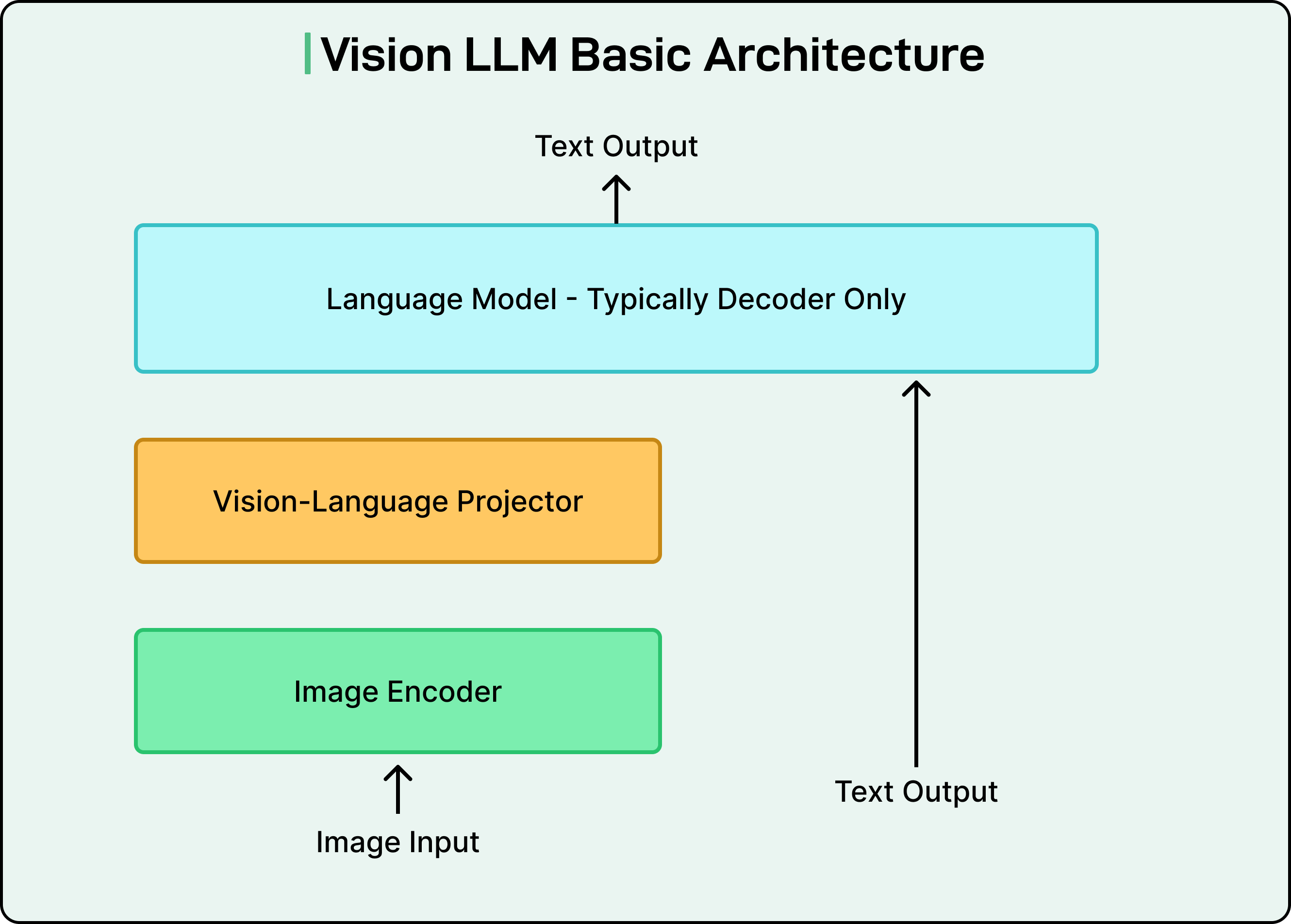
A standard LLM processes text inputs and generates text outputs. A Vision LLM extends this capability by enabling the model to understand and process images. The architecture consists of three essential components working together:
The first component is the image encoder. This module processes an image and converts it into a numerical format that computers can work with. Think of it as translating visual information into a structured representation of numbers and vectors.
The second component is the vision-language projector. This acts as a bridge between the image encoder and the language model. It transforms the numerical representation of the image into a format that the language model can interpret and use alongside text inputs.
The third component is the language model itself. This is the familiar text-processing model that takes both the transformed image information and any text instructions to generate a final text output. In the case of document processing, this output would be the extracted text and structured information from the document.
See the diagram below:
Build product instead of babysitting prod (Sponsored)

Engineering teams at Coinbase, MSCI, and Zscaler have at least one thing in common: they use Resolve AI’s AI SRE to make MTTR 5x faster and increase dev productivity by up to 75%.
When it comes to production issues, the numbers hurt: 54% of significant outages exceed $100,000 lost. Downtime cost the Global 2000 ~$400 billion annually.
It’s why eng teams leverage our AI SRE to correlate code, infrastructure, and telemetry and provide real-time root cause analysis, prescriptive remediation, and continuous learning.
Time to try an AI SRE? This guide covers:
The ROI of an AI SRE
Whether you should build or buy
How to assess AI SRE solutions
Selecting the Base Model
Grab evaluated several open-source models capable of performing OCR and Key Information Extraction (KIE). The options included Qwen2VL, miniCPM, Llama3.2 Vision, Pixtral 12B, GOT-OCR2.0, and NVLM 1.0.
After thorough evaluation, Grab selected Qwen2-VL 2B as the base multimodal LLM. This decision was driven by several critical factors:
First, the model size was appropriate. With 2 billion parameters, it was small enough to allow full fine-tuning on GPUs with limited VRAM resources. Larger models would have required more expensive infrastructure and longer training times.
Second, the model offered good Southeast Asian language support. The tokenizer showed efficiency for languages like Thai and Vietnamese, indicating decent native vocabulary coverage. A tokenizer is the component that breaks text into smaller units (tokens) that the model can process. Efficient tokenization means the model can represent these languages without wasting capacity.
Third, and perhaps most importantly, Qwen2-VL supports dynamic resolution. Unlike models that require fixed-size image inputs, this model can process images in their native resolution. This capability is critical for OCR tasks because resizing or cropping images can distort text characters, leading to recognition errors. Preserving the original resolution maintains text integrity and improves accuracy.
Initial benchmarking of Qwen2VL and miniCPM on Grab’s dataset revealed low accuracy, primarily due to the limited coverage of Southeast Asian languages. This finding motivated the team to pursue fine-tuning to improve OCR and KIE accuracy.
However, training LLMs is both data-intensive and GPU resource-intensive, which brings up two important questions: how to use open-source and internal data effectively, and how to customize the model to reduce latency while maintaining high accuracy.
Training Dataset Generation
Grab developed two approaches to generate training data for the model:
1 - Synthetic OCR Dataset
The first approach involved creating synthetic training data. Grab extracted Southeast Asian language text content from Common Crawl, a large online text corpus that contains data from across the internet. Using an in-house synthetic data pipeline, the team generated text images by rendering this content in various fonts, backgrounds, and augmentations.
The resulting dataset included text in Bahasa Indonesia, Thai, Vietnamese, and English. Each image contained a paragraph of random sentences extracted from the corpus. This synthetic approach offered several advantages. It allowed controlled generation of training examples, enabled the creation of unlimited variations, and ensured coverage of different visual styles and document conditions.
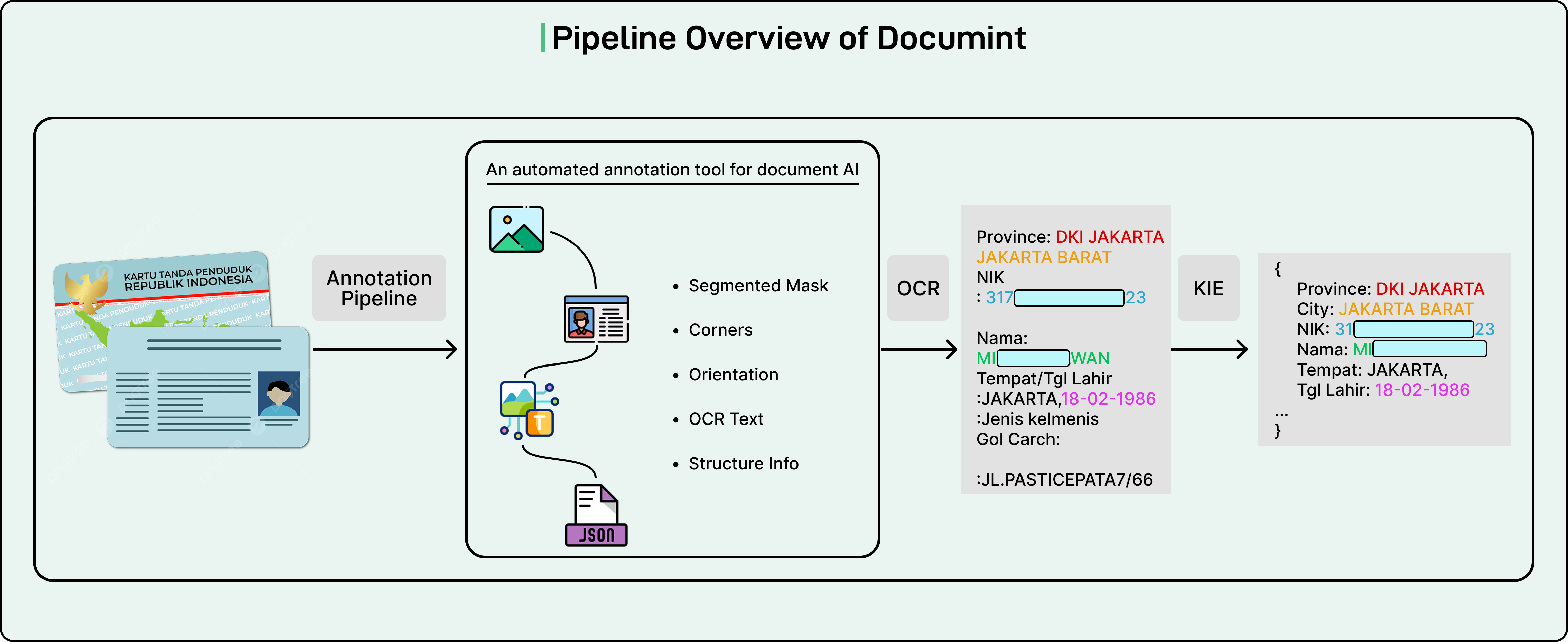
2 - Documint: The Auto-Labelling Framework
The second approach leveraged real documents collected by Grab. Experiments showed that applying document detection and orientation correction significantly improved OCR and information extraction.
To generate a preprocessing dataset, Grab built Documint, an internal platform that creates an auto-labelling and preprocessing framework for document understanding.
Documint prepares high-quality, labelled datasets through various submodules that execute the full OCR and KIE task. The team used this pipeline with a large volume of Grab-collected cards and documents to extract training labels. Human reviewers then refined the data to achieve high label accuracy.
Documint consists of four main modules:
The detection module identifies the document region from a full picture.
The orientation module determines the correction angle needed, such as 180 degrees if a document is upside down.
The OCR module extracts text values in an unstructured format.
Finally, the KIE module converts the unstructured text into structured JSON values.
The Experimentation Journey
Grab conducted the model development in three distinct phases, each building on the lessons learned from the previous phase:
Phase 1: LoRA Fine-Tuning
The first attempt at fine-tuning involved a technique called Low-Rank Adaptation, or LoRA.
This method is efficient because it updates only a small portion of the model’s parameters rather than retraining the entire model. Specifically, LoRA adds small trainable matrices to the model while keeping most of the original weights frozen. This approach minimizes computational resource requirements and reduces training time.
Grab trained the model on curated document data that included various document templates in multiple languages. The performance showed promise for documents with Latin scripts. The LoRA fine-tuned Qwen2VL-2B achieved high field-level accuracy for Indonesian documents.
However, the fine-tuned model struggled with two categories of documents:
First, it had difficulty with documents containing non-Latin scripts, such as Thai and Vietnamese.
Second, it performed poorly on unstructured layouts with small, dense text.
The experiments revealed a key limitation. While open-source Vision LLMs often have extensive multilingual text corpus coverage for the language model decoder’s pre-training, they lack visual examples of text in Southeast Asian languages during vision encoder training. The language model might understand Thai text, but the vision encoder had never learned to recognize what Thai characters look like in images. This insight drove the decision to pursue full parameter fine-tuning.
Phase 2: Full Fine-Tuning
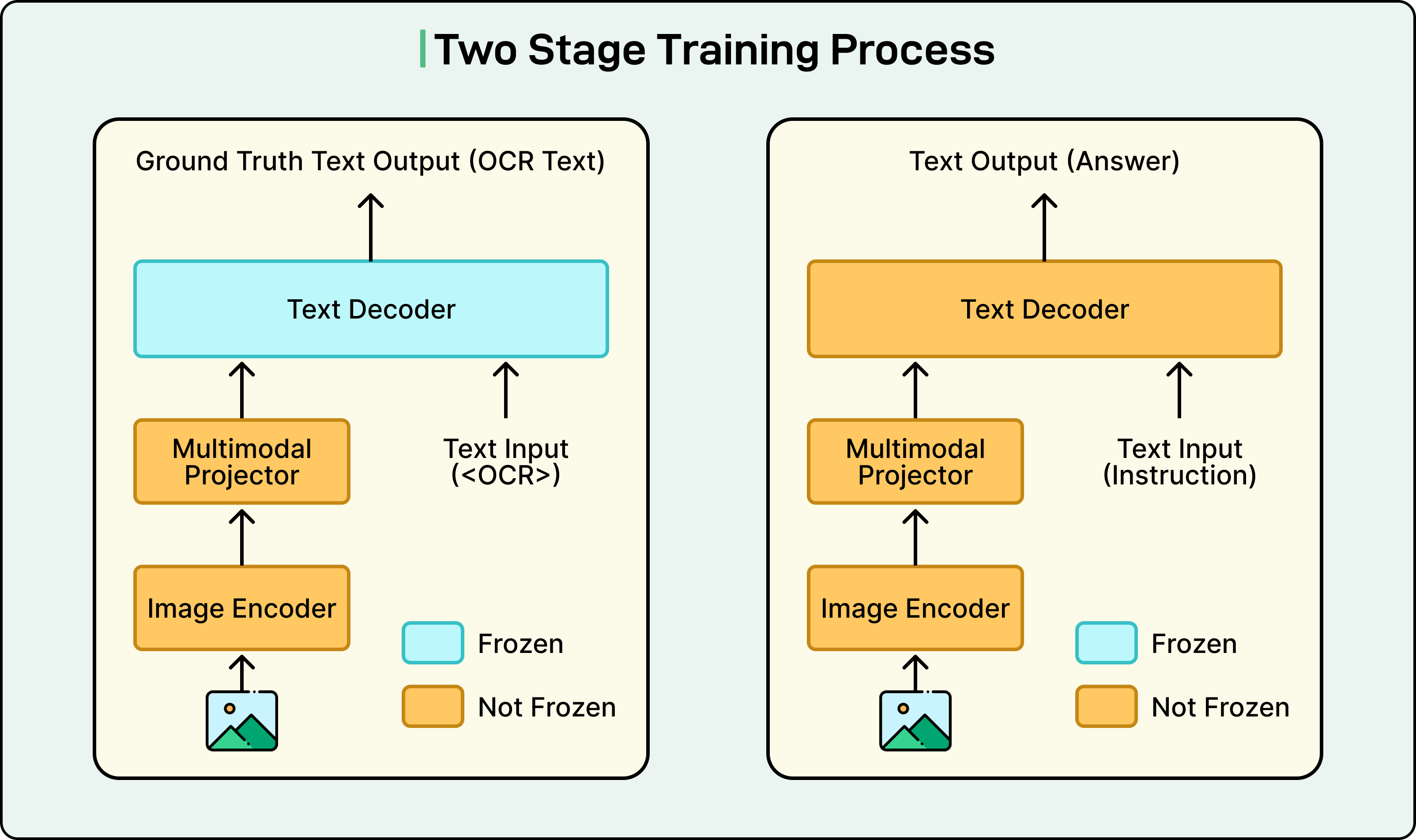
Drawing from the Large Language and Vision Assistant (LLAVA) methodology, Grab implemented a two-stage training approach:
In Stage 1, called continual pre-training, the team trained only the vision components of the model using synthetic OCR datasets created for Bahasa Indonesia, Thai, Vietnamese, and English. This stage helped the model learn the unique visual patterns of Southeast Asian scripts. During this stage, the language model remained frozen, meaning its weights were not updated.
In Stage 2, called full-parameter fine-tuning, Grab fine-tuned the entire model. This included the vision encoder, the projector, and the language model. The team used task-specific document data for this training. All components of the model were now trainable and could be optimized together for the document extraction task.
The results were significant. For example, the Thai document accuracy increased by 70 percentage points from the baseline. Vietnamese document accuracy rose by 40 percentage points from the baseline. Indonesian documents saw a 15 percentage point improvement, and Philippine documents improved by 6 percentage points.
The fully fine-tuned Qwen2-VL 2B model delivered substantial improvements, especially on documents that the LoRA model had struggled with.
Phase 3: Building a 1B Model from Scratch
While the 2B model succeeded, full fine-tuning pushed the limits of available GPUs.
To optimize resource usage and create a model perfectly tailored to their needs, Grab decided to build a lightweight Vision LLM with approximately 1 billion parameters from scratch.
The strategy involved combining the best components from different models. Grab took the powerful vision encoder from the larger Qwen2-VL 2B model, which had proven effective at understanding document images. The team paired it with the compact and efficient language decoder from the Qwen2.5 0.5B model. They connected these components with an adjusted projector layer to ensure seamless communication between the vision encoder and language decoder.
This combination created a custom Vision LLM with approximately 1 billion parameters, optimized for both training and deployment.
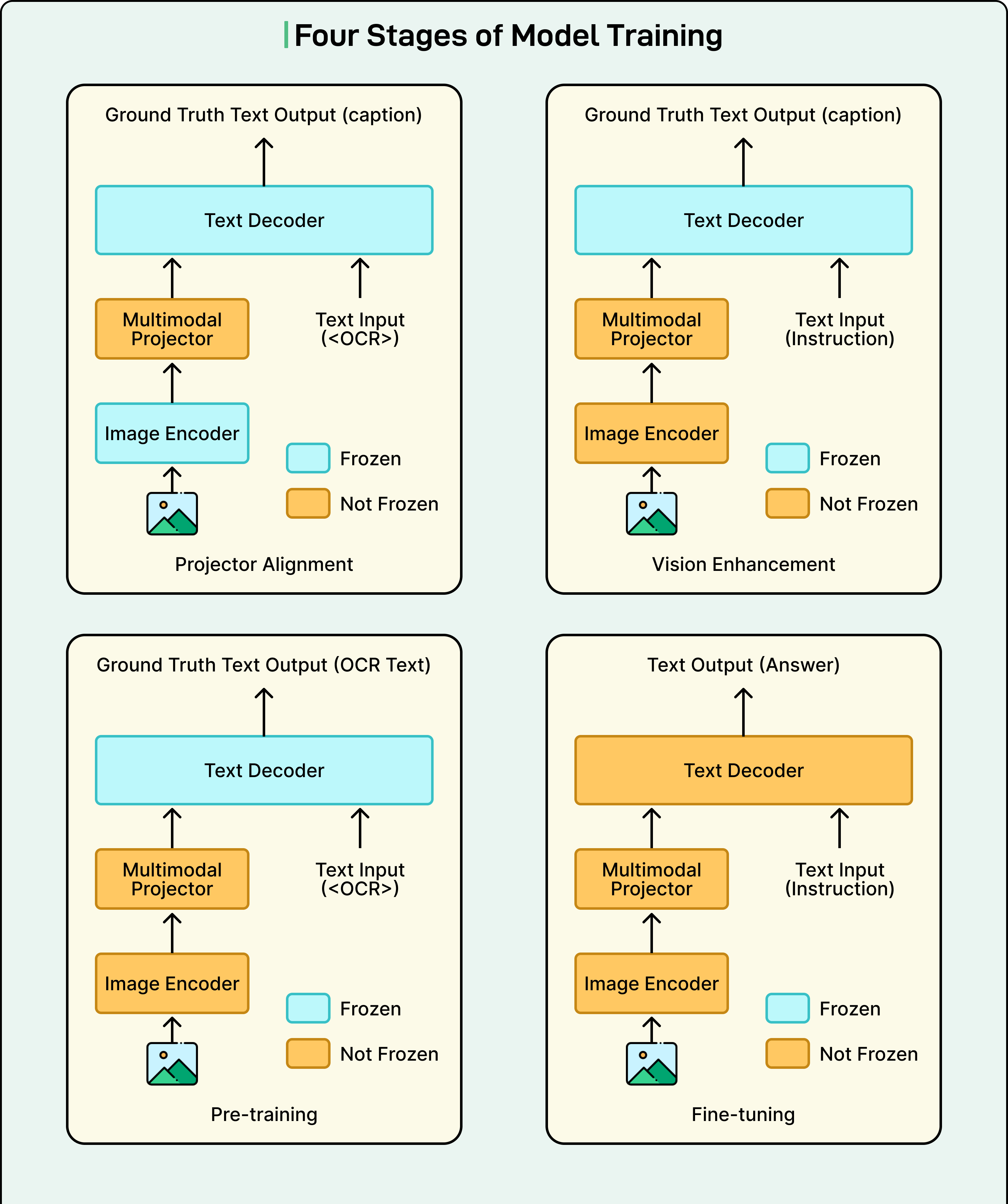
Four-Stage Training Process
Grab trained this new model using a comprehensive four-stage process:
Stage 1 focused on projector alignment. The first step was to train the new projector layer to ensure the vision encoder and language decoder could communicate effectively. Without proper alignment, the language model would not be able to interpret the vision encoder’s outputs correctly.
Stage 2 involved vision tower enhancement. The team trained the vision encoder on a vast and diverse set of public multimodal datasets. These datasets covered tasks like visual question answering, general OCR, and image captioning. This stage improved the model’s foundational visual understanding across various scenarios.
Stage 3 centered on language-specific visual training. Grab trained the model on two types of synthetic OCR data specific to Southeast Asian languages. This stage proved critical. Without it, performance on non-Latin documents dropped by as much as 10 percentage points. This stage ensured the vision encoder could recognize the specific visual characteristics of Thai, Vietnamese, and other regional scripts.
Stage 4 completed the process with task-centric fine-tuning. The team performed full-parameter fine-tuning on the custom 1B model using the curated document dataset. This final stage optimized the entire system for the specific production use case of document information extraction.
Results and Performance
The final 1B model achieved remarkable results across two key metrics: accuracy and latency.
For accuracy, the model performed comparably to the larger 2B model, staying within a 3 percentage point accuracy gap across most document types. The model also maintained strong generalization when trained on quality-augmented datasets, meaning it could handle variations it had not seen during training.
For latency, the results were even more impressive. The 1B model achieved 48 percent faster processing at the P50 latency (median response time), 56 percent faster at P90 latency (90th percentile), and 56 percent faster at P99 latency (99th percentile, representing worst-case scenarios).
These latency improvements are particularly important. Grab identified that one of the biggest weaknesses of external APIs like ChatGPT or Gemini was the P99 latency, which can easily be 3 to 4 times higher than the P50 latency. This variability would not be acceptable for large-scale production rollouts where consistent performance is essential.
Key Technical Insights
The project yielded several important insights that can guide similar efforts.
Full parameter fine-tuning proved superior to LoRA for specialized, non-Latin script domains. While LoRA is efficient, it cannot match the performance gains of updating all model parameters when dealing with significantly different data distributions.
Lightweight models can be highly effective. A smaller model of approximately 1 billion parameters, built from scratch and trained comprehensively, can achieve near state-of-the-art results. This validates the approach of custom architecture over simply using the largest available model.
The choice of base model matters significantly. Starting with a model that has native support for target languages is crucial for success. Trying to force a model to learn languages it was not designed for leads to suboptimal results.
Data quality plays a critical role. Meticulous dataset preprocessing and augmentation are as important as model architecture in achieving consistent and accurate results. The effort invested in building Documint and creating synthetic datasets directly contributed to the final model’s success.
Finally, native resolution support is transformative for OCR tasks. A model that can handle dynamic image resolutions preserves text integrity and dramatically improves OCR capabilities. This feature prevents the distortion that occurs when images are resized to fit fixed input dimensions.
Conclusion
Grab’s journey of building a Vision LLM demonstrates that specialized Vision LLMs can effectively replace traditional OCR pipelines with a single, unified, highly accurate model. This opens new possibilities for document processing at scale.
The project shows that with strategic training approaches, high-quality data preparation, and thoughtful model architecture decisions, smaller specialized models can outperform larger general-purpose alternatives. The resulting system processes documents faster and more accurately than previous solutions while using fewer computational resources.
Grab continues to enhance these capabilities. The team is developing Chain of Thought-based OCR and KIE models to strengthen generalization and tackle even more diverse document scenarios. They are also extending support to all Grab markets, bringing advanced document processing to Myanmar, Cambodia, and beyond.
References: