
How Grab Built an AI Foundation Model To Understand Customers Better

Break production less with Seer Code Review (Sponsored)

Sentry’s AI Code Review uses Sentry’s deep context to catch bugs you’ll actually care about before you ship them – without all the noise.
In the last month it has caught more than 30,000 bugs that would have impacted users, saving developers time and reducing rollbacks. Plus it’s now 50% faster and offers agent prompts that help you fix what’s wrong fast.
Ship confidently with Sentry context built into every review.
Disclaimer: The details in this post have been derived from the details shared online by the Grab Engineering Team. All credit for the technical details goes to the Grab Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Grab operates one of the most complex and data-rich platforms in Southeast Asia. Over the years, it has expanded far beyond ride-hailing into multiple verticals, including food delivery, groceries, mobility, and financial services. This expansion has generated a massive amount of user interaction data that reflects how millions of people engage with the platform every day.
Until recently, personalizing the user experience relied heavily on manually engineered features. Teams built features such as order frequency, ride history, or spending patterns for specific products and services. These features were often siloed, difficult to maintain, and expensive to scale. More importantly, they were not very good at capturing the evolving, time-based nature of user behavior.
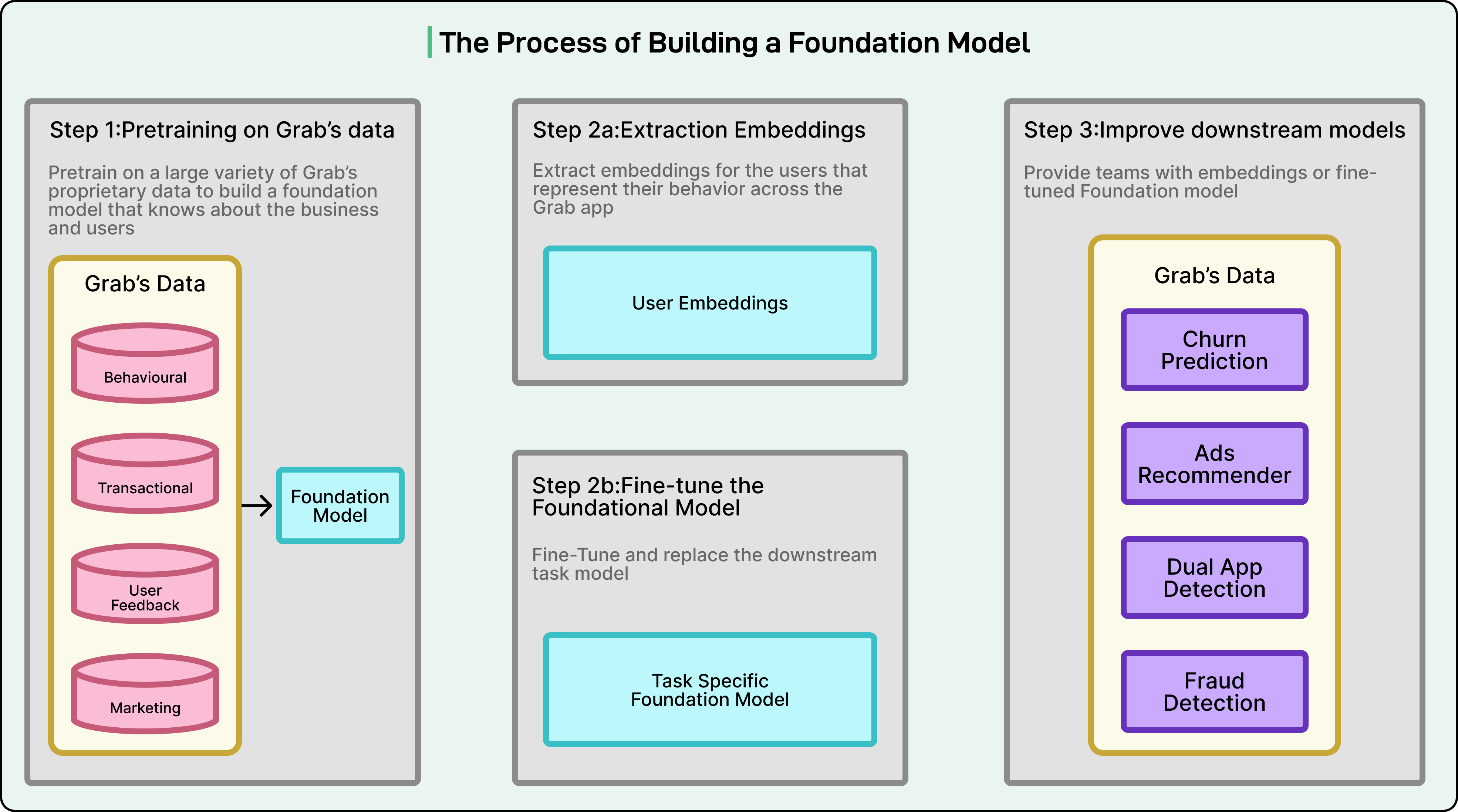
To address these limitations, the Grab Engineering Team has adopted a foundation model approach. Instead of relying on task-specific features, this approach learns directly from two core data sources: tabular data, such as user profiles and transaction history, and sequential data, such as clickstream interactions. By learning patterns directly from these signals, the model generates shared embeddings for users, merchants, and drivers. These embeddings provide a single, generalized understanding of how people use the app.
This shift allows Grab to move away from fragmented personalization pipelines and toward a unified system that powers multiple downstream applications, including recommendations, fraud detection, churn prediction, and ad optimization. In this article, we look at how Grab developed this foundational model and the challenges it faced.
Data Foundation
The heart of Grab’s foundation model lies in its ability to work with a wide variety of data.
Unlike platforms that focus on a single use case, Grab operates a superapp that brings together food delivery, mobility, courier services, and financial products. Each of these services generates different kinds of signals about user activity. To build a single, reliable foundation model, the Grab Engineering Team had to find a way to bring all of this information together in a structured way.
The data used to train the model falls into two main categories.
The first is tabular data, which captures a user’s long-term profile and habits. This includes demographic attributes, saved addresses, spending trends, and other behavioral statistics, such as how often a person orders food or takes a ride in a month. These attributes tend to remain stable over time and give the model a sense of the user’s overall identity and preferences.
The second is time-series clickstream data, which captures the user’s short-term, real-time behavior on the app. This is the sequence of actions a user takes in a session (what they view, click, search for, and eventually purchase). It also includes timing information, such as how long someone hesitates before completing an action, which can reveal their level of decisiveness or interest. This type of data provides a dynamic and up-to-date view of what the user is trying to accomplish at any given moment.
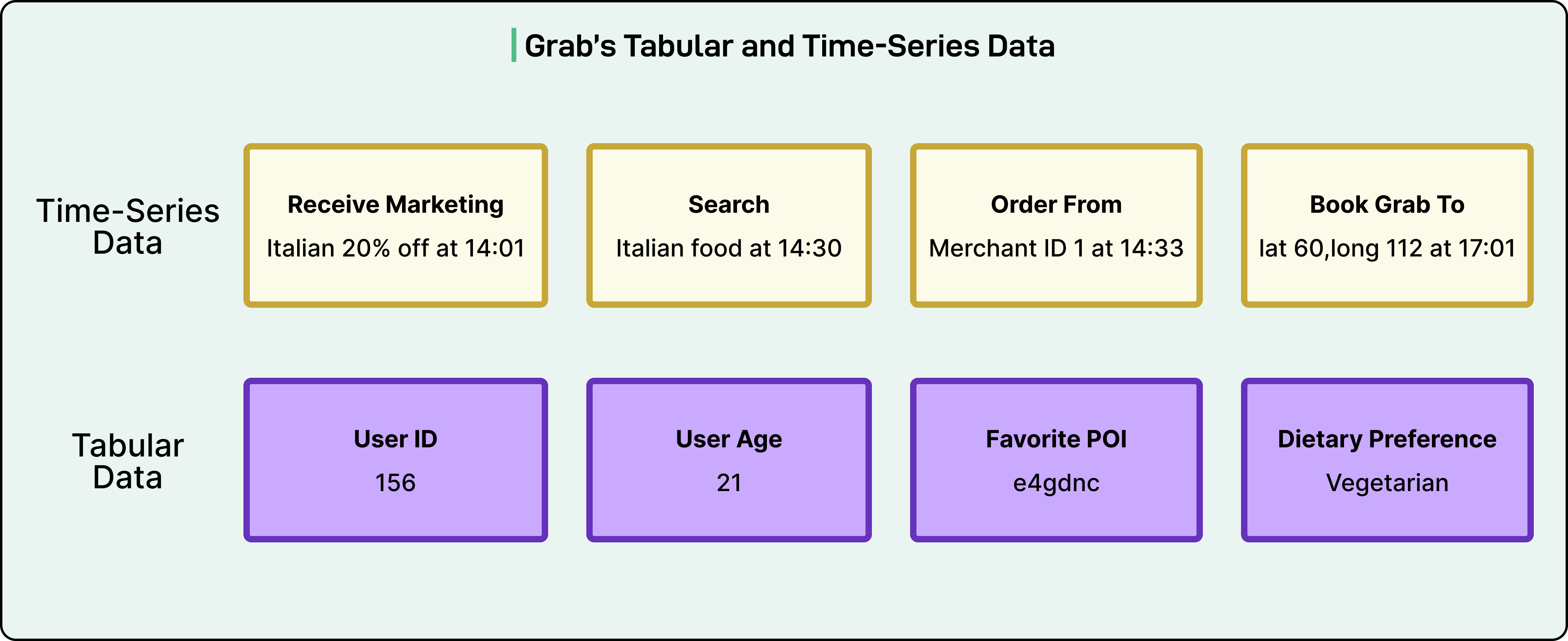
To make this information usable by a machine learning model, Grab groups the data into multiple modalities, each with its own characteristics:
Text: Search queries, merchant names, and user-generated reviews contain rich signals about intent and preferences.
Numerical: Numbers such as delivery prices, ride fares, travel distances, and wait times help quantify behavior and context.
Categorical IDs: Unique identifiers such as user_id, merchant_id, and driver_id allow the system to link individual entities to their history and attributes.
Location: Geographic coordinates and geohashes represent places with real-world meaning. For example, a specific geohash might correspond to a shopping mall, a busy transport hub, or a residential neighborhood.
This diversity makes Grab’s data ecosystem very different from platforms with a single primary data source, like videos or text posts. A user on Grab might book a ride to a mall, then search for Japanese food, browse a few restaurants, and place an order. Each of those actions involves a mix of text, location, IDs, and numerical values.
The challenge is not only to handle these different formats but to preserve their structure and relationships when combining them. A ride drop-off location, for example, is not just a coordinate, but often a signal that influences what the user does next. By integrating these heterogeneous data types effectively, the foundation model can build a much richer understanding of context, intent, and behavior.
Key Challenges in Model Design
Building a foundation model for a superapp like Grab comes with a unique set of technical challenges.
The Grab Engineering Team identified four major challenges that shaped the design of the system.
Learning from Tabular and Time-Series Data Together
The first challenge is that tabular and time-series data behave very differently.
Tabular data, such as a user’s profile attributes or aggregated spending history, does not depend on any specific order. Whether “age” appears before or after “average spending” makes no difference to its meaning.
Time-series data, on the other hand, is entirely order-dependent. The sequence of clicks, searches, and transactions tells a story about what the user is trying to do in real time.
Traditional models struggle to combine these two types of data because they treat them in the same way or process them separately, losing important context in the process. Grab needed a model that could handle both forms of data natively and make use of their distinct characteristics without forcing one to behave like the other.
Handling Multiple Modalities
The second challenge is the variety of modalities.
Text, numbers, IDs, and locations each carry different types of information and require specialized processing. Text might need language models, numerical data might require normalization, and location data needs geospatial understanding.
Simply treating all of these as the same kind of input would blur their meaning. The model needed to process each modality with techniques suited to it while still combining them into a unified representation that downstream applications could use.
Generalizing Across Many Tasks
Most machine learning models are built for one purpose at a time, like recommending a movie or ranking ads.
Grab’s foundation model had to support many different use cases at once, from ad targeting and food recommendations to fraud detection and churn prediction. A model trained too narrowly on one vertical would produce embeddings biased toward that use case, making it less useful elsewhere.
In other words, the architecture needed to learn general patterns that could be transferred effectively to many different tasks.
Scaling to Big Vocabularies
The final major challenge was scale.
Grab’s platform involves hundreds of millions of unique users, merchants, and drivers. Each of these entities has an ID that needs to be represented in the model. A naive approach that tries to predict or classify over all of these IDs directly would require an output layer with billions of parameters, making the model slow and expensive to train.
The design had to find a way to work efficiently at this massive scale without sacrificing accuracy or flexibility.
Architecture Overview - Transformer Backbone
To bring together so many different types of data and make them useful in a single model, the Grab Engineering Team built its foundation model on top of a transformer architecture.
Transformers have become a standard building block in modern machine learning because they can handle sequences of data and learn complex relationships between tokens. But in Grab’s case, the challenge was unique: the model had to learn jointly from both tabular and time-series data, which behave in very different ways.
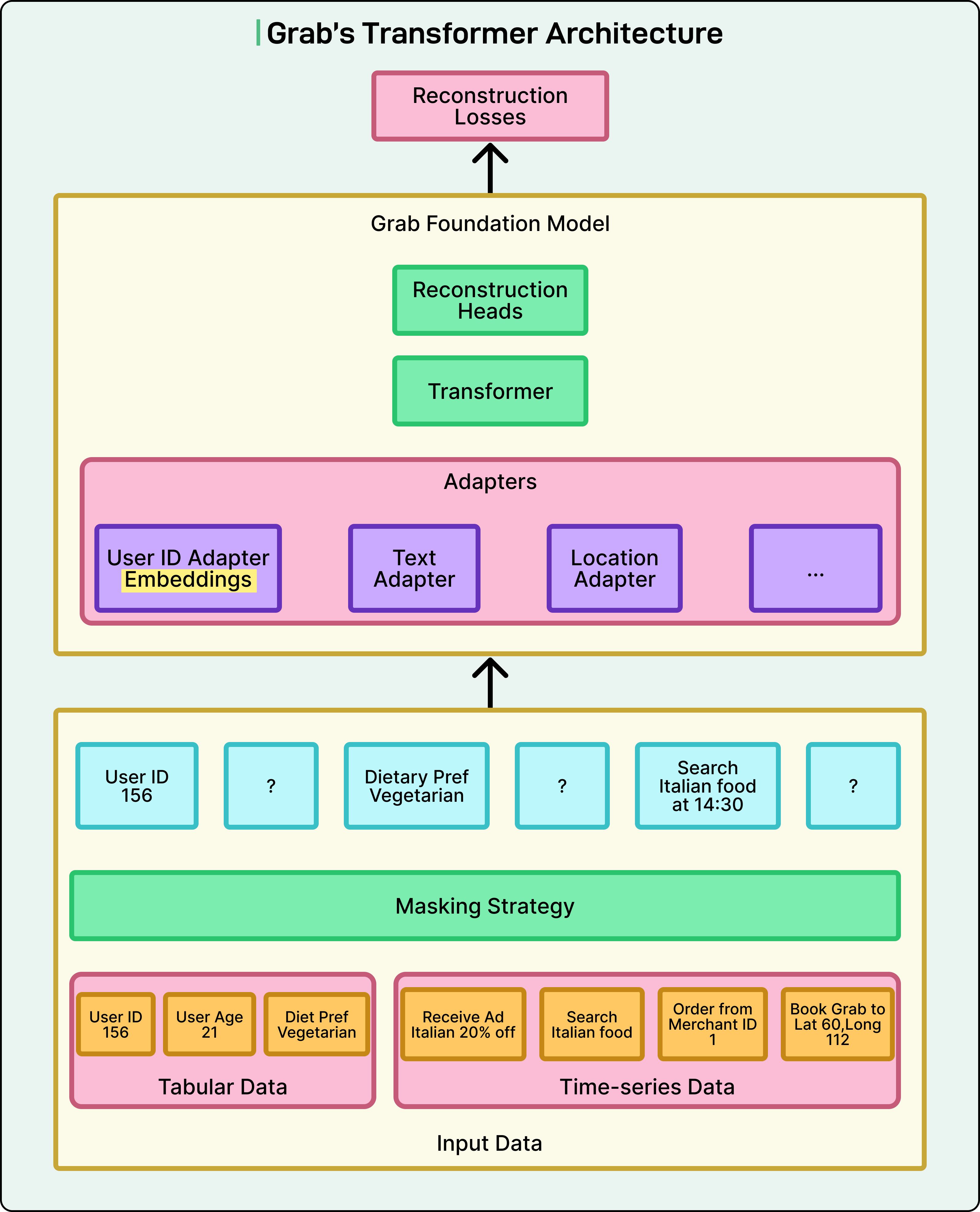
The key innovation lies in how the data is tokenized and represented before it enters the transformer.
Tokenization Strategy
Instead of feeding raw tables or sequences directly into the model, Grab converts every piece of information into a key: value token. Here’s how it handles tabular and time-series data:
For tabular data, the key is the column name (for example, online_hours) and the value is the user’s attribute (for example, 4).
For time-series data, the key is the event type (for example, view_merchant) and the value is the entity involved (for example, merchant_id_114).
This method gives the model a unified language to describe every kind of signal, whether it is a static attribute or a sequence of actions. A “token” here can be thought of as a small building block of information that the transformer processes one by one.
Positional Embeddings and Attention Masks
Transformers are sensitive to the order of tokens because order can change meaning. For example, in a time series, a ride booking followed by a food order has a different meaning than the reverse. But tabular data does not have a natural order.
To solve this, Grab applies different positional rules depending on the data type:
Tabular tokens are treated as an unordered set. The model does not try to find meaning in the order of columns.
Time-series tokens are treated as an ordered sequence. The model uses positional embeddings to understand which event came first, second, third, and so on.
This is where attention masks play an important role. In simple terms, an attention mask tells the transformer which tokens should be related to each other and how. For tabular data, the mask ensures that the model does not infer any fake ordering. For time-series data, it ensures that the model respects the actual sequence of actions.
A Hybrid Design for Unified Learning
This combination of key: value tokenization, different positional treatments, and attention masks allows the model to process both structured profile information and sequential behavior at the same time.
In traditional systems, these two types of data are often handled by separate models and then stitched together. Grab’s approach lets the transformer learn directly from both simultaneously, which leads to richer and more accurate user representations.
This hybrid backbone forms the core of the foundation model. It ensures that no matter whether the signal comes from a stable profile attribute or a rapidly changing interaction pattern, the model can interpret it in a consistent and meaningful way.
Adapter-based Modality Handling
Once the transformer backbone is in place, the next major design challenge is figuring out how to handle different data types in a way that preserves their meaning.
A user’s interaction with Grab can involve text, numerical values, location data, and large sets of IDs. Each of these requires different processing techniques before the model can bring them together into a shared representation. If all data were treated the same way, important nuances would be lost. For example, a text search for “chicken rice” should not be processed in the same manner as a pair of latitude and longitude coordinates or a user ID.
To solve this, the Grab Engineering Team uses a modular adapter-based design.
Adapters act as specialized mini-models for each modality. Their role is to encode raw data into a high-dimensional vector representation that captures its meaning and structure before it reaches the main transformer.
Here’s how different modalities are handled:
Text adapters: Textual data, such as search queries and reviews, is processed through encoders initialized with pre-trained language models. This lets the system capture linguistic patterns and semantic meaning effectively, without having to train a language model from scratch.
ID adapters: Categorical identifiers like user_id, merchant_id, and driver_id are handled through dedicated embedding layers. Each unique ID gets its own learnable vector representation, allowing the model to recognize specific users or entities and their historical patterns.
Location and numerical adapters: Data such as coordinates, distances, and prices do not fit neatly into existing language or ID embedding spaces. For these, the team builds custom encoders designed to preserve their numerical and spatial structure. This ensures that the model understands how two nearby locations might relate more closely than two distant ones, or how price differences can affect behavior.
Once each adapter processes its input, the resulting vectors are passed through an alignment layer. This step ensures that all the different modality vectors are projected into the same latent representation space. This makes it possible for the transformer to compare and combine them meaningfully, such as linking a text query to a location or a specific merchant.
Unsupervised Pre-Training
One of the most important decisions in building Grab’s foundation model was how to train it.
Many machine learning systems are trained for one specific task, such as predicting whether a user will click on an ad or what item they might buy next. While this approach works well for focused problems, it can lead to biased embeddings that perform poorly outside that single use case.
Since Grab’s model needs to support a wide range of applications across multiple verticals, the Grab Engineering Team decided to use an unsupervised pre-training strategy.
In supervised learning, the model is optimized to solve one particular labeled task. However, Grab’s ecosystem involves food orders, rides, grocery deliveries, financial transactions, and more. A model trained only on one vertical (say, food ordering) would end up favoring signals relevant to that domain while ignoring others.
By contrast, unsupervised pre-training lets the model learn general patterns across all types of data and interactions without being tied to a single label or task. Once trained, the same model can be adapted or fine-tuned for many downstream applications like recommendations, churn prediction, or fraud detection.
The first core technique is masked language modeling (MLM). This approach, inspired by methods used in large language models, involves hiding (or “masking”) some of the tokens in the input and asking the model to predict the missing pieces.
For example, if a token represents “view_merchant: merchant_id_114”, the model might see only view_merchant:[MASK] and must learn to infer which merchant ID fits best based on the rest of the user’s activity. This forces the model to build a deeper understanding of how user actions relate to each other.
The second key technique is next action prediction, which aligns perfectly with how user behavior unfolds in a superapp. A user might finish a ride and then search for a restaurant, or browse groceries, and then send a package. The model needs to predict what kind of action comes next and what specific value is involved.
This happens in two steps:
Action type prediction: Predicting what kind of interaction will happen next (for example, click_restaurant, book_ride, or search_mart).
Action value prediction: Predicting the entity or content tied to that action, such as the specific merchant ID, destination coordinates, or text query.
This dual-prediction structure mirrors the model’s key: value token format and helps it learn complex behavioral patterns across different modalities.
Different data types require different ways of measuring how well the model is learning. To handle this, Grab uses modality-specific reconstruction heads, which are specialized output layers tailored to each data type:
Categorical IDs: Use cross-entropy loss, which is well-suited for classification tasks involving large vocabularies.
Numerical values: Use mean squared error (MSE) loss, which works better for continuous numbers like prices or distances.
Other modalities: Use loss functions best matched to their specific characteristics.
Handling of Massive ID Vocabularies
One of the biggest scaling challenges Grab faced while building its foundation model was dealing with massive ID vocabularies. The platform serves hundreds of millions of users, merchants, and drivers. Each of these entities has a unique ID that the model needs to understand and, in some cases, predict.
If the model were to predict directly from a single list containing all these IDs, the output layer would have to handle hundreds of millions of possibilities at once. This would require tens of billions of parameters, making the system extremely expensive to train and slow to run. It would also be prone to instability during training because predicting across such a huge space is computationally difficult.
To address this, the Grab Engineering Team adopted a hierarchical classification strategy. Instead of treating all IDs as one flat list, the model breaks the prediction task into two steps:
The model first predicts a high-level category that the target ID belongs to. For example, if it is trying to predict a restaurant, it might first predict the city or the cuisine type.
Once the coarse group is identified, the model then predicts the specific ID within that smaller group. For example, after predicting the “Japanese cuisine” group, it might choose a particular restaurant ID from within that set.
Embedding Extraction vs Fine-Tuning
Once Grab’s foundation model has been pre-trained on massive amounts of user interaction data, the next question is how to use it effectively for real business problems.
The Grab Engineering Team relies on two main approaches to make the most of the model’s capabilities: fine-tuning and embedding extraction.
Fine-Tuning for Specific Tasks
Fine-tuning means taking the entire pre-trained model and training it further on a labeled dataset for a specific task. For example, the model can be fine-tuned to predict fraud risk, estimate churn probability, or optimize ad targeting.
The advantage of fine-tuning is that the model retains all the general knowledge it learned during pre-training but adapts it to the needs of one particular problem. This approach usually gives the highest performance when you need a specialized solution because the model learns to focus on the signals most relevant to that specific task.
Embedding Extraction as General Features
The second, more flexible option is embedding extraction. Instead of retraining the entire model, Grab uses it to generate embeddings, which are high-dimensional numerical vectors that represent users, merchants, or drivers. These embeddings can then be fed into other downstream models (such as gradient boosting machines or neural networks) without modifying the foundation model itself.
This approach makes the foundation model a feature generator. It gives other teams across the company the ability to build specialized applications quickly, using embeddings as input features, without having to train a large model from scratch. This saves both time and computational resources.
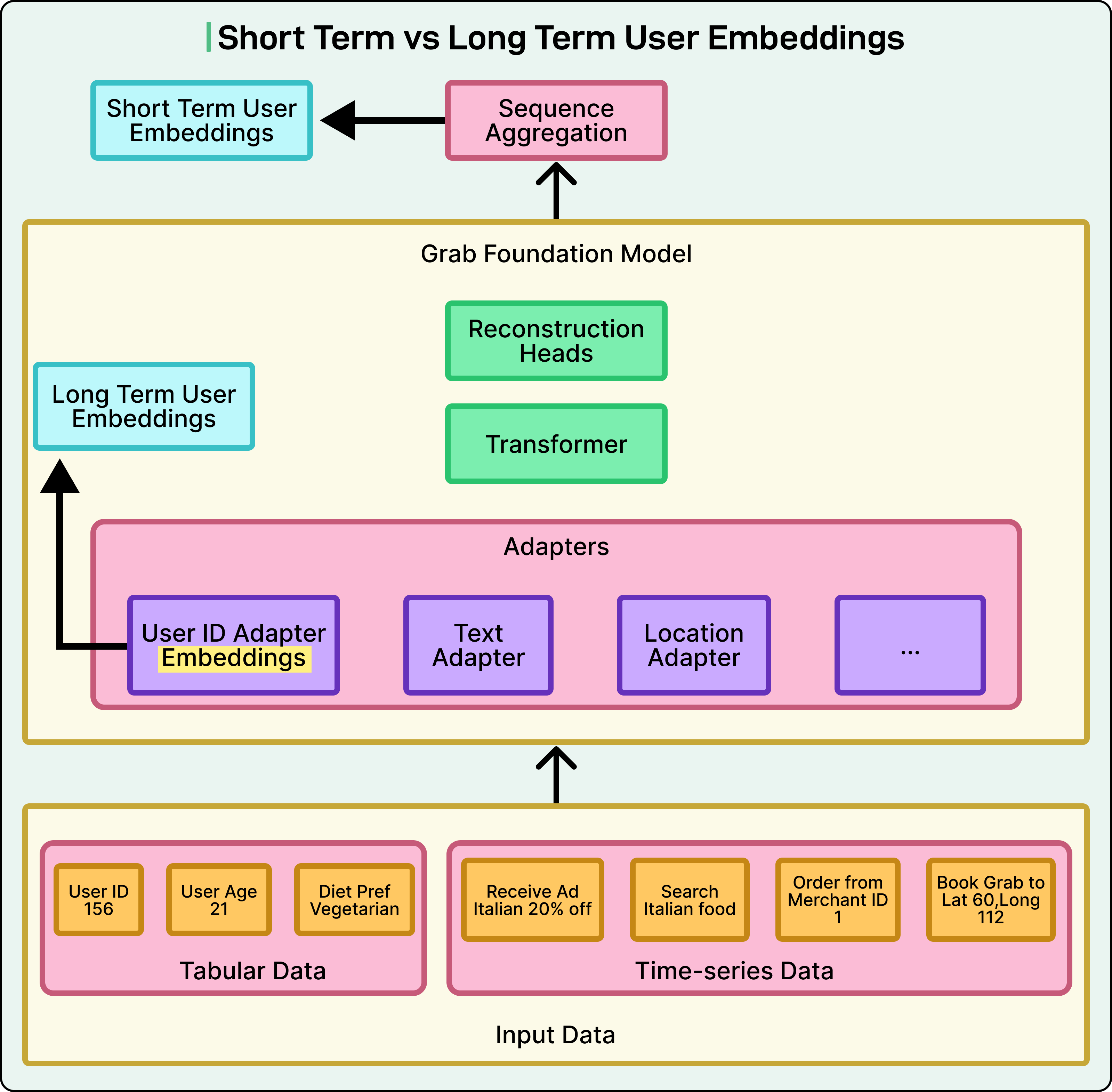
Dual-Embedding Strategy: Long-Term and Short-Term
To fully capture user behavior, Grab uses a dual-embedding strategy, generating two types of embeddings for each user:
Long-term embedding: This comes from the User ID adapter. It reflects stable behavioral patterns built up over time, such as spending habits, preferred locations, and service usage frequency. Think of it as a long-term profile or “memory” of the user.
Short-term embedding: This is derived from a user’s recent interaction sequence, processed through the model’s adapters and transformer backbone. A Sequence Aggregation Module then compresses the sequence output into a single vector that captures the user’s current intent or “what they’re trying to do right now.”
Conclusion
Grab’s foundation model represents a major step forward in how large-scale, multi-service platforms can use AI to understand user behavior.
By unifying tabular and time-series data through a carefully designed transformer architecture, the Grab Engineering Team has created a system that delivers cross-modal representations of users, merchants, and drivers.
The impact of this shift is already visible. Personalization has become faster and more flexible, allowing teams to build models more quickly and achieve better performance. These embeddings are currently powering critical use cases, including ad optimization, dual app prediction, fraud detection, and churn modeling. Since the foundation model is trained once but can be reused in many places, it provides a consistent understanding of user behavior across Grab’s ecosystem.
Looking ahead, Grab aims to take this a step further with its vision of “Embeddings as a Product.” The goal is to provide a centralized embedding service that covers not only users, merchants, and drivers but also locations, bookings, and marketplace items. By making embeddings a core platform capability, Grab can give teams across the company immediate access to high-quality behavioral representations without needing to train their own models from scratch.
To support this vision, the roadmap includes three key priorities:
Unifying data streams to create cleaner and lower-noise signals for training.
Evolving the model architecture to learn from richer and more complex data sources.
Scaling the infrastructure to handle growing traffic volumes and new data modalities as the platform expands.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Excellent work. Well done Grab Engineering Team🔥 Thanks ByteByteGo for capturing it nicely.