
How Grab is Using AI Agents to Boost Team Productivity

The developer toolkit for shipping AI features with confidence (Sponsored)

With release cycles speeding up in the era of AI, developers need to move fast without losing visibility in production. Get 4 resources covering everything from catching flaky tests and pipeline bottlenecks to instrumenting LLM calls and controlling rollouts before regressions reach users.
You’ll learn how to:
Track every CI pipeline run and cut test suite instability slowing your AI delivery cycles.
Catch LLM quality, latency, and cost issues before they surface in production.
Measure and improve release confidence as AI drives higher commit volume across your team.
Grab’s data engineering team had a problem that looks familiar to anyone who’s maintained shared infrastructure. Their best engineers were spending two full days every week answering quick questions from colleagues.
For reference, Grab is a super-app across Southeast Asia handling rides, food delivery, payments, and more. All of that activity generates enormous amounts of data, and the Analytics Data Warehouse (ADW) team is responsible for organizing and serving it to the rest of the company.
This team manages over 15,000 tables that power roughly half of all queries in Grab’s data lake, and about 1,000 people across the company query those tables every month. Analysts, product managers, and other engineers all depend on the ADW team’s tables to do their jobs.
That made the ADW team the librarians of Grab’s data, but also the help desk. The questions were quick to ask, such as “Why does this ID look like gibberish?” or “Can you add a column to this table?”
However, each answer required a fragmented journey through data catalogs, manual lineage tracing, SQL validation, and log diving. So they built a multi-agent AI system to automate the investigation process. The system worked great in demos. Then they shipped it to production, and six things broke.
But before we get to what broke and how the team handled things, let us understand what they built.
Disclaimer: This post is based on publicly shared details from the Grab Engineering Team. Please comment if you notice any inaccuracies.
The Pattern Behind the Problem
The ADW team tracked the anatomy of these questions and noticed something important. While every question was different, the process of answering them was quite consistent. An engineer would search through data catalogs, trace where the data came from, validate it with SQL queries, and check pipeline logs. The questions varied, but the investigation playbook stayed the same. This consistency was a signal for a possible automation opportunity.
Their design philosophy started with a clean separation, which they describe as decoupling the brain from the hands.
The brain is the LLM doing the reasoning. The hands are specialized agents and tools that actually fetch information, run queries, and interact with systems. By separating these two concerns, they created a system that was both capable and easy to debug. When something went wrong, they could pinpoint whether the issue was in the reasoning or in a specific tool interaction.
They also made a deliberate architectural bet.
Rather than building one massive AI trained to handle every type of question, they built multiple specialized agents, each focused on a narrow domain.
See the diagram below that shows how an AI agent works:
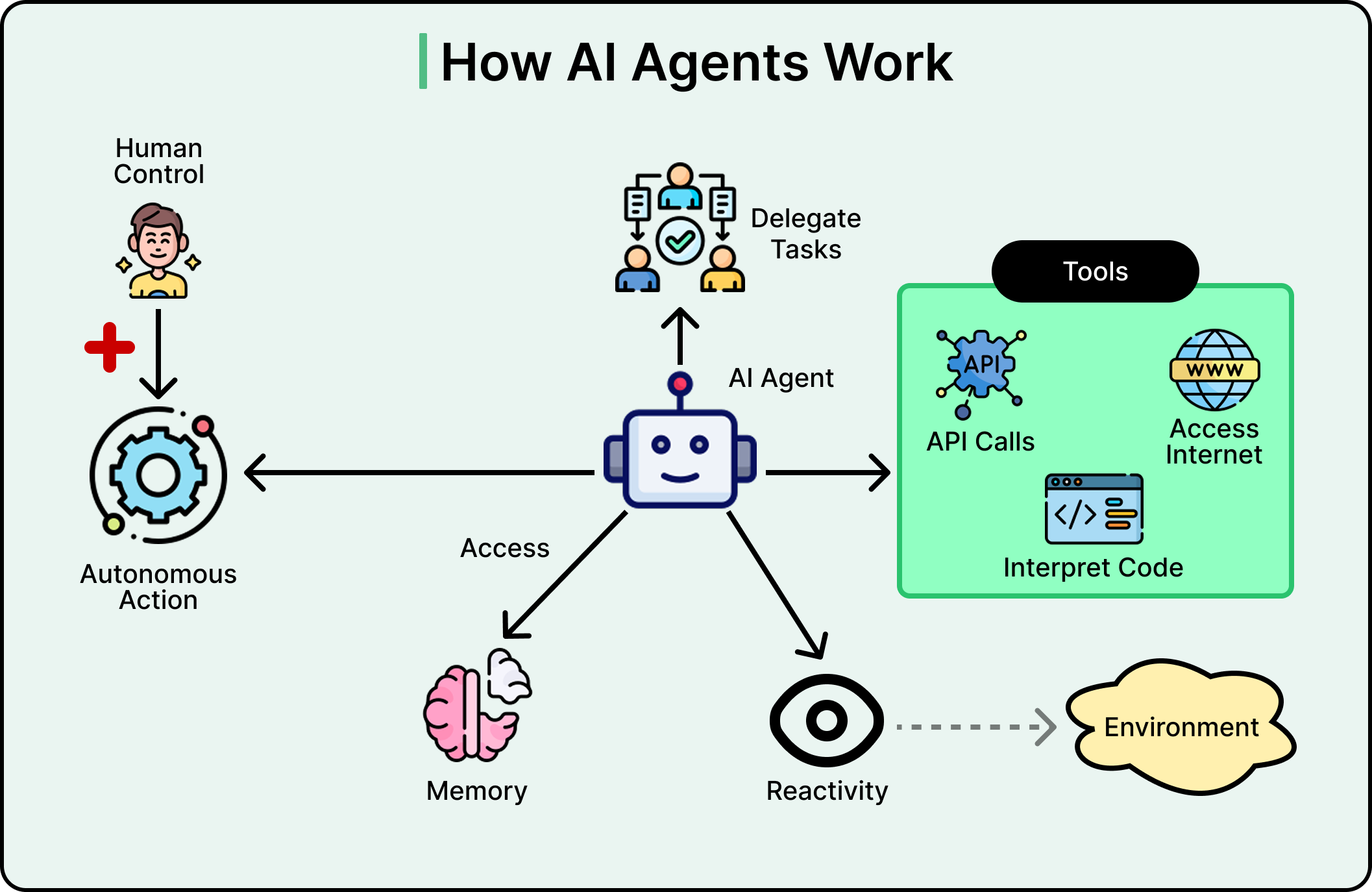
A single monolithic model would have been simpler to deploy with one model and one inference call, but it would also be harder to debug, and any change would risk affecting everything. On the other hand, specialized agents are modular. You can improve one without touching the others, add new ones without rewriting the system, and assign clear responsibilities that make failures traceable. The tradeoff is coordination complexity and some added latency from sequential execution.
See the comparison below:
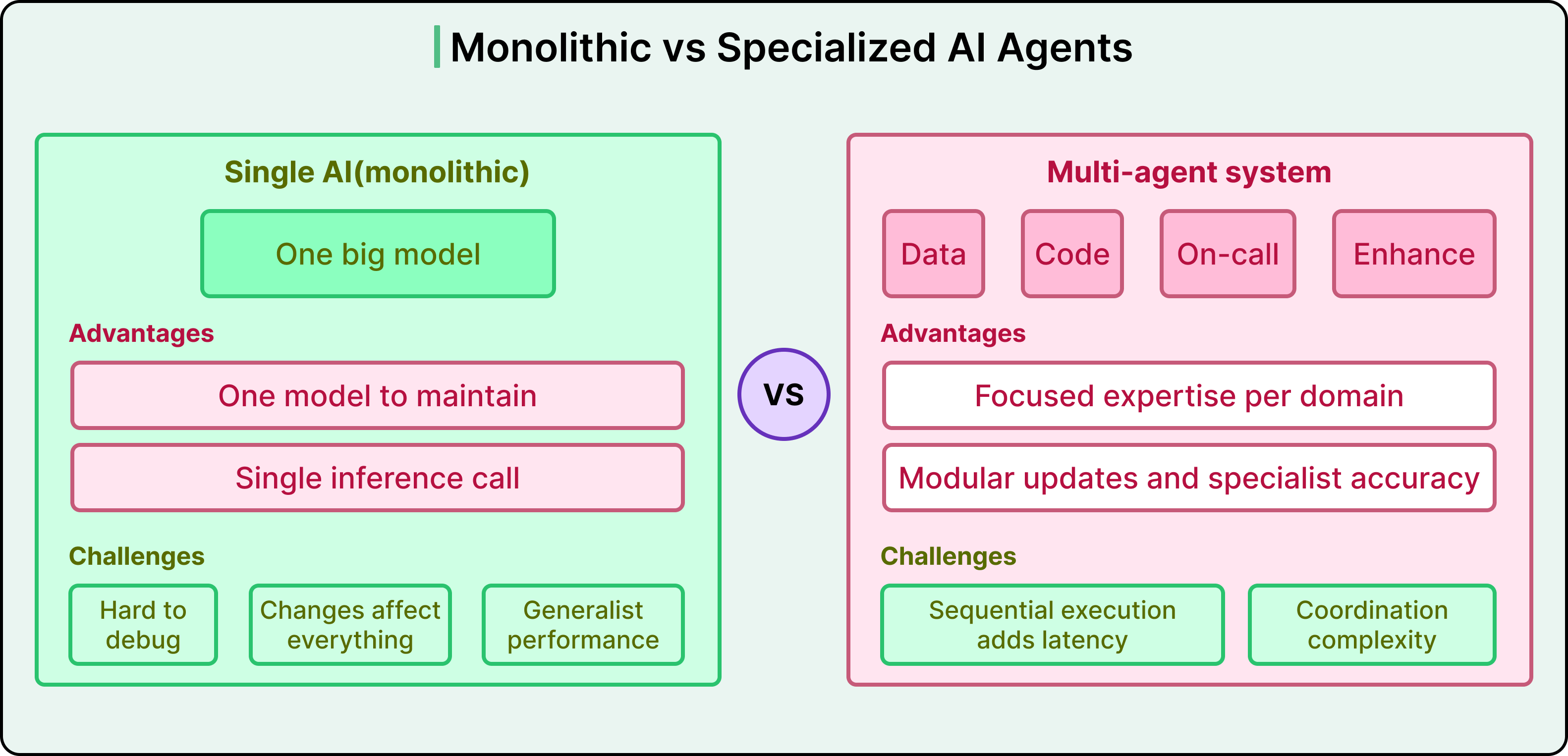
Grab accepted that tradeoff because maintainability and accuracy mattered more than saving a few seconds. The idea was that when you are replacing a multi-hour manual investigation, a few minutes for a precise answer is a massive improvement.
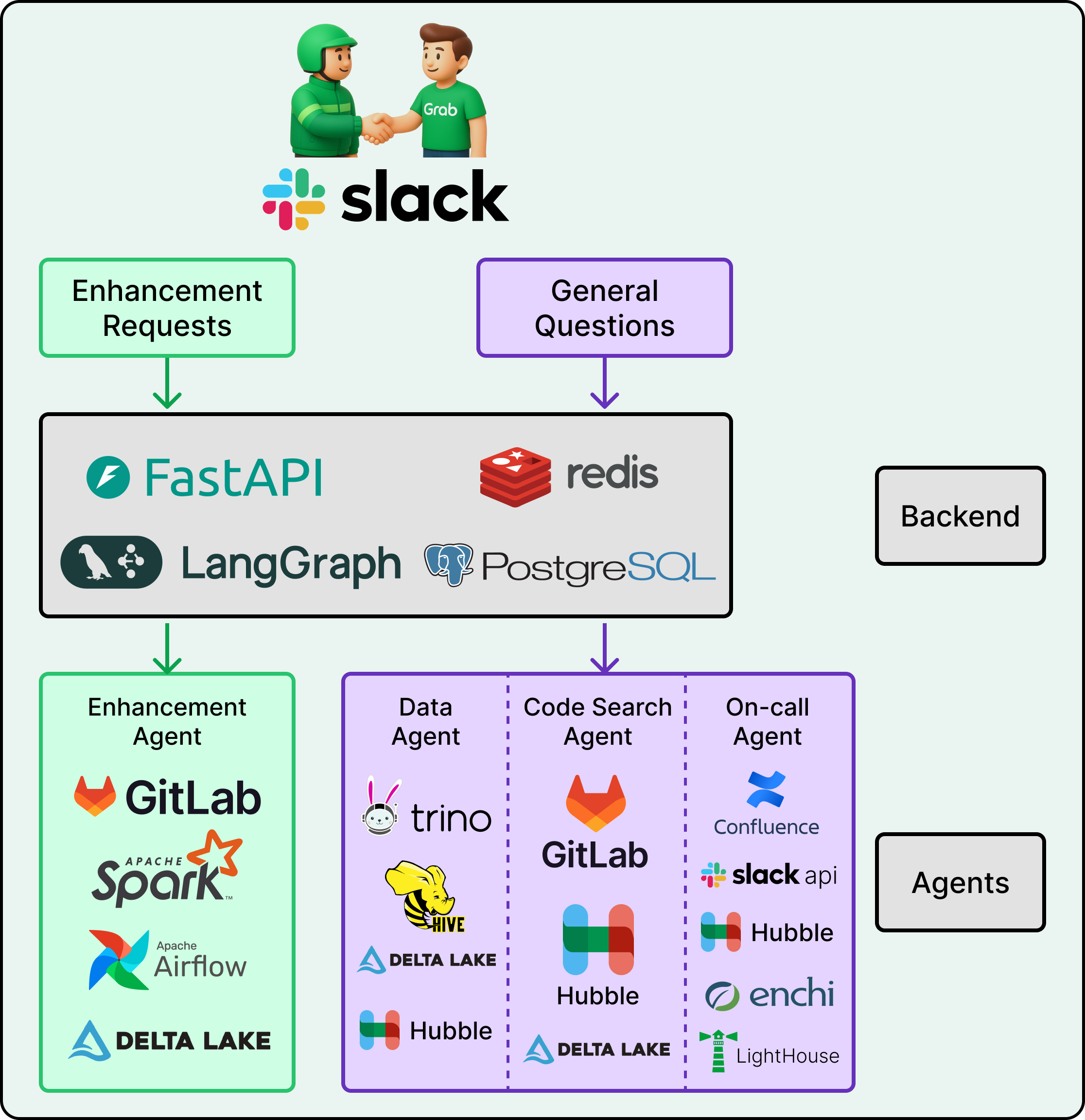
On the tech stack side, they used FastAPI to handle incoming requests and LangGraph to manage the complex stateful logic that multi-agent collaboration requires. Simple LLM calls follow a straight line from input to output, but Grab’s agents need to loop back, ask for more information, or hand off tasks to one another, and LangGraph supports that kind of cyclical workflow. Redis handles caching and real-time session needs, while PostgreSQL stores conversation history and agent metadata as persistent memory. The agents themselves pull information from three internal platforms, which are as follows:
Hubble serves as a centralized metadata and data catalog.
Genchi is a data quality observability platform that enforces data contracts.
Lighthouse tracks pipeline execution status and health.
See the diagram below:
With the architecture in place, the next design decision was how to split the work. This split turned out to be one of the most important choices in the entire system.
Two Pathways, Five Agents, One Supervisor
When a question arrives through Slack, the system first determines which of two pathways to take. This fork is the architectural backbone of the whole system, and it is based on an important principle. Read-only operations and write operations have fundamentally different risk profiles, so they deserve fundamentally different architectures.
See the diagram below:
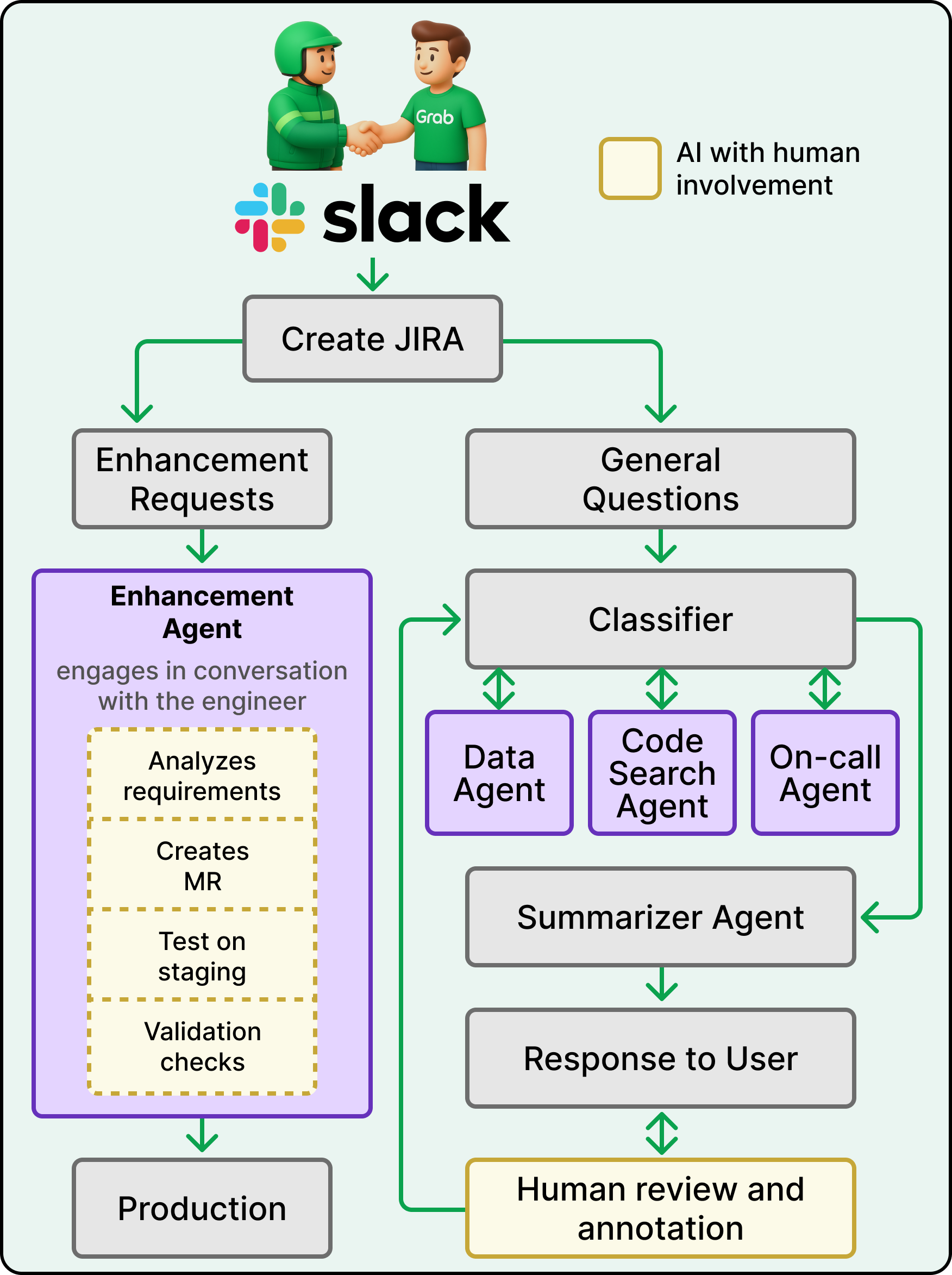
The investigation pathway handles questions like “Why does this data look wrong?” or “Where does this metric come from?” These are read-only. The system is gathering information, and the worst case is a wrong answer that gets caught in review. Four agents collaborate here as follows:
The Classifier is the first responder. It parses the question, extracts key entities like table names and column references, detects guardrail violations such as PII requests or out-of-scope queries, and determines which specialist agents are needed and in what sequence. It also provides reasoning for its routing decisions, which helps with debugging later.
The Data Agent handles the actual data investigation. It enriches prompts with table and column metadata, executes queries with built-in guardrails, validates schemas to avoid unnecessary scans, and retrieves sample data.
The Code Search Agent traces column transformations through the codebase, follows table lineage across multiple transformation steps, and generates plain-language explanations of what the code is doing.
The On-call Agent monitors production health by searching Slack channels for outage announcements, checking observability platforms for pipeline status, and validating data quality metrics like null counts and duplicate rates.
Once the specialist agents finish their work, the Summarizer Agent combines their findings into a coherent answer. This is more than concatenation. It handles conflicting information between agents, ensures consistency, and produces a structured response ready for human review.
The enhancement pathway handles requests that change things, like adding a new column or modifying aggregation logic. These are write operations that touch production pipelines, so the architecture is fundamentally more cautious.
A single Enhancement Agent handles these requests. It reads the JIRA ticket, discovers relevant code in the repository, runs validation checks, generates schema changes and code modifications, and creates a merge request with full documentation. Users can then trigger test pipeline runs through the bot. But at every stage, a human engineer reviews and approves. This pathway is semi-automated by design because code changes to production pipelines require human judgment, and the system was built to respect that boundary.
To see how the investigation pathway works in practice, consider a real scenario from the blog:
Someone messages the team on Slack and asks why the ID in the vehicles table is unreadable.
In the old world, an engineer would spend the next couple of hours searching catalogs, tracing lineage, running SQL, and checking logs.
With the multi-agent system, the Classifier routes the question to all three investigation agents.
The Data Agent queries the actual data and discovers that the IDs are valid UUIDs in standard hexadecimal format. It also searches Grab’s data catalog and finds a dimension table that maps these UUIDs to human-readable vehicle names.
The Code Search Agent traces the lineage through the codebase and confirms that the UUID format comes directly from the source system, with no Spark transformation applied along the way.
The On-call Agent checks Airflow pipeline status, Slack channels for incidents, and data quality metrics, and finds everything healthy.
The Summarizer pulls it all together into a clear answer. The supposed bug was actually working as designed.
See the diagram below:
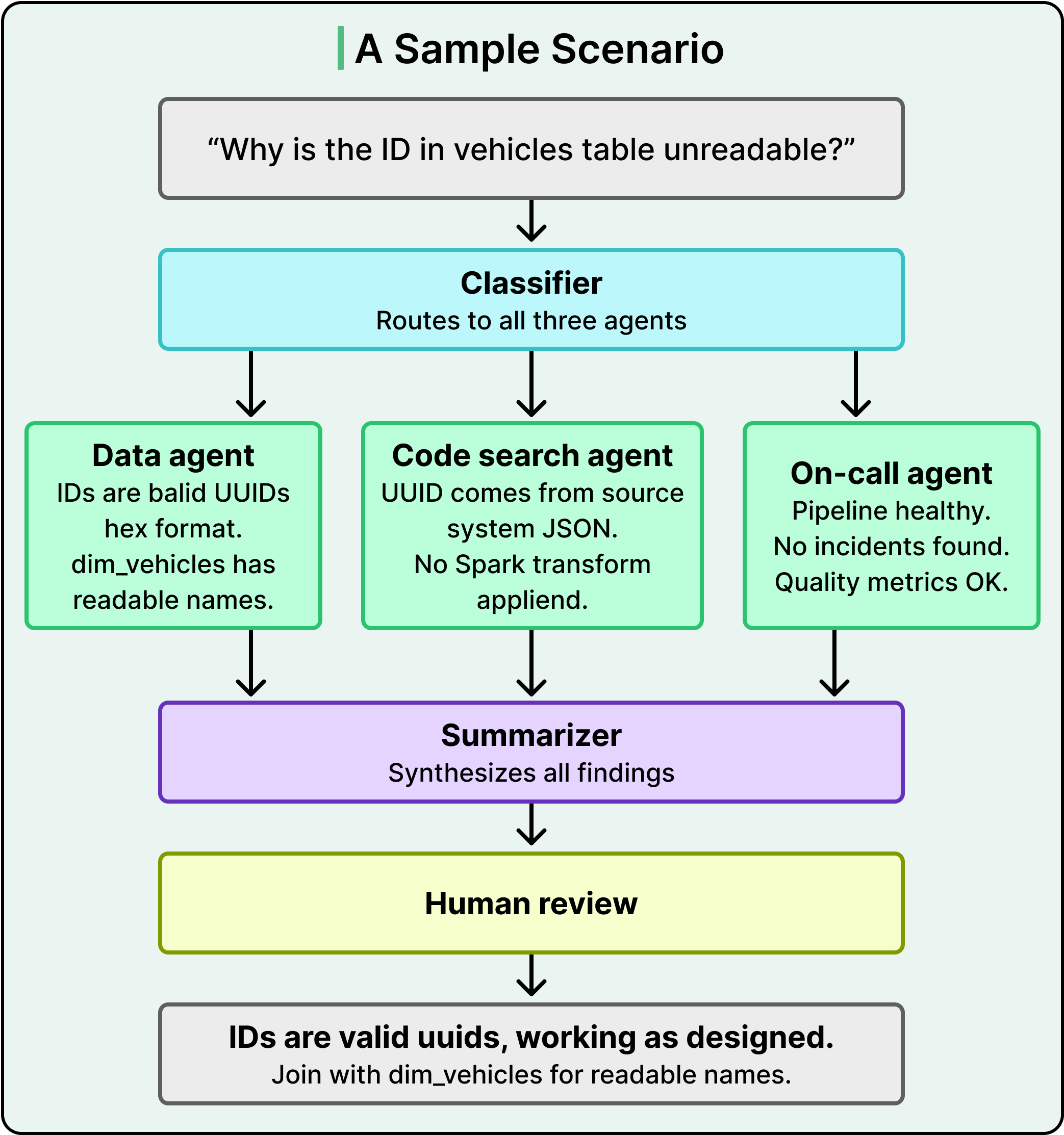
Each agent asked a different type of question. What does the data look like? How is it transformed? Is the system healthy? The full picture only emerged when their findings were combined.
This architecture worked well in controlled demos. Then real users started using it, and the team discovered that building agents was only part of the challenge.
Challenges In Production
Grab’s initial prototype performed well in controlled settings, but real-world usage exposed critical gaps. Complex questions, long conversations, and edge cases pushed the system in ways that demos never did.
Here are four of the most instructive challenges they faced, along with the solutions they engineered.
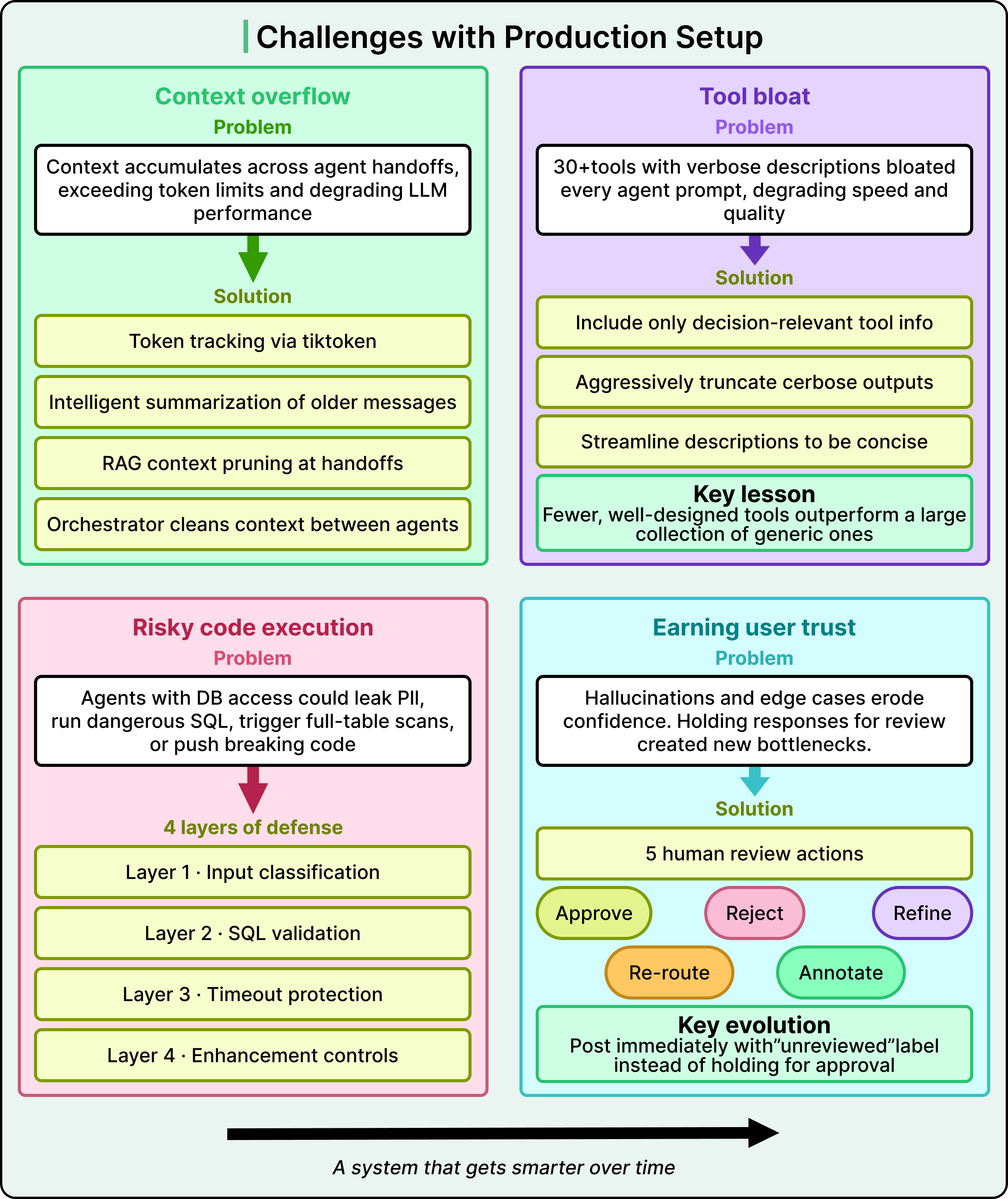
Let’s look at each in more detail:
Context Overflow Across Agent Handoffs
In a multi-agent system, context accumulates fast. Every piece of information passed from one agent to the next adds tokens, and LLM performance degrades when context windows get overloaded.
Grab built a multi-layered solution.
They track every message’s token count in real time using tiktoken, an open-source tokenizer library. When token limits approach, earlier messages are automatically summarized while recent messages and critical context remain untouched to preserve accuracy.
They also prune tool outputs before handoffs. Instead of passing full code files to the Code Search Agent, smaller LLM models extract only the relevant snippets and a short description. The orchestrator sits between agents, cleaning and compressing context at every handoff.
Tool Bloat
The initial design gave agents access to over 30 tools, each with verbose descriptions structured like generic API documentation.
Since tool definitions are part of the agent’s prompt, every inference call had to process all of that text. This degraded both speed and quality.
The fix was aggressive simplification. Include only the portions of tool descriptions needed for decision-making, truncate verbose outputs, and streamline everything to be concise and actionable. This sounds simple, but it produced a substantial improvement in system responsiveness. The lesson is that tool design is an important engineering concern, and fewer well-designed tools outperform a large collection of generic ones.
Risky Code Execution
AI agents with database access and code generation capabilities pose real risks. Without safeguards, they could access sensitive PII data, execute dangerous SQL operations, run expensive queries that scan entire tables, or generate breaking code changes.
Grab built four layers of defense that work together so that any single layer’s blind spots are covered by the others.
The first layer is input classification. The Classifier detects PII requests and out-of-scope queries before any agent executes.
The second layer is SQL validation. Every query is checked for PII column access, dangerous operations like DELETE or DROP, missing partition filters, and schema validity. Without these partition filters, a query might scan an entire massive table instead of just the relevant slice, which is both expensive and slow, and schema validity.
The third layer is timeout protection, where strict execution limits on all database queries prevent runaway operations.
The fourth layer is enhancement controls. The Enhancement Agent cannot commit to the main branches directly. All changes require human review, and everything runs in staging before production.
Earning User Trust
Even with safety layers, AI agents can hallucinate, misinterpret questions, or stumble on edge cases. If users lose confidence in the answers, the system fails regardless of its technical capabilities.
Grab built a human review system where engineers can take five actions on any AI-generated response. They can approve it as-is with a verified footnote, reject it and log it for improvement, refine it by adding a prompt to regenerate the answer, re-route it to a specific agent with additional context, or annotate it with structured feedback for continuous improvement.
They also made a key design evolution here.
Initially, the system withheld all AI-generated responses until an engineer approved them. This was safe but slow, and it created a new bottleneck where questions sat unanswered during peak workload times.
They redesigned the flow to post responses immediately with a clear, unreviewed label, allowing engineers to review and modify as needed. Users get fast answers, the transparency of the label sets appropriate expectations, and the review process still catches errors.
Solving these challenges made the system reliable. But the team wanted something more, a system that gets smarter over time
Closing the Loop
The annotations from human review were initially passive records. The team had a wealth of information about what worked and what failed, but they were missing a systematic way to learn from it.
They transformed annotations into an active improvement engine through multiple mechanisms, which are as follows:
Random annotations get pulled to create test cases for offline evaluation, ensuring the system is tested against real-world failures rather than synthetic ones.
Pattern analysis identifies systemic issues by asking questions such as:
Is the Classifier consistently routing to the wrong agents?
Does a specific agent struggle with certain query types?
Are particular table schemas confusing?
Quality metrics tracked over time detect regression. If the rejection rate suddenly spikes, something has changed that needs investigation.
Targeted improvements use these insights to refine agent prompts, enhance guardrails, and add examples for query types that the system struggles with.
The impact was significant. The bots now autonomously handle the majority of standard user inquiries and a significant portion of enhancement requests. Resolution time dropped by an order of magnitude. The team reclaimed several full-time equivalents worth of engineering bandwidth, shifting hundreds of hours from reactive support to proactive roadmap delivery.
Conclusion
Grab’s journey from overwhelmed data engineers to an AI-augmented team distills into a few key principles:
If the problems vary but the process of solving them stays consistent, it is a good opportunity to have automation.
When building that automation, expect the majority of the effort to go into production hardening rather than the agents themselves.
Apply different levels of autonomy based on the risk profile of the operation.
Read-only investigations can run with light oversight, but anything that changes production data deserves human gates.
Engineer the feedback loop deliberately, because without it, the system is frozen at the quality level of its first deployment. Every rejected response, every annotation, every pattern in the failure data is an opportunity to make the system smarter.
Grab’s own principles capture this well. The goal was never to replace engineers. It was to give them their time back.
References:
Great post! We built a similar data tool for my team's Product Managers at Yelp. It massively cut the number of inbound data questions we received from PM stakeholders.
The annotation flywheel is the part I'd underline three times. Most teams stop at "we collect feedback" whereas Grab turned every rejected response into an offline test case and used pattern analysis to surface systemic failures (wrong routing, struggling agents, confusing schemas). That's the difference between a system that compounds and one frozen at v1.