
How Instacart Built a Search for Billions of Products

New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)

Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
In 2021, the Instacart search team faced a problem they could trace to their users’ typing habits. One group of shoppers searched for items like “pesto pasta sauce 8oz” and expected the exact product to appear. Another group searched for things like “healthy foods” and expected the system to understand what they meant. These are genuinely different problems. The first asks for precise keyword matching. The second asks the system to grasp intent from vague language.
Solving both required two different retrieval systems running in parallel. One handled keyword search. The other handled semantic search, where meaning rather than exact words drives the result. The setup worked, and for a while it worked well. But maintaining two systems in sync, blending their results into a single ranked list, and keeping both fast enough for millions of daily queries became a tax that grew heavier each quarter.
In this article, we will learn how Instacart’s search infrastructure evolved over the years and the challenges its engineering team faced.
Disclaimer: This post is based on publicly shared details from the Instacart Engineering Team. Please comment if you notice any inaccuracies.
The Shape of Search at Instacart
Before looking at the technical choices, it helps to understand the workload Instacart’s search has to serve. A catalog with billions of items stretches across thousands of retailers. The system handles millions of search requests every day, with query volume swinging widely from hour to hour.
What makes their problem genuinely unusual is the write side. Grocery items are fast-moving goods. Prices shift multiple times a day. Inventory availability changes as shelves empty and restock. Discounts come and go. As a result, the search database receives billions of writes per day. Those writes include catalog changes, pricing updates, availability data, ancillary tables for ranking and display, personalization signals, and replacement product data.
This combination is crucial. In most search problems, you index once, maybe refresh occasionally, and queries run against a mostly stable dataset. Instacart’s situation inverts this. Their data changes constantly, and every change has to show up in search results within seconds.
Two terms that we should know are precision and recall. Precision is the percentage of retrieved results that are actually relevant. Recall is the percentage of all relevant documents that the system manages to retrieve. A system with high precision returns mostly good results. A system with high recall catches most of the good results that exist. Tuning these tradeoffs is the core game of search, and the architecture determines how much control you have over each.
Agentic Fine-Tuning and Inference with Pioneer (Sponsored)

Fine-tuning open-source models manually is a slow, tedious task.
Pioneer is a fine-tuning agent that automates the entire process, allowing users to generate synthetic training data, perform LoRA and full fine-tuning runs, run custom evals, and deploy models to production through a chat interface or API. Once deployed, Pioneer autonomously diagnoses failures and retrains on live data in a continuous loop called adaptive inference.
Fastino Labs recently released a technical report evaluating Pioneer’s adaptive inference across eight benchmarks, achieving improvements of up to +83.8 percentage points over base models, with each run completing in 8-12 hours at $12–55.
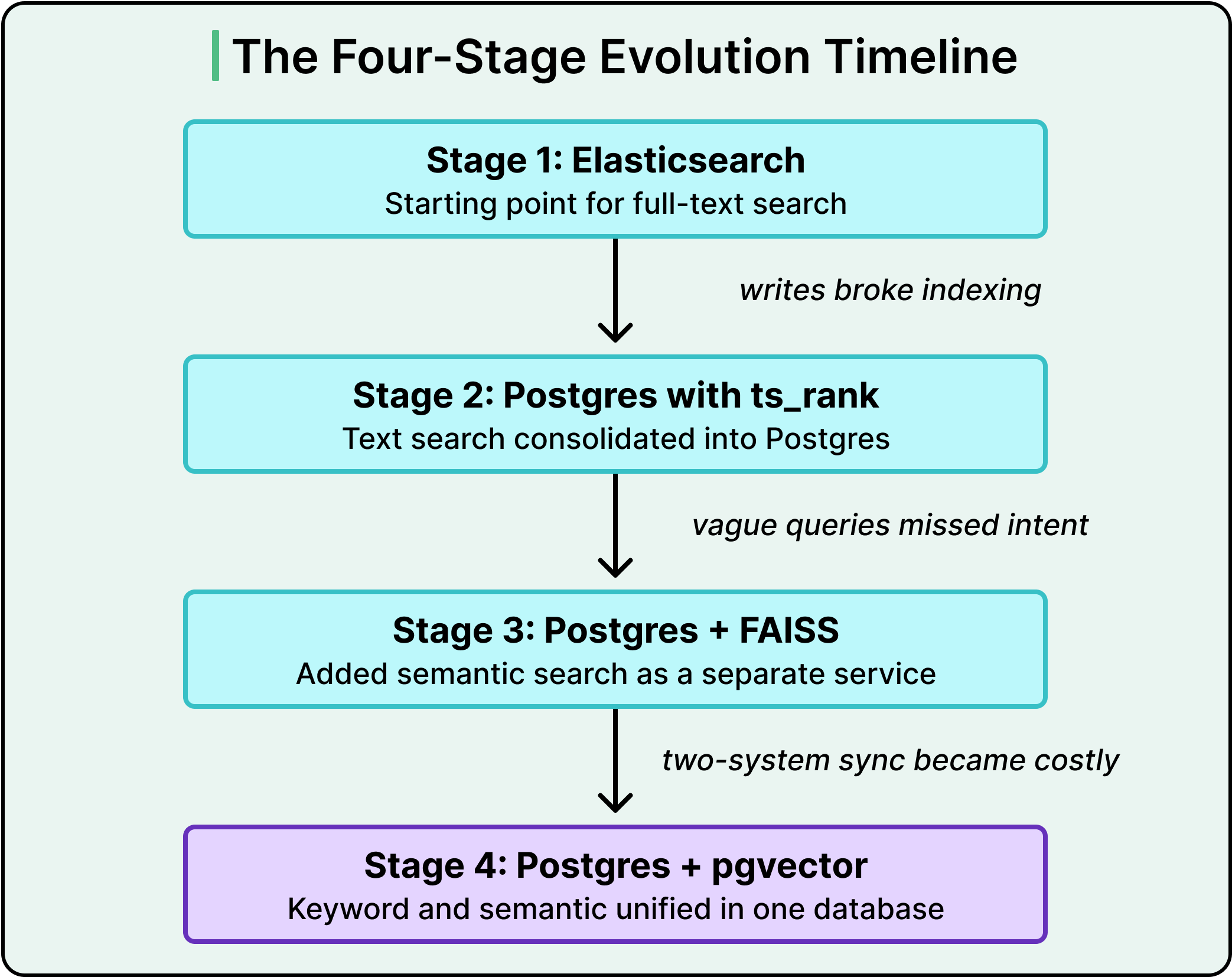
Leaving Elasticsearch Behind
Instacart’s original search was built on Elasticsearch, which was the industry-standard choice for full-text search at the time, and still is today. On paper, the fit looked ideal. Elasticsearch is purpose-built for keyword search at scale, uses a well-understood ranking algorithm called BM25, and has a mature ecosystem of tooling around it.
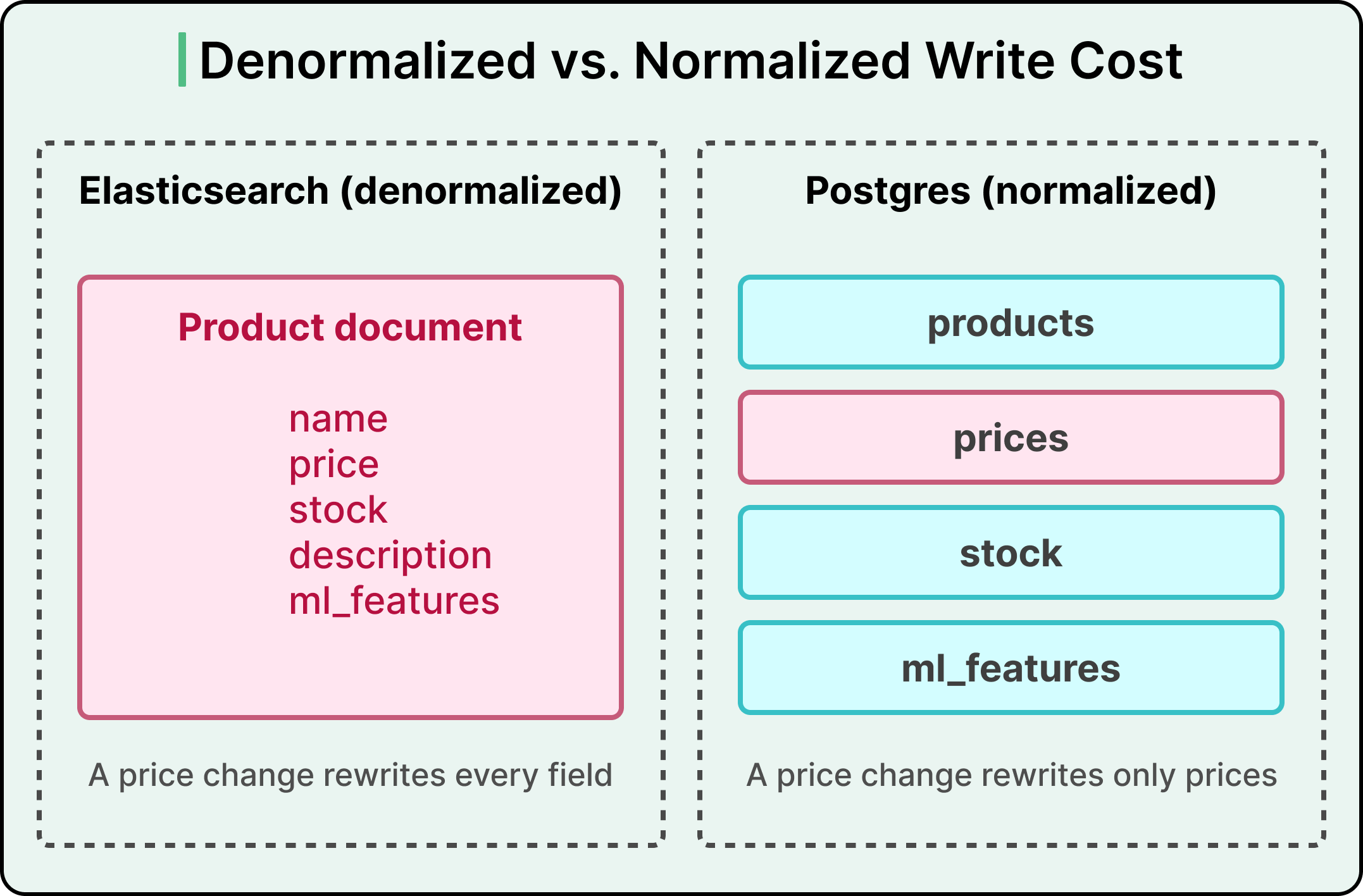
The fit broke down because of how Elasticsearch wants data structured. Elasticsearch prefers denormalized documents, meaning one record per item that bundles together every relevant field. When a user searches, Elasticsearch can return complete documents quickly because everything is already in one place. The catch is that when any single field changes, the entire document has to be rewritten and re-indexed.
For Instacart, this was catastrophic. A price change on a single product triggers a full document rewrite. Multiply that by billions of daily writes, and the indexing load becomes crushing. The system struggled so badly that fixing erroneous data could take days. Layering sophisticated ML features on top only made things worse, since those features also had to be indexed, further degrading read performance.
The team’s response was unusual. Instead of moving to a more specialized search tool, they moved the search into Postgres. This was counterintuitive, since Postgres is a general-purpose relational database, meaning it organizes data into tables with structured columns and relationships between them. The rationale was practical. Their catalog data already lived in Postgres, the team already had deep operational experience running it at scale, and Postgres supports full-text search through GIN indexes (a type of index optimized for searching inside composite values) and a ranking function called ts_rank.
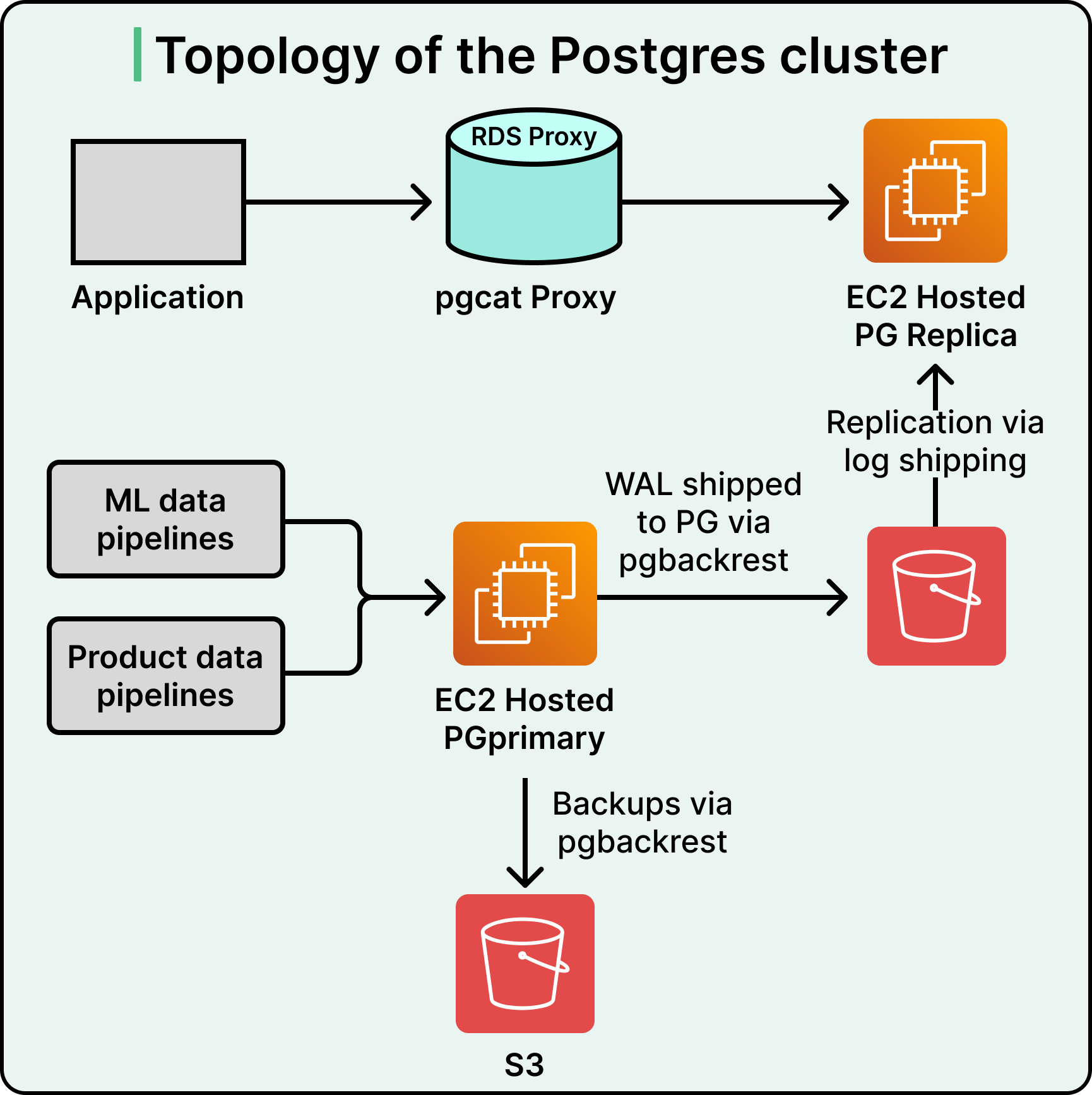
The payoff was significant. A normalized data model, where prices, availability, and ML features live in separate joined tables instead of being stuffed into a single document, reduced their write workload by a factor of ten. Only the price table gets touched by a price change, leaving the rest of the system alone. They also gained the ability to store hundreds of gigabytes of ML features alongside documents, which unlocked more sophisticated retrieval models.
The lesson here is easy to miss. Elasticsearch is an excellent tool. For read-heavy, append-only workloads like log analytics, it remains the right choice. The problem was the mismatch between Elasticsearch’s data model assumptions and Instacart’s write patterns.
Semantic Search and the Two-System Problem
Consolidating text search onto Postgres solved the indexing problem, but it left a different gap. A search for “pesto pasta sauce 8oz” is a straightforward matching exercise. The words are specific, the match criteria are clear, and the keyword search handles it beautifully. Ambiguous queries are where keyword search hits its ceiling. When someone searches for “healthy foods,” the query words and the product titles barely overlap. You want results that match the meaning of the query, since exact word matching falls short here.
This is where semantic search enters the picture. The idea is to convert text into vectors, which are simply lists of numbers (typically a few hundred long), so that texts with similar meanings end up with similar vectors. Once you have vectors for every product and for the query, finding relevant results becomes a geometry problem. You look for vectors near the query vector in this numerical space. This lookup is called approximate nearest neighbor search, or ANN. Clever index structures let ANN find close matches quickly, rather than comparing every single vector in the database against the query.
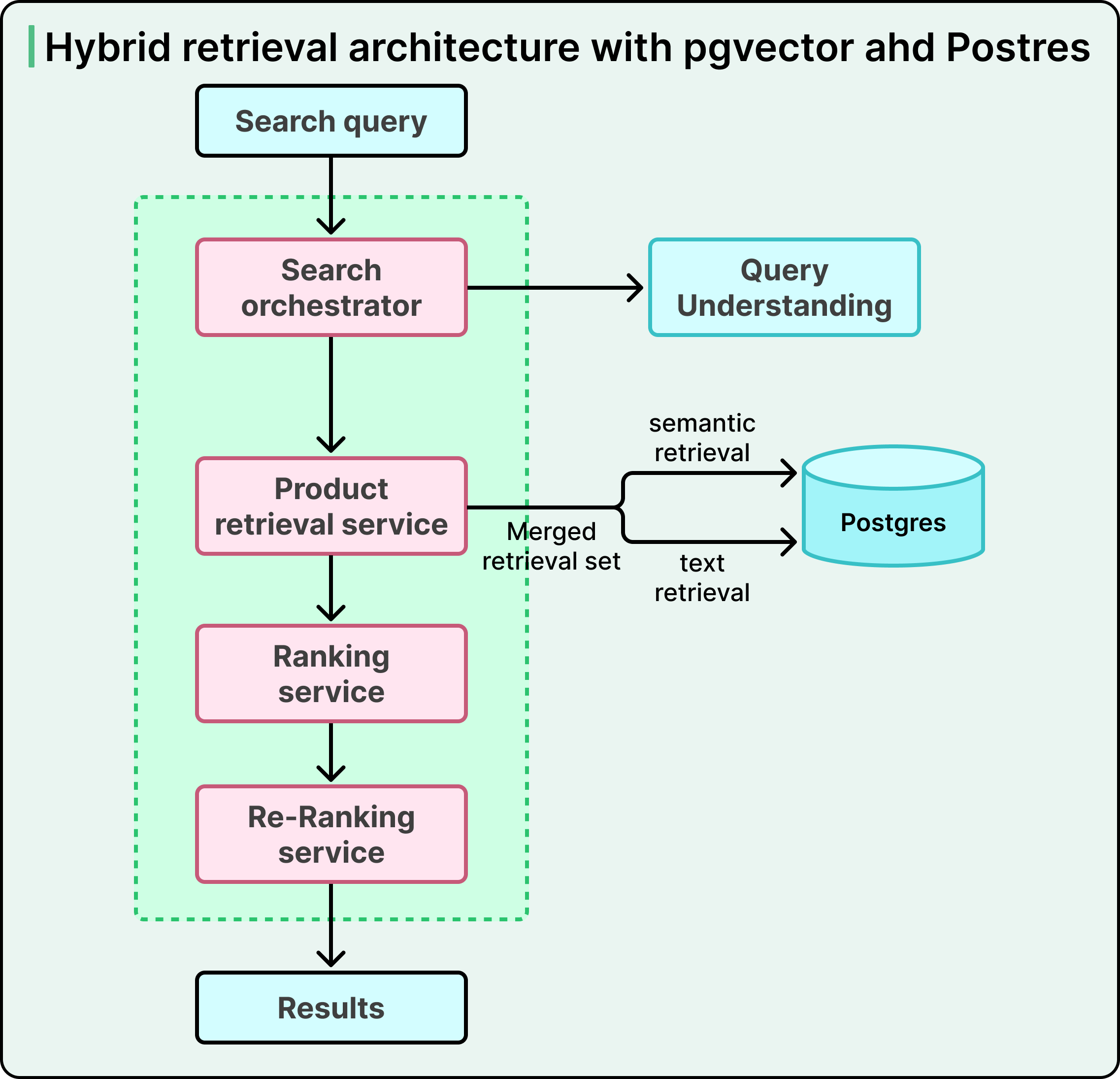
In 2021, Instacart added semantic search to its stack. Since Postgres at the time had yet to gain native ANN support, they built a standalone service using FAISS, a vector search library from Meta. For every incoming query, the system made parallel calls. One call went to Postgres for keyword retrieval. The other went to the FAISS service for semantic retrieval. The application layer merged the two result sets using a weighted ranking step, then passed the top candidates onward to downstream ranking stages that score and order results before they reach the user.
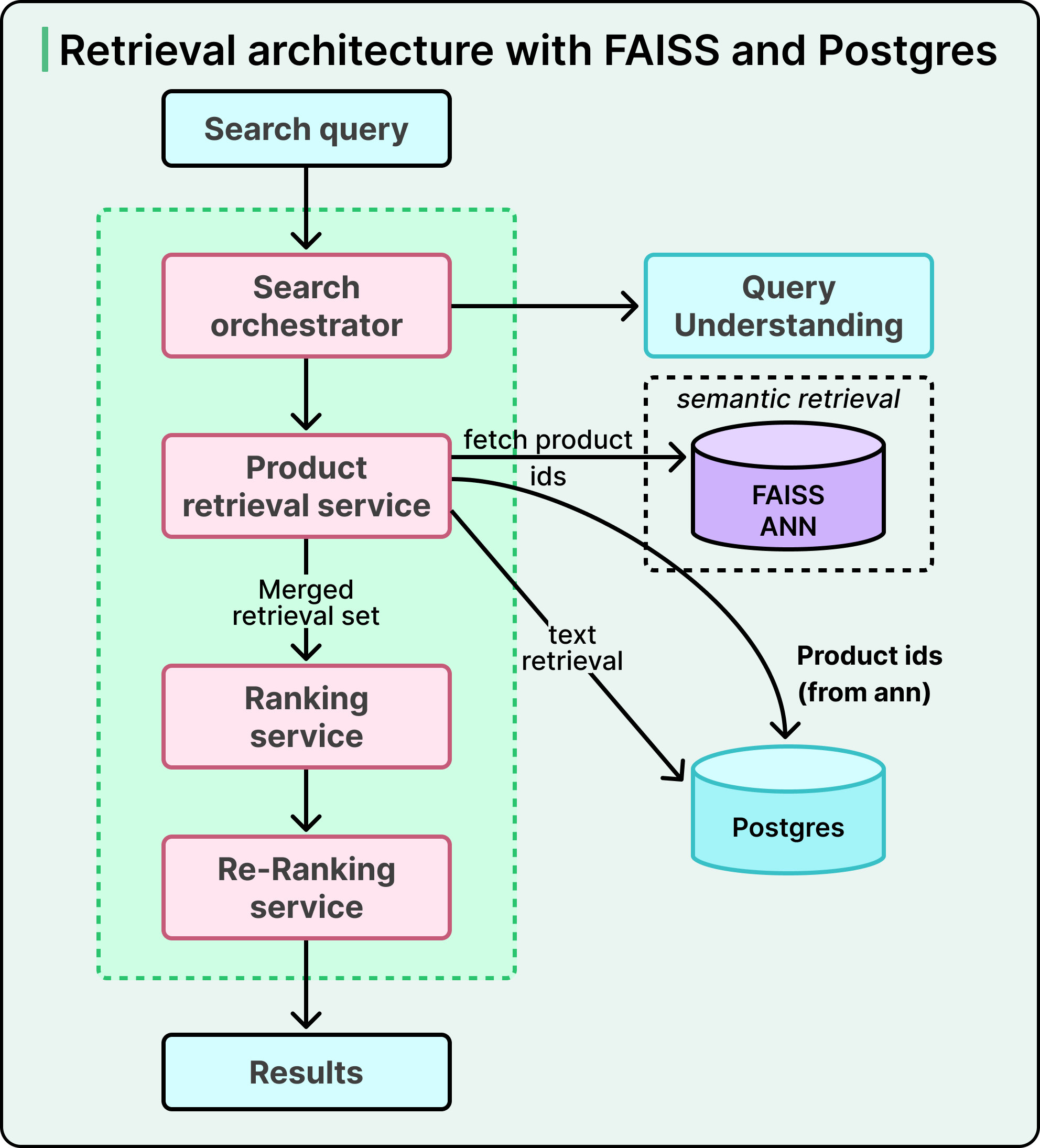
The architecture worked, and search quality improved significantly. Still, three real problems emerged:
First, FAISS had limited support for filtering by document attributes at retrieval time, so the system had to overfetch documents and filter them afterward. This meant some genuinely relevant items got dropped before they reached ranking.
Second, maintaining two separate services created developmental and operational overhead, along with subtle data inconsistencies from keeping them in sync.
Third, the split architecture constrained how intelligently the team could combine signals from the two retrievers.
The 2021 choice was correct for its moment. Postgres-based vector search was still immature then, and FAISS was the right tool for the circumstances. Architectures expire, though, and this one was reaching its shelf life.
Putting It All Back Together with pgvector
As the tradeoffs of the split architecture became more visible, the team started looking for a unified alternative. Two broad paths were available:
The first kept specialized datastores for vectors and text, combining results in the application layer. This is the path most new companies take, since managed vector databases like Pinecone are easy to adopt.
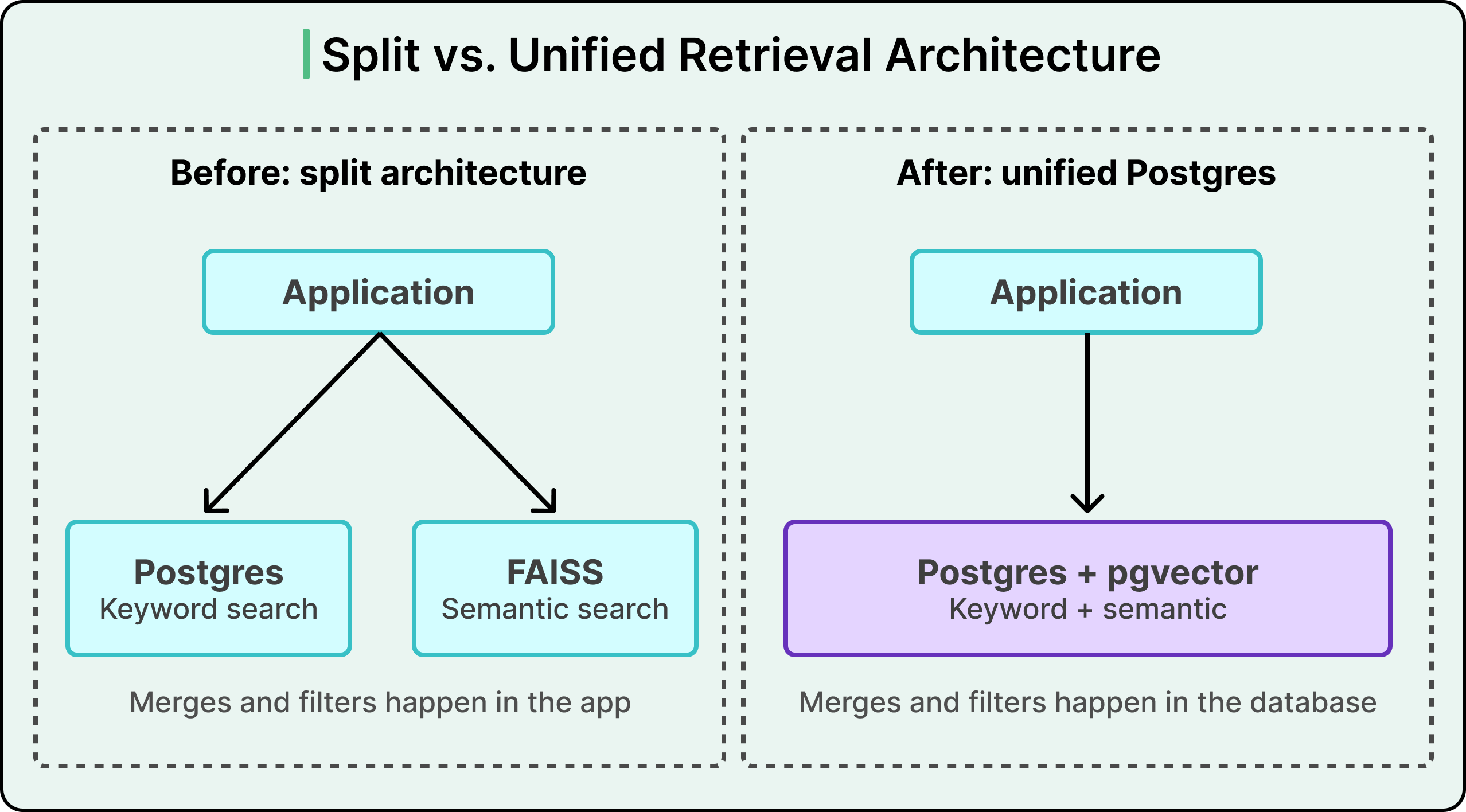
The second used semantic search support inside an existing text search datastore. For Postgres, this meant pgvector, an extension that teaches Postgres to store and search over vectors.
Instacart chose the second path, following the same reasoning as before. Text search already lived in Postgres, the team already operated Postgres at scale, and pgvector had matured enough for serious production workloads. Co-locating vectors with relational data unlocked something new. The system could use real-time inventory as a filter applied before the semantic search ran, rather than after.
Before committing, the team built a lab-scale prototype cluster that mimicked production traffic. The prototype confirmed that pgvector could meet their throughput and latency requirements, with better recall than FAISS and only marginally slower speeds on the largest retailers. One honest finding deserves mention. The team tested whether tuning index parameters per retailer catalog size would help and found it offered little benefit. Sometimes the clever optimization simply falls flat.
A small simplification came out of the migration as well. In the FAISS era, Instacart maintained a separate vector index for every retailer, adding up to hundreds of indexes to operate. With pgvector, they built hybrid indexes grouped by retailer characteristics, dramatically reducing the operational surface area.
The production results were what mattered. An A/B test against real traffic showed a 6 percent drop in searches that returned zero results, driven by improved recall. That single number is the entire business case for the migration. Every zero-result search is a customer who bounced, gave up, or switched apps. Recovering 6 percent of those interactions translated directly into incremental revenue.
The deeper unlock was attribute filtering. With availability data living in the same database as the vectors, Postgres could filter for in-stock items before the ANN search ran, rather than fetching extras and discarding sold-out items afterward. The split architecture made this kind of pre-filter practically impossible. Consolidation made it simple.
Bring the Compute to the Data
The consolidated Postgres architecture made search roughly twice as fast. This speedup deserves attention because of where it came from. The cause was simpler than a new algorithm or faster hardware. Algorithms stayed the same. Hardware stayed the same. What changed was the location of the work.
Here is what the old architecture did on every search request. The application layer made a network call to Elasticsearch for text results. It made separate network calls to other services, including the item availability data service, to gather the rest of the context. It joined the data in memory, applied filters, and assembled the final result set. Every request paid the cost of multiple round-trip, overfetching, and application-layer joining.
The new architecture pushed all of that work into Postgres. Availability data, ML features, ranking tables, and search indexes now live together in one database. A single query could retrieve search matches, join them against availability and other attributes, and filter the result set before sending anything back to the application. The flow needed a single round trip, with zero overfetching and zero in-memory joining.
Why does this matter?
Every network hop adds latency. Every application-layer join forces to fetch extra data you will throw away. Moving the computation into the same place as the data eliminates both costs. This is the principle. Bring the compute to the data, and whenever feasible, avoid the reverse.
The industry-wide trend over the past decade has actually gone the other direction. Systems like Snowflake and BigQuery deliberately separate compute from storage so they can scale each independently. For elastic, bursty analytical workloads, that design makes sense. For latency-sensitive operational workloads like search, the reverse design wins.
The Limits of This Approach
The Instacart approach is powerful, and it also has real limits.
The tool pgvector handles workloads well up to roughly 50 to 100 million vectors per index. Beyond that, purpose-built vector databases scale more gracefully. Instacart stays within this ceiling by structuring indexes per retailer, keeping individual index sizes manageable even as the total catalog runs into the billions.
Workload fit is the other big caveat. Their approach made sense because their data already lived in Postgres, because their team had deep Postgres operational expertise, and because their write workload suited a normalized relational model. A startup with a greenfield system, a read-heavy workload, and a small team might rationally choose a managed vector database like Pinecone. Those teams would be right to do so.
Consolidation is itself a bet. Putting everything in one database means every workload shares the same cluster. Analytical queries, search queries, and transactional writes compete for the same resources, which can create noisy-neighbor problems when the workload balance shifts.
The 2x latency improvement and 10x write reduction belong to Instacart’s workload. Your system will show its own numbers. The principles, though, travel well.
Conclusion
Instacart’s story covers four stages of architecture, each correct at its moment and each eventually needing to be replaced.
When we hear that a specialized tool fits a specialized job, it might not fit every possible scenario. In case of two systems running in sync, measure the real cost of that sync. It is almost always higher than it looks. When your application keeps pulling data in, joining it, and filtering most of it away, ask whether the work belongs closer to the data.
Architecture is a sequence, made one decision at a time.
References:
Great insight ! what a coincidence, I just wrote about it today too, you might take a look at it : https://quentin209.substack.com/p/postgres-vs-elasticsearch-for-hybrid?r=7pgxx7
One caveat I had with this method is that ts_rank and ts_rank_cd methods are not as sharp as BM25 can be within elastic search, and that can be a little confusing first hand
Great breakdown. Search at Instacart is not just keyword matching; it is about intent, ranking, inventory, and real-time product availability. Curious question: what is harder at this scale, showing the most relevant product or keeping results accurate when inventory changes store by store?