
How Large Language Models Learn

Overcome the challenges of deploying LLMs securely and at scale (Sponsored)

To scale with LLMs, you need to know how to monitor them effectively. In this eBook, get practical strategies to monitor, debug, and secure LLM-powered applications. From tracing multi-step workflows and detecting prompt injection attacks to evaluating response quality and tracking token usage, you’ll learn best practices for integrating observability into every layer of your LLM stack.
When we talk about large language models “learning,” we can end up creating a misleading impression. The word “learning” suggests something similar to human learning, complete with understanding, reasoning, and insight.
However, that’s not what happens inside these systems. LLMs don’t learn the way you learned to code or solve problems. Instead, they follow repetitive mathematical procedures billions of times, adjusting countless internal parameters until they become very good at mimicking patterns in text.
This distinction matters more than you might think because it changes the way LLMs generate their answers.
Understanding how LLMs actually work helps you know when to trust their outputs and when to be skeptical. It reveals why they can write convincing essays about topics they don’t fully understand, and why they sometimes fail in surprising ways.
In this article, we’ll explore three core concepts that have a key impact on the working of LLMs: loss functions (how we measure failure), gradient descent (how we make improvements), and next-token prediction (what LLMs actually do).
The Foundation: Loss Functions
Before an LLM can learn anything, we need a way to measure how badly it’s performing. This measurement is called a loss function.
Think of it as a scoring system that provides a single number representing how wrong the model is. The higher the number, the worse the performance. The goal of training is to make this number as small as possible.
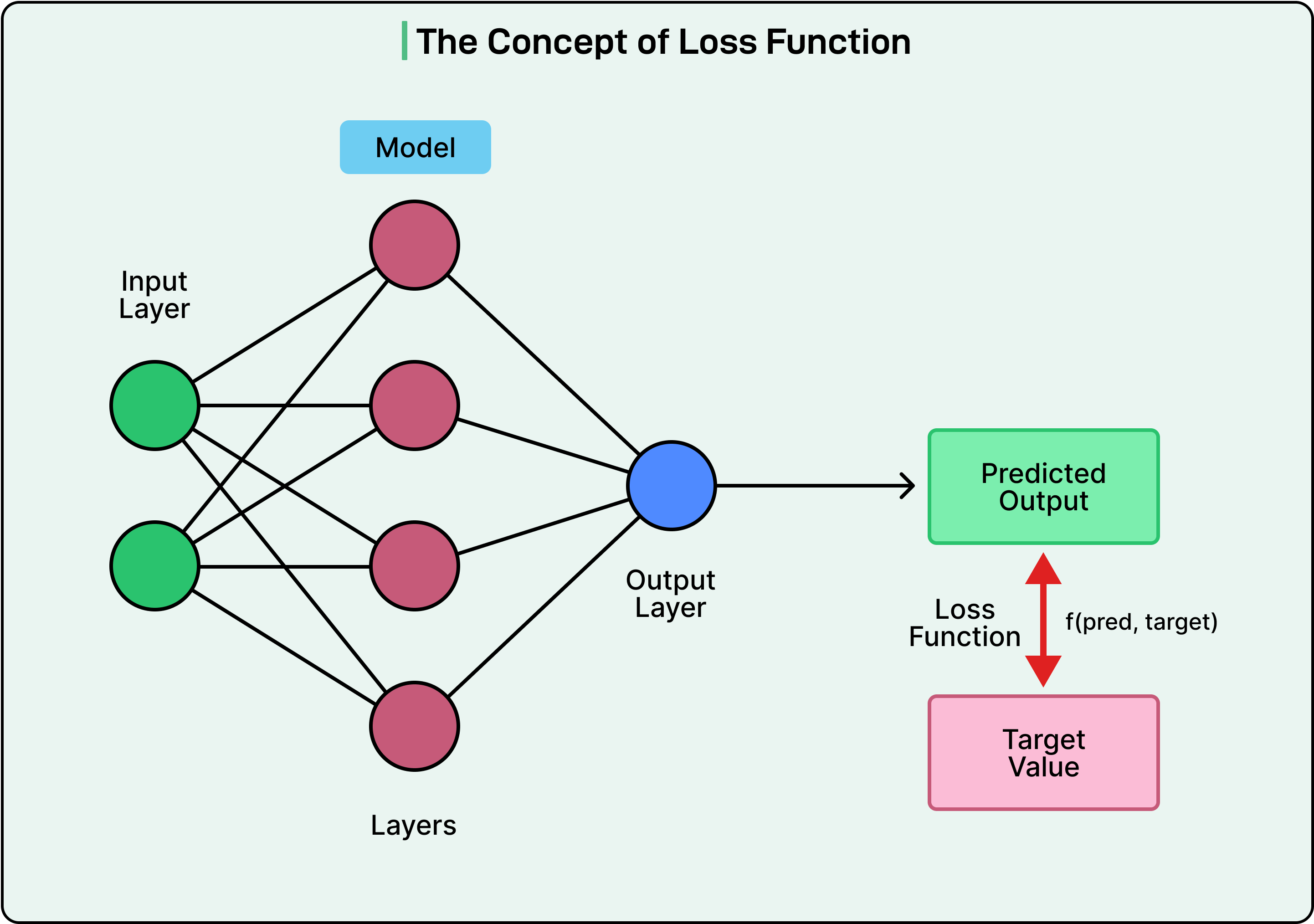
However, you can’t just pick any measurement and expect it to work. A good loss function must satisfy three critical requirements:
First, it must be specific. It needs to measure something concrete and not vague. If someone told you to “build an intelligent computer,” you’d struggle because intelligence itself is hard to define. Would a system that passes an IQ test count? Probably not, since computers have passed IQ tests for over a decade without being useful for much else. For LLMs, we pick something very specific, such as predicting the next word in a sequence correctly. This is concrete and measurable.
Second, the loss function must be computable. The computer needs to calculate it quickly and repeatedly. We can’t measure abstract qualities like “creativity” or “hard work” because these aren’t things you can easily quantify with the data available during training. However, you can measure whether a predicted word matches the actual next word in your training data. That’s a simple comparison that computers handle effortlessly.
Third, the loss function must be smooth. This is the trickiest requirement to grasp. Smoothness means the function’s output should change gradually as inputs change, without sudden jumps or breaks. Imagine walking down a gentle slope versus walking down a staircase. The slope is smooth because your altitude changes continuously. Stairs are not smooth because you suddenly drop from one step to the next.
Why does smoothness matter?
The training algorithm needs to figure out which direction to adjust the model’s parameters. If the loss function jumps around wildly, the algorithm can’t determine whether it’s moving in the right direction. Interestingly, accuracy (counting correct predictions) isn’t smooth because you can’t have partial predictions. You either got 47 or 48 predictions right, not 47.3. This is why LLMs actually optimize for something called cross-entropy loss instead, which is smooth and works better mathematically, even though accuracy is what we ultimately care about.
The crucial point to understand here is that LLMs are scored on matching patterns in their training data, not on being truthful or correct. If false information appears frequently in training data, the model gets rewarded for reproducing it. This fundamental design choice explains why LLMs can confidently state things that are completely wrong.
Unblocked: The context layer your AI tools are missing (Sponsored)

Many developer tools promise context-aware AI, but having data access doesn’t automatically mean agents know when to use it.
Real context requires understanding. Unblocked synthesizes knowledge from your codebase, PRs, discussions, docs, project trackers, and runtime signals. It connects past decisions to current work, resolves conflicts between outdated docs and actual practice, respects data permissions, and surfaces what matters for the task at hand.
With Unblocked:
Coding agents like Cursor, Claude, and Copilot generate output that aligns with your actual architecture and conventions
Code review focuses on real bugs rather than stylistic nits
You find instant answers without interrupting teammates
The Process: Gradient Descent
Once the loss function is decided, we need a process to actually improve the model. This is where gradient descent comes in.
Gradient descent is the algorithm that figures out how to adjust the billions of parameters inside a neural network to reduce the loss.
See the diagram below:
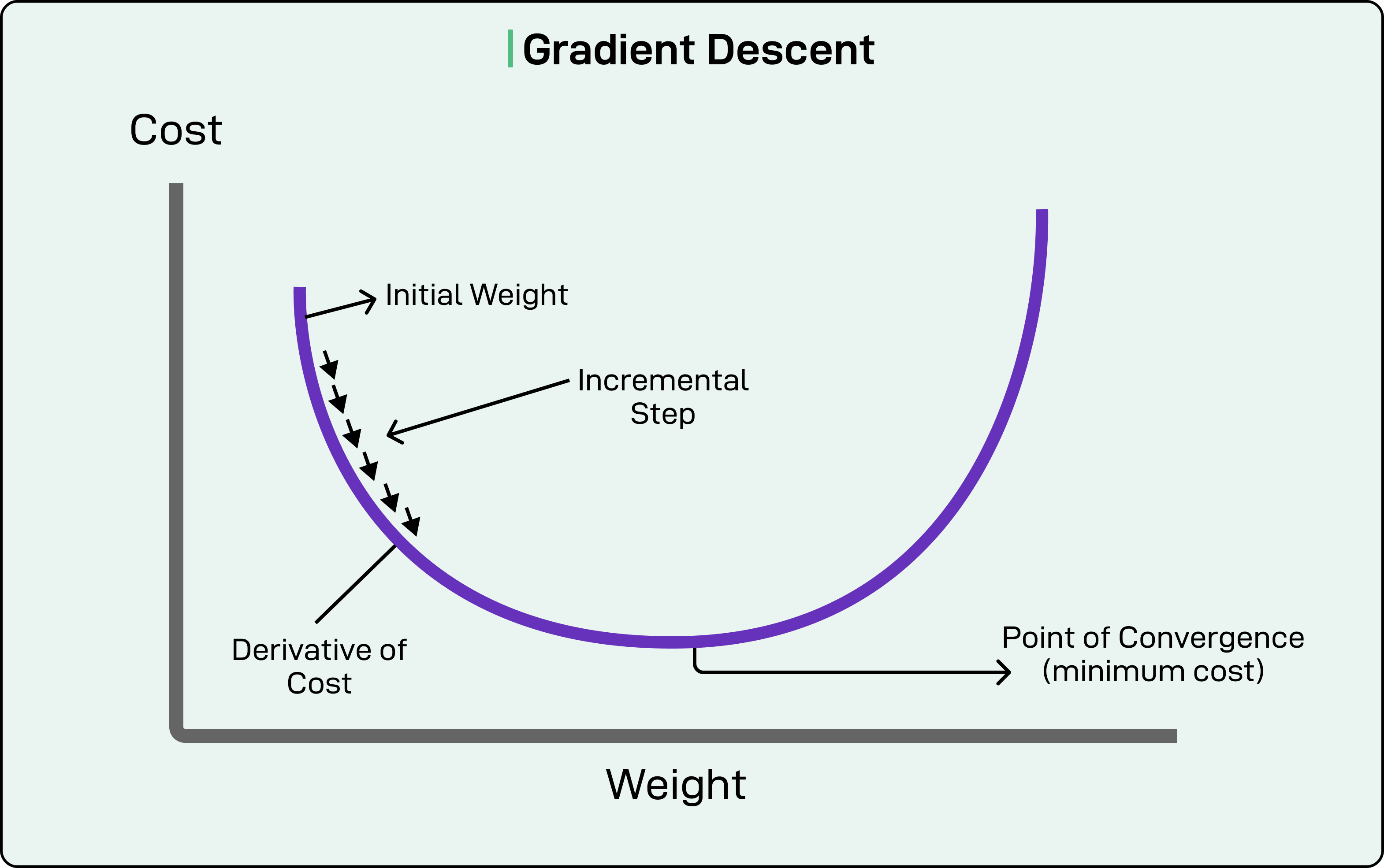
Imagine you have a ball sitting somewhere on a hilly landscape. The ball’s position represents the model’s current parameter values. The height of the ground beneath the ball represents the loss function’s output. Valleys represent low loss (good performance), and peaks represent high loss (bad performance). The goal is to get the ball to the lowest valley possible.
The process follows these steps:
Start with the ball at a random position on the landscape
Look at the slope directly around the ball to determine which direction is downhill
Roll the ball a tiny distance in that downhill direction
Repeat this process billions of times until the ball settles in a valley
Each adjustment is incredibly small. We’re not throwing the ball or making dramatic changes, but nudging it slightly based on the local slope. The “gradient” in gradient descent refers to this slope measurement, which tells you both the direction and steepness of the decline.
This approach uses a greedy algorithm, meaning it only considers the immediate next step without looking ahead. Picture walking downhill in thick fog where you can only see your feet. We can tell which direction slopes downward right where we’re standing, but we can’t see if there’s a deeper valley just beyond a small uphill section. The ball might settle in a minor dip when a much better solution exists nearby.
Why use such a limited approach?
This is because the alternative is computationally impossible. An LLM might have hundreds of billions of parameters. Evaluating all possible future states to find the absolute best solution would take longer than the lifespan of the universe. Gradient descent is practical because each step is simple and cheap to compute, even though we need billions of them.
Modern LLMs use a variation called Stochastic Gradient Descent, or SGD. The word “stochastic” means random. Instead of calculating loss across all your training data at once (which would require impossible amounts of memory), SGD uses small random batches of data. This makes training feasible with massive datasets. If we have a billion training examples, we can take a billion small steps using different random samples, which actually works better than trying to process everything at once.
The LLM Secret: Next-Token Prediction
Now we get to what LLMs actually train on. Despite their ability to write essays, explain concepts, and hold conversations, LLMs are trained on one simple task: predict the next word in a sequence.
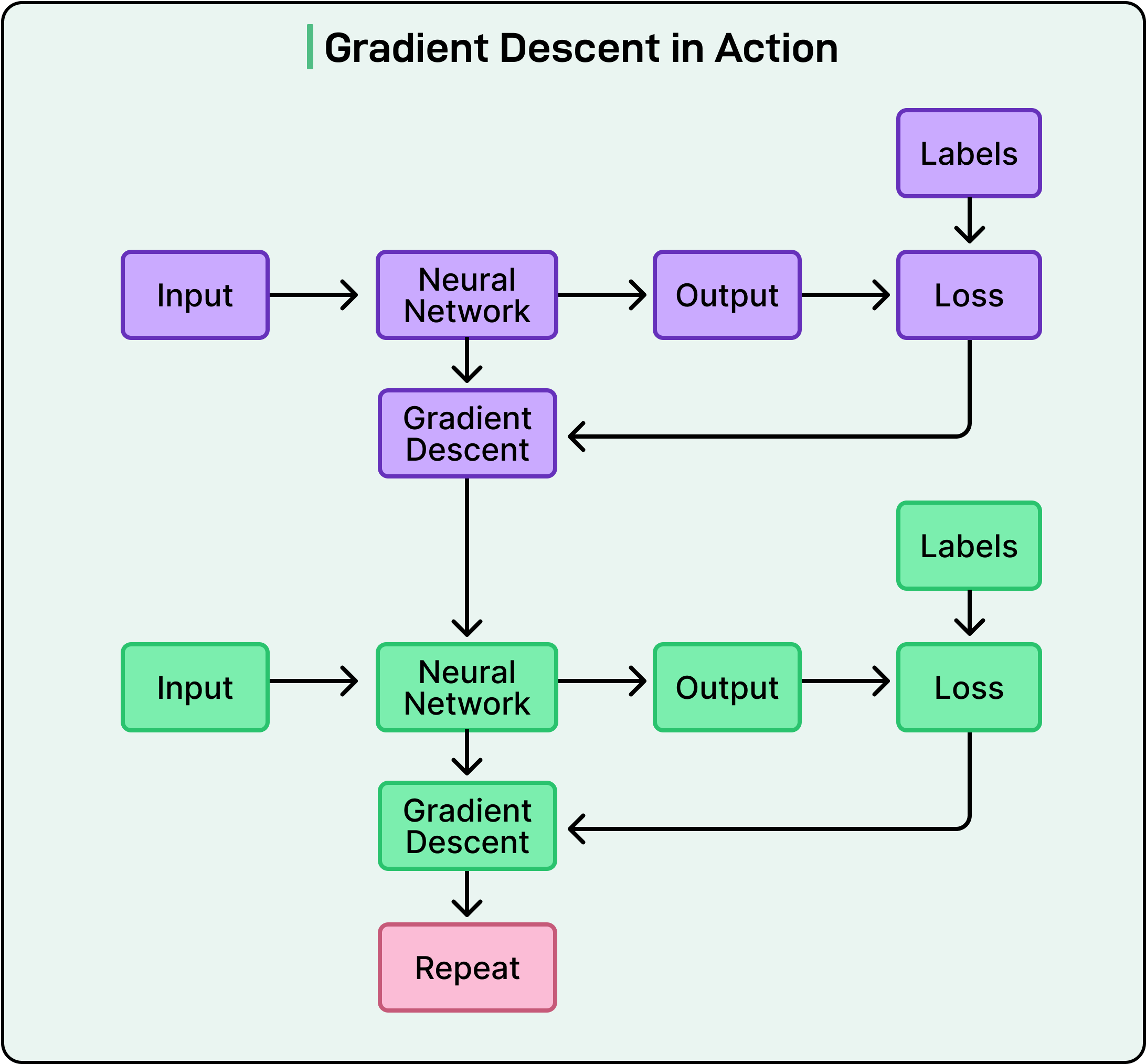
Take the sentence “The cat sat on the mat.” During training, the model doesn’t see the whole sentence at once. Instead, it trains on overlapping segments:
Input: “The” → Predict: “cat” → If correct, gain a point
Input: “The cat” → Predict: “sat” → If correct, gain a point
Input: “The cat sat” → Predict: “on” → If correct, gain a point
Input: “The cat sat on” → Predict: “the” → If correct, gain a point
Input: “The cat sat on the” → Predict: “mat” → If correct, gain a point
This process repeats billions of times across trillions of words from the internet, books, articles, and other text sources. Every time the model predicts correctly, gradient descent adjusts its parameters to make similar predictions more likely in the future. Every time it predicts incorrectly, the parameters adjust to make that mistake less likely.
But why does this simple task produce such convincing outputs? The answer lies in how context narrows down possibilities.
Consider predicting the next word in this sequence: “I love to eat.” Without more context, it could be almost any food. But add more information: “I love to eat something for breakfast.” Now you’re narrowed down to breakfast foods like eggs, cereal, pancakes, or toast. Add even more: “I love to eat something for breakfast with chopsticks.” Now you’re thinking about foods eaten with chopsticks at breakfast, perhaps rice or noodles. Include geography: “I love to eat something for breakfast with chopsticks in Tokyo.” The possibilities narrow further to Japanese breakfast items.
LLMs excel at this pattern recognition because they process billions of these associations during training. They learn which words tend to follow others in different contexts. The more context we provide, the better their predictions become. This is why longer prompts often produce better results.
The transformer architecture that powers modern LLMs has a critical advantage over older approaches. It can process all these training examples in parallel rather than one at a time. This parallelization is why we can now train models on datasets that would take you multiple lifetimes to read. It’s the breakthrough that made current LLMs possible.
Why This Is Amazing But Also Has Problems
Next-token prediction through pattern matching produces impressive results. LLMs can write in different styles, translate languages, explain complex topics, and generate code. They spot subtle patterns across billions of examples that humans would never notice. For most common tasks, this approach works quite well.
However, pattern matching is not reasoning, and this creates predictable failure modes.
Consider what happens when you ask an LLM a question with a false premise. The model doesn’t stop to verify whether the premise is true. Instead, it might pattern-match to find the appropriate answer based on its training data. The answer can sound authoritative and detailed, but it might explain something that isn’t true. In other words, the model is trained to continue patterns in text, but not to fact-check or apply logical reasoning.
This problem extends to situations where training data is scarce. Suppose you ask an LLM to write code in Python. It will likely produce excellent results because massive amounts of Python code exist in its training data. However, ask it to write the same code in an obscure programming language, and it starts making confident mistakes. It might use operators that don’t exist in that language or call functions with the wrong number of arguments. The model extrapolates common programming patterns from popular languages, assuming they apply everywhere. With insufficient training examples to learn otherwise, these extrapolations lead to errors.
Perhaps most tellingly, LLMs fail at variations of problems they’ve seen before. There’s a famous logic puzzle about transporting a cabbage, a goat, and a wolf across a river with specific constraints about which items can’t be left alone together. LLMs solve this puzzle easily because it appears many times in their training data. However, if you slightly modify the constraints, the model often continues using the original solution. It doesn’t reason through the new logical requirements. Instead, it pattern-matches to the familiar puzzle and reproduces the memorized answer.
This happens because of how transformers work internally. When the model sees text that looks very similar to something in its training data, it does a fuzzy match and retrieves the known answer. This is efficient for common problems but fails when those small differences actually matter.
The core issue is that LLMs are optimized to reproduce patterns from their training data, not to be truthful, logical, or correct. When training data contains errors (and internet data contains many), models learn to reproduce those errors. When training data contains biases, models learn those too. When a task requires actual reasoning rather than pattern matching, the illusion can break down.
Conclusion
Understanding the mechanics of LLM training helps you use these tools more effectively.
LLMs are sophisticated pattern-matching systems that predict tokens through billions of small parameter adjustments. They’re not reasoning engines, and they don’t truly understand the text they generate.
This knowledge suggests several practical guidelines:
Use LLMs for tasks that are well-represented in their training data. They excel at common programming problems, generating content in standard formats, and answering frequently asked questions. They’re powerful productivity tools that can save enormous amounts of time on routine work.
However, be skeptical when dealing with novel problems, unusual edge cases, or domains where accuracy is critical.
Always verify outputs for important use cases. Don’t assume that confident-sounding responses are correct. The training process optimizes for sounding like training data, not for being right.
Most importantly, remember that LLMs are tools with specific capabilities and specific limitations. They’re remarkable at what they do, which is identifying and reproducing patterns in text. However, pattern matching, no matter how sophisticated, is not the same as reasoning, understanding, or intelligence. Knowing this difference helps you leverage their strengths while avoiding their weaknesses.
Excellent breakdown of how LLMs actually “learn”...especially the emphasis on loss functions and next-token prediction over true reasoning. The distinction between pattern matching and understanding is critical, and this piece explains it in a way that’s both technically accurate and accessible.
Human doesn’t learn by repetitive & feedback too ? Just curious.