
How LinkedIn Feed Uses LLMs to Serve 1.3 Billion Users

How to stop babysitting your agents (Sponsored)

Agents can generate code. Getting it right for your system, team conventions, and past decisions is the hard part. You end up babysitting the agent and watch the token costs climb.
More MCPs, rules, and bigger context windows give agents access to information, but not understanding. The teams pulling ahead have a context engine to give agents only what they need for the task at hand.
Join us for a FREE webinar on April 23 to see:
Where teams get stuck on the AI maturity curve and why common fixes fall short
How a context engine solves for quality, efficiency, and cost
Live demo: the same coding task with and without a context engine
If you want to maximize the value you get from AI agents, this one is worth your time.
LinkedIn used to run five separate systems just to decide which posts to show you. One tracked trending content. Another did collaborative filtering. A third handled embedding-based retrieval.
Each had its own infrastructure, its dedicated team, and its own optimization logic. The setup worked, but when the Feed team wanted to improve one part, they’d break another. Therefore, they made a radical bet and ripped out all five systems, replacing them with a single LLM-powered retrieval model. That solved the complexity problem, but it raised new questions, such as:
How do you teach an LLM to understand structured profile data?
How do you make a transformer serve predictions in under 50 milliseconds for 1.3 billion users?
How do you train the model when most of the data is noise?
In this article, we will look at how the LinkedIn engineering team rebuilt the Feed and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the LinkedIn Engineering Team. Please comment if you notice any inaccuracies.
Five Librarians, One Library
For years, LinkedIn’s Feed retrieval relied on what engineers call a heterogeneous architecture. When you opened the Feed, content came from multiple specialized sources running in parallel.
A chronological index of network activity.
Trending posts by geography.
Collaborative filtering based on similar members.
Industry-specific pipelines.
Several embedding-based retrieval systems.
Each maintained its own infrastructure, index structure, and optimization strategy.
See the diagram below:
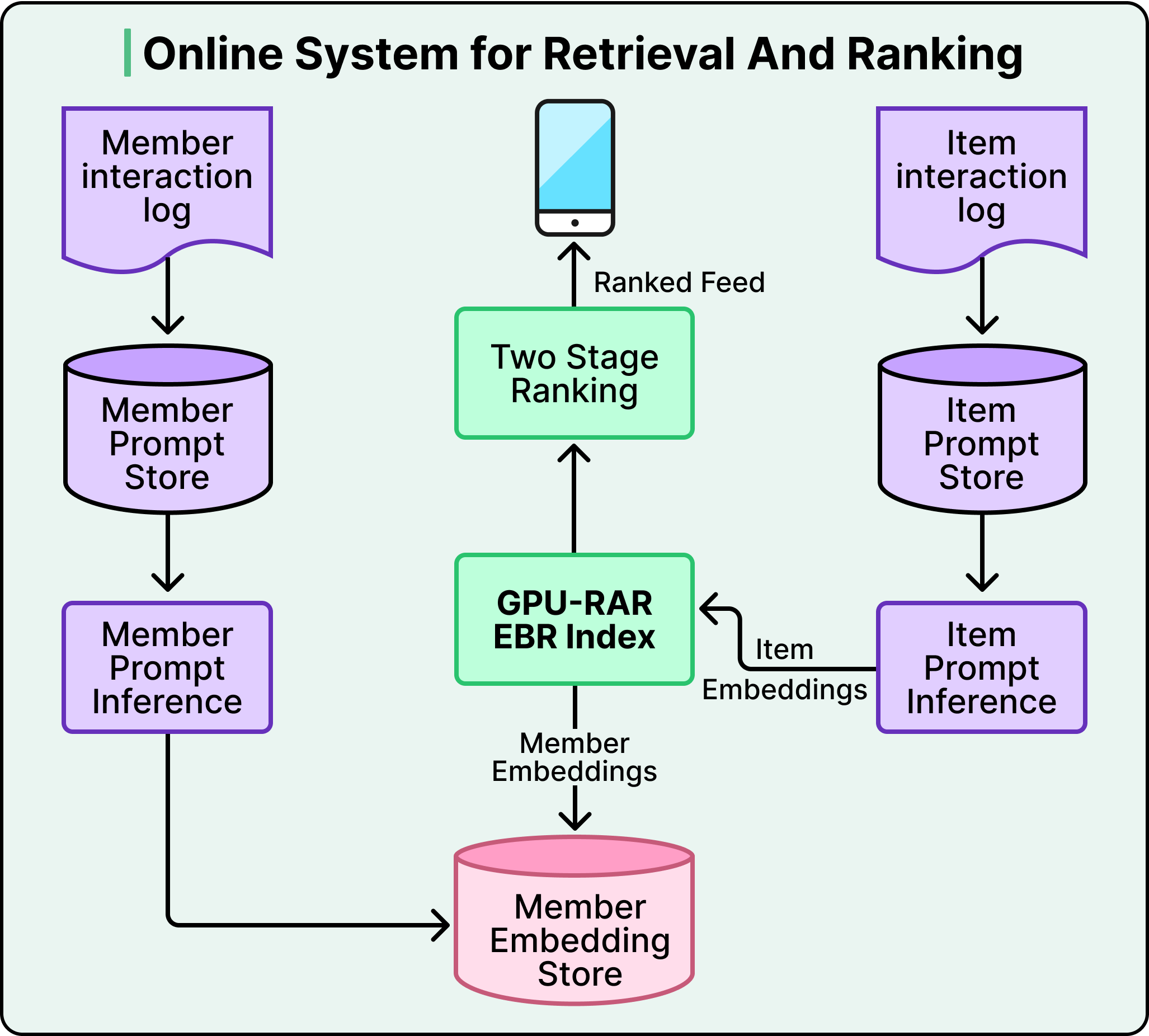
This architecture surfaced diverse, relevant content. But optimizing one retrieval source could degrade another, and no team could tune across all sources simultaneously. Holistic improvement was nearly impossible.
So the Feed team asked a simple question. What if they replaced all of these sources with a single system powered by LLM-generated embeddings?
Under the hood, this works through a dual encoder architecture. A shared LLM converts both members and posts into vectors in the same mathematical space. The training process pushes member and post representations close together when there’s genuine engagement, and pulls them apart when there isn’t. When you open your Feed, the system fetches your member embedding and runs a nearest-neighbor search against an index of post embeddings, retrieving the most relevant candidates in under 50 milliseconds.
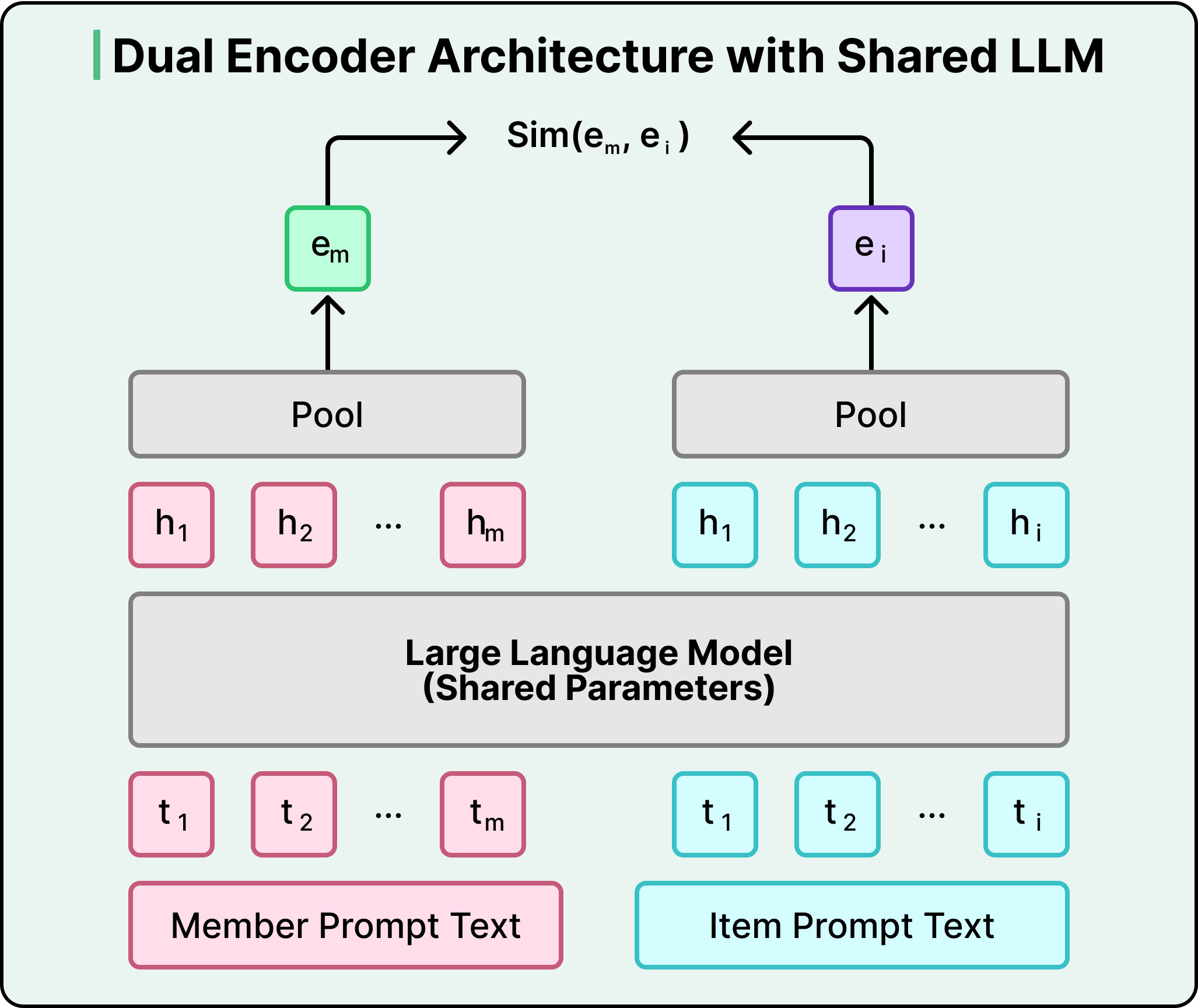
However, the real power comes from what the LLM brings to those embeddings. Traditional keyword-based systems rely on surface-level text overlap. If your profile says “electrical engineering” and a post is about “small modular reactors,” a keyword system misses the connection.
An LLM-based system understands that these topics are related because the model carries world knowledge from pretraining. It knows that electrical engineers often work on power grid optimization and nuclear infrastructure. This is especially powerful for cold-start scenarios, when a new member joins with just a profile headline. The LLM can infer likely interests without waiting for engagement history to accumulate.
The downstream benefits compounded the benefits. Instead of receiving candidates from disparate sources with different biases, the ranking layer now receives a coherent candidate set selected through the same semantic similarity. Ranking became easier, and each optimization to the ranking model became more effective.
But replacing five systems with one LLM created a new problem. LLMs expect text, and recommendation systems run on structured data and numbers.
The Model Is Only As Good As Its Input
To feed structured data into an LLM, LinkedIn built a “prompt library” that transforms structured features into templated text sequences. For posts, it includes author information, engagement counts, and post text. For members, it incorporates profile information, skills, work history, and a chronologically ordered sequence of posts they’ve previously engaged with. Think of it as prompt engineering for recommendation systems.
The most striking example is what happened with numerical features. Initially, LinkedIn passed raw engagement counts directly into prompts. For example, a post with 12,345 views would appear as “views:12345” in the text. The model treated those digits like any other text tokens. When the team measured the correlation between item popularity counts and embedding similarity scores, they found it was essentially zero (-0.004). Popularity is one of the strongest relevance signals in recommendation. And the model was completely ignoring it.
The problem is fundamental. LLMs don’t understand magnitude. They process “12345” as a sequence of digit tokens, not as a quantity.
The fix was quite simple. Instead of passing raw counts, LinkedIn converted them into percentile buckets wrapped in special tokens. This meant that “Views:12345” became <view_percentile>71</view_percentile>, indicating this post sits in the 71st percentile of view counts. Most values between 1 and 100 get processed by the LLM as a single unit rather than a multi-digit sequence, giving the model a stable, learnable vocabulary for quantity. The model can learn that anything above 90 means “very popular” without trying to parse arbitrary digit sequences.
The correlation between popularity features and embedding similarity jumped 30x. Recall@10, which measures whether the top 10 retrieved posts are actually relevant, improved by 15%. LinkedIn applied the same strategy to engagement rates, recency signals, and affinity scores.
Less Data, Better Model
When building the member’s interaction history for training, LinkedIn initially included everything. Every post that was shown to a member went into the sequence, whether they engaged with it or scrolled past. The idea was that more data should mean a better model.
However, this didn’t turn out to be the case. Including scrolled-past posts not only made model performance worse, but it also made training significantly more expensive. GPU compute for transformer models scales quadratically with context length.
When the team filtered to include only positively-engaged posts, the results improved across every dimension.
Memory footprint per sequence dropped by 37%.
The system could process 40% more training sequences per batch.
Training iterations ran 2.6x faster
The reason comes down to signal clarity. A scrolled-past post is ambiguous. Maybe the post was irrelevant. Maybe the member was busy. Maybe the headline was mildly interesting, but not enough to stop for. Posts you actively chose to engage with are a much cleaner learning target.
The gains compounded due to this change. Better signal quality meant faster training. Faster training meant more experimentation. More experimentation meant better hyperparameter tuning. When a single change improves both quality and efficiency, the benefits multiply through the entire development cycle.
The training strategy had one more clever element. LinkedIn used two types of negative examples:
Easy negatives were randomly sampled posts never shown to a member, providing a broad contrastive signal.
Hard negatives were posts actually shown but not engaged with, the almost-right cases where the model must learn nuanced distinctions between relevant and genuinely valuable.
The difficulty of the negative examples shapes what the model learns. Easy negatives teach broad distinction, whereas hard negatives teach the fine-grained ones. Using both together is a common and effective pattern across retrieval systems, and at LinkedIn, adding just two hard negatives per member improved recall by 3.6%.
With retrieval producing high-quality candidates, the next question was how to rank them. LinkedIn’s answer was to stop treating each post as an isolated decision.
The Feed Is a Story, Not a Snapshot
Traditional ranking models evaluate each member-post pair independently. This works, but it misses something fundamental about how professionals consume content.
LinkedIn built a Generative Recommender (GR) model that treats your Feed interaction history as a sequence. Instead of scoring each post in isolation, GR processes more than a thousand of a user’s historical interactions to understand temporal patterns and long-term interests.
The practical difference matters. If the user engages with machine learning content on Monday, distributed systems on Tuesday, and opens LinkedIn again on Wednesday, a sequential model understands these aren’t random events. They’re the continuation of a learning trajectory. A traditional pointwise model sees three independent decisions, whereas the sequential model sees the story.
The GR model uses a transformer with causal attention, meaning each position in the history can only attend to previous positions, mirroring how you actually experienced content over time. Recent posts might matter more for predicting immediate interests, but a post from two weeks ago might suddenly become relevant if recent activity suggests renewed interest.
See the diagram below that shows the transformer architecture:
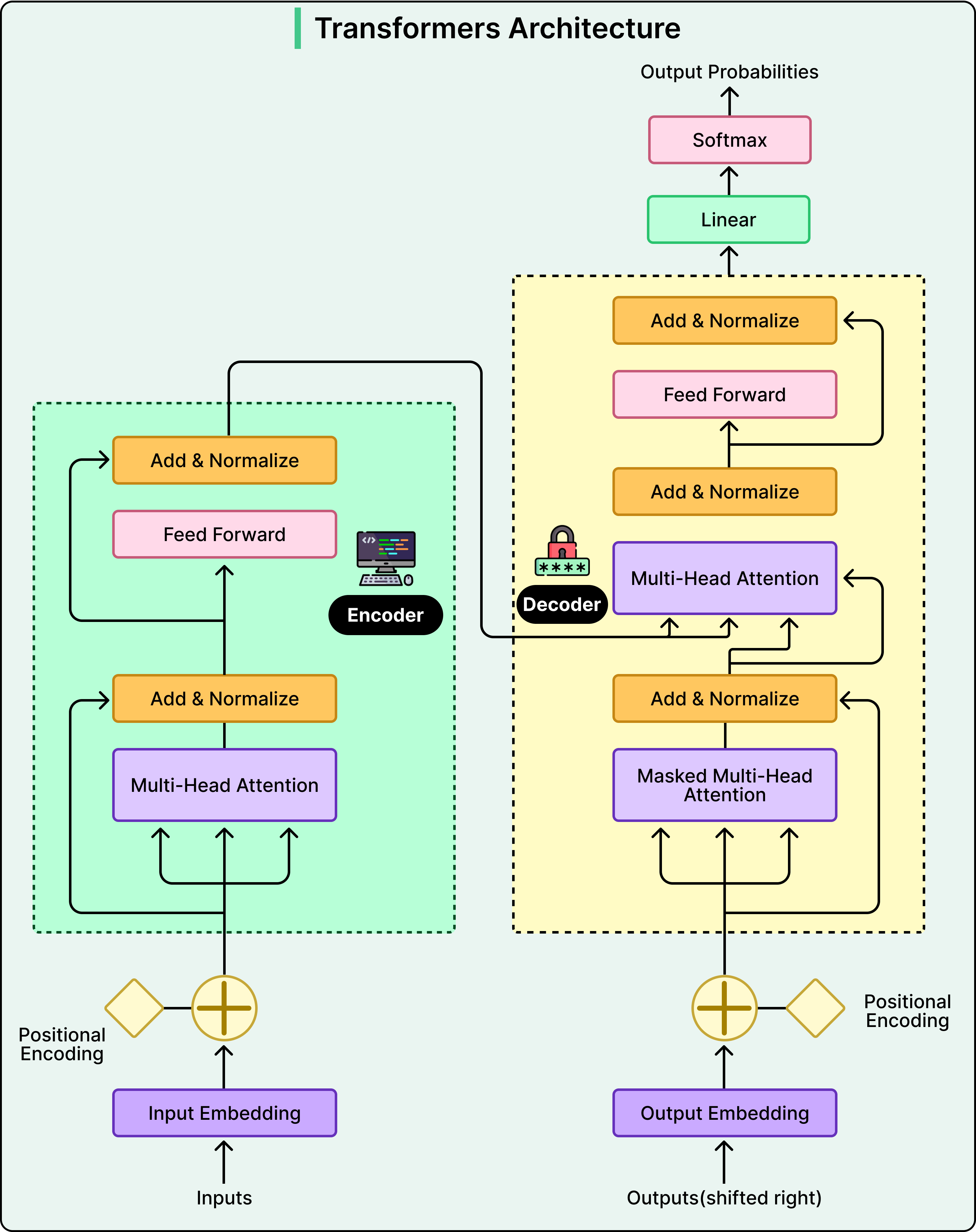
One of the most practical architectural decisions is what LinkedIn calls late fusion. Not every feature benefits from full self-attention. Count features and affinity signals carry a strong independent signal, and running them through the transformer would inflate computational cost quadratically without clear benefit. Instead, these features are concatenated with the transformer output after sequence processing. This results in rich sequential understanding from the transformer, plus contextual signals that drive relevance, without the cost of processing them through self-attention.
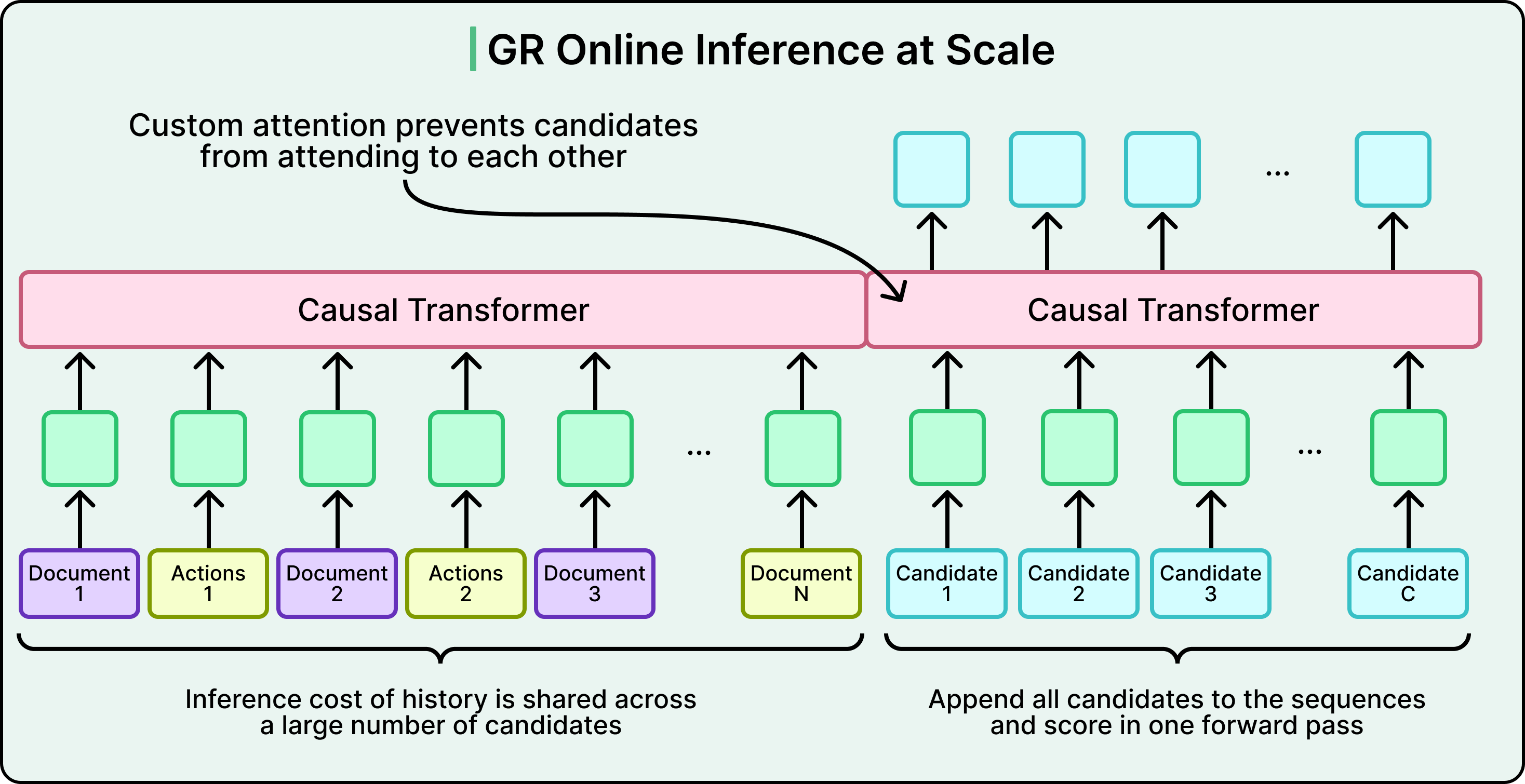
The serving challenge is equally important. Processing 1,000+ historical interactions through multiple transformer layers for every ranking request is expensive. LinkedIn’s solution is shared context batching. The system computes the user’s history representation once, then scores all candidates in parallel using custom attention masks.
On top of the transformer, a Multi-gate Mixture-of-Experts (MMoE) prediction head routes different engagement predictions like clicks, likes, comments, and shares through specialized gates while sharing the same sequential representations underneath.
See the diagram below that shows a typical Mixture-of-Experts architecture.
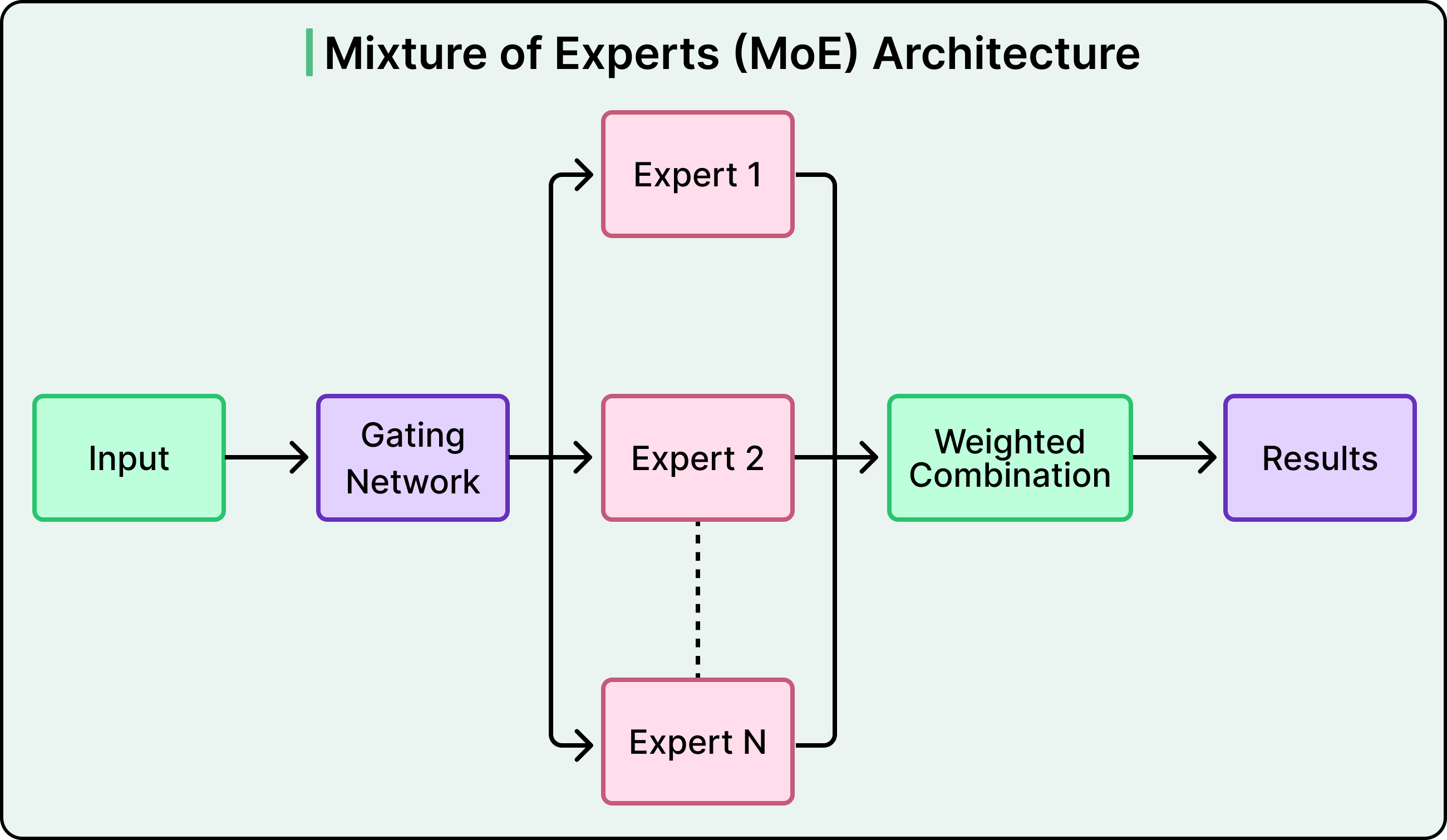
This lets the model handle multiple prediction tasks without duplicating the expensive transformer computation. Together, shared context batching and the MMoE head are what make the sequential model viable at production scale.
Making It All Work at Scale
Even the best model is useless without the infrastructure to serve it. LinkedIn’s historical ranking models ran on CPUs. Transformers are fundamentally different, with self-attention scaling quadratically with sequence length and massive parameter counts requiring GPU memory. At LinkedIn’s scale, cost-per-inference determines whether sophisticated AI models can serve every member, or only high-engagement users.
The team invested heavily in custom infrastructure on both sides. For training, a custom C++ data loader eliminates Python’s multiprocessing overhead, custom GPU routines reduced metric computation from a bottleneck to negligible overhead, and parallelized evaluation across all checkpoints cut pipeline time substantially. For serving, a disaggregated architecture separates CPU-bound feature processing from GPU-heavy model inference, and a custom Flash Attention variant called GRMIS delivered an additional 2x speedup over PyTorch’s standard implementation.
See the diagram below that shows the GR Infrastructure Stack
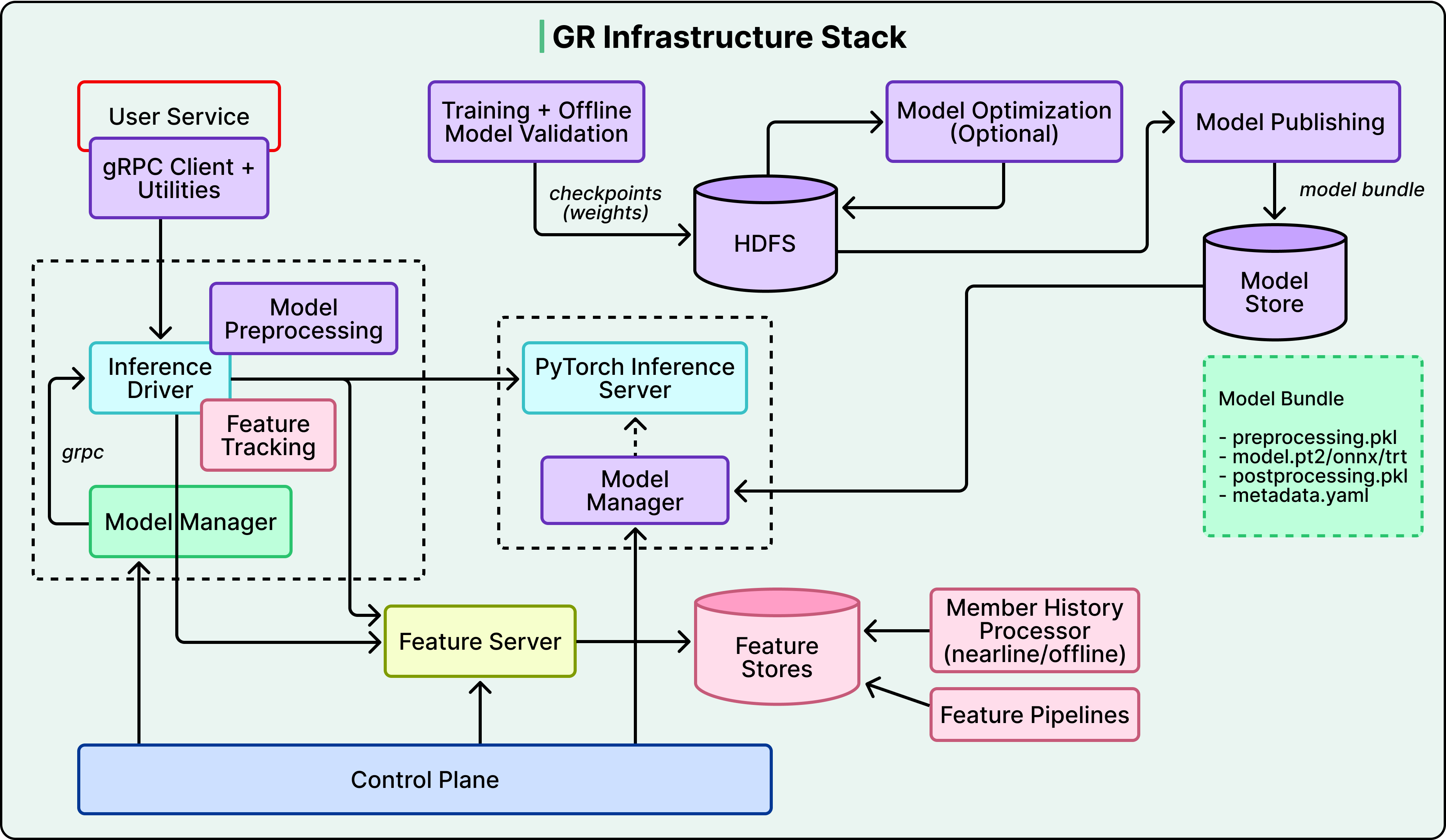
Freshness required its own solution.
Three continuously running background pipelines keep the system current, capturing platform activity, generating updated embeddings through LLM inference servers, and ingesting them into a GPU-accelerated index.
Each pipeline optimizes independently, while the end-to-end system stays fresh within minutes. LinkedIn’s models are also regularly audited to ensure posts from different creators compete on an equal footing, with ranking relying on professional signals and engagement patterns, never demographic attributes.
Conclusion
There are some takeaways:
Replacing five retrieval systems with one trades resilience for simplicity.
LLM-based embeddings are richer but more expensive than lightweight alternatives.
The bottleneck is rarely the model architecture. It’s everything around it.
The infrastructure investment represents an effort most teams can’t replicate. And this approach leans on LinkedIn’s rich text data. For primarily visual platforms, the calculus would be different.
The next time you open LinkedIn and see a post from someone you don’t follow, on a topic you didn’t search for, but it’s exactly what you needed to read, that’s all of this working together under the hood.
References:
Consolidating five retrieval sources into one LLM-based system is elegant but I'd love to hear more about the failure modes. Five specialized systems gave you independent optimization surfaces and natural redundancy.
When the unified model regresses on something like cold-start or trending content, what's the rollback story?
Interesting...