
How LLMs See Images, Audio, and More

Data Streaming + AI: Shaping the Future Together (Sponsored)

Join us at the Data Streaming + AI Summit on Sept 30, 2025 at the Grand Hyatt at SFO — the most open data streaming conference bringing together leaders from OpenAI, Netflix, Uber, Google, Salesforce, LinkedIn, Blueshift, Confluent, Ververica, StreamNative, and more. Hear keynote insights from Reynold Xin (Co-founder & Chief Architect, Databricks), learn how OpenAI powers AI with real-time streaming, and explore 30+ technical sessions across four tracks. On September 29, level up your skills with Data Streaming Fundamentals Training (for beginners) or dive deeper with the Hands-On Streaming Lakehouse Workshop (advanced, in partnership with AWS).
🎟️ Use code BBG50 for 50% off conference tickets.
Language models are no longer limited to text. Today's AI systems can understand images, process audio, and even handle video, but they still need to convert everything into tokens first. Just like how "Hello world!" becomes discrete tokens for text processing, a photograph gets chopped into image patches, and a song becomes a sequence of audio codes.
This is Part 2 of the ByteByteGo LLM Tokenization Series. You can view Part 1 here.
Each type of media requires completely different tokenization strategies, each with unique trade-offs between quality, efficiency, and semantic understanding.
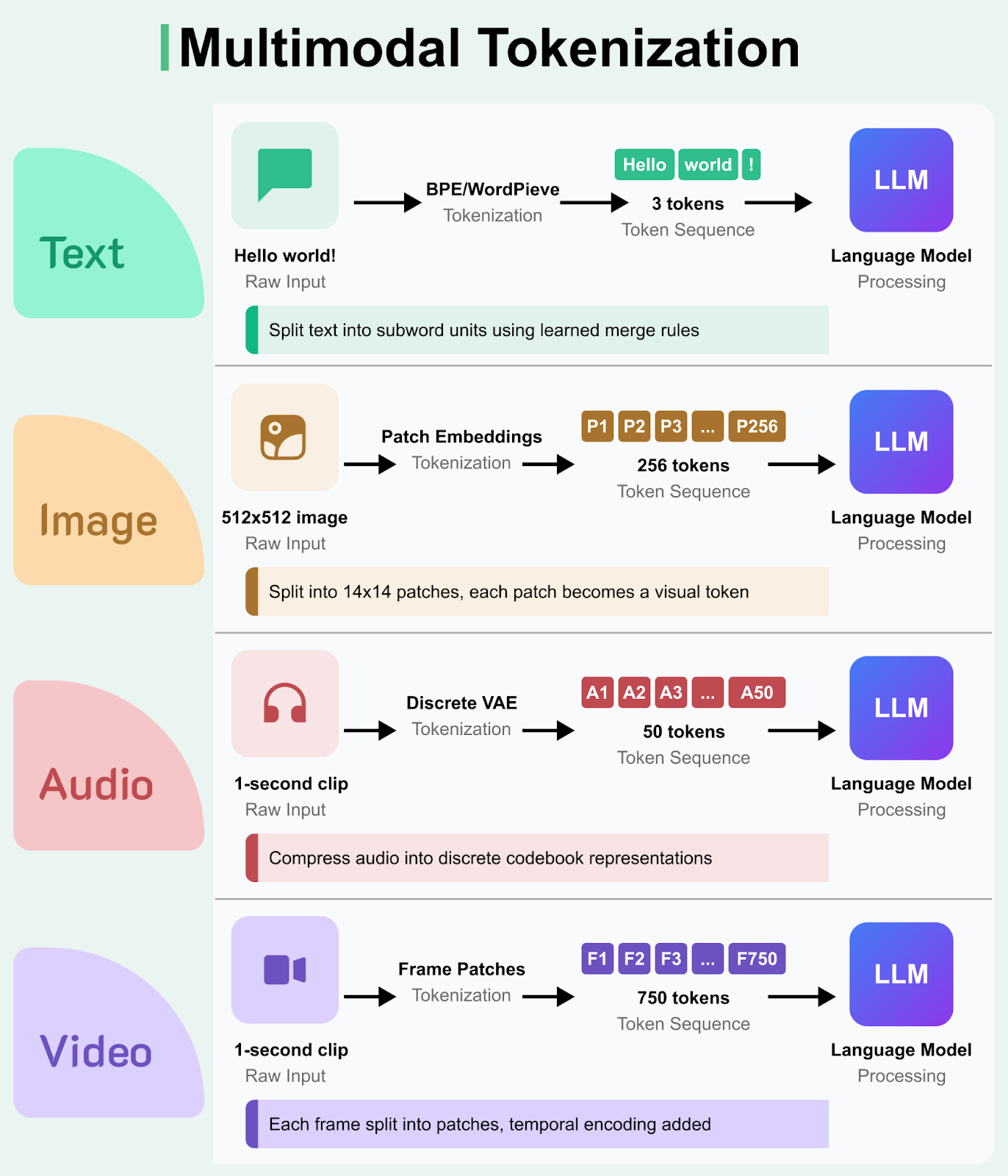
As models extend beyond pure text, multimodal tokenization lets them ingest images, audio, and video alongside natural language. While the core idea of mapping raw input into a discrete sequence remains the same, each modality uses a different strategy.
Image Tokenization
Image tokenization transforms visual data into discrete tokens that can be processed by LLMs. Unlike text, which naturally exists as discrete symbols, images are continuous pixel arrays that require conversion into token sequences.
Main Approaches to Image Tokenization
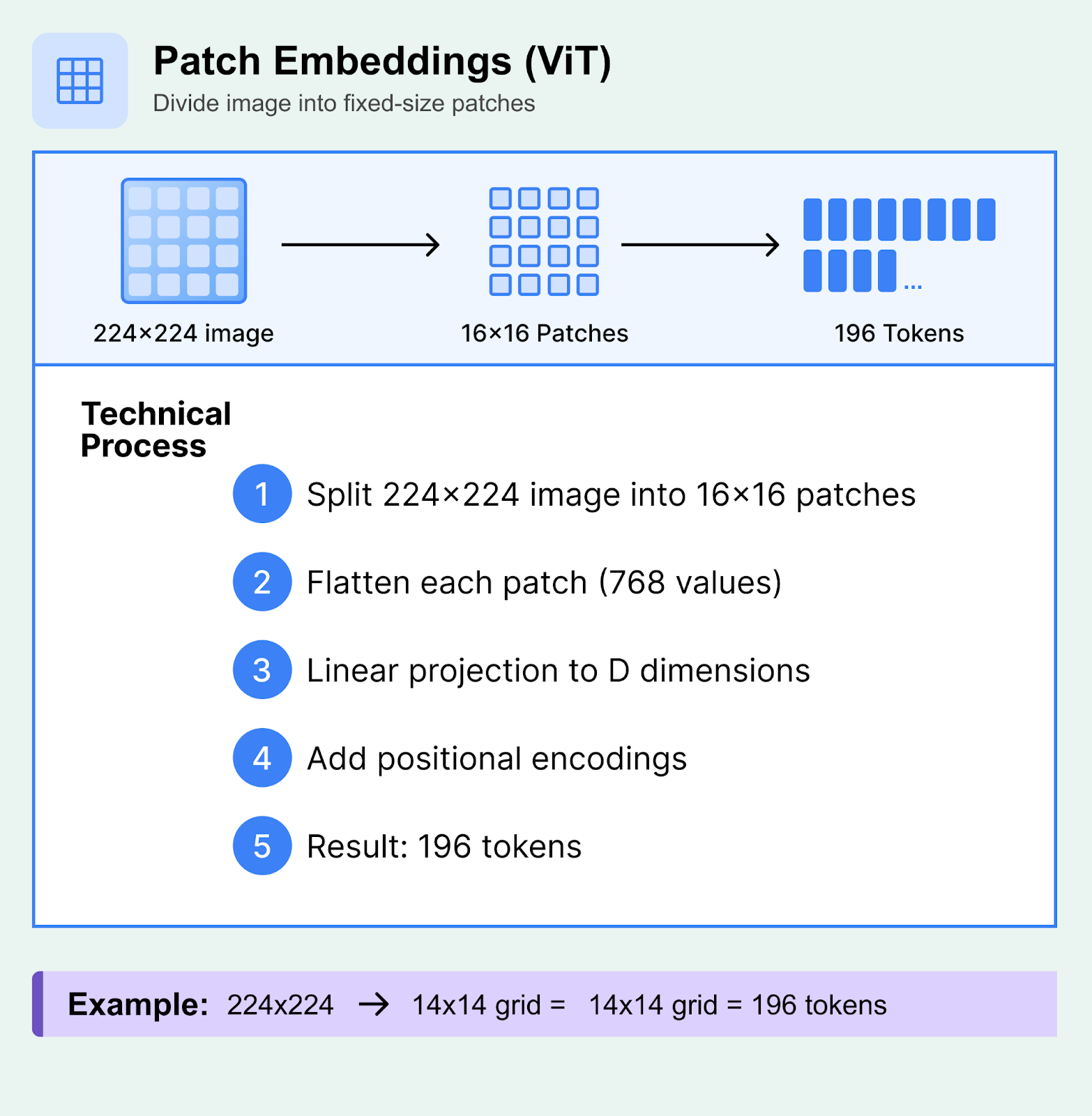
1. Patch Embeddings (Vision Transformer Style)
Patch embeddings divide images into fixed-size, non-overlapping “patches”. Each patch is treated as a single token, similar to how words function in text sequences. This allows the image to be processed into understandable units, just like text tokens.
Technical Process:
An input image (e.g., 224×224 pixels) is divided into patches of size P×P (commonly 16×16 or 14×14)
Each patch contains P²×C values (where C is the number of channels, typically 3 for RGB)
These pixel values are flattened and linearly projected through a learned embedding matrix to create a D-dimensional vector
Positional encodings are added to preserve spatial relationships between patches
The result is a sequence of N tokens, where N = (H×W)/(P²)
What to know:
Advantages: Simple, preserves spatial structure, works well with standard transformer architectures
Limitations: Fixed patch size may not align with natural object boundaries, can be inefficient for high-resolution images
Typical Applications: Image classification, object detection, general computer vision tasks
Example: A 224×224 image with 16×16 patches yields 196 tokens (14×14 grid).
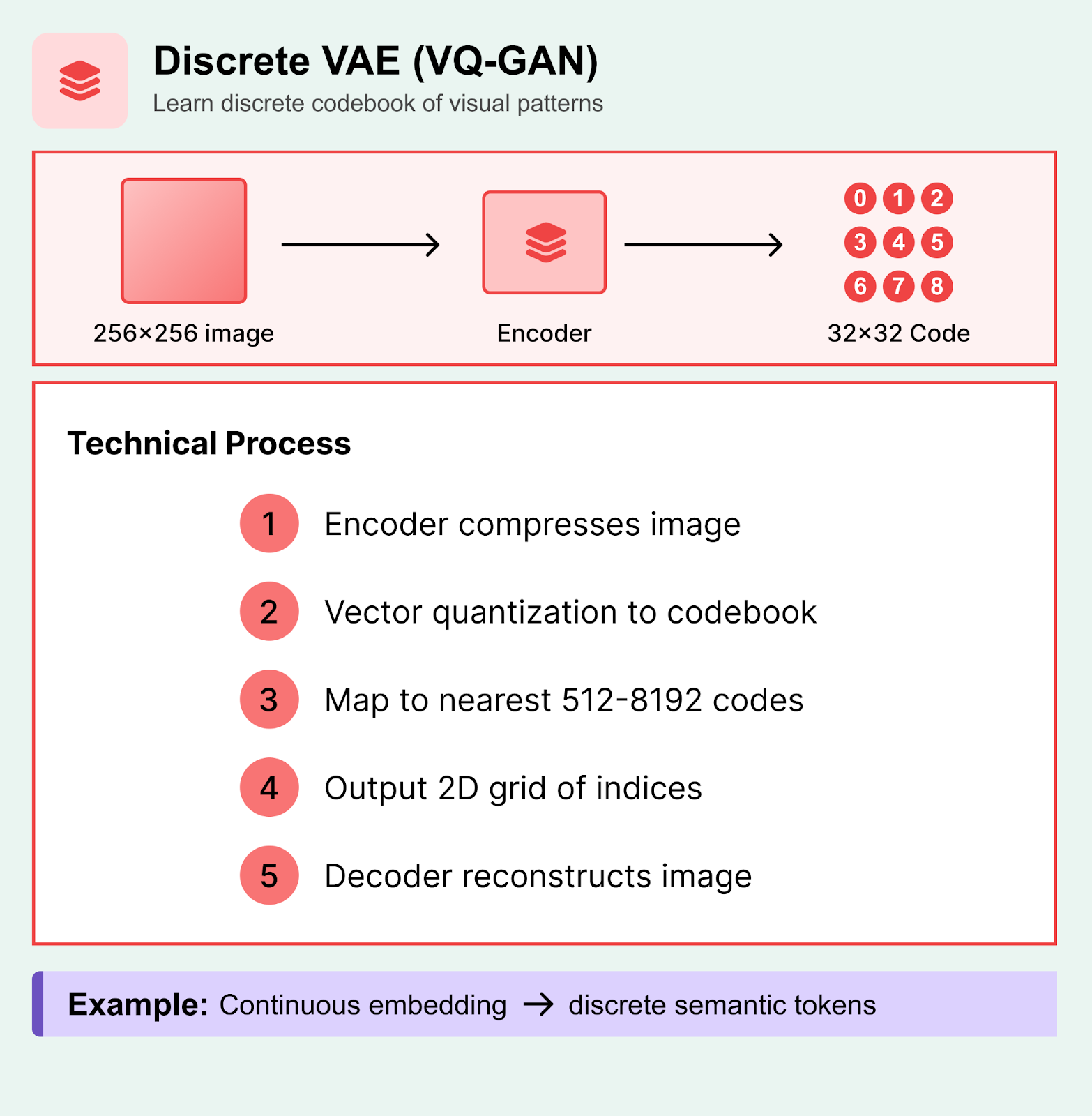
2. Discrete VAE and Vector Quantization
Vector quantization is like creating a visual dictionary. It converts values into “buckets” so that AI can pattern match image parts into buckets.
Technical Process:
An encoder network compresses the input image into a smaller, more manageable representation
The system then matches each part of this compressed image to the closest pattern in its learned "visual vocabulary"
This vocabulary typically contains 512-8,192 different visual patterns (like textures, shapes, or color combinations)
The result is a grid of pattern numbers - for example, a 32×32 grid of codes that represents a 256×256 pixel image
A decoder network can recreate the original image by looking up each code and reconstructing the corresponding visual pattern
Variants (remove?):
VQ-VAE: Basic vector quantization with straight-through gradient estimation
VQ-GAN: Adds adversarial training for better reconstruction quality
RQ-VAE: Uses multiple quantization layers for hierarchical representations
What to know:
Advantages: True discrete tokens, excellent compression ratios
Limitations: Requires pre-training the codebook, potential information loss during quantization
Typical Applications: Image generation, image compression, multimodal language models
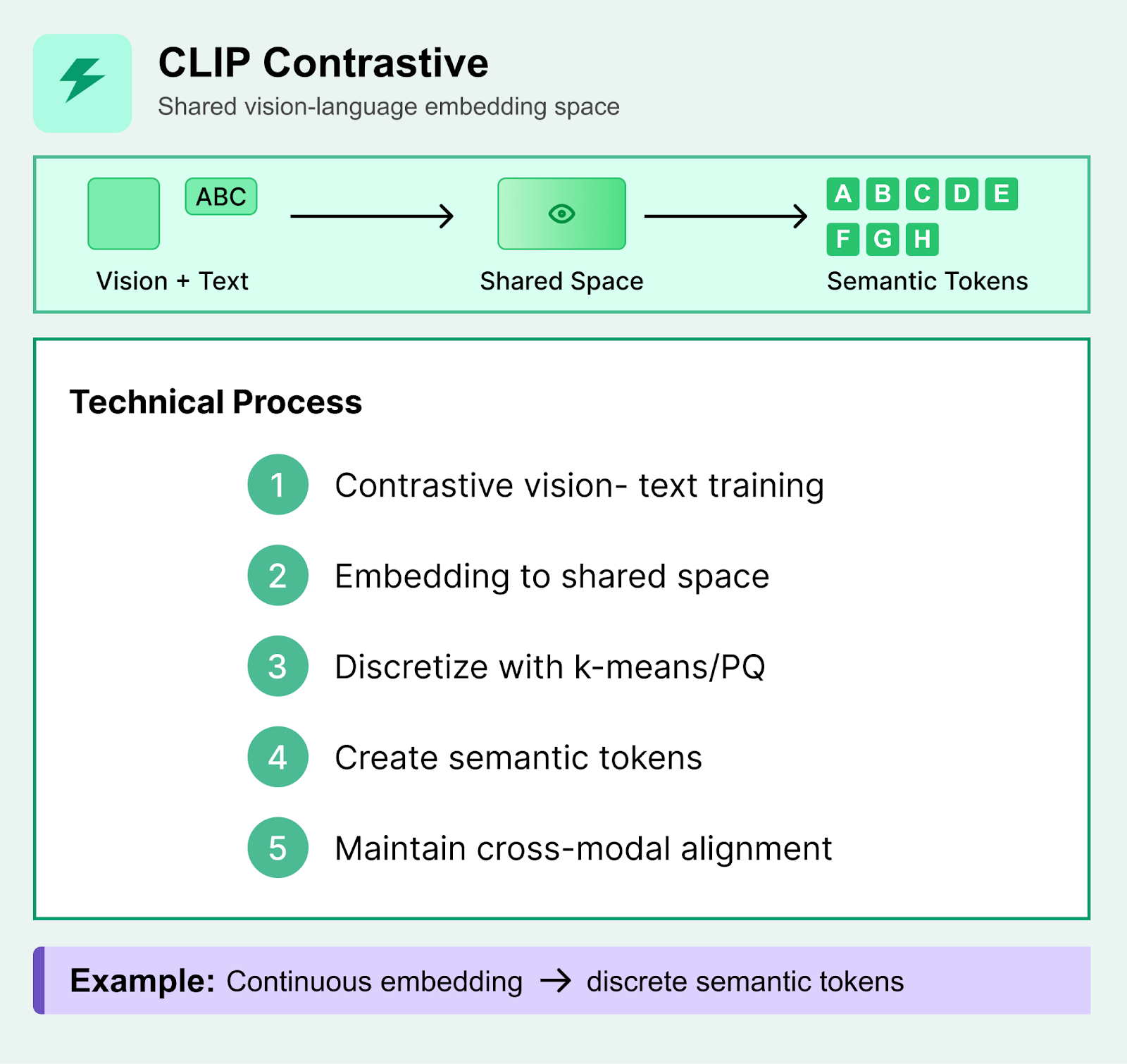
3. CLIP-Style Contrastive Embeddings
Contrastive learning approaches like CLIP create embeddings in a shared vision-language space, which can then be discretized into pseudo-tokens for downstream tasks.
Technical Process:
Images and text are embedded into a shared high-dimensional space through contrastive learning
The continuous embeddings capture semantic relationships between visual and textual concepts
Discretization techniques (k-means clustering, product quantization, or learned codebooks) convert continuous embeddings into discrete tokens
These tokens maintain semantic meaning while being compatible with discrete sequence models
What to know:
Advantages: Semantically meaningful tokens, natural vision-language alignment, transferable across tasks
Limitations: Requires large-scale contrastive pre-training, discretization may lose fine-grained details
Typical Applications: Multimodal retrieval, vision-language understanding, cross-modal generation
Trade-offs to Know
Each tokenization approach has important design decisions to be aware of that impact performance, efficiency, and applicability:
Computational Efficiency:
Patch size directly affects sequence length and computational cost
Smaller patches (8×8) preserve more detail but create longer sequences
Larger patches (32×32) are more efficient but may lose fine-grained information
Token count impacts transformer attention complexity (quadratic scaling)
Information Preservation vs Compression:
Higher compression ratios reduce token count but may lose visual details
VQ-based methods offer excellent compression but require careful codebook design
Patch embeddings preserve all information but with minimal compression
The choice depends on whether perfect reconstruction is necessary for your task
Audio Tokenization
Audio tokenization converts continuous audio waveforms into discrete tokens that can be processed by sequence models. Unlike text or images, audio has unique challenges due to its temporal nature, high sampling rates, and the need to preserve both semantic content and acoustic properties like prosody, timbre, and speaker characteristics.
Main Approaches to Audio Tokenization
1. Codec Tokens (Neural Audio Codecs)
Neural audio codecs like EnCodec and SoundStream compress audio into token sequences while preserving quality. They map audio features to a finite set of learned codes using something called “vector quantization.”
Technical Process:
Audio is segmented into overlapping windows (typically 10-25 ms)
An encoder network converts each window into a continuous feature representation
Vector quantization maps features to the nearest codebook entry (typically 1024-4096 codes)
Multiple quantization layers create hierarchical representations
The result is a sequence of discrete tokens at ~50-75 Hz (much lower than original audio sampling rate)
Models:
EnCodec: Facebook's codec with residual vector quantization, achieving high compression ratios
SoundStream: Google's approach with efficient temporal modeling
What to know:
Advantages: Preserves acoustic properties, enables high-quality reconstruction, suitable for music and speech
Limitations: Requires pre-trained codec models, may introduce artifacts at very low bitrates
Applications: Audio generation, compression, music synthesis, speech synthesis

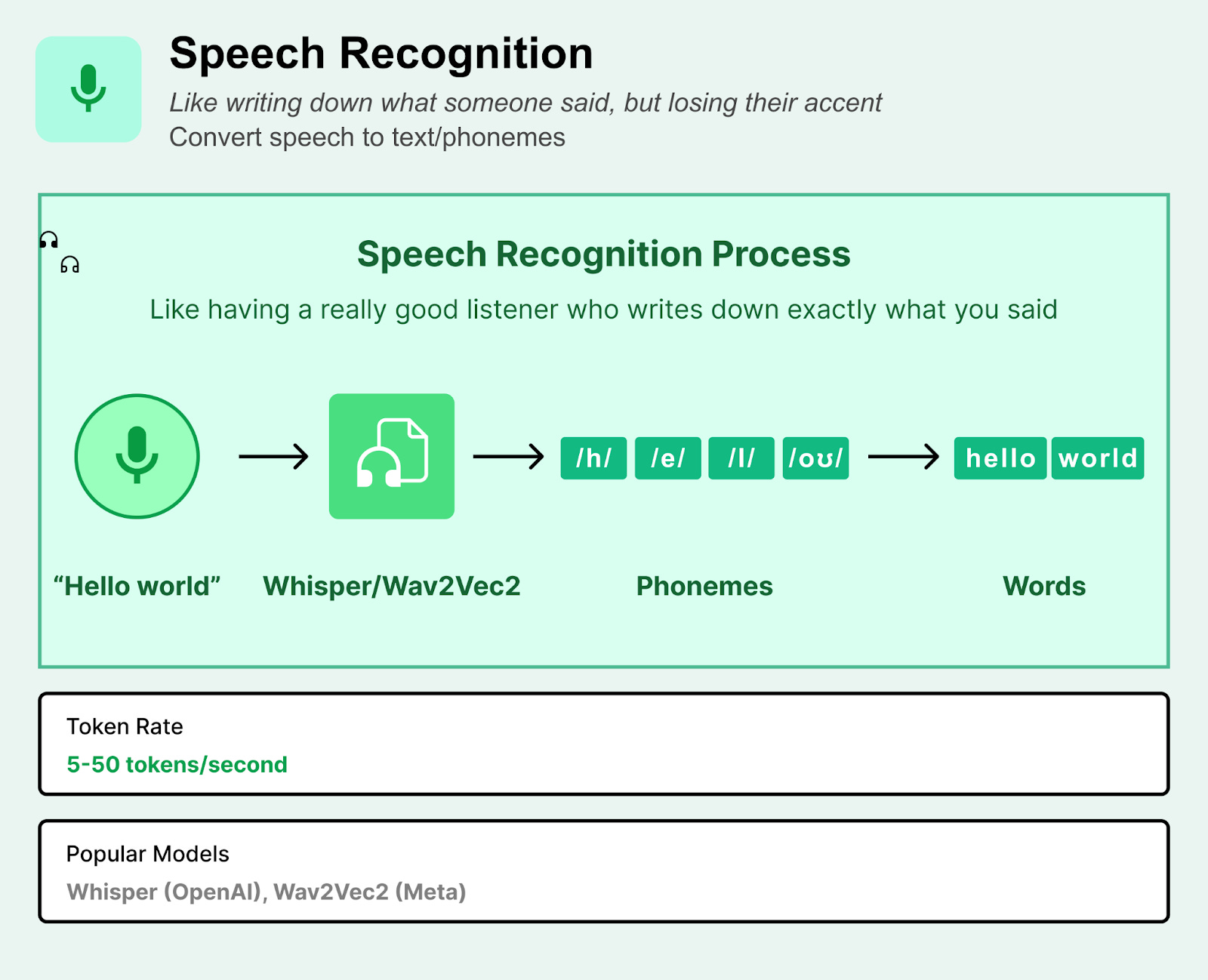
2. Phoneme/Character Tokens (ASR-based)
Automatic Speech Recognition converts spoken audio into text representations, creating tokens that capture semantic content but discard acoustic properties.
Technical Process:
Audio is processed through an ASR system (e.g., Whisper, Wav2Vec2)
Speech is converted to phonemes (sound units) or characters/words
Tokens represent linguistic content rather than acoustic features
Can include timing information and confidence scores
Often combined with speaker identification or language detection
Token Types:
Phonemes: Fine-grained linguistic units (typically 40-50 phonemes per language)
Characters: Direct transcription to text characters
Words/Subwords: Higher-level semantic units using BPE or similar tokenization
What to know:
Advantages: Compact representation, language-model compatible, captures semantic meaning
Limitations: Complete loss of prosody, speaker identity, emotional content, and non-speech audio
Applications: Speech-to-text, voice assistants, content indexing, cross-modal retrieval
3. Multi-Scale Token Stacks (Hierarchical Representations)
Hierarchical approaches use multiple token sequences at different temporal resolutions to capture both global structure and fine-grained details, similar to multi-scale image or video representations.
Technical Process:
Coarse tokens: Capture global audio structure at low temporal resolution (e.g., 12.5 Hz)
Fine tokens: Represent detailed acoustic information at higher resolution (e.g., 50 Hz)
Multiple quantization layers create a pyramid of representations
Tokens can be processed jointly or in stages (coarse-to-fine generation)
Cross-attention mechanisms often link different scales
Implementation Examples:
Residual Vector Quantization: Multiple codebooks applied sequentially to capture different levels of detail
Temporal Hierarchies: Different encoding rates for different time scales
Frequency Hierarchies: Separate tokenization for different frequency bands
What to know:
Advantages: Balances efficiency with quality, enables progressive generation, captures multi-scale patterns
Limitations: Increased model complexity, requires careful design of hierarchy levels
Applications: High-quality audio generation, music modeling, efficient compression

Tradeoffs to Remember
Temporal Resolution vs Efficiency:
Higher token rates preserve more temporal detail but increase sequence length
Codec tokens typically achieve 50-100x compression over raw audio
ASR tokens provide extreme compression but lose all acoustic information
Semantic vs Acoustic Information:
Codec tokens preserve acoustic properties (pitch, timbre, speaker identity)
ASR tokens capture semantic content but get rid of rhythm/intonation information
Multi-scale approaches try their best to balance both types of information
Quality vs Compression:
More codebook entries improve reconstruction quality but increase model size
Hierarchical approaches can achieve better quality-compression trade-offs
Domain Usage:
Speech-optimized codecs may not work well for music and vice versa
Universal codecs like EnCodec aim to handle diverse audio types
ASR-based approaches are limited to speech and may not handle accents or languages well
The best tokenization approach depends on your specific use case: codec tokens for high-quality audio generation, ASR tokens for semantic understanding, and multi-scale approaches when you need both efficiency and quality.
Video Tokenization
The most common way that videos are tokenized today is to turn video into video frames and send the video in as a sampling of images, with audio attached. For example, Gemini currently treats video as sequential images interweaved with text/audio (from online sources, so we can link).
The Future of Tokenization
Researchers are exploring ways to improve tokenization in LLMs:
Tokenization-Free Models: Some cutting-edge research proposes eliminating tokenization entirely, allowing models to operate directly on raw bytes or Unicode code points. This approach avoids the need for a predefined vocabulary, letting models natively handle any language, symbol, or character without relying on heuristics or subword units. However, training such models is more computationally intensive.
Adaptive Tokenization: Instead of using a fixed token vocabulary, adaptive tokenization allows the model to determine the optimal token split dynamically based on the input. This could mean breaking down complex or rare words into smaller units while preserving common phrases or numbers as whole tokens. The goal is to strike a balance between efficiency (fewer tokens) and semantic clarity (keeping meaningful units intact).
Conclusion
Multimodal tokenization extends the concept of text tokens to images, audio, and video. Images get converted through patch embeddings (splitting into grid squares), vector quantization (learning visual codebooks), or contrastive embeddings (CLIP-style). Audio uses neural codecs (preserving sound quality), ASR transcription (converting to text), or hierarchical approaches (multiple resolution levels).
Each method has tradeoffs, and these tokenization choices directly impact what AI systems can understand and generate.
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.

What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Well written, though you could tag this on to the title-> "Where Do We Go From Here?"