
How Lyft Built an ML Platform That Serves Millions of Predictions Per Second

✂️ Cut your QA cycles down to minutes with automated testing (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
Disclaimer: The details in this post have been derived from the details shared online by the Lyft Engineering Team. All credit for the technical details goes to the Lyft Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them
When you request a ride on Lyft, dozens of machine learning models spring into action behind the scenes. One model may calculate the price of your trip. Another determines which drivers should receive bonus incentives. A fraud detection model scans the transaction for suspicious activity. An ETA prediction model estimates your arrival time. All of this happens in milliseconds, and it happens millions of times every single day.
The engineering challenge of serving machine learning models at this scale is immense.
Lyft’s solution was to build a system called LyftLearn Serving that makes this task easy for developers. In this article, we will look at how Lyft built this platform and the architecture behind it.
Two Planes of Complexity
Lyft identified that machine learning model serving is difficult because of the complexity on two different planes:
The first plane is the data plane. This encompasses everything that happens during steady-state operation when the system is actively processing requests. This includes network traffic, CPU, and memory consumption. Also, the model must load into memory and execute the inference tasks quickly. In other words, these are the runtime concerns that determine whether the system can handle production load.
The second plane is the control plane, which deals with everything that changes over time. For example, models need to be deployed and undeployed. They need to be retrained on fresh data and versioned properly. New models need to be tested through experiments before fully launching. Also, backward compatibility must be maintained so that changes don’t break existing functionality.
Lyft needed to excel at both simultaneously while supporting a diverse set of requirements across dozens of teams.
The Requirements Problem
The diversity of requirements at Lyft made building a one-size-fits-all solution nearly impossible. Different teams cared about wildly different system characteristics, creating a vast operating environment.
For example, some teams required extremely tight latency limits. Their models needed to return predictions in single-digit milliseconds because any delay would degrade user experience. Other teams cared more about throughput, needing to handle over a million requests per second during peak hours. Some teams wanted to use niche machine learning libraries that weren’t widely supported. Others needed continual learning capabilities, where models update themselves in real-time based on new data.
See the diagram below:
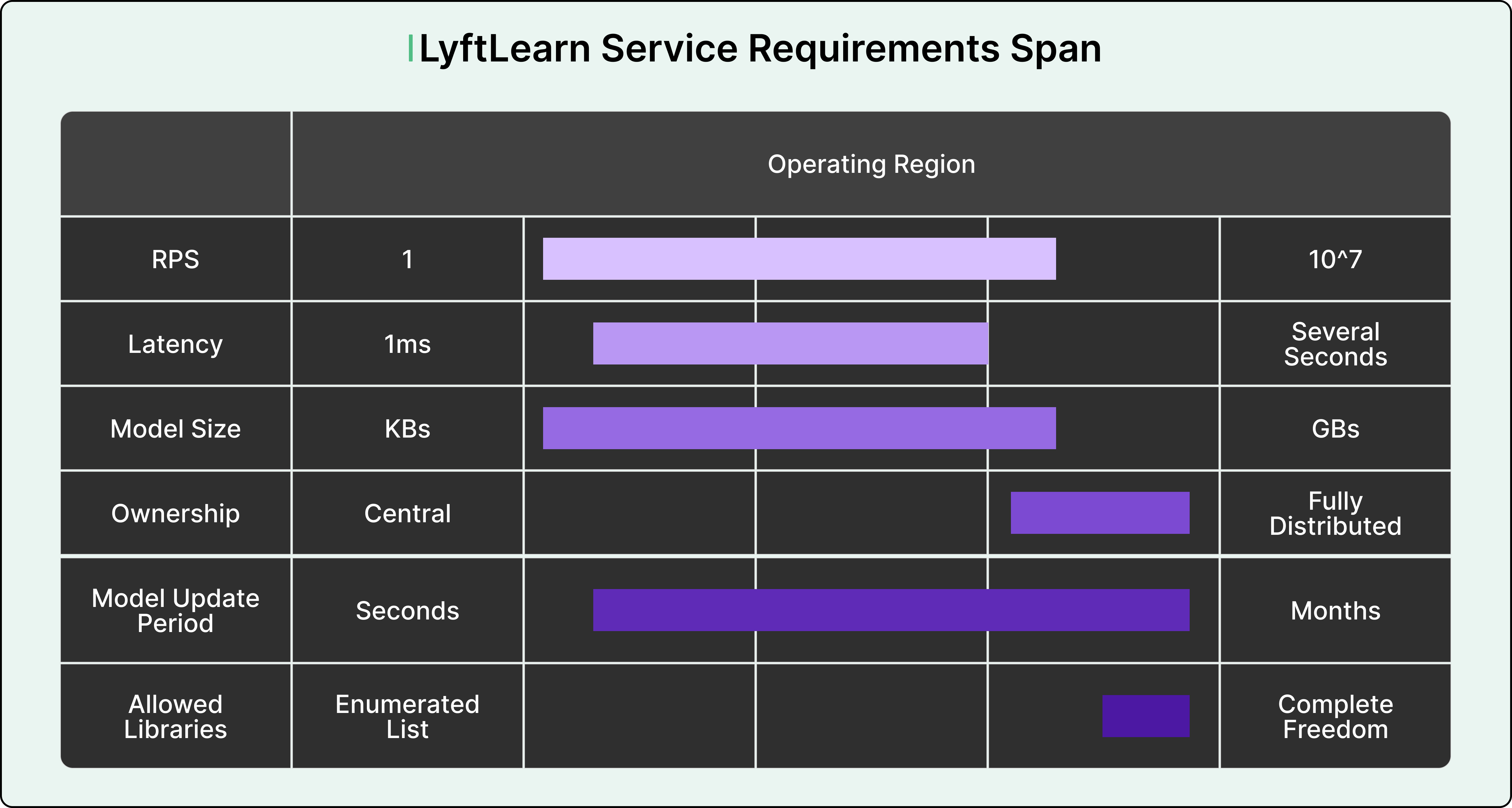
To make matters worse, Lyft already had a legacy monolithic serving system in production. While this system worked for some use cases, its monolithic design created serious problems.
All teams shared the same codebase, which meant they had to agree on which versions of libraries to use. One team’s deployment could break another team’s models. During incidents, it was often unclear which team owned which part of the system. Teams frequently blocked each other from deploying changes.
Cut Code Review Time & Bugs in Half (Sponsored)

Code reviews are critical but time-consuming. CodeRabbit acts as your AI co-pilot, providing instant Code review comments and potential impacts of every pull request.
Beyond just flagging issues, CodeRabbit provides one-click fix suggestions and lets you define custom code quality rules using AST Grep patterns, catching subtle issues that traditional static analysis tools might miss.
CodeRabbit reviews 1 million PRs every week across 3 million repositories and is used by 100 thousand Open-source projects.
CodeRabbit is free for all open-source repo’s.
The Microservices Solution
Lyft chose to build LyftLearn Serving using a microservices architecture, where small, independent services each handle specific responsibilities. This decision aligned with how most software systems at Lyft are built, allowing the team to leverage existing tooling for testing, networking, and operational management.
See the diagram below:
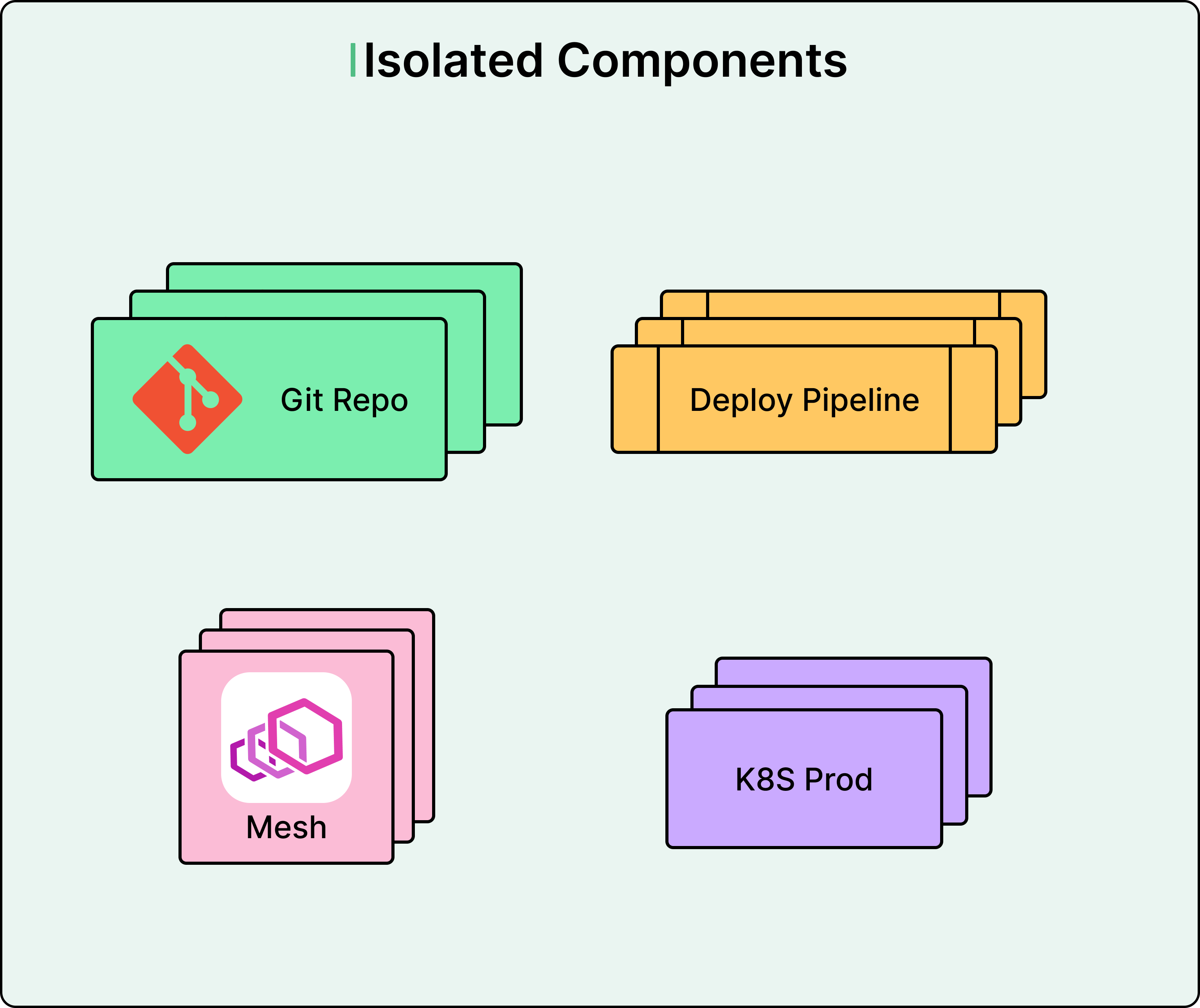
However, the Lyft team took the microservices concept further than typical implementations. Rather than building a single shared microservice that all teams use, they created a platform that generates completely independent microservices for each team.
When a team at Lyft wants to serve machine learning models, they use a configuration generator to create their own dedicated GitHub repository. This repository contains all the code and configuration for a microservice that belongs entirely to that team. For example, the Pricing team gets its own repository and microservice. The Fraud Detection team gets its own and so on.
These microservices share common underlying components, but they run independently. Each team controls its own deployment pipeline, choosing when to release changes to production. Each team can use whatever versions of TensorFlow, PyTorch, or other ML libraries they need without conflicts. Each team’s service runs in isolated containers with dedicated CPU and memory resources. If one team’s deployment breaks, only that team is affected.
This architecture solved the ownership problem that plagued the legacy system. Every repository clearly identifies which team owns it. On-call escalation paths are unambiguous. Library updates only affect one team at a time. Teams can move at their own pace without blocking each other.
See the diagram below:
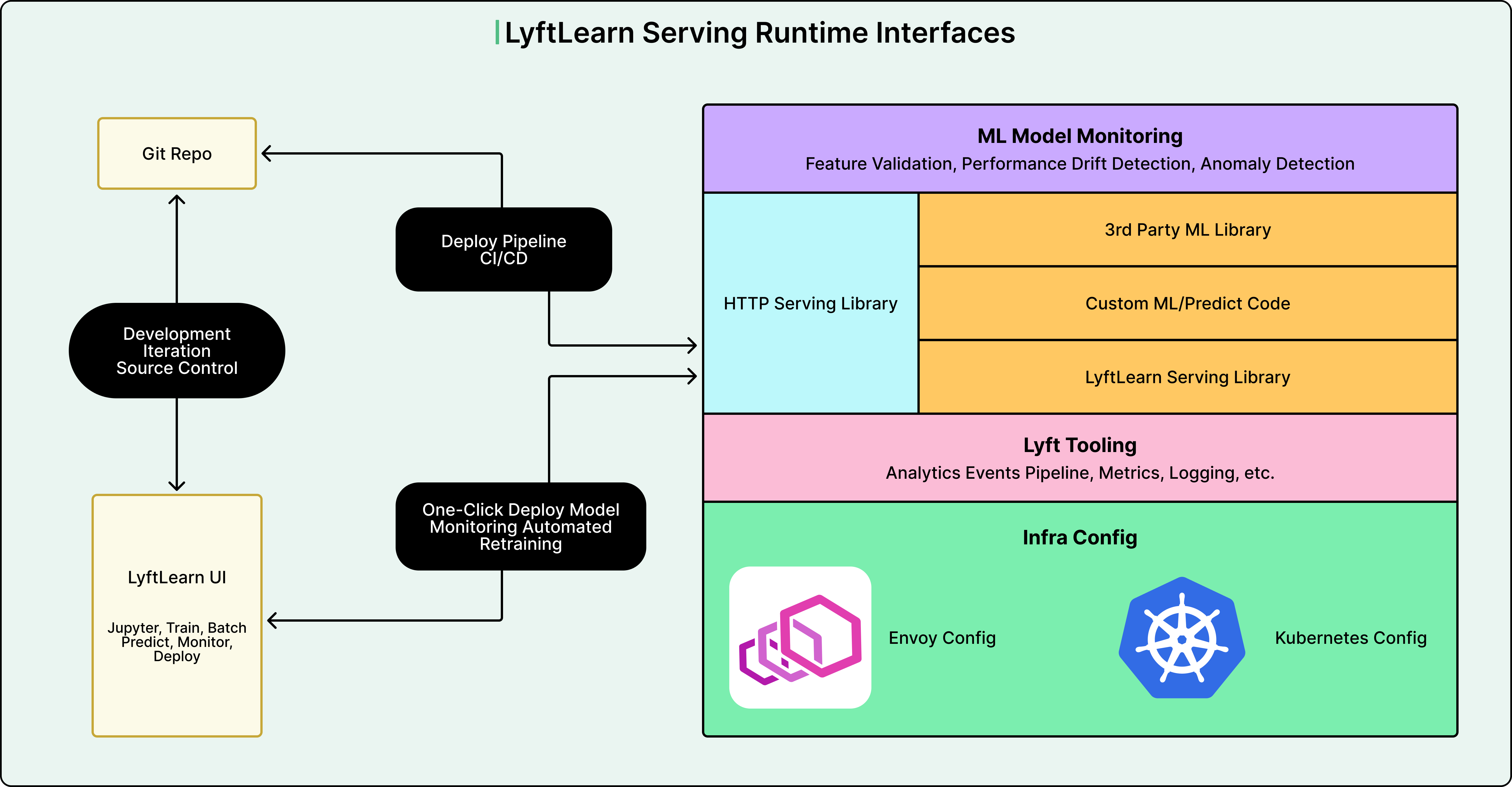
The Runtime Architecture
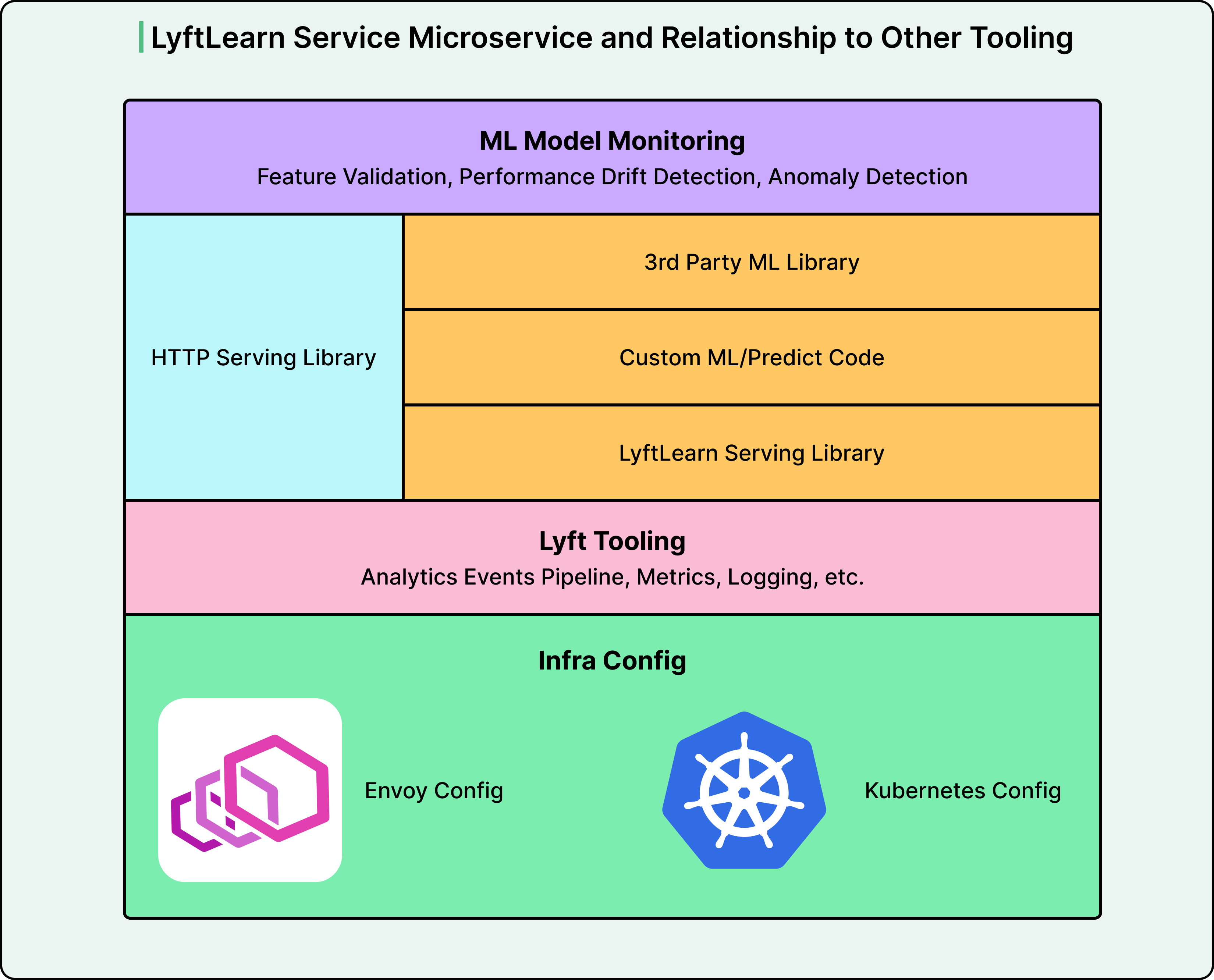
Understanding what actually runs when a LyftLearn Serving microservice is deployed helps clarify how the system works. The runtime consists of several layers that work together.
At the outermost layer sits the HTTP serving infrastructure. Lyft uses Flask, a Python web framework, to handle incoming HTTP requests. Flask runs on top of Gunicorn, a web server that manages multiple worker processes to handle concurrent requests. In front of everything sits Envoy, a load balancer that distributes requests across multiple server instances. The Lyft team made custom optimizations to Flask to work better with Envoy and Gunicorn.
Beneath the HTTP layer sits the Core LyftLearn Serving Library, which contains the business logic that powers the platform. This library handles critical functionality like loading models into memory and unloading them when needed, managing multiple versions of the same model, processing inference requests, shadowing new models alongside production models for safe testing, monitoring model performance, and logging predictions for analysis.
The next layer is where teams inject their custom code. ML engineers write two key functions that get called by the platform.
The load function specifies how to deserialize their specific model from disk into memory.
The predict function defines how to preprocess input features and call their model’s prediction method.
At the deepest layer sit third-party ML libraries like TensorFlow, PyTorch, LightGBM, and XGBoost. The Lyft platform doesn’t restrict which libraries teams can use, as long as they have a Python interface. This flexibility was essential for supporting diverse team requirements.
Finally, the entire stack sits on top of Lyft’s infrastructure, which uses Kubernetes for container orchestration and Envoy for service mesh networking. The runtime implements interfaces for metrics, logging, tracing, and analytics that integrate with Lyft’s monitoring systems.
The Configuration Generator
One of the most important aspects of LyftLearn Serving is how it solves the onboarding problem. Deploying a microservice at a company like Lyft requires extensive configuration across many systems, such as:
Kubernetes YAML files to define how containers run.
Terraform configuration for cloud infrastructure.
Envoy configs for networking.
Database connections, security credentials, monitoring setup, and deployment pipelines.
Expecting ML engineers to learn all of these systems would create a massive barrier to adoption. The Lyft team’s solution was to build a configuration generator using Yeoman, a project scaffolding tool.
See the diagram below:
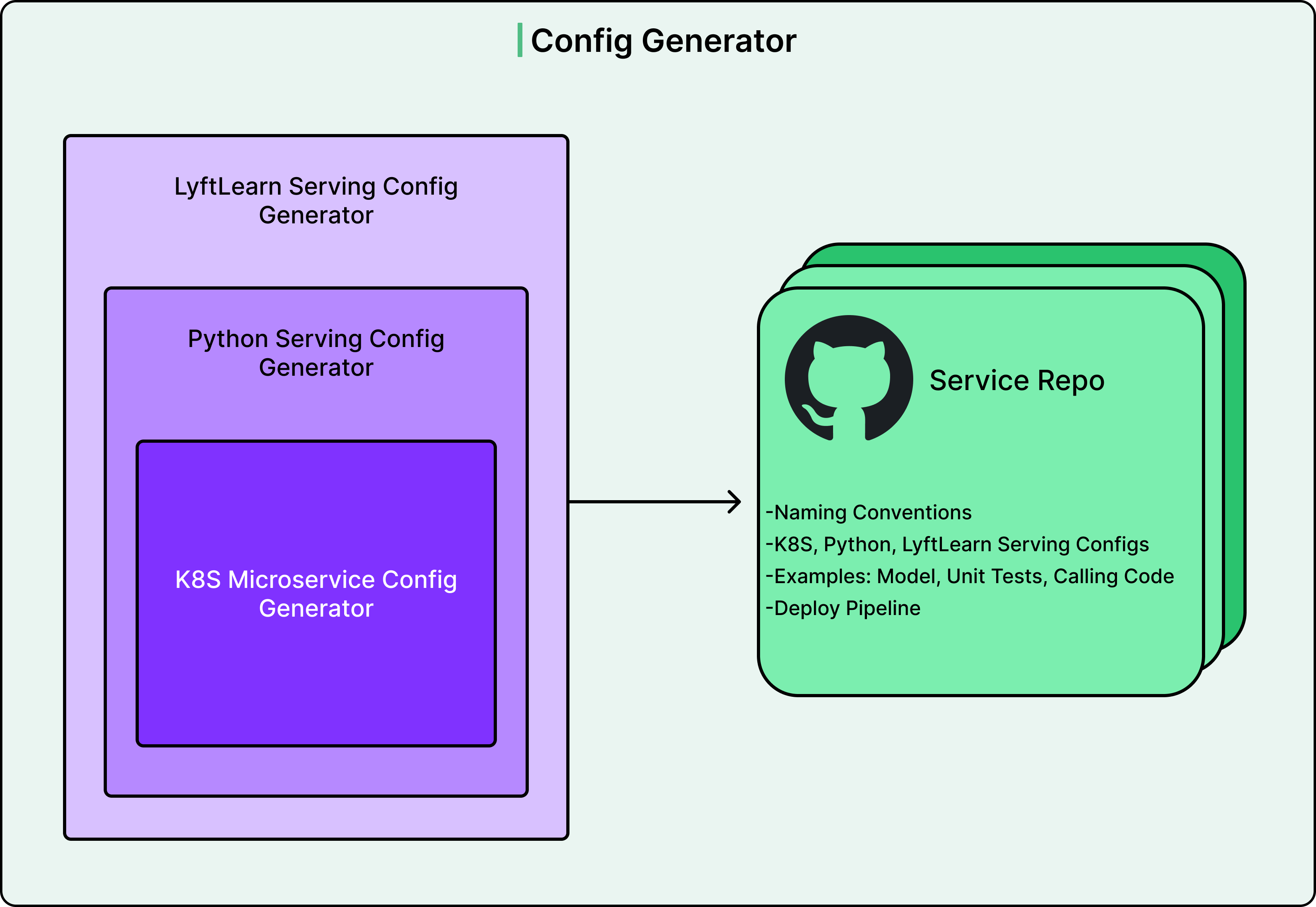
The generator works through a simple question-and-answer flow. An ML engineer runs the generator and answers a handful of basic questions about their service name, team ownership, and a few other details. The generator then automatically creates a complete GitHub repository containing everything needed to run a LyftLearn Serving microservice.
The generated repository includes properly formatted configuration files for all infrastructure systems, working example code demonstrating how to implement model loading and prediction, unit test templates, a fully configured CI/CD deployment pipeline, and documentation on how to customize everything.
Most importantly, the generated repository is immediately deployable. An ML engineer can run the generator, merge the created code, deploy it, and have a functioning microservice serving models in production. This approach reduced the support burden on the ML Platform team. Teams could self-onboard without extensive help. With over 40 teams using LyftLearn Serving, this scalability was essential.
Model Self-Tests
The Lyft team built a solution for ensuring models continue working correctly as the system evolves. They call this feature model self-tests.
ML engineers define test data directly in their model code. This test data consists of sample inputs and their expected outputs. For example, a neural network model might specify that input [1, 0, 0] should produce output close to [1]. This test data gets saved alongside the model binary itself.
The platform automatically runs these self-tests in two scenarios:
First, every time a model loads into memory, the system runs predictions on the test data and verifies the outputs match expectations. Results are logged and turned into metrics that ML engineers can monitor.
Second, whenever someone creates a pull request to change code, the continuous integration system tests all models in the repository against their saved test data.
This automated testing catches problems early. If a library upgrade breaks model compatibility, the tests fail before deployment. If container image changes affect model behavior, engineers know immediately. The tests provide confidence that models work correctly without requiring manual verification.
How an Inference Request Flows Through the System
Seeing how an actual prediction request moves through LyftLearn Serving helps tie all the pieces together. Consider a request to predict driver incentives.
The request arrives as an HTTP POST to the /infer endpoint, containing a model ID and input features in JSON format.
The Flask server receives the request and routes it to the appropriate handler function. This handler is provided by the Core LyftLearn Serving Library.
The platform code first retrieves the requested model from memory using the model ID. It validates that the input features match the expected schema. If model shadowing is configured, it may route the request to multiple model versions simultaneously for comparison.
Next, the platform calls the custom predict function that the ML engineer wrote. This function preprocesses the features as needed, then calls the underlying ML library’s prediction method.
Finally, more platform code executes. The system emits latency metrics and logs for debugging. It generates analytics events for monitoring model performance. The prediction is packaged into a JSON response and returned to the caller.
See the diagram below:
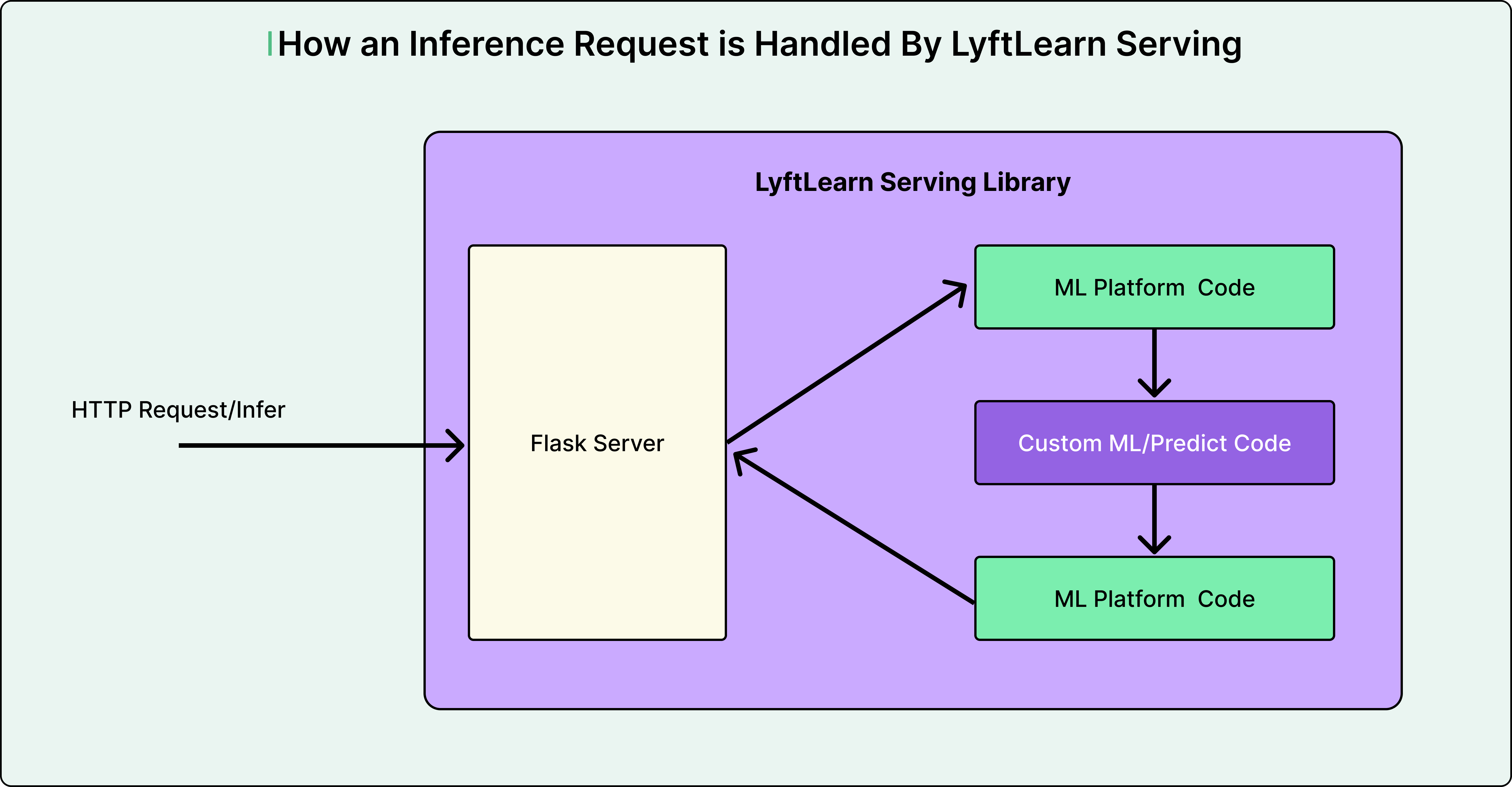
This entire flow typically completes in milliseconds. The clean separation between platform code and custom code allows Lyft to add new capabilities without teams needing to change their prediction logic.
Development Workflow and Documentation
The Lyft team recognized that different users need different interfaces. They provided two primary ways to work with LyftLearn Serving.
For software engineers comfortable with code, the model repository offers full control. Engineers can edit deployment pipelines, modify CI/CD configurations, and write custom inference logic. Everything is version-controlled and follows standard software development practices.
For data scientists who prefer visual interfaces, LyftLearn UI provides a web application. Users can deploy models with one click, monitor performance through dashboards, and manage training jobs without writing infrastructure code.
See the diagram below:
Documentation also received first-class treatment. The Lyft team organized docs using the Diátaxis framework, which defines four documentation types:
Tutorials provide step-by-step learning for beginners.
How-to guides give specific instructions for common tasks.
Technical references document APIs in detail.
Discussions explain concepts and design decisions.
Conclusion
The Lyft engineering team shared several important lessons from building LyftLearn Serving. These insights apply broadly to anyone building platform systems.
First, they emphasized the importance of defining terms carefully. The word “model” can mean many different things: source code, trained weights, files in cloud storage, serialized binaries, or objects in memory. Every conversation needs clarity about which meaning is intended.
Second, they learned that models serve production traffic indefinitely. Once a model goes live, it typically runs forever. This reality demands extreme stability and careful attention to backward compatibility.
Third, they found that great documentation is critical for platform products. Thorough, clear docs enable self-onboarding and reduce support burden. The investment in documentation pays continuous dividends.
Fourth, they accepted that hard trade-offs are inevitable. The team constantly balanced seamless user experience against power user flexibility, or custom workflows against enforced best practices.
Fifth, they learned to align their vision with power users. The most demanding customers often have the right priorities: stability, performance, and flexibility. Meeting their needs tends to benefit everyone.
Finally, they embraced boring technology. Rather than chasing the latest trends, they chose proven, stable tools like Flask, Kubernetes, and Python. These technologies have strong community support, make hiring easier, and cause fewer unexpected problems.
Lyft made LyftLearn Serving available internally in March 2022. The team then migrated all models from the legacy monolithic system to the new platform. Today, over 40 teams use LyftLearn Serving to power hundreds of millions of predictions daily.
References:
Powering Millions of Real-Time Decisions with LyftLearn Serving
LyftLearn: ML Model Training Infrastructure built on Kubernetes
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.