
How Meta Built a New AI-Powered Ads Model for 5% Better Conversions

Cut Code Review Time & Bugs in Half (Sponsored)

Code reviews are critical but time-consuming. CodeRabbit acts as your AI co-pilot, providing instant Code review comments and potential impacts of every pull request.
Beyond just flagging issues, CodeRabbit provides one-click fix suggestions and lets you define custom code quality rules using AST Grep patterns, catching subtle issues that traditional static analysis tools might miss.
CodeRabbit has so far reviewed more than 10 million PRs, installed on 2 million repositories, and used by 100 thousand Open-source projects. CodeRabbit is free for all open-source repo’s.
Disclaimer: The details in this post have been derived from the details shared online by the Meta Engineering Team. All credit for the technical details goes to the Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When Meta announced in Q2 2025 that its new Generative Ads Model (GEM) had driven a 5% increase in ad conversions on Instagram and a 3% increase on Facebook Feed, the numbers might have seemed modest.
However, at Meta’s scale, these percentages translate to billions of dollars in additional revenue and represent a fundamental shift in how AI-powered advertising works.
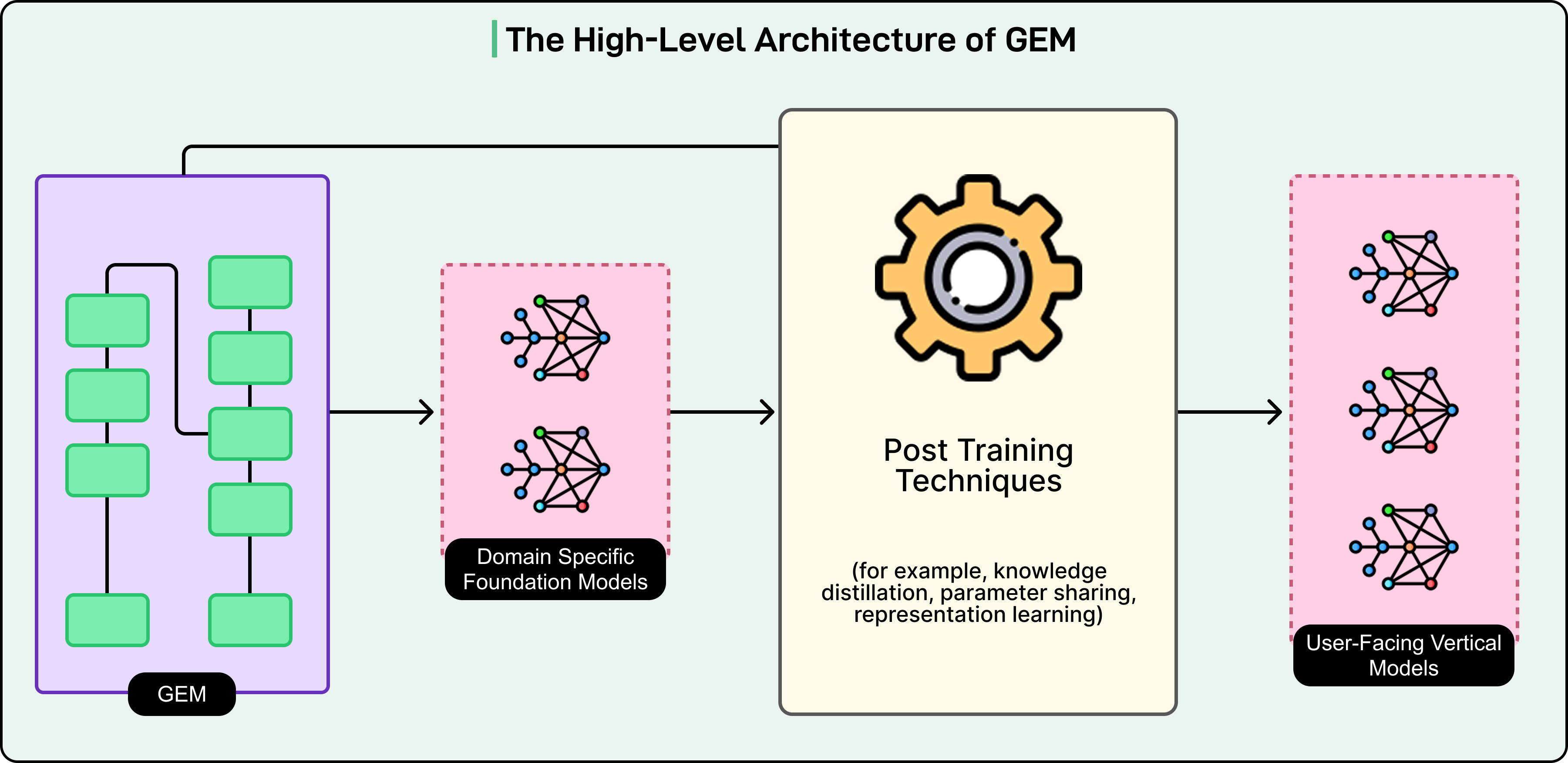
GEM is the largest foundation model ever built for recommendation systems. It has been trained at the scale typically reserved for large language models like GPT-4 or Claude. Yet here’s the paradox: GEM is so powerful and computationally intensive that Meta can’t actually use it directly to serve ads to users.
Instead, the company developed a teacher-student architecture that lets smaller, faster models benefit from GEM’s intelligence without inheriting its computational cost.
In this article, we look at how the Meta engineering team built GEM and the challenges they overcame.
👋 Goodbye low test coverage and slow QA cycles (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native solution provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to minutes.
They can get you:
80% automated E2E test coverage in weeks—not years
Unlimited parallel test runs
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
The Core Problem GEM Solves
Every day, billions of users scroll through Facebook, Instagram, and other Meta platforms, generating trillions of potential ad impression opportunities. Each impression represents a decision point: which ad, from millions of possibilities, should be shown to this specific user at this particular moment? Getting this wrong means wasting advertiser budgets on irrelevant ads and annoying users with content they don’t care about. Getting it right creates value for everyone involved.
Traditional ad recommendation systems struggled with this in several ways. Some systems treated each platform separately, which meant that insights about user behavior on Instagram couldn’t inform predictions on Facebook. This siloed approach missed valuable cross-platform patterns. Other systems tried to treat all platforms identically, ignoring the fact that people interact with Instagram Stories very differently from how they browse Facebook Feed. Neither approach was optimal.
The data complexity also compounds these challenges in the following ways:
Meaningful signals like clicks and conversions are extremely sparse compared to total impression volume.
User features are dynamic and constantly changing.
The system must process multimodal inputs, including text, images, video, and complex behavioral sequences.
Traditional models had severe memory limitations, typically only considering a user’s last 10 to 20 actions.
GEM’s goal was to create a unified intelligence that understands users holistically across Meta’s entire ecosystem, learning from long behavioral histories and complex cross-platform patterns while maintaining the nuance needed to optimize for each specific surface and objective.
How GEM Understands Users?
GEM’s architecture processes user and ad information through three complementary systems, each handling a different aspect of the prediction problem.
The first system handles what Meta calls non-sequence features, which are essentially static attributes and their combinations. These include user demographics like age and location, user interests, ad characteristics like format and creative content, and advertiser objectives.
The challenge here isn’t just knowing these individual features but understanding how they interact. For example, a 25-year-old tech worker has very different purchasing patterns than a 25-year-old teacher, even if they share some interests. The system needs to learn which combinations of features actually matter.
GEM uses an enhanced version of the Wukong architecture with stackable factorization machines that can scale both vertically for deeper interactions and horizontally for broader feature coverage. This architecture works through multiple stacked layers, where each successive layer learns increasingly complex patterns from the simpler patterns discovered by previous layers. For instance, an early layer might discover the basic pattern that young professionals respond well to tech product ads. A layer deeper in the stack builds on this by learning that young professionals in urban areas who show interest in fitness respond especially well to smart wearable ads. An even deeper layer might refine this further, discovering that this combination works best specifically when those ads emphasize data tracking features rather than fashion elements.
The second system handles sequence features, which capture the timeline of user behavior. A user’s actions don’t exist in isolation. They tell a story with order and meaning. Someone who clicked on home workout content, then searched for gyms nearby, then viewed several gym websites, then researched membership costs is clearly on a specific journey. Traditional architectures struggled to process long sequences efficiently because the computational cost grows rapidly with sequence length.
GEM overcomes this with a pyramid-parallel structure. Think of it as processing your behavior history in chunks at the bottom level, then combining those chunks into broader patterns at middle levels, and finally synthesizing everything into a complete journey understanding at the top level. Multiple chunks can be processed simultaneously rather than sequentially, which dramatically improves efficiency.
The breakthrough here is scale. GEM can now analyze thousands of your past actions rather than just the most recent handful. This extended view reveals patterns that shorter windows simply cannot capture, like the progression from casual interest to serious purchase intent that might develop over months.
See the diagram below:
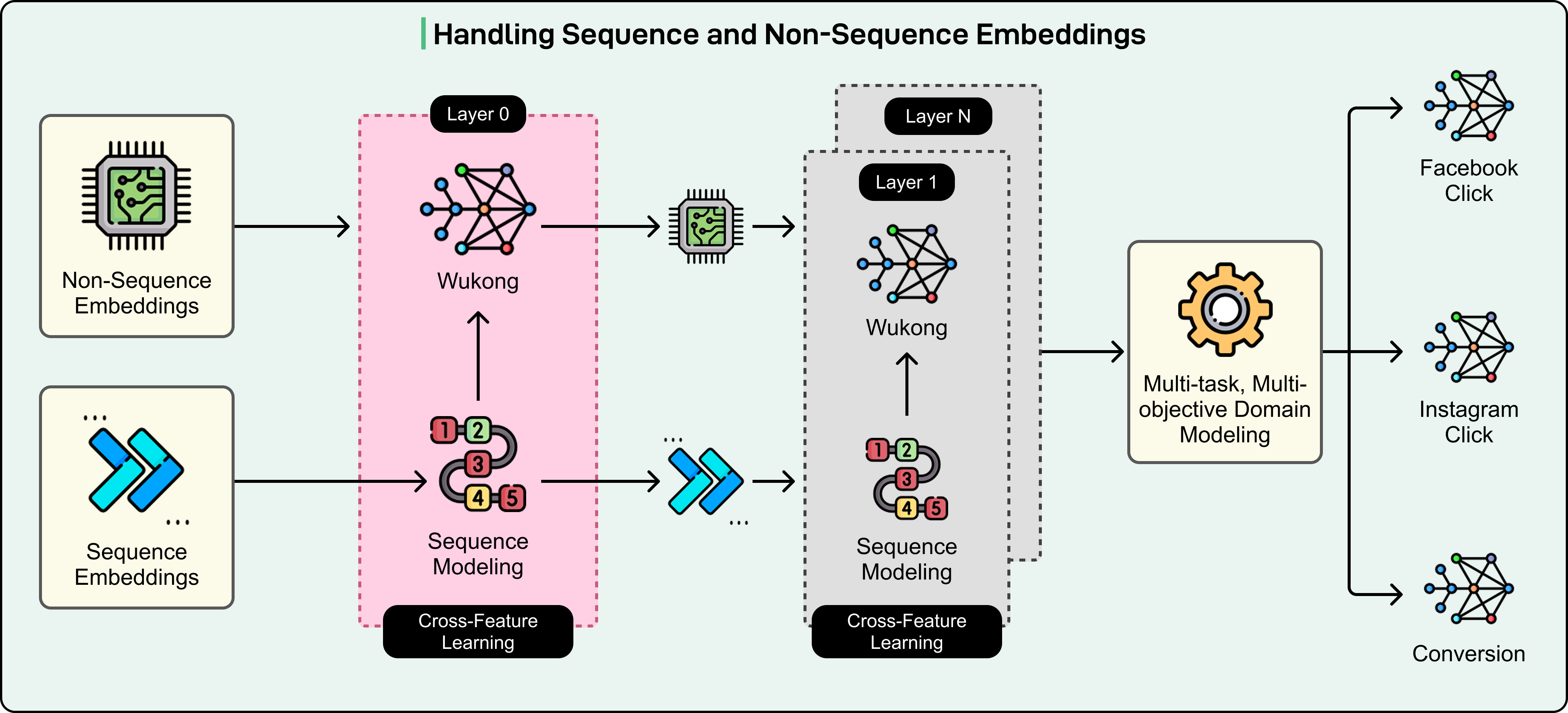
The third system, called InterFormer, handles cross-feature learning by connecting your static profile with your behavioral timeline. This is where GEM’s intelligence really becomes evident. Previous approaches would compress your entire behavior history into a compact summary vector (like reducing an entire novel to a single rating). This compression inevitably loses critical details about your journey.
InterFormer takes a different approach using an interleaving structure. It alternates between layers that focus purely on understanding your behavior sequence and layers that connect those behaviors to your profile attributes.
The first sequence layer might identify that you’ve shown increasing interest in fitness over time.
The first cross-feature layer then considers how your age, income, and location context shape what that fitness interest means.
The second sequence layer re-examines your behavior with these new insights and might notice that your fitness research intensified after a gym opened near your workplace.
The second cross-feature layer then makes even deeper connections about purchase intent and timing.
This alternating process continues through multiple layers, with each cycle refining understanding without losing access to the complete behavioral record.
The Practical Problem with Using GEM
Despite GEM’s obvious strengths, Meta faced a fundamental engineering challenge in using GEM.
GEM is enormous and trained using thousands of GPUs over extended periods. Running GEM directly for every ad prediction would be impossibly slow and expensive. When a user scrolls through Instagram, the system needs to make ad decisions in tens of milliseconds. GEM simply cannot operate at that speed while serving billions of users simultaneously.
Meta’s solution was a teacher-student architecture where GEM acts as the master teacher that trains hundreds of smaller, faster Vertical Models (VMs) that actually serve ads in production. These VMs are specialized for specific contexts like Instagram Stories click prediction or Facebook Feed conversion prediction. Each VM is lightweight enough to make predictions in milliseconds, but they’re much smarter than they would be if trained independently because they learn from GEM.
The knowledge transfer happens through two strategies. Direct transfer works when a VM operates in the same domain where GEM was trained, with similar data and objectives. GEM can teach these models directly. Hierarchical transfer applies when VMs work in specialized areas quite different from GEM’s training domain. In these cases, GEM first teaches medium-sized domain-specific foundation models for areas like Instagram or Facebook Marketplace. These domain models then teach the even smaller VMs. The knowledge flows down through levels, getting adapted and specialized at each stage.
Meta employs three sophisticated techniques to maximize transfer efficiency:
Knowledge distillation with Student Adapter: Student models learn to replicate GEM’s reasoning process, not just final predictions. The Student Adapter refines GEM’s predictions using recent ground-truth data, adjusting for timing delays and domain-specific differences.
Representation learning: Creates a shared conceptual framework between teacher and students. GEM learns to encode information in ways that transfer well across different model sizes, adding no computational overhead during ad serving.
Parameter sharing: This lets VMs selectively incorporate specific components directly from GEM. Small VMs stay fast while borrowing GEM’s sophisticated components for complex user understanding tasks.
Together, these three techniques achieve twice the effectiveness of standard knowledge distillation alone. The continuous improvement cycle works like this:
Users interact with fast VMs in real time
Their engagement data flows back into Meta’s data pipelines
GEM periodically re-trains on this fresh data, updated knowledge transfers to VMs through the post-training techniques, and
Improved VMs get deployed to production.
This cycle repeats continuously, with GEM getting smarter and VMs getting regular intelligence updates.
Training at Unprecedented Scale
Building GEM required Meta to rebuild its training infrastructure from the ground up.
The challenge was training a model at LLM scale, but for the fundamentally different task of recommendation rather than language generation. The company achieved a 23x increase in effective training throughput while using 16x more GPUs and simultaneously improving hardware efficiency by 1.43x.
This required innovations across multiple areas. Multi-dimensional parallelism orchestrates how thousands of GPUs work together, splitting the model’s dense components using techniques like Hybrid Sharded Distributed Parallel while handling sparse components like embedding tables through a combination of data and model parallelism. The goal was to ensure every GPU stayed busy with minimal idle time waiting for communication from other GPUs.
System-level optimizations pushed GPU utilization even higher:
Custom GPU kernels designed for variable-length user sequences, fusing operations to reduce memory bandwidth bottlenecks.
PyTorch 2.0 graph-level compilation automates optimizations like activation checkpointing and operator fusion.
Memory compression, including FP8 quantization to reduce the footprint without impacting accuracy.
NCCLX communication collectives that handle inter-GPU communication without consuming the main compute resources.
The efficiency gains extended beyond raw training speed.
Meta reduced job startup time by 5x through optimizations in trainer initialization, data reader setup, and checkpointing. They cut PyTorch 2.0 compilation time by 7x using intelligent caching strategies. These might seem like minor details, but when you’re training models that cost millions of dollars in compute resources, every percentage point of efficiency improvement matters enormously.
The result is a training system that can iterate rapidly on GEM, incorporating new data and architectural improvements at a pace that would have been impossible with previous infrastructure. This enables Meta to keep GEM at the frontier of recommendation AI while controlling costs enough to make the massive investment worthwhile.
Conclusion
Meta’s roadmap for GEM extends well beyond its current capabilities.
The next major evolution involves true multimodal learning, where GEM processes text, images, audio, and video together rather than treating them as separate input streams. This will enable an even richer understanding of both user preferences and ad creative effectiveness across all content types. The company is also exploring inference-time scaling, which would allow the system to dynamically allocate more computational resources to difficult predictions while handling straightforward cases more efficiently.
Perhaps most ambitiously, Meta envisions a unified engagement model that ranks both organic content and ads using the same underlying intelligence. This would fundamentally change how advertising integrates into social feeds, potentially creating more seamless experiences where ads feel like natural content recommendations rather than interruptions. On the advertiser side, GEM’s intelligence will enable more sophisticated agentic automation, where AI systems can manage and optimize campaigns with minimal human intervention while achieving better results.
References:
Meta’s Generative Ads Model (GEM): The Central Brain Accelerating Ads Recommendation AI Innovation
Wukong: Towards a Scaling Law for Large-Scale Recommendation
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.