
How Meta Built Threads to Support 100 Million Signups in 5 Days

Generate your MCP server with Speakeasy (Sponsored)

Like it or not, your API has a new user: AI agents. Make accessing your API services easy for them with an MCP (Model Context Protocol) server. Speakeasy uses your OpenAPI spec to generate an MCP server with tools for all your API operations to make building agentic workflows easy.
Once you've generated your server, use the Speakeasy platform to develop evals, prompts and custom toolsets to take your AI developer platform to the next level.
Disclaimer: The details in this post have been derived from the articles written by the Meta engineering team. All credit for the technical details goes to the Meta/Threads Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Threads, Meta’s newest social platform, launched on July 5, 2023, as a real-time, public conversation space.
Built in under five months by a small engineering team, the product received immediate momentum. Infrastructure teams had to respond immediately to the incredible demand.
When a new app hits 100 million signups in under a week, the instinct is to assume someone built a miracle backend overnight. That’s not what happened with Threads. There was no time to build new systems or bespoke scaling plans. The only option was to trust the machinery already in place.
And that machinery worked quite smoothly. As millions signed up in 5 days, the backend systems held on, and everything from the user’s perspective worked as intended.
Threads didn’t scale because it was lucky. It scaled because it inherited Meta’s hardened infrastructure: platforms shaped by a decade of lessons from Facebook, Instagram, and WhatsApp.
This article explores two of those platforms that played a key role in the successful launch of Threads:
ZippyDB, the distributed key-value store powering state and search.
Async, the serverless compute engine that offloads billions of background tasks.
Neither of these systems was built for Threads. But Threads wouldn’t have worked without them.
ZippyDB was already managing billions of reads and writes daily across distributed regions. Also, Async had been processing trillions of background jobs across more than 100,000 servers, quietly powering everything from feed generation to follow suggestions.
ZippyDB: Key-Value at Hyperscale
ZippyDB is Meta’s internal, distributed key-value store designed to offer strong consistency, high availability, and geographical resilience at massive scale.
At its core, it builds on RocksDB for storage, extends replication with Meta’s Data Shuttle (a Multi-Paxos-based protocol), and manages placement and failover through a system called Shard Manager.
Unlike purpose-built datastores tailored to single products, ZippyDB is a multi-tenant platform. Dozens of use cases (from metadata services to product feature state) share the same infrastructure. This design ensures higher hardware utilization, centralized observability, and predictable isolation across workloads.
The Architecture of ZippyDB
ZippyDB doesn’t treat deployment as a monolith. It’s split into deployment tiers: logical groups of compute and storage resources distributed across geographic regions.
Each tier serves one or more use cases and provides fault isolation, capacity management, and replication boundaries. The most commonly used is the wildcard tier, which acts as a multi-tenant default, balancing hardware utilization with operational simplicity. Dedicated tiers exist for use cases with strict isolation or latency constraints.
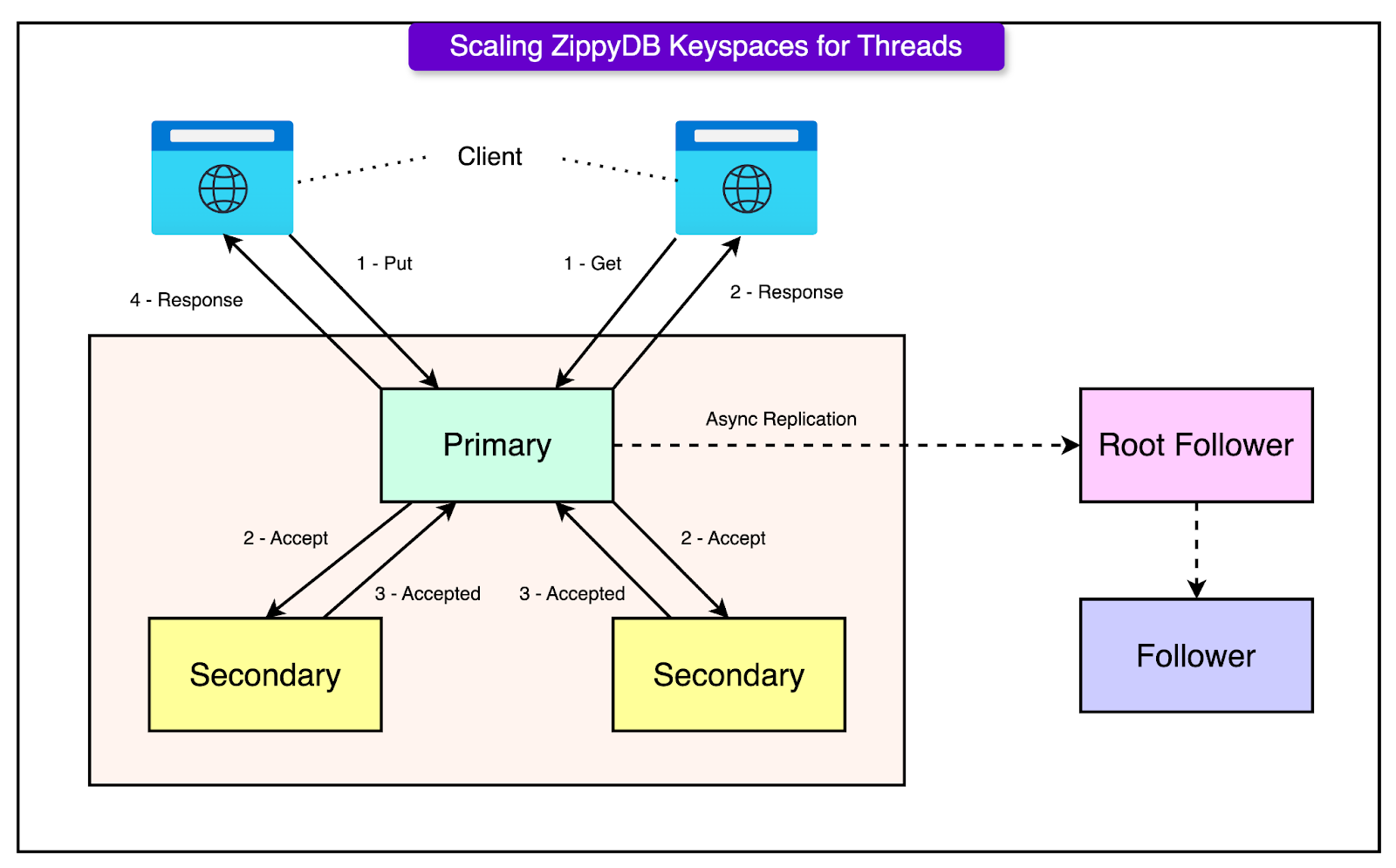
Within each tier, data is broken into shards, the fundamental unit of distribution and replication. Each shard is independently managed and:
Synchronously replicated across a quorum of Paxos nodes for durability and consistency. This guarantees that writes survive regional failures and meet strong consistency requirements.
Asynchronously replicated to follower replicas, which are often co-located with high-read traffic regions. These replicas serve low-latency reads with relaxed consistency, enabling fast access without sacrificing global durability.
This hybrid replication model (strong quorum-based writes paired with regional read optimization) gives ZippyDB flexibility across a spectrum of workloads.
See the diagram below that shows the concept of region-based replication supported by ZippyDB.

To push scalability even further, ZippyDB introduces a layer of logical partitioning beneath shards: μshards (micro-shards). These are small, related key ranges that provide finer-grained control over data locality and mobility.
Applications don’t deal directly with physical shards. Instead, they write to μshards, which ZippyDB dynamically maps to underlying storage based on access patterns and load balancing requirements.
ZippyDB supports two primary strategies for managing μshard-to-shard mapping:
Compact Mapping: Best for workloads with relatively static data distribution. Mappings change only when shards grow too large or too hot. This model prioritizes stability over agility and is common in systems with predictable access patterns.
Akkio Mapping: Designed for dynamic workloads. A system called Akkio continuously monitors access patterns and remaps μshards to optimize latency and load. This is particularly valuable for global products where user demand shifts across regions throughout the day. Akkio reduces data duplication while improving locality, making it ideal for scenarios like feed personalization, metadata-heavy workloads, or dynamic keyspaces.
In ZippyDB, the Shard Manager acts as the external controller for leadership and failover. It doesn’t participate in the data path but plays a critical role in keeping the system coordinated.
The Shard Manager assigns a Primary replica to each shard and defines an epoch: a versioned leadership lease. The epoch ensures only one node has write authority at any given time. When the Primary changes (for example, due to failure), Shard Manager increments the epoch and assigns a new leader. The Primary sends regular heartbeats to the Shard Manager. If the heartbeats stop, the Shard Manager considers the Primary unhealthy and triggers a leader election by promoting a new node and bumping the epoch.
See the diagram below that shows the role of the Shard Manager:

Consistency and Durability in ZippyDB
In distributed systems, consistency is rarely black-and-white. ZippyDB embraces this by giving clients per-request control over consistency and durability levels, allowing teams to tune system behavior based on workload characteristics.
1 - Strong Consistency
Strong consistency in ZippyDB ensures that reads always reflect the latest acknowledged writes, regardless of where the read or write originated. To achieve this, ZippyDB routes these reads to the primary replica, which holds the current Paxos lease for the shard. The lease ensures that only one primary exists at any time, and only it can serve linearizable reads.
If the lease state is unclear (for example, during a leadership change), the read may fall back to a quorum check to avoid split-brain scenarios. This adds some latency, but maintains correctness.
2 - Bounded Staleness (Eventual Consistency)
Eventual consistency in ZippyDB isn’t the loose promise it implies in other systems. Here, it means bounded staleness: a read may be slightly behind the latest write, but it will never serve stale data beyond a defined threshold.
Follower replicas (often located closer to users) serve these reads. ZippyDB uses heartbeats to monitor follower lag, and only serves reads from replicas that are within an acceptable lag window. This enables fast, region-local reads without compromising on the order of operations.
3 - Read-Your-Writes Consistency
For clients that need causal guarantees, ZippyDB supports a read-your-writes model.
After a write, the server returns a version number (based on Paxos sequence ordering). The client caches this version and attaches it to subsequent reads. ZippyDB then ensures that reads reflect data at or after that version.
This model works well for session-bound workloads, like profile updates followed by an immediate refresh.
4 - Fast-Ack Write Mode
In scenarios where write latency matters more than durability, ZippyDB offers a fast-acknowledgment write mode. Writes are acknowledged as soon as they are enqueued on the primary for replication, not after they’re fully persisted in the quorum.
This boosts throughput and responsiveness, but comes with trade-offs:
Lower durability (data could be lost if the primary crashes before replication).
Weaker consistency (readers may not see the write until replication completes).
This mode fits well in systems that can tolerate occasional loss or use an idempotent retry.
Transactions and Conditional Writes
ZippyDB supports transactional semantics for applications that need atomic read-modify-write operations across multiple keys. Unlike systems that offer tunable isolation levels, ZippyDB keeps things simple and safe: all transactions are serializable by default.
Transactions
ZippyDB implements transactions using optimistic concurrency control:
Clients read a database snapshot (usually from a follower) and assemble a write set.
They send both read and write sets, along with the snapshot version, to the primary.
The primary checks for conflicts, whether any other transaction has modified the same keys since the snapshot.
If there are no conflicts, the transaction commits and is replicated via Paxos.
If a conflict is detected, the transaction is rejected, and the client retries. This avoids lock contention but works best when write conflicts are rare.
ZippyDB maintains recent write history to validate transaction eligibility. To keep overhead low, it prunes older states periodically. Transactions spanning epochs (i.e., across primary failovers) are automatically rejected, which simplifies correctness guarantees at the cost of some availability during leader changes.
Conditional Writes
For simpler use cases, ZippyDB exposes a conditional write API that maps internally to a server-side transaction. This API allows operations like:
“Set this key only if it doesn’t exist.”
“Update this value only if it matches X.”
“Delete this key only if it’s present.”
These operations avoid the need for client-side reads and round-trips. Internally, ZippyDB evaluates the precondition, checks for conflicts, and commits the write as a transaction if it passes.

This approach simplifies client code and improves performance in cases where logic depends on the current key's presence or state.
Why was ZippyDB critical To Threads?
Threads didn’t have months to build a custom data infrastructure. It needed to read and write at scale from day one. ZippyDB handled several core responsibilities, such as:
Counters: Like counts, follower tallies, and other rapidly changing metrics.
Feed ranking state: Persisted signals to sort and filter what shows up in a user's home feed.
Search state: Underlying indices that powered real-time discovery.
What made ZippyDB valuable wasn’t just performance but adaptability. As a multi-tenant system, it supported fast onboarding of new services. Teams didn’t have to provision custom shards or replicate schema setups. They configured what they needed and got the benefit of global distribution, consistency guarantees, and monitoring from day one.
At launch, Threads was expected to grow. But few predicted the velocity: 100 million users in under a week. That kind of growth doesn’t allow for manual shard planning or last-minute migrations.
ZippyDB’s resharding protocol turned a potential bottleneck into a non-event. Its clients map data into logical shards, which are dynamically routed to physical machines. When load increases, the system can:
Provision new physical shards.
Reassign logical-to-physical mappings live, without downtime.
Migrate data using background workers that ensure consistency through atomic handoffs.
No changes are required in the application code. The system handles remapping and movement transparently. Automation tools orchestrate these transitions, enabling horizontal scale-out at the moment it's needed, not hours or days later.
This approach allowed Threads to start small, conserve resources during early development, and scale adaptively as usage exploded, without risking outages or degraded performance.
During Threads’ launch window, the platform absorbed thousands of machines in a matter of hours. Multi-tenancy played a key role here. Slack capacity from lower-usage keyspaces was reallocated, and isolation boundaries ensured that Threads could scale up without starving other workloads.
Async - Serverless at Meta Scale
Async is Meta’s internal serverless compute platform, formally known as XFaaS (eXtensible Function-as-a-Service).
At peak, Async handles trillions of function calls per day across more than 100,000 servers. It supports multiple languages such as HackLang, Python, Haskell, and Erlang.
What sets Async apart is the fact that it abstracts away everything between writing a function and running it on a global scale. There is no need for service provisioning. Drop code into Async, and it inherits Meta-grade scaling, execution guarantees, and disaster resilience.

Async’s Role in Threads
When Threads launched, one of the most critical features wasn’t visible in the UI. It was the ability to replicate a user’s Instagram follow graph with a single tap. Behind that one action sat millions of function calls: each new Threads user potentially following hundreds or thousands of accounts in bulk.
Doing that synchronously would have been a non-starter. Blocking the UI on graph replication would have led to timeouts, poor responsiveness, and frustrated users. Instead, Threads offloaded that work to Async.
Async queued those jobs, spread them across the fleet, and executed them in a controlled manner. That same pattern repeated every time a celebrity joined Threads—millions of users received follow recommendations and notifications, all piped through Async without spiking database load or flooding services downstream.
How Async Handled the Surge
Async didn’t need to be tuned for Threads. It scaled the way it always does.
Several features were key to the success of Threads:
Queueing deferred less-urgent jobs to prevent contention with real-time tasks.
Batching combined many lightweight jobs into fewer, heavier ones, reducing overhead on dispatchers and improving cache efficiency.
Capacity-aware scheduling throttled job execution when downstream systems (like ZippyDB or the social graph service) showed signs of saturation.

This wasn’t reactive tuning. It was a proactive adaptation. Async observed system load and adjusted flow rates automatically. Threads engineers didn’t need to page anyone or reconfigure services. Async matched its execution rate to what the ecosystem could handle.
Developer Experience
One of the most powerful aspects of Async is that the Threads engineers didn’t need to think about scale. Once business logic was written and onboarded into Async, the platform handled the rest:
Delivery windows: Jobs could specify execution timing, allowing deferment or prioritization.
Retries: Transient failures were retried with backoff, transparently.
Auto-throttling: Job rates were adjusted dynamically based on system health.
Multi-tenancy isolation: Surges in one product didn’t impact another.
These guarantees allowed engineers to focus on product behavior, not operational limits. Async delivered a layer of predictable elasticity, absorbing traffic spikes that would have crippled a less mature system.
Conclusion
The Threads launch was like a stress test for Meta’s infrastructure. And the results spoke for themselves. A hundred million users joined in less than a week. But there were no major outages.
That kind of scale doesn’t happen by chance.
ZippyDB and Async weren’t built with Threads in mind. But Threads only succeeded because those systems were already in place, hardened by a decade of serving billions of users across Meta’s core apps. They delivered consistency, durability, elasticity, and observability without demanding custom effort from the product team.
This is the direction high-velocity engineering is heading: modular infrastructure pieces that are composable and deeply battle-tested. Not all systems need to be cutting-edge. However, the ones handling critical paths, such as state, compute, and messaging, must be predictable, reliable, and invisible.
References:
How we built a general-purpose key-value store for Facebook with ZippyDB
Asynchronous computing @Facebook: Driving efficiency and developer productivity at Facebook scale
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.