
How Meta Uses AI Agents for Data Warehouse Access and Security

👋 Goodbye low test coverage and slow QA cycles (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native solution provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to minutes.
They can get you:
80% automated E2E test coverage in weeks—not years
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
Disclaimer: The details in this post have been derived from the details shared online by the Meta Engineering Team. All credit for the technical details goes to the Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Meta has one of the largest data warehouses in the world, supporting analytics, machine learning, and AI workloads across many teams. Every business decision, experiment, and product improvement relies on quick, secure access to this data.
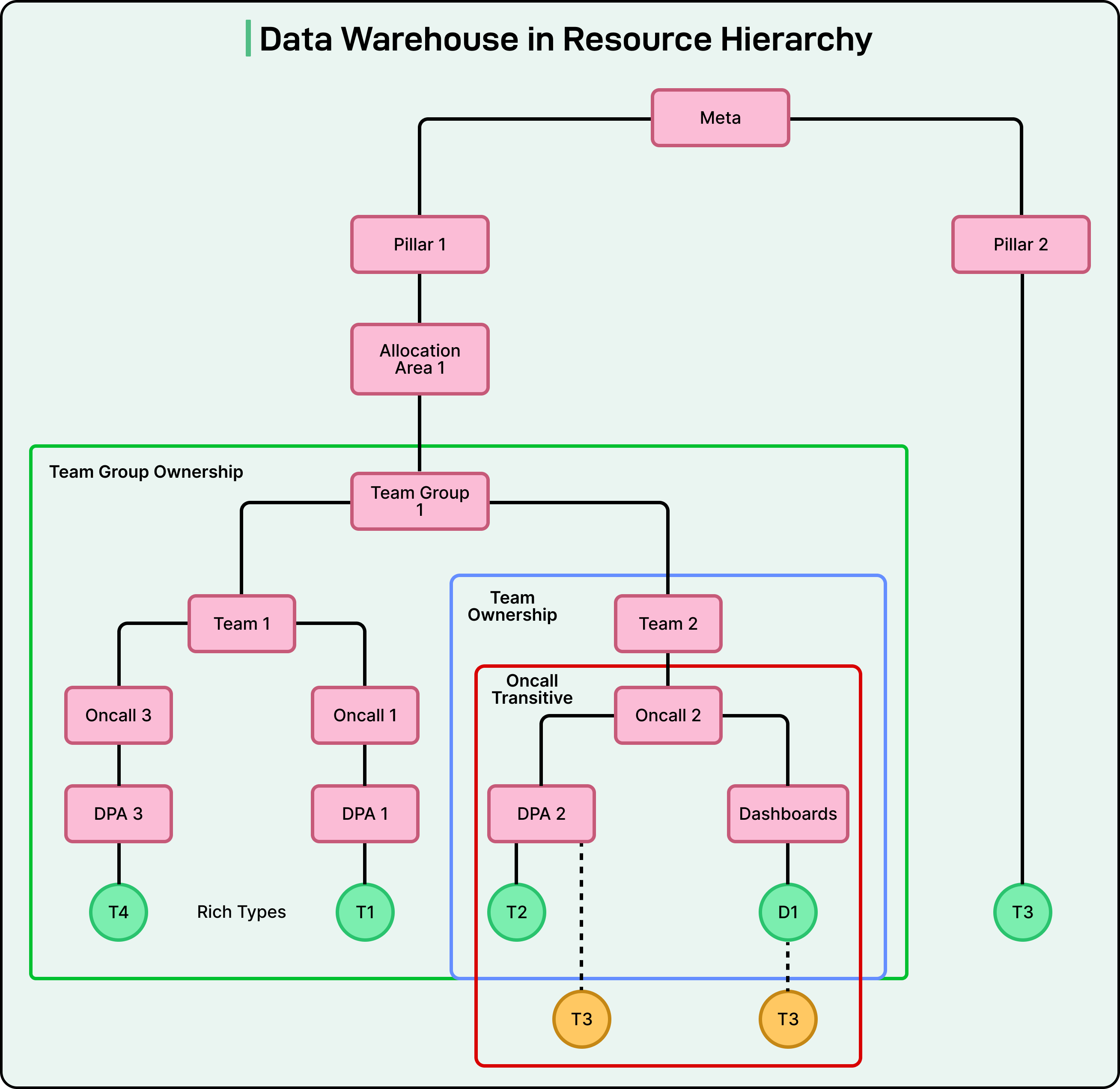
To organize such a vast system, Meta built its data warehouse as a hierarchy. At the top are teams and organizations, followed by datasets, tables, and finally dashboards that visualize insights. Each level connects to the next, forming a structure where every piece of data can be traced back to its origin.
Access to these data assets has traditionally been managed through role-based access control (RBAC). This means access permissions are granted based on job roles. A marketing analyst, for example, can view marketing performance data, while an infrastructure engineer can view server performance logs. When someone needed additional data, they would manually request it from the data owner, who would approve or deny access based on company policies.
This manual process worked well in the early stages. However, as Meta’s operations and AI systems expanded, this model began to strain under its own weight. Managing who could access what became a complex and time-consuming process.
Three major problems began to emerge:
The data graph became massive. Each table, dashboard, and data pipeline connects to others, forming a web of relationships. Understanding dependencies and granting permissions safely across this web became difficult.
Access decisions became slower and required multiple approvals. Different teams had to coordinate across departments to manage security.
AI systems changed how data was used. Earlier, each team mainly worked within its own data domain. Now, AI models often need to analyze data from multiple domains at once. The traditional human-managed access system could not keep up with these cross-domain patterns.
To keep innovation moving while maintaining security, Meta had to find a better way to handle the problem of data access at scale. The Meta engineering team discovered that the answer lay in AI agents. These agents are intelligent software systems capable of understanding requests, evaluating risks, and making decisions autonomously within predefined boundaries
In this article, we look at how Meta redesigned their data warehouse architecture to work with both humans and agents.
The Agentic Solution: Two-Agent Architecture
To overcome the growing complexity of data access, the Meta engineering team developed what they call a multi-agent system.
In simple terms, it is a setup where different AI agents work together, each handling specific parts of the data-access workflow. This design allows Meta to make data access both faster and safer by letting agents take over the repetitive and procedural tasks that humans once did manually.
At the heart of this system are two key types of agents that interact with each other:
Data-user agents, which act on behalf of employees or systems that need access to data.
Data-owner agents, which act on behalf of the people or teams responsible for managing and protecting data.
See the diagram below:

Data-User Agent
The data-user agent is not one single program. Instead, it is a group of smaller, specialized agents that work together. These sub-agents are coordinated by a triage layer, which acts like a manager that decides which sub-agent should handle each part of the task.
See the diagram below:
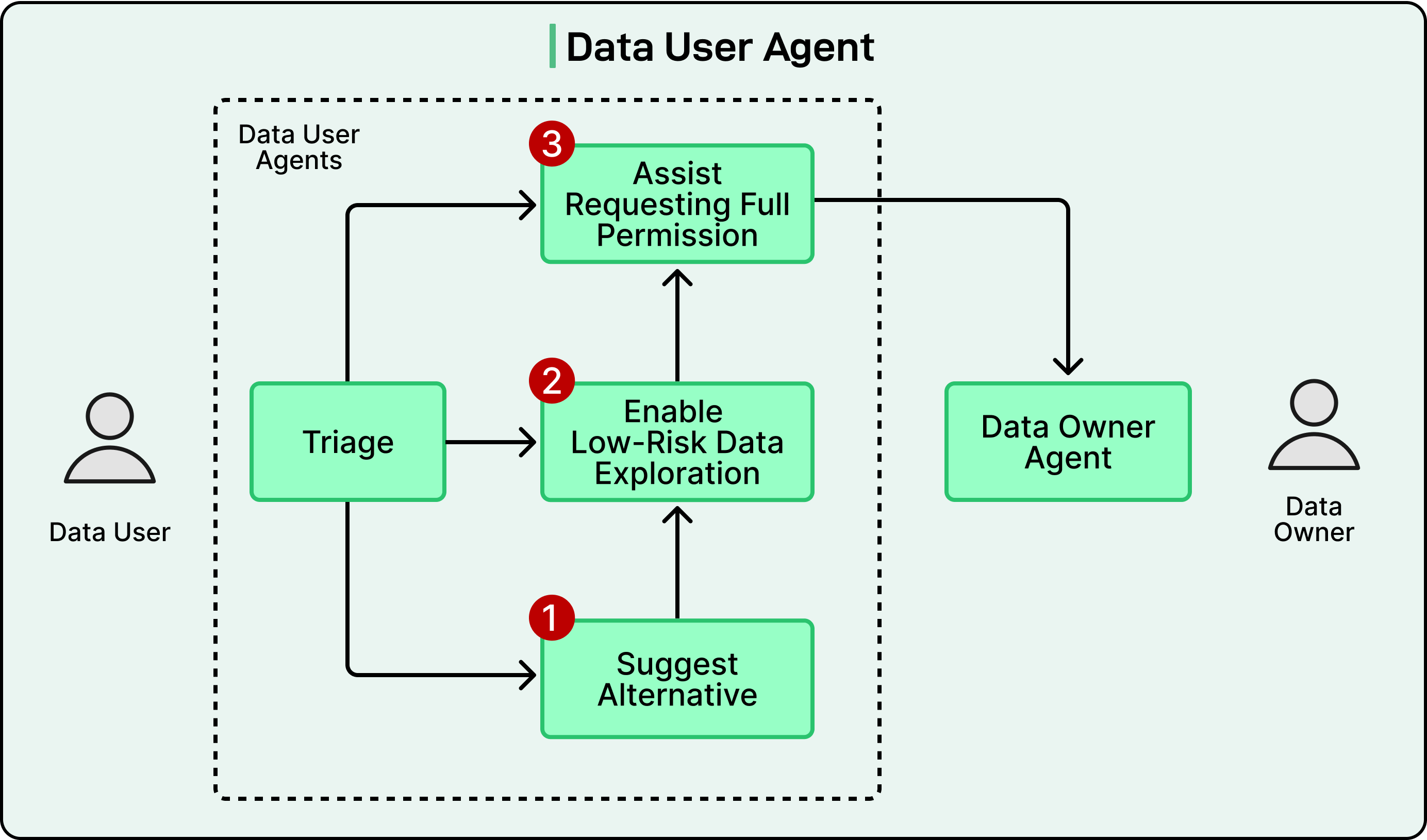
There are three main sub-agents inside this structure:
Alternative-suggestion Sub-agent
This sub-agent helps users find safer or less restricted ways to access the information they need. For example, if someone requests access to a sensitive data table, the agent might recommend another table that contains similar but non-sensitive data. It can even help rewrite queries to use only unrestricted columns or public data sources.
The sub-agent relies on large language models (LLMs) to reason about relationships between datasets. Traditionally, this kind of knowledge existed only as “tribal knowledge”, meaning it was known informally by a few experienced engineers. Now, the agent can synthesize that hidden information and offer intelligent recommendations automatically.
Low-risk exploration sub-agent
Most users do not need full access to an entire dataset when they are still exploring. Often, they just need to look at a small portion to understand its structure or content.
This sub-agent provides temporary or partial access to small data samples so that users can explore safely. It ensures that this kind of low-risk exploration does not expose sensitive information.
Access-negotiation sub-agent
When full access is required, this sub-agent prepares the formal permission request. It communicates directly with the data-owner agent to request access based on business needs and data policies.
At the moment, Meta keeps a human in the loop to supervise these interactions, meaning a person reviews or confirms the agent’s actions. However, the engineering team expects that, over time, this sub-agent will be able to operate more autonomously as the system matures and safety mechanisms improve.
Data-Owner Agent
On the other side of the workflow is the data-owner agent, which represents the data managers or teams that control sensitive information.
It also consists of specialized components, each focusing on a different responsibility. See the diagram below:

Let’s look at the two main components of the data owner agent:
Security-operations sub-agent
This sub-agent functions like a junior security engineer. It follows Standard Operating Procedures (SOPs) written by data owners and applies them to incoming access requests.
When a data-user agent sends a request, this sub-agent checks it against the established rules and risk policies. It ensures that the request follows security protocols and that only legitimate users with valid purposes are granted access.
Access-management sub-agent
Beyond handling requests, this sub-agent takes a proactive role in shaping and maintaining access policies. It evolves the older “role-mining” process, where engineers manually examined user roles and permissions, into a smarter, automated system.
Using metadata, data semantics, and historical access patterns, it continuously refines and optimizes who should have access to which resources. This helps Meta reduce the manual overhead of managing permissions while still keeping the data warehouse secure.
Making the Data Warehouse Agent-Friendly
The next challenge for the Meta engineering team was to make the data warehouse usable not only by humans but also by AI agents.
Unlike people, agents interact through text-based interfaces. This means they cannot browse graphical dashboards or manually navigate folders. They need information presented in a structured, text-readable format that they can process and reason about.
To achieve this, Meta redesigned the data warehouse into what can be described as a text-navigable hierarchy, similar to how folders and files are organized on a computer. In this setup, each element in the warehouse (such as a table, a dashboard, or a policy) is treated as a resource. Agents can read these resources and understand how they relate to one another. The system turns complex warehouse objects into text summaries that describe what each resource represents and how it can be used.
In addition, important materials like SOPs, internal documentation, and even historical access rules are also represented as text. This approach allows LLMs powering the agents to analyze these textual resources just as they would analyze written information in a document.
Managing Context and Intention
To make good decisions about data access, an AI agent must understand the full situation around a request. The Meta engineering team calls this context and intention management. Together, these two concepts help the agent figure out who is asking for data, what they are trying to access, and why they need it.
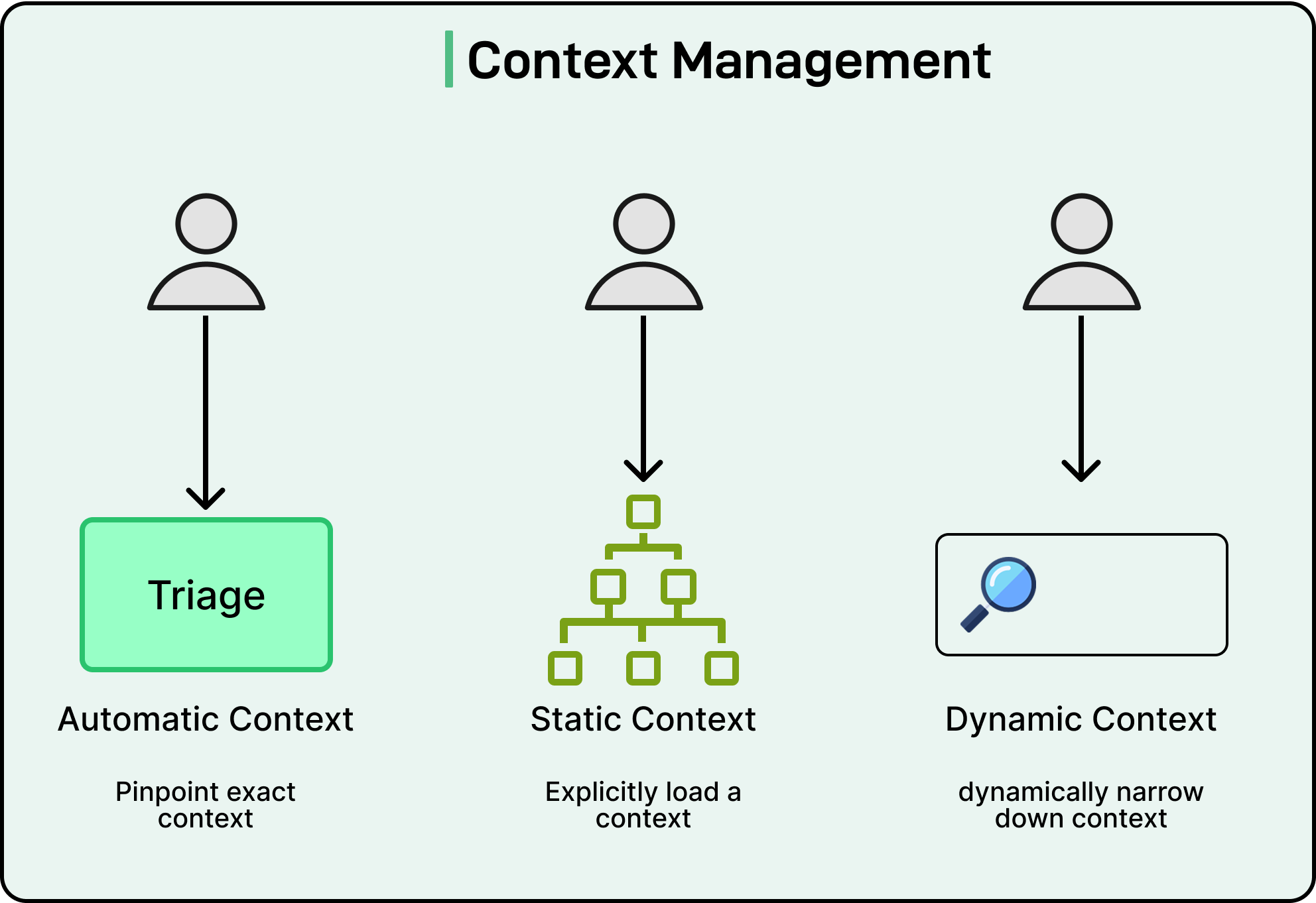
Let’s start with context management. Context gives the agent the background information it needs before acting. Meta defines three main types of context:
Automatic context: When someone tries to open a dataset or run a query, the system already knows who they are and what resource they are attempting to access. This information is collected automatically from internal tools and user identities.
Static context: Sometimes, a user wants to focus on a specific project or dataset category. They can define that scope manually. For example, an engineer could choose to work within the “Ad Metrics” project area to limit search results to relevant tables.
Dynamic context: Agents can refine context further by analyzing metadata or performing similarity searches. For instance, if a user is studying ad-spend data, the agent can automatically find other tables related to ad budgets or campaign performance.
Once context is clear, the next step is intention management, which identifies the reason behind a user’s request. Meta approaches this in two ways:
Explicit intention is when a user clearly states their purpose. For example, they might indicate that they are “investigating ad performance for Q3”. The system can then match this role or goal with appropriate data-access policies.
Implicit intention is when the system infers purpose from user behavior. If an engineer suddenly starts accessing error logs at midnight, the system can reasonably assume they are responding to an outage and temporarily grant limited diagnostic access.
Deep Dive: Partial Data Preview
To understand how Meta’s agentic data-access system actually works, let’s look at an end-to-end example.
The process begins when a data scientist wants to look at new data for analysis. Instead of immediately granting full access to an entire dataset, the low-risk exploration sub-agent steps in first. It allows the user to view a small, limited sample of the data so they can understand its structure and decide if it is relevant to their task. At this stage, context-aware controls ensure that only non-sensitive parts of the dataset are visible.
If the user later needs deeper or broader access, the access-negotiation sub-agent automatically prepares a formal permission request and contacts the data-owner agent for review. This workflow not only speeds up exploration but also keeps security intact by enforcing layers of protection at every step.
The entire system operates through four major capabilities:
Context analysis: The agent understands what the user is trying to do and matches it with business rules and policies.
Query-level access control: Each query is examined to see how much data it touches and whether it performs aggregations or random sampling. This helps the system judge the potential risk of exposure.
Data-access budgets: Every employee has a daily quota of how much data they can access. This budget resets automatically every day and acts as a safeguard against accidental overexposure.
Rule-based risk management: The system continuously monitors agent behavior through analytical risk rules, catching anything unusual or potentially unsafe.
See the diagram below:
Behind the scenes, a complex architecture powers this workflow.
The data-user agent serves as the entry point. It collects signals from several internal tools:
User-activity logs, which include actions like editing code (diffs), viewing dashboards, completing tasks, or handling service events.
User-profile information, such as team, role, and current project details.
Using this information, the agent builds an intention model, a structured understanding of why the user is making the request and what they need to accomplish. This model is combined with the shape of the query (for example, whether it is reading a few rows, aggregating data, or joining large tables) to form a complete picture of the situation.
Once this intention is formed, the data-user agent hands control to the data-owner agent. This second agent retrieves metadata about the requested resources, including table summaries, column descriptions, and SOPs. It then uses a large language model (LLM) to reason about whether access should be granted or denied. The LLM’s reasoning is checked by a set of guardrails that apply rule-based risk calculations to make sure the outcome aligns with security policies.
See the diagram below:
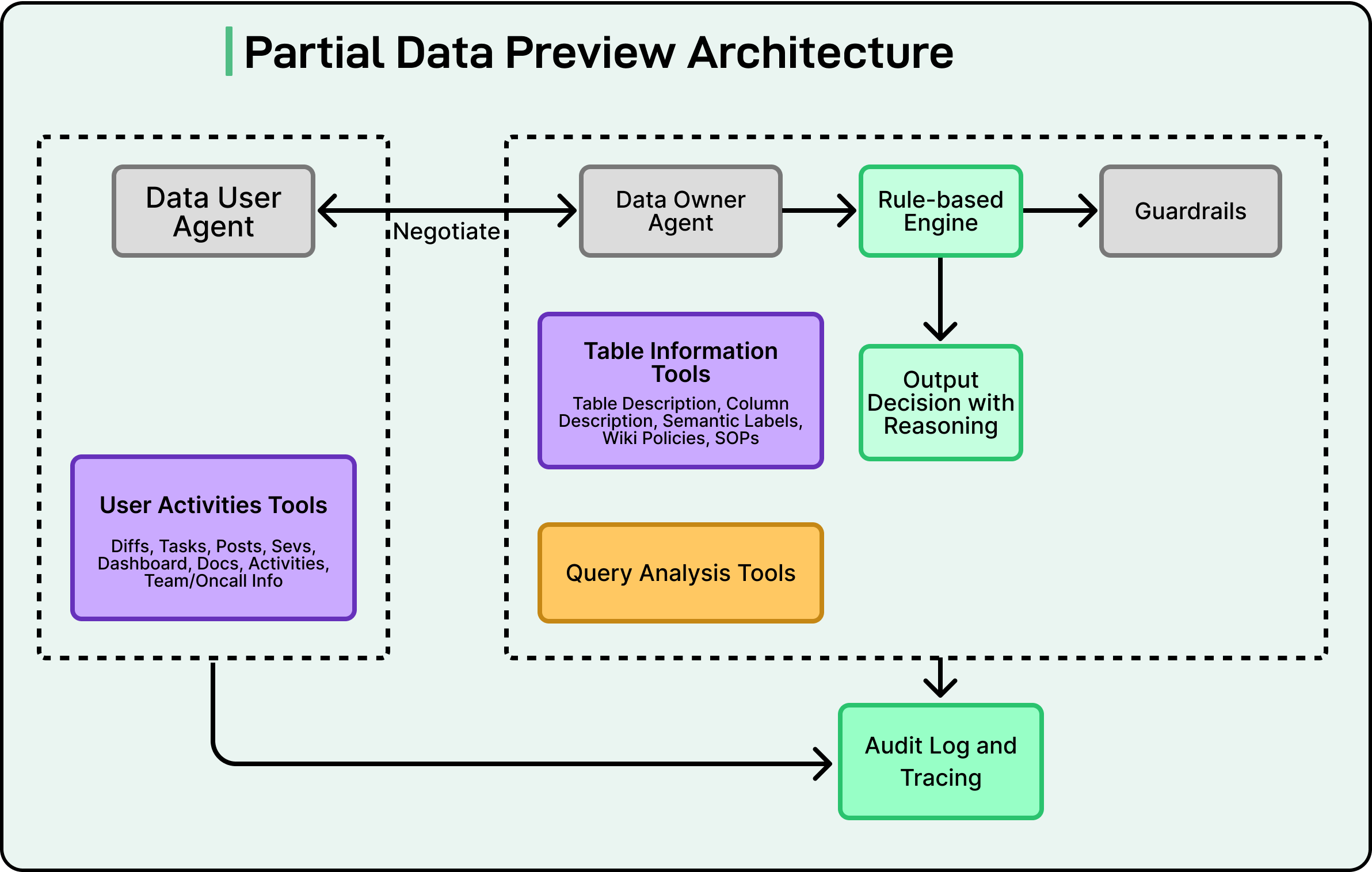
Every action, decision, and result is logged securely for future auditing and analysis. This makes it possible to trace exactly how and why each access decision was made.
Conclusion
The Meta engineering team has made significant progress toward transforming how data is accessed and secured across its massive warehouse systems. However, the journey toward a fully agent-ready infrastructure is still ongoing. The long-term vision is to create a system where both humans and AI agents can work side by side, safely and efficiently, without adding complexity or risk.
The first area of continued focus is agent collaboration. Meta is increasingly seeing scenarios where agents act on behalf of users without direct human input. In the future, these agents may communicate and negotiate with each other automatically. To support this, Meta needs to refine how agents interact, ensuring that every exchange remains transparent, auditable, and aligned with company policies.
Next, the infrastructure itself must evolve. Many of Meta’s warehouse tools, APIs, and interfaces were originally built for human use. To fully enable machine-to-machine workflows, these systems must be reengineered to accommodate automated reasoning, contextual understanding, and safe delegation between agents.
Finally, Meta is investing heavily in benchmarking and evaluation. For agents to operate safely, the company must continuously measure performance, accuracy, and compliance. This involves defining clear metrics and running regular evaluations to detect errors or regressions. The feedback loop created by human review and automated assessment ensures that the system learns and improves over time.
In summary, Meta’s data warehouse now integrates AI agents that not only request but also approve access in a controlled manner. The combination of LLM-based reasoning with rule-based guardrails ensures that productivity and security remain balanced.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.