
How Netflix Built a Distributed Counter for Billions of User Interactions

Build AI Agents with Dynamiq in Just Hours (Sponsored)

Break free from traditional no-code tool constraints and build multi-agents with a fully customizable low-code interface.
Free plan lets you design, test, and deploy multi-agent systems at zero cost (no credit card required).
Start instantly with pre-built agent templates, and extend functionality using our open-source Python package.
Built-in Knowledge Bases with an integrated workflow automatically split, embed, and store documents in a vector database - fully customizable, like everything else.
Switch between LLMs in just a few clicks and deploy anywhere - on-prem, cloud, or hybrid setups.
Whether you’re working with top LLMs or building advanced workflows, we’ve got you covered.
Disclaimer: The details in this post have been derived from the Netflix Tech Blog. All credit for the technical details goes to the Netflix engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Netflix operates at an incredible scale, with millions of users interacting with its platform every second.
To provide a great user experience, Netflix needs to track and measure these interactions—for example, counting how many users are watching a new show or clicking on specific features. These numbers help Netflix make real-time decisions about improving user experience, optimizing its infrastructure, and running experiments like A/B tests.
However, counting at such a massive scale is not straightforward. Imagine trying to count millions of events happening worldwide simultaneously while ensuring the results are fast, accurate, and cost-effective.
That’s where the Distributed Counter Abstraction comes in.
This system is designed to handle counting in a way that meets Netflix's demanding requirements:
Low Latency: Counts need to be updated and available within milliseconds.
High Throughput: The system must handle thousands of updates per second without bottlenecks.
Cost Efficiency: Managing such a large-scale system shouldn’t break the bank.
In this article, we’ll look at how Netflix built a Distributed Counter Abstraction and the challenges they faced.
Why the Need for a Distributed Counter?
Netflix needs to count millions of events every second across its global platform. These events could be anything: the number of times a feature is used, how often a show is clicked, or even detailed metrics from experiments like A/B testing
The challenge is that these counting needs aren’t one-size-fits-all.
Some situations require quick, approximate results, while others need precise and durable counts. This is where Netflix’s Distributed Counter Abstraction shines, offering flexibility to address these diverse needs.
There are two broad categories of counting:
Best-Effort Counting: This type of counting is used when speed is more important than accuracy. The counts don’t need to be perfectly precise, and they aren’t stored for a long time. It works well for scenarios like A/B testing, where approximate counts are enough to compare the performance of two groups.
Eventually Consistent Counting: This type is used when accuracy and durability are critical. Although it may take a little longer to get the final count, it ensures the results are correct and preserved. This is ideal for metrics that must be recorded precisely over time, such as billing, regulatory compliance, or critical usage reports.
We will look at both categories in more detail in a later section.
However, both categories share some key requirements that are as follows:
High Availability: The system must always be up and running, even during failures or high demand. Netflix cannot afford downtime in counting since these metrics often drive critical decisions.
High Throughput: The system must handle millions of counting operations per second. This means it needs to efficiently process a huge volume of incoming data without bottlenecks.
Scalability: Netflix operates globally, so the counting system must scale horizontally across multiple regions and handle spikes in usage like during the release of a new show.
The table below shows these requirements in more detail:

The Counter Abstraction API Design
The Distributed Counter abstraction was designed as a highly configurable and user-friendly system.
The abstraction provides an API that is simple yet powerful, enabling clients to interact with counters consistently. The main API operations are as follows:
1 - Add Count/AddAndGetCount
The purpose of this endpoint is to increment or decrement a counter by a specified value.
The client specifies the namespace (for example, “user_metrics”), the counter name (for example, “views_counter”), and the delta (a positive or negative value to adjust the count). The API returns the updated count immediately after applying the delta.
See the example below:
{
"namespace": "user_metrics",
"counter_name": "views_counter",
"delta": 5,
"idempotency_token": {
"token": "unique_event_id",
"generation_time": "2025-01-28T14:48:00Z"
}
}Here, the idempotency token ensures that repeated requests (due to retries) do not result in double-counting.
2 - GetCount
This endpoint helps to retrieve the current value of a counter.
The client specifies the namespace and counter name, and the system fetches the value. Here’s an example API request:
{
"namespace": "user_metrics",
"counter_name": "views_counter"
}This operation is optimized for speed, returning slightly stale counts in some configurations to maintain performance.
3 - ClearCount
This endpoint helps reset a counter’s value to zero.
Similar to other requests, the client provides the namespace and counter name. This operation also supports idempotency tokens to ensure safe retries.
Counting Techniques
The Distributed Counter abstraction supports several types of counters to meet Netflix's diverse counting requirements. Each approach balances trade-offs between speed, accuracy, durability, and infrastructure cost.
Here’s a detailed breakdown of the main counting strategies:
Best-Effort Regional Counter
This is a lightweight counting approach optimized for speed and low infrastructure cost. It provides quick but approximate counts.
It is built on EVCache, Netflix’s distributed caching solution based on Memcached. Counts are stored as key-value pairs in a cache with minimal latency and high throughput. TTL (Time-To-Live) ensures counters don’t occupy the cache indefinitely.
The best-effort counter is ideal for short-lived experiments like A/B testing where precise counts aren’t critical. The advantages of this type of counter are as follows:
Extremely fast with millisecond-level latency.
Cost-effective due to shared multi-tenant clusters.
However, there are also disadvantages to this approach:
No cross-region replication for counters.
Lacks idempotency, making retries unsafe.
Cannot guarantee consistency across nodes.
Eventually Consistent Global Counter
For scenarios where accuracy and durability are crucial, there are several approaches available under the eventually consistent model. These ensure that counters converge to accurate values over time, though some delays are acceptable.
1 - Single Row Per Counter
It’s a straightforward approach where each counter is represented by a single row in a globally replicated datastore.
See the table below for example:

Despite its simplicity, this approach has some disadvantages such as:
Vulnerable to data loss if an instance fails before flushing its counts.
Difficult to synchronize counter resets across instances.
Lacks idempotency, thereby complicating retries.
2 - Per Instance Aggregation
This approach aggregates counts in memory on individual instances, then periodically writes the aggregated values to a durable store. This process is known as flushing. Introducing sufficient jitter to the flush process helps reduce contention.
See the diagram below for reference:

The main advantage of this approach is that it reduces contention by limiting updates to the durable store. However, it also poses some challenges such as:
Vulnerable to data loss if an instance fails before flushing its counts.
Difficult to synchronize counter resets across instances.
Lacks idempotency.
3 - Durable Queues
This approach logs counter events to a durable queuing system like Apache Kafka. Events are processed in batches for aggregation. Here’s how it works:
Counter events are written to specific Kafka partitions based on a hash of the counter key.
Consumers read from partitions, aggregate events, and store the results in a durable store.
See the diagram below:

This approach is reliable and fault tolerant due to durable logs. Also, idempotency is easier to implement, preventing overcounting during retries.
However, it can cause potential delays if consumers fall behind. Rebalancing partitions as counters or throughput increases can be complex.
4 - Event Log of Increments
This approach logs every individual increment (or decrement) as an event with metadata such as event time and event_id. The event_id can include the source information of where the operation originated.
See the diagram below:

The combination of event_time and event_id can also serve as the idempotency key for the write.
However, this approach also has several drawbacks:
High storage cost due to the need to retain every increment.
Degraded read performance as it requires scanning all events for a counter.
Wide partitions in databases like Cassandra can slow down queries.
Netflix’s Hybrid Approach
Netflix’s counting needs are vast and diverse, requiring a solution that balances speed, accuracy, durability, and scalability.
To meet these demands, Netflix developed a hybrid approach that combines the strengths of various counting techniques we’ve discussed so far. This approach uses event logging, background aggregation, and caching to create a system that is both scalable and efficient, while also maintaining eventual consistency.
Let’s understand the approach in more detail:
1 - Logging Events in the TimeSeries Abstraction
At the core of Netflix’s solution is its TimeSeries Abstraction, a high-performance service designed for managing temporal data.
Netflix leverages this system to log every counter event as an individual record, allowing precise tracking and scalability.
Each counter event is recorded with metadata, including:
event_time: The time the event occurred.
event_id: A unique identifier for the event to ensure idempotency.
event_item_key: Specifies the counter being updated.
Events are organized into time buckets (for example, by minute or hour) to prevent wide partitions in the database. Unique event IDs prevent duplicate counting, even if retries occur.
2 - Aggregation Processes for High Cardinality Counters
To avoid the inefficiency of fetching and recalculating counts from raw events during every read, Netflix employs a background aggregation process. This system continuously consolidates events into summarized counts, reducing storage and read overhead.
Aggregation occurs within defined time windows to ensure data consistency. An immutable window is used, meaning only finalized events (not subject to further updates) are aggregated.
The Last Rollup Timestamp tracks the last time a counter was aggregated. It ensures that the system only processes new events since the previous rollup.
Here’s how the aggregation process works:
The rollup process collects all events for a counter within the aggregation window. It summarizes the total count and updates the rollup store.
Aggregated counts are stored in a durable system like Cassandra for persistence. Future aggregations build on this checkpoint, reducing computation costs.
Rollups are triggered during writes and reads. For writes, it is triggered when a lightweight event notifies the system of changes. During reads, when a user fetches a counter, rollups are triggered if the count is stale.
See the diagram below for the write path process:

Next, we have the diagram below that shows the read or getCount process:

Aggregation reduces the need to repeatedly process raw events, improving read performance. By using immutable windows, Netflix ensures that counts are accurate within a reasonable delay.
3 - Caching for Optimized Reads
While the aggregation process ensures counts are eventually consistent, caching is used to further enhance performance for frequently accessed counters. Netflix integrates EVCache (a distributed caching solution) to store rolled-up counts.
The cache holds the last aggregated count and the corresponding last rollup timestamp. When a counter is read, the cached value is returned immediately, providing a near-real-time response. A background rollup is triggered to ensure the cache stays up to date.
Cached counts allow users to retrieve values in milliseconds, even if they are slightly stale. Also, caching minimizes direct queries to the underlying datastore, saving infrastructure costs.
Key Benefits of the Hybrid Approach
The hybrid approach has several benefits such as:
Combining Accuracy and Performance: It logs every event for precise recounting when needed. Aggregates events in the background to maintain high read performance.
Scales with High Cardinality: Handles millions of counters efficiently using time and event bucketing. This ensures an even distribution of workload across storage and processing systems.
Ensures Reliability: Uses idempotency tokens to handle retries safely. Also, it employs persistent storage (for example, Cassandra) and caches for fault tolerance.
Balances Trade-Offs: Sacrifices some immediacy for eventual consistency in global counts. It also introduces slight delays in aggregation to maintain accuracy within immutable windows.
Scaling the Rollup Pipeline
To manage millions of counters across the globe while maintaining high performance, Netflix uses a Rollup Pipeline. This is a sophisticated system that processes counter events efficiently, aggregates them in the background, and scales to handle massive workloads.
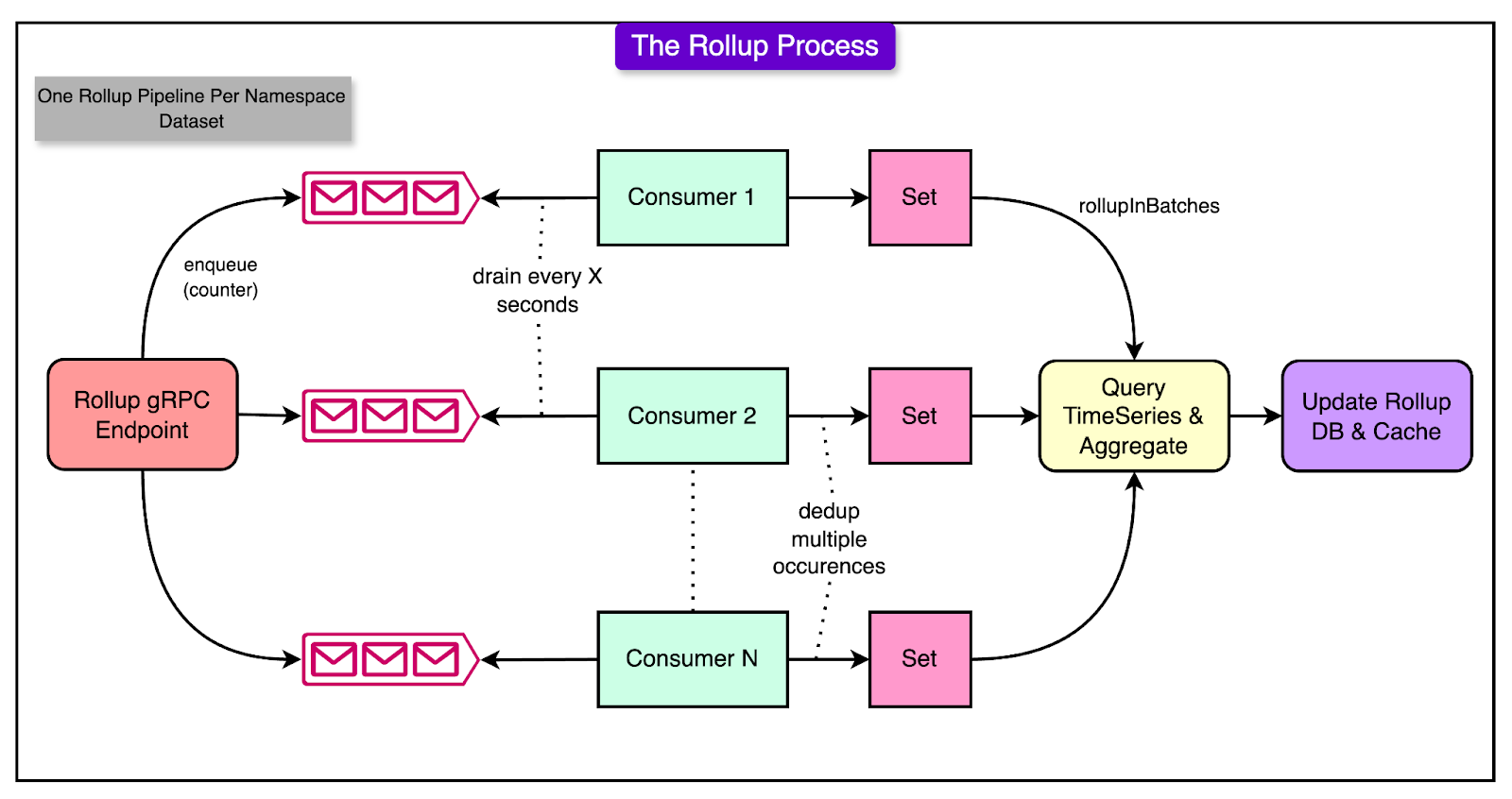
There are three main parts of this rollup pipeline:
1 - Rollup Events and Queues
When a counter is updated (via an AddCount, ClearCount, or GetCount operation), the system generates a lightweight rollup event.
This event notifies the Rollup Pipeline that the counter requires aggregation. The rollup event itself does not include the raw data but merely identifies the counter needing processing.
Here’s how rollup queues work:
Each Rollup Server instance maintains in-memory queues that receive rollup events. These queues allow parallel processing of aggregation tasks, enabling the system to handle high-throughput workloads.
A fast, non-cryptographic hash function (for example, XXHash) ensures that related counters are consistently routed to the same queue. This minimizes duplicate work and improves efficiency.
Multiple events for the same counter are consolidated into a Set, so each counter is rolled up only once within a rollup window.
Netflix opted for in-memory rollup queues to simplify provisioning and reduce costs. This design is easier to implement compared to a fully durable queuing system.
However, there are some potential risks as well.
If a rollup server crashes before processing all events, those events are lost. This is mitigated for frequently accessed counters, as subsequent operations trigger new rollups.
During deployments or scaling, there may be brief overlaps where both old and new servers are active. However, this is managed safely because aggregations occur within immutable windows.
When workloads increase, Netflix scales the Rollup Pipeline by increasing the number of rollup queues and redeploying the rollup servers with updated configurations.
The process is seamless with old servers gracefully shutting down after draining their events. During deployments, both old and new Rollup Servers may briefly handle the same counters. This avoids downtime but introduces slight variability in counts, which is eventually resolved as counts converge.
2 - Dynamic Batching and Back-Pressure
To optimize performance, the Rollup Pipeline processes counters in batches rather than individually.
The size of each batch adjusts dynamically based on system load and counter cardinality. This prevents the system from overwhelming the underlying data store (for example, Cassandra). Within a batch, the pipeline queries the TimeSeries Abstraction in parallel to aggregate events for multiple counters simultaneously.
See the diagram below:

The system monitors the performance of each batch and uses this information to control the processing rate. After processing one batch, the pipeline pauses before starting the next, based on how quickly the previous batch is completed. This adaptive mechanism ensures the system doesn’t overload the storage backend during high traffic.
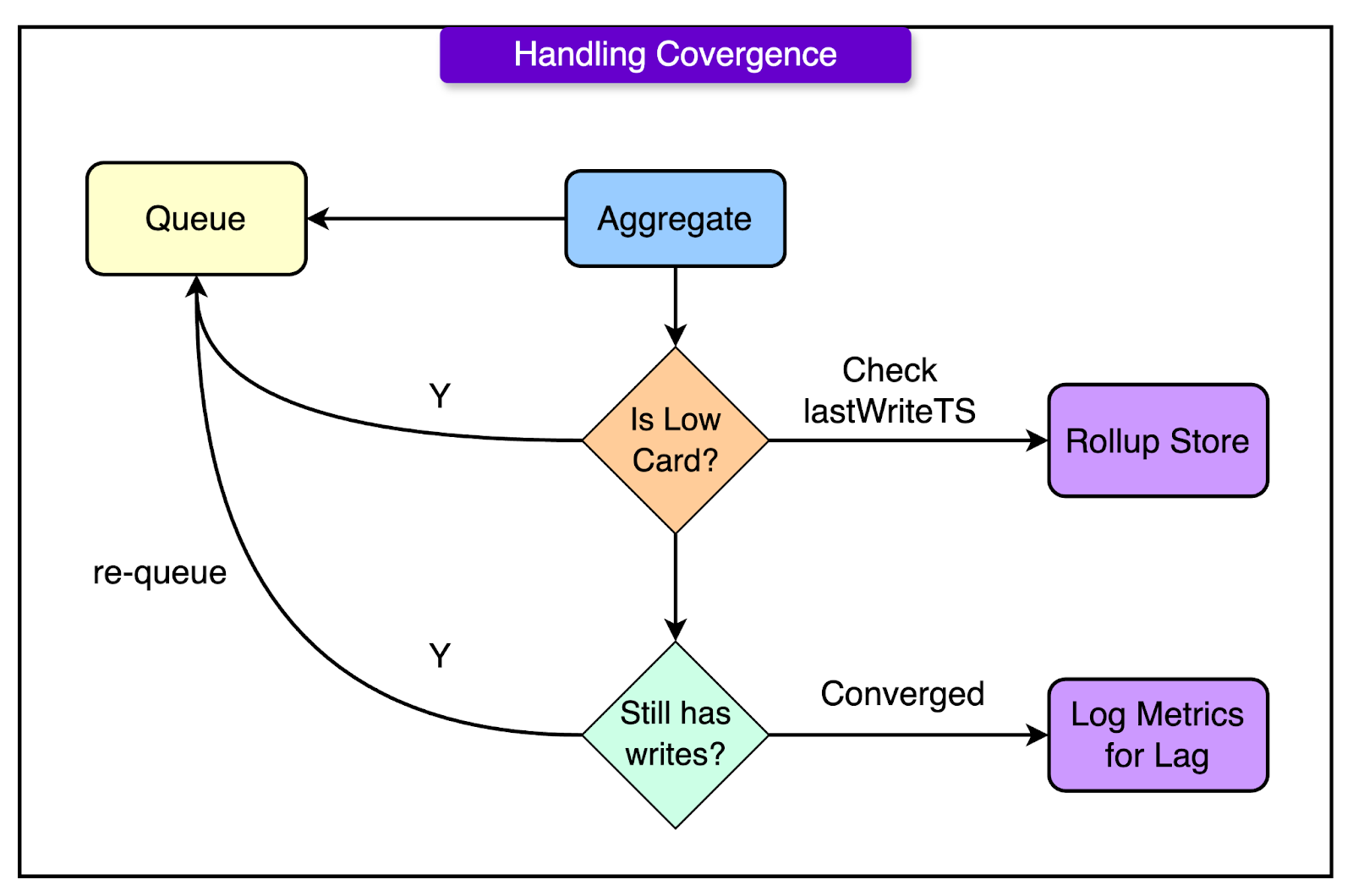
3 - Handling Convergence for Low and High Cardinality Counters
Low cardinality counters are frequently accessed but have fewer unique instances. The pipeline keeps them in continuous rollup circulation to ensure they remain up to date.
On the other hand, high-cardinality counters have many unique instances (such as per-user metrics) and may not be accessed frequently. To avoid excessive memory usage, the pipeline uses the last-write-timestamp to determine when a counter needs to be re-queued. This ensures aggregation continues until all updates are processed.
See the diagram below:
Centralized Configuration of the Control Plane
At the heart of Netflix’s Distributed Counter Abstraction is its control plane, a centralized system that manages configuration, deployment, and operational complexity across the abstraction layers.
See the diagram below:

The control plane allows Netflix to fine-tune every aspect of the counting service, ensuring it meets the needs of diverse use cases without requiring manual intervention or re-engineering.
1 - Role of the Control Plane
The Control Plane serves as a management hub for all configurations related to the Distributed Counter Abstraction. It is responsible for:
Configuring the persistence mechanisms for counters.
Adjusting settings for specific use cases, such as high or low-cardinality counters.
Implementing strategies for data retention, caching, and durability.
This centralized management ensures that teams across Netflix can focus on their use cases without worrying about the underlying complexities of distributed counting.
2 - Configuring Persistent Mechanisms
The Control Plane enables the configuration of persistence layers for storing counter data.
Netflix uses a combination of EVCache (for caching) and Cassandra (for durable storage). The control plane coordinates their interaction.
EVCache is used for fast, low-latency access to counters. The control plane specifies parameters such as cache size and expiration policies.
{
"id": "CACHE",
"physical_storage": {
"type": "EVCACHE",
"cluster": "evcache_dgw_counter_tier1"
}
}Cassandra is used as the primary datastore for durable, long-term storage of counters and their rollups.
The configurable parameters for this include:
Keyspace settings, such as the number of partitions.
Time partitioning for counters (for example, breaking data into manageable time buckets).
Retention policies to prevent excessive storage use.
See the example configuration below:
{
"id": "COUNTER_ROLLUP",
"physical_storage": {
"type": "CASSANDRA",
"cluster": "cass_dgw_counter_uc1",
"dataset": "my_dataset"
}
}3 - Supporting Different Cardinality Strategies
Counters can vary greatly in cardinality i.e. the number of unique counters being managed.
Low-cardinality counters are global metrics like “total views” for a show. Such counters are frequently accessed and require continuous rollup processing. This requires smaller time buckets for aggregation and shorter TTLs for cached values to ensure freshness.
High-cardinality counters include per-user metrics like “views per user”. These counters are less frequently accessed but require efficient handling of a large number of unique keys. They involve larger time buckets to reduce database overhead and efficient partitioning to distribute load across storage nodes.
4 - Retention and Lifecycle Policies
Retention policies ensure that counter data does not grow uncontrollably, reducing costs while maintaining historical relevance.
For example, raw counter events are stored temporarily (such as 7 days) before being deleted or archived. Aggregated rollups are retained longer, as they occupy less space and are useful for long-term metrics.
Also, the control plane ensures counters expire after their intended lifespan, preventing them from consuming unnecessary resources.
5 - Multi-Tenant Support
Netflix’s Control Plane is designed to support a multi-tenant environment where different teams or applications can operate their counters independently:
Each namespace is isolated, allowing configurations to vary based on the use case.
For example, the user_metrics namespace may prioritize low-latency caching for real-time dashboards. Also, the billing_metrics namespace may focus on durability and accuracy for financial reporting.
Conclusion
Distributed counting is a complex problem, but Netflix’s approach demonstrates how thoughtful design and engineering can overcome these challenges.
By combining powerful abstractions like the TimeSeries and Data Gateway Control Plane with innovative techniques like rollup pipelines and dynamic batching, Netflix delivers a counting system that is fast, reliable, and cost-effective.
The system processes 75,000 counter requests per second globally while maintaining single-digit millisecond latency for API endpoints. This incredible performance is achieved through careful design choices, including dynamic batching, caching with EVCache, and efficient aggregation processes.

The principles behind Netflix’s Distributed Counter Abstraction extend well beyond their platform. Any large-scale system requiring real-time metrics, distributed event tracking, or global consistency can benefit from a similar architecture
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
After reading this I am so happy to have never had a Netflix account