
How Netflix Built a Real-Time Distributed Graph for Internet Scale

2026 AI predictions for builders (Sponsored)

The AI landscape is changing fast—and the way you build AI systems in 2026 will look very different.
Join us live on January 28 as we unpack the first take from Redis’ 2026 predictions report: why AI apps won’t succeed without a unified context engine.
You’ll learn:
One architectural standard for AI across teams
Lower operational overhead via shared context infrastructure
Predictable, production-grade performance
Clear observability and governance for agent data access
Faster time to market for new AI features
Read the full 2026 predictions report →
Netflix is no longer just a streaming service. The company has expanded into live events, mobile gaming, and ad-supported subscription plans. This evolution created an unexpected technical challenge.
To understand the challenge, consider a typical member journey. Assume that a user watches Stranger Things on their smartphone, continues on their smart TV, and then launches the Stranger Things mobile game on a tablet. These activities happen at different times on different devices and involve different platform services. Yet they all belong to the same member experience.
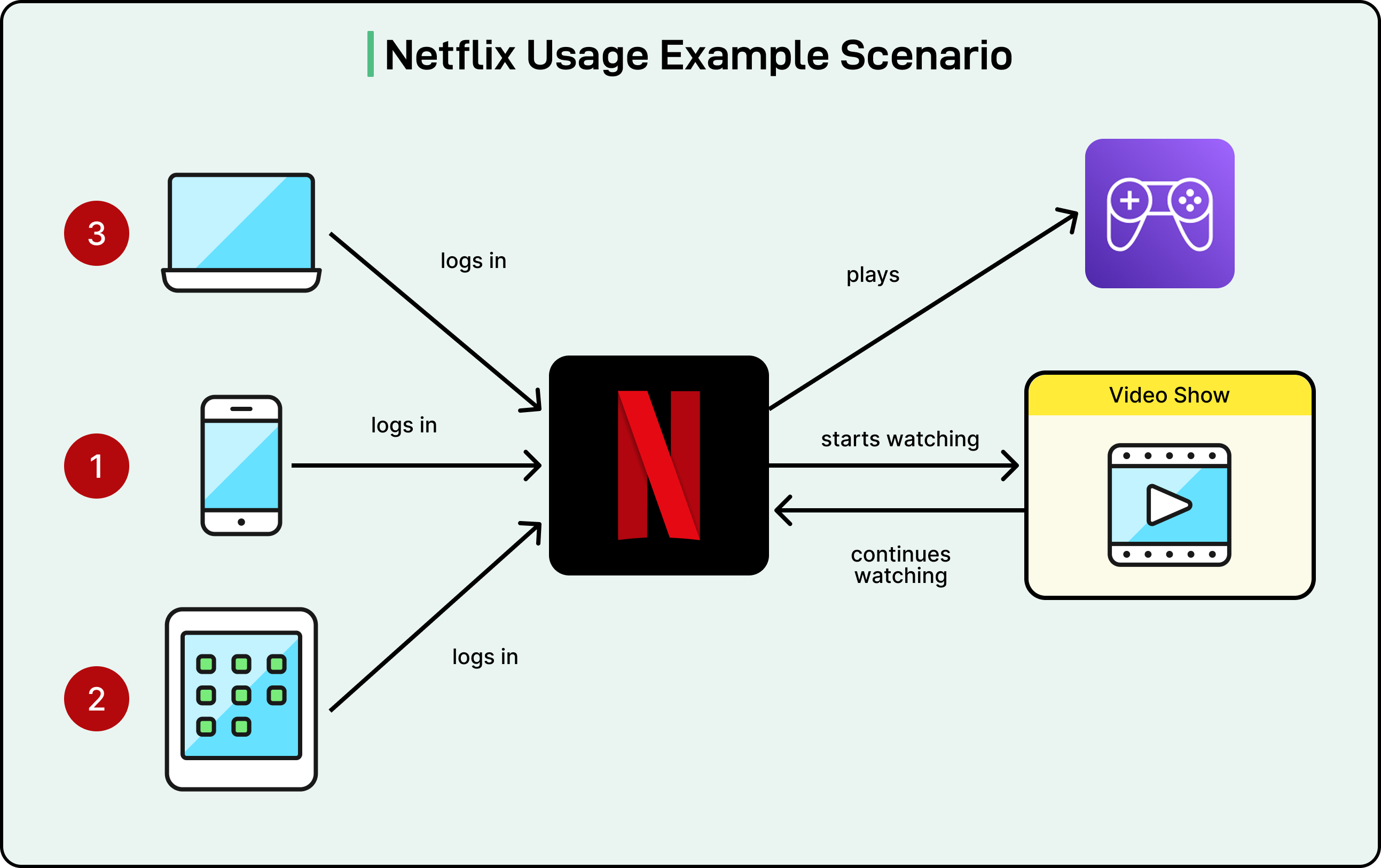
Disclaimer: This post is based on publicly shared details from the Netflix Engineering Team. Please comment if you notice any inaccuracies.
Understanding these cross-domain journeys became critical for creating personalized experiences. However, Netflix’s architecture made this difficult.
Netflix uses a microservices architecture with hundreds of services developed by separate teams. Each service can be developed, deployed, and scaled independently, and teams can choose the best data storage technology for their needs. However, when each service manages its own data, information can become siloed. Video streaming data lives in one database, gaming data in another, and authentication data separately. Traditional data warehouses collect this information, but the data lands in different tables and processes at different times.
Manually stitching together information from dozens of siloed databases became overwhelming. Therefore, the Netflix engineering team needed a different approach to process and store interconnected data while enabling fast queries. They chose a graph representation for the same due to the following reasons:
First, graphs enable fast relationship traversals without expensive database joins.
Second, graphs adapt easily when new connections emerge without significant schema changes.
Third, graphs naturally support pattern detection. Identifying hidden relationships and cycles is more efficient using graph traversals than siloed lookups.
This led Netflix to build the Real-Time Distributed Graph, or RDG. In this article, we will look at the architecture of RDG and the challenges Netflix faced while developing it.
Building the Data Pipeline
The RDG consists of three layers: ingestion and processing, storage, and serving. See the diagram below:
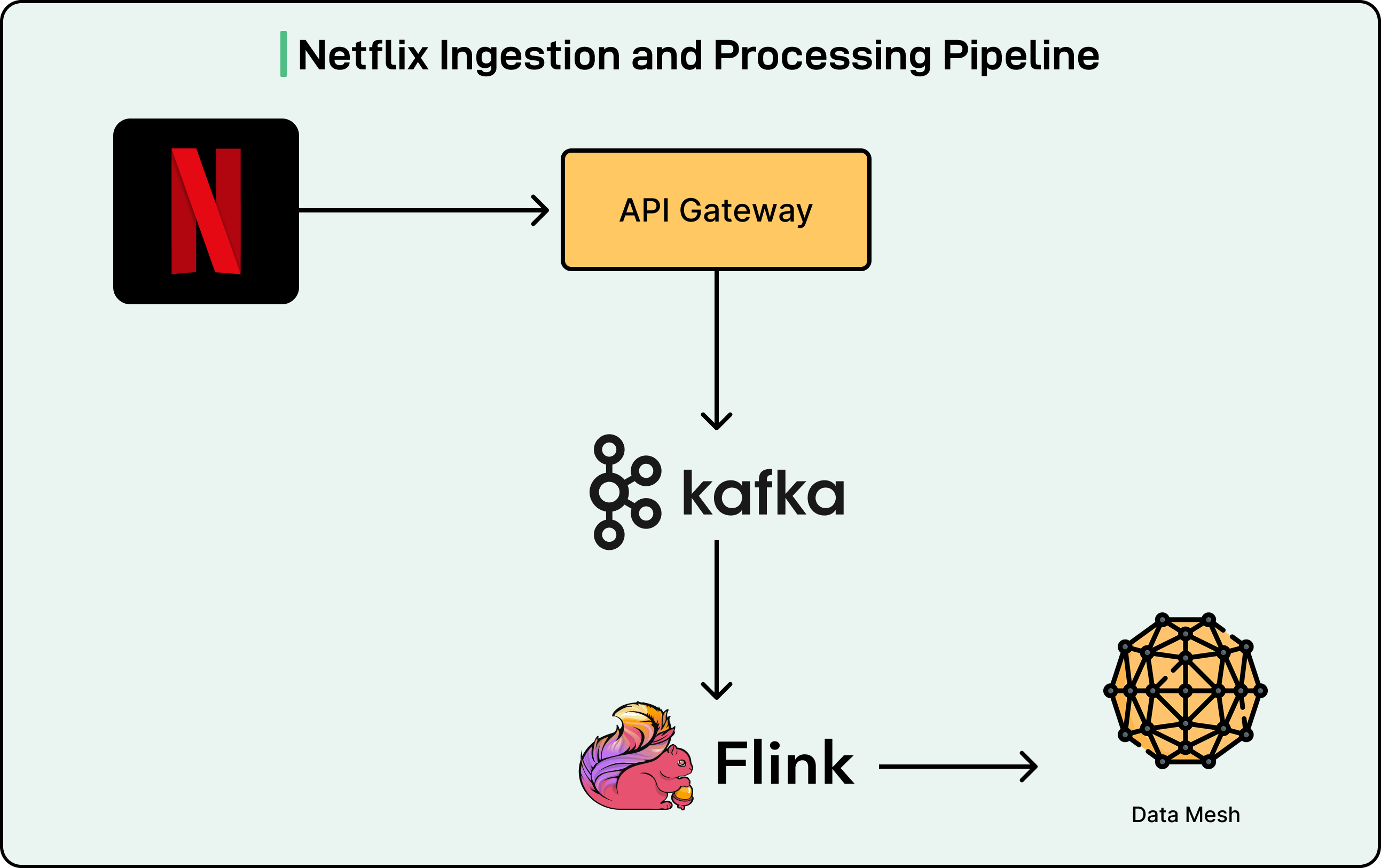
When a member performs any action in the Netflix app, such as logging in or starting to watch a show, the API Gateway writes these events as records to Apache Kafka topics.
Apache Kafka serves as the ingestion backbone, providing durable, replayable streams that downstream processors can consume in real time. Netflix chose Kafka because it offers exactly what they needed for building and updating the graph with minimal delay. Traditional batch processing systems and data warehouses could not provide the low latency required to maintain an up-to-date graph supporting real-time applications.
The scale of data flowing through these Kafka topics is significant. For reference, Netflix’s applications consume several different Kafka topics, each generating up to one million messages per second. Records use Apache Avro format for encoding, with schemas persisted in a centralized registry. To balance data availability against storage infrastructure costs, Netflix tailors retention policies for each topic based on throughput and record size. They also persist topic records to Apache Iceberg data warehouse tables, enabling backfills when older data expires from Kafka topics.
Apache Flink jobs ingest event records from the Kafka streams. Netflix chose Flink because of its strong capabilities around near-real-time event processing. There is also robust internal platform support for Flink within Netflix, which allows jobs to integrate with Kafka and various storage backends seamlessly.
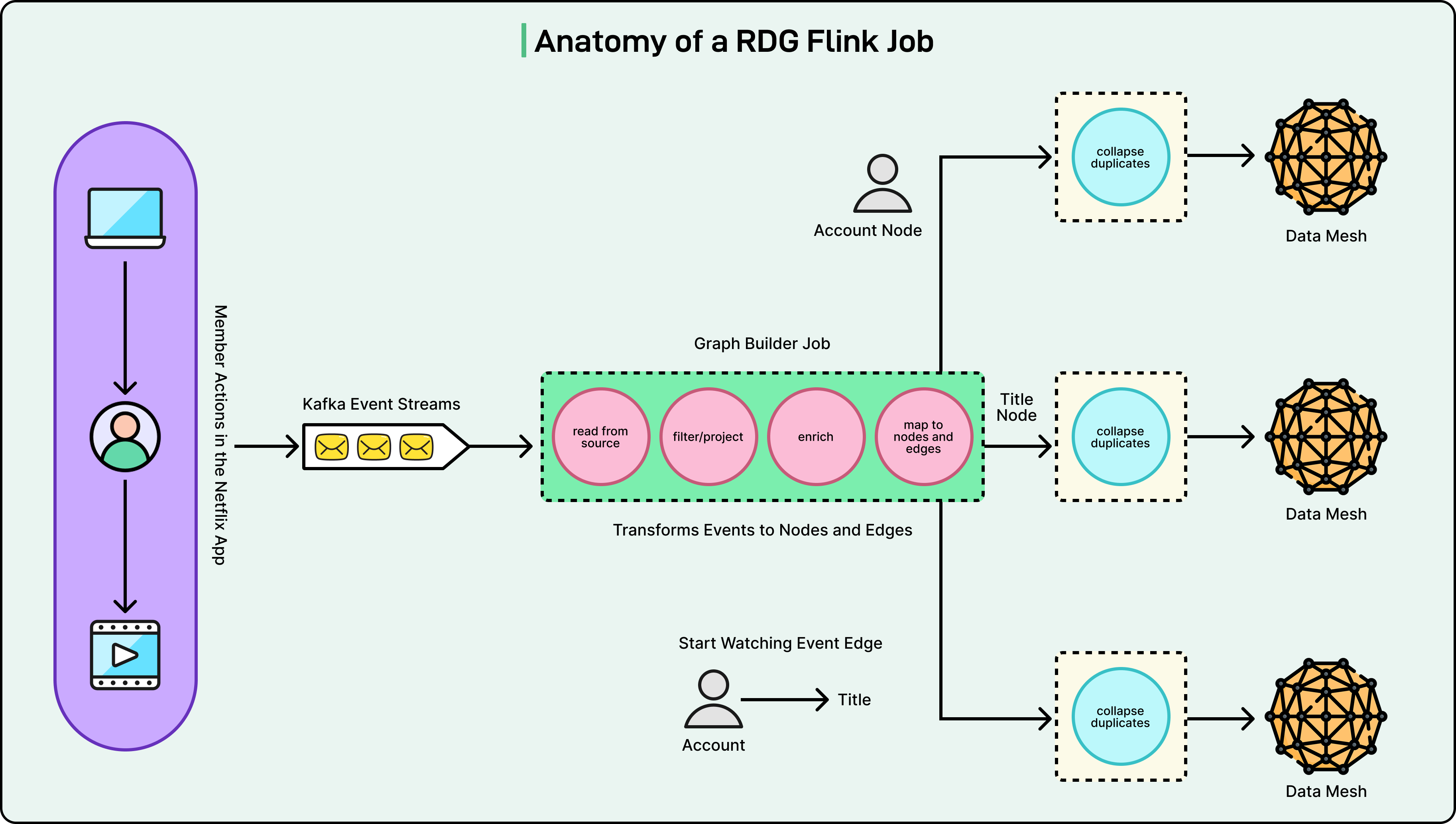
A typical Flink job in the RDG pipeline follows a series of processing steps:
First, the job consumes event records from upstream Kafka topics.
Next, it applies filtering and projections to remove noise based on which fields are present or absent in the events.
Then it enriches events with additional metadata stored and accessed via side inputs.
The job then transforms events into graph primitives, creating nodes that represent entities like member accounts and show titles, plus edges that represent relationships or interactions between them.
After transformation, the job buffers, detects, and deduplicates overlapping updates to the same nodes and edges within a small configurable time window. This step reduces the data throughput published downstream and is implemented using stateful process functions and timers. Finally, the job publishes node and edge records to Data Mesh, an abstraction layer connecting data applications and storage systems.
See the diagram below:
For reference, Netflix writes more than five million total records per second to Data Mesh, which handles persisting the records to data stores that other internal services can query.
Learning Through Failure
Netflix initially tried one Flink job consuming all Kafka topics. Different topics have vastly different volumes and throughput patterns, making tuning impossible. They pivoted to one-to-one mapping from topic to job. While this added operational overhead, each job became simpler to maintain and tune.
Similarly, each node and edge type gets its own Kafka topic. Though this means more topics to manage, Netflix valued the ability to tune and scale each independently. They designed the graph data model to be flexible, making new node and edge types infrequent additions.
The Storage Challenge
After creating billions of nodes and edges from member interactions, Netflix faced the critical question of how to actually store them.
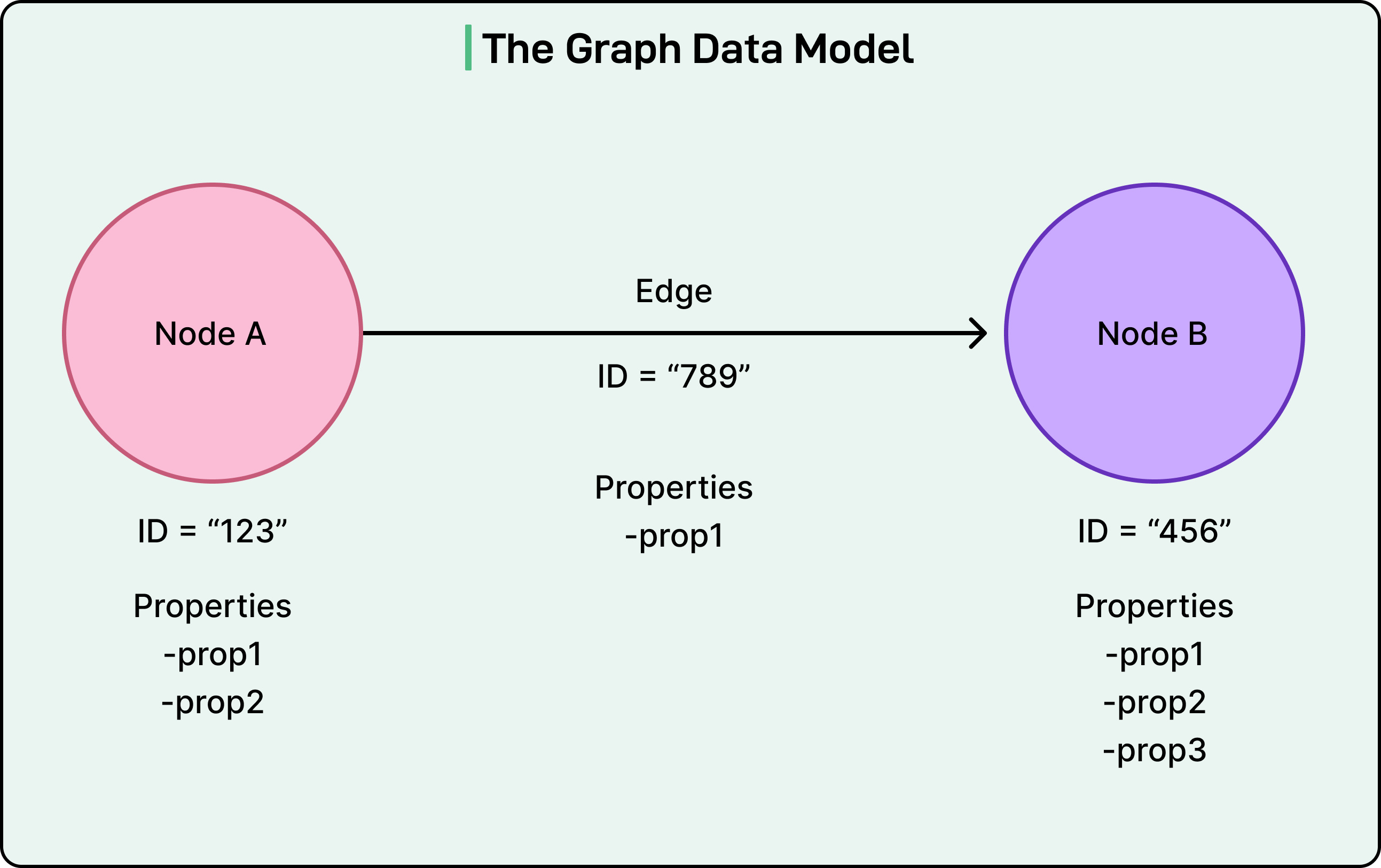
The RDG uses a property graph model. Nodes represent entities like member accounts, titles, devices, and games. Each node has a unique identifier and properties containing additional metadata. Edges represent relationships between nodes, such as started watching, logged in from, or plays. Edges also have unique identifiers and properties like timestamps.
See the diagram below:
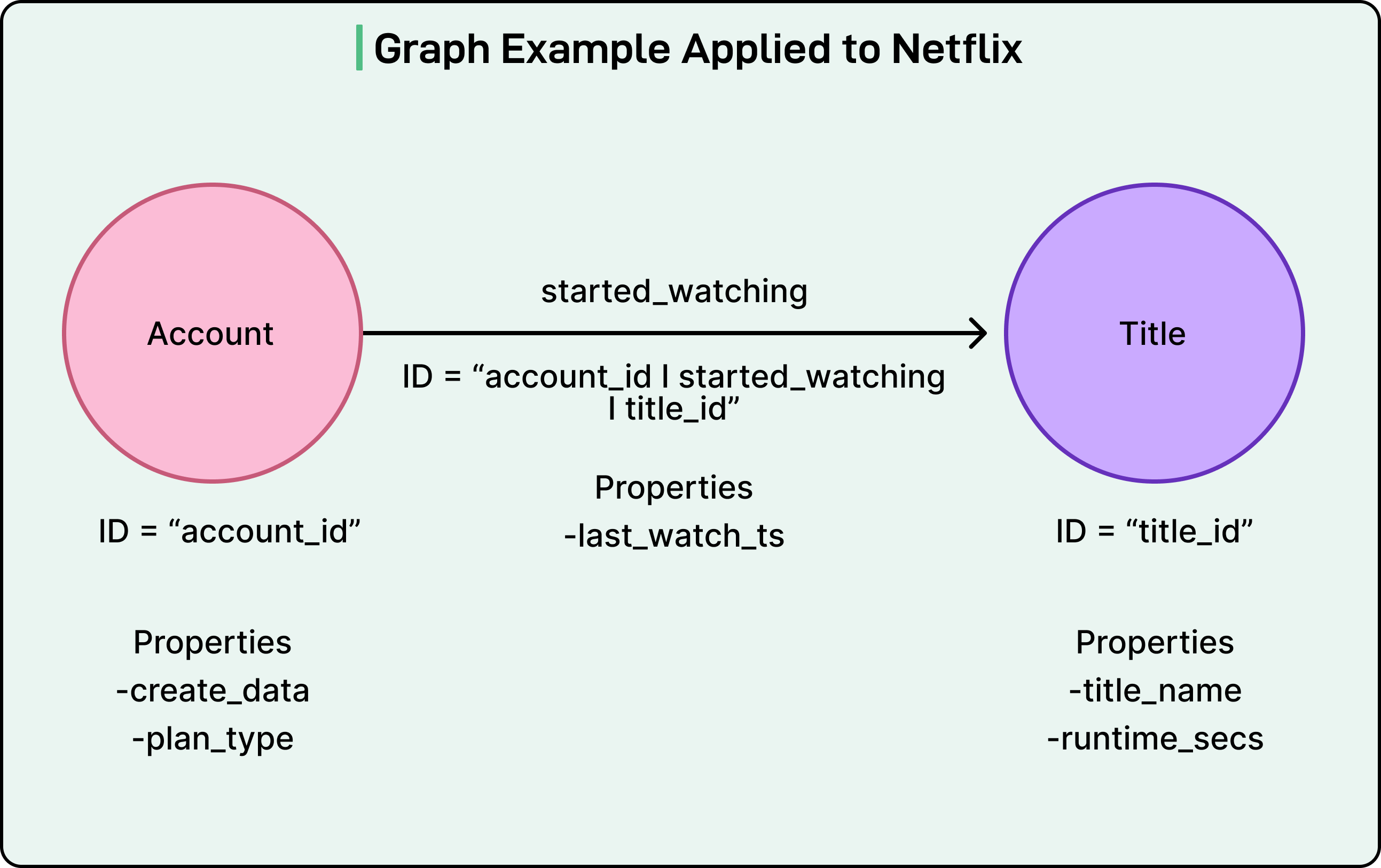
When a member watches a particular show, the system might create an account node with properties like creation date and plan type, a title node with properties like title name and runtime, and a started watching edge connecting them with properties like the last watch timestamp.
This simple abstraction allows Netflix to represent incredibly complex member journeys across its ecosystem.
Why Traditional Graph Databases Failed
The Netflix engineering team evaluated traditional graph databases like Neo4j and AWS Neptune. While these systems provide feature-rich capabilities around native graph query support, they posed a mix of scalability, workload, and ecosystem challenges that made them unsuitable for Netflix’s needs.
Native graph databases struggle to scale horizontally for large, real-time datasets. Their performance typically degrades with increased node and edge count or query depth.
In early evaluations, Neo4j performed well for millions of records but became inefficient for hundreds of millions due to high memory requirements and limited distributed capabilities.
AWS Neptune has similar limitations due to its single-writer, multiple-reader architecture, which presents bottlenecks when ingesting large data volumes in real time, especially across multiple regions.
These systems are also not inherently designed for the continuous, high-throughput event streaming workloads critical to Netflix operations. They frequently struggle with query patterns involving full dataset scans, property-based filtering, and indexing.
Most importantly for Netflix, the company has extensive internal platform support for relational and document databases compared to graph databases. Non-graph databases are also easier for them to operate. Netflix found it simpler to emulate graph-like relationships in existing data storage systems rather than adopting specialized graph infrastructure.
The KVDAL Solution
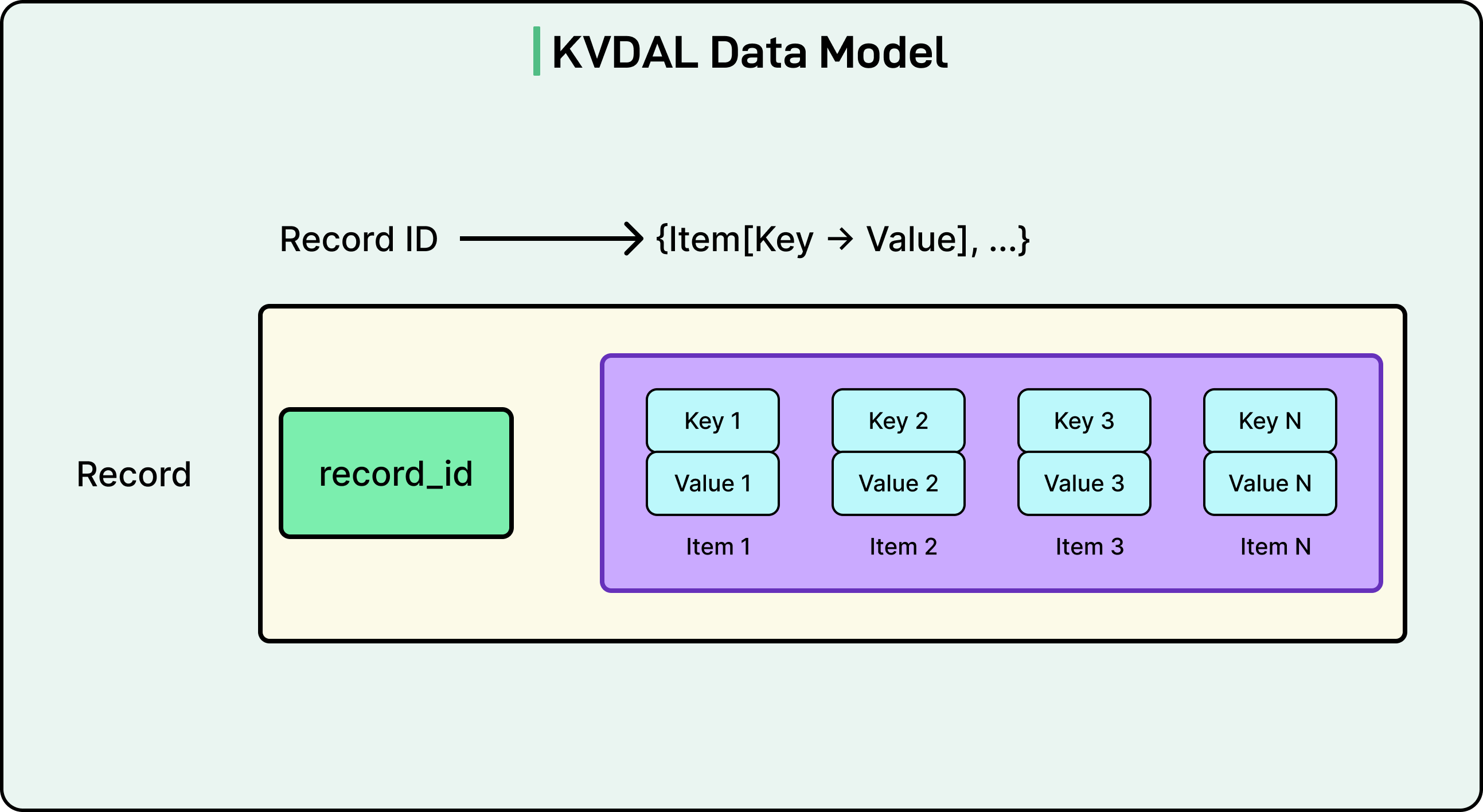
The Netflix engineering team turned to KVDAL, the Key-Value Data Abstraction Layer from their internal Data Gateway Platform. Built on Apache Cassandra, KVDAL provides high availability, tunable consistency, and low latency without direct management of underlying storage.
See the diagram below:
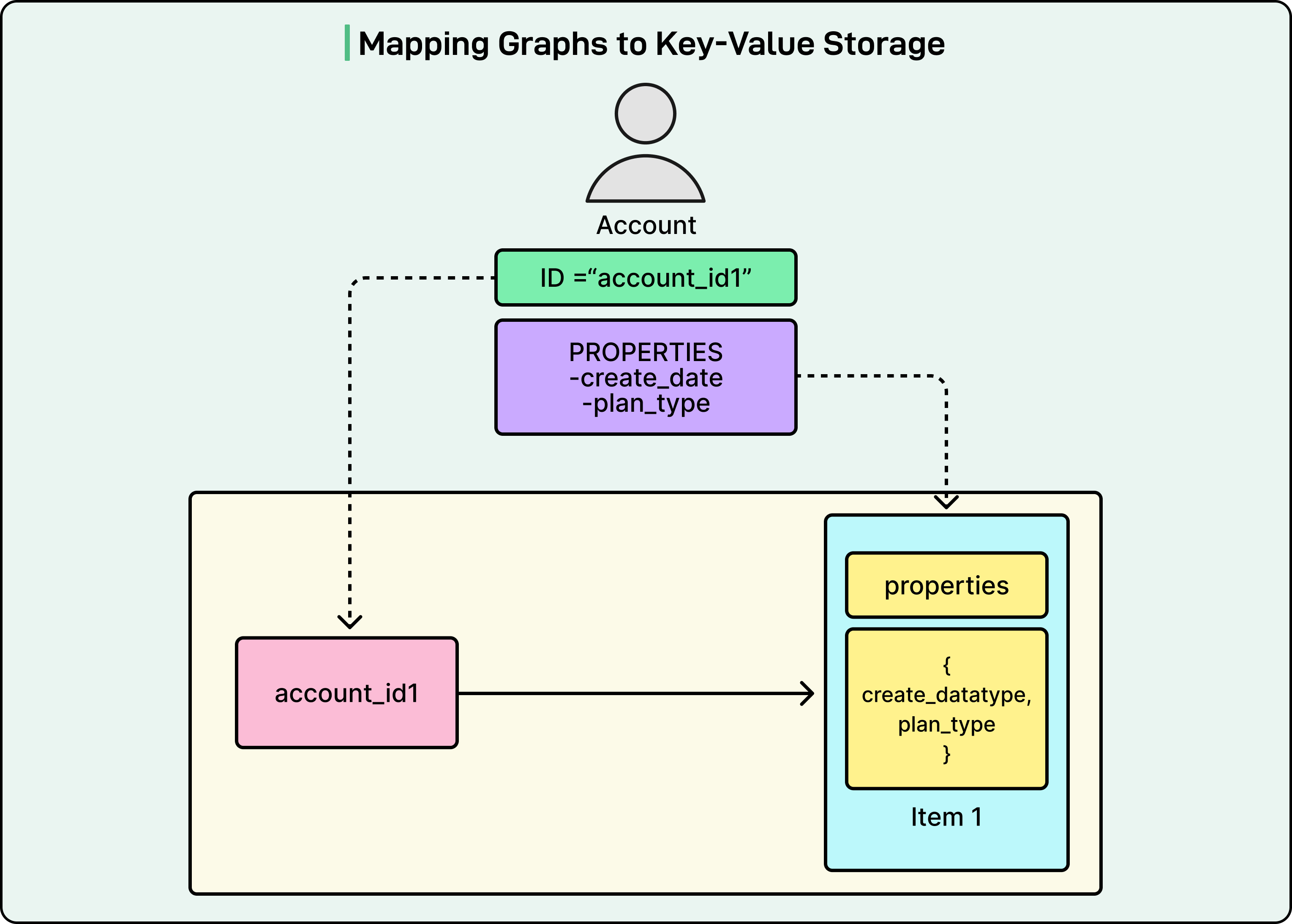
KVDAL uses a two-level map architecture. Data is organized into records uniquely identified by a record ID. Each record contains sorted items, where an item is a key-value pair. To query KVDAL, you look up a record by ID, then optionally filter items by their keys. This gives both efficient point lookups and flexible retrieval of related data.
For nodes, the unique identifier becomes the record ID, with all properties stored as a single item. For edges, Netflix uses adjacency lists. The record ID represents the origin node, while items represent all destination nodes it connects to. If an account has watched multiple titles, the adjacency list contains one item per title with properties like timestamps.
This format is vital for graph traversals. To find all titles a member watched, Netflix retrieves the entire record with one KVDAL lookup. They can also filter by specific titles using key filtering without fetching unnecessary data.
Managing Data Lifecycle
As Netflix ingests real-time streams, KVDAL creates new records for new nodes or edges. When an edge exists with an existing origin but a new destination, it creates a new item in the existing record. When ingesting the same node or edge multiple times, KVDAL overwrites existing values, keeping properties like timestamps current. KVDAL can also automatically expire data on a per-namespace, per-record, or per-item basis, providing fine-grained control while limiting graph growth.
Namespaces Enable Massive Scale
Namespaces are the most powerful KVDAL feature Netflix leveraged. A namespace is like a database table, a logical grouping of records that defines physical storage while abstracting underlying system details.
You can start with all namespaces backed by one Cassandra cluster. If one namespace needs more storage or traffic capacity, you can move it to its own cluster for independent management. Different namespaces can use entirely different storage technologies. Low-latency data might use Cassandra with EVCache caching. High-throughput data might use dedicated clusters per namespace.
KVDAL can scale to trillions of records per namespace with single-digit millisecond latencies. Netflix provisions a separate namespace for every node type and edge type. While seemingly excessive, this enables independent scaling and tuning, flexible storage backends per namespace, and operational isolation where issues in one namespace do not impact others.
Conclusion
The numbers demonstrate real-world performance. Netflix’s graph has over eight billion nodes and more than 150 billion edges. The system sustains approximately two million reads per second and six million writes per second. This runs on a KVDAL cluster with roughly 27 namespaces, backed by around 12 Cassandra clusters across 2,400 EC2 instances.
These numbers are not limits. Every component scales linearly. As the graph grows, Netflix can add more namespaces, clusters, and instances.
Netflix’s RDG architecture offers important lessons.
Sometimes the right solution is not the obvious one. Netflix could have used purpose-built graph databases, but chose to emulate graph capabilities using key-value storage based on operational realities like internal expertise and existing platform support.
Scaling strategies evolve through experimentation. Netflix’s monolithic Flink job failed. Only through experience did they discover that one-to-one topic-to-job mapping worked better despite added complexity.
Isolation and independence matter at scale. Separating each node and edge type into its own namespace enabled independent tuning and reduced issue blast radius.
Building on proven infrastructure pays dividends. Rather than adopting new systems, Netflix leveraged battle-tested technologies like Kafka, Flink, and Cassandra, building abstractions to meet their needs while benefiting from maturity and operational expertise.
The RDG enables Netflix to analyze member interactions across its expanding ecosystem. As the business evolves with new offerings, this flexible architecture can adapt without requiring significant re-architecture.
References:
How and Why Netflix Built a Real-Time Distributed Graph - Part 1
How and Why Netflix Built a Real-Time Distributed Graph - Part 2
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.