
How Netflix Stores 140 Million Hours of Viewing Data Per Day

🚀Faster mobile releases with automated QA (Sponsored)

Manual testing on mobile devices is too low and too limited. It forces teams to cut releases a week early just to test before submitting them to app stores. And without broad device coverage, issues slip through.
QA Wolf’s AI-native service delivers 80% automated test coverage in weeks, with test running on real iOS devices and Android emulators—all in 100% parallel with zero flakes.
QA cycles reduced to just 15 minutes
Multi-device + gesture interactions fully supported
Reliable test execution with zero flakes
Human-verified bug reports
Engineering teams move faster, releases stay on track, and testing happens automatically—so developers can focus on building, not debugging.
Rated 4.8/5 ⭐ on G2
Disclaimer: The details in this post have been derived from the Netflix Tech Blog. All credit for the technical details goes to the Netflix engineering team. Some details related to Apache Cassandra® have been taken from Apache Cassandra® official documentation. Apache Cassandra® is a registered trademark of The Apache Software Foundation. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Every single day millions of people stream their favorite movies and TV shows on Netflix.
With each stream, a massive amount of data is generated: what a user watches, when they pause, rewind, or stop, and what they return to later. This information is essential for providing users with features like resume watching, personalized recommendations, and content suggestions.
However, Netflix's growth has led to an explosion of time series data (data recorded over time, like a user’s viewing history). The company relies heavily on this data to enhance the user experience, but handling such a vast and ever-increasing amount of information also presents a technical challenge in the following ways:
Every time a user watches a show or movie, new records are added to their viewing history. This history keeps growing, making it harder to store and retrieve efficiently.
As millions of people use Netflix, the number of viewing records increases not just for individual users but across the entire platform. This rapid expansion means Netflix must continuously scale its data storage systems.
When Netflix introduces new content and features, people spend more time watching. With the rise of binge-watching and higher-quality streaming (like 4K videos), the amount of viewing data per user is also increasing.
A failure to manage this data properly could lead to catastrophic user experience delays when loading watch history. It could also result in useless recommendations, or even lost progress in shows.
In this article, we’ll learn how Netflix tackled these problems and improved their storage system to handle millions of hours of viewing data every day.
The Initial Approach
When Netflix first started handling large amounts of viewing data, they chose Apache Cassandra® for the following reasons:
Apache Cassandra® allows for a flexible structure, where each row can store a growing number of viewing records without performance issues.
Netflix’s system processes significantly more writes (data being stored) than reads (data being retrieved). The ratio is approximately 9:1, meaning for every 9 new records added, only 1 is read. Apache Cassandra® excels in handling such workloads.
Instead of enforcing strict consistency, Netflix prioritizes availability and speed, ensuring users always have access to their watch history, even if data updates take a little longer to sync. Apache Cassandra® supports this tradeoff with eventual consistency, meaning that all copies of data will eventually match up across the system.
See the diagram below, which shows the data model of Apache Cassandra® using column families.

To structure the data efficiently, Netflix designed a simple yet scalable storage model in Cassandra®.
Each user’s viewing history was stored under their unique ID (CustomerId). Every viewing record (such as a movie or TV show watched) was stored in a separate column under that user’s ID. To handle millions of users, Netflix used "horizontal partitioning," meaning data was spread across multiple servers based on CustomerId. This ensured that no single server was overloaded.
Reads and Writes in the Initial System
The diagram below shows how the initial system handled reads and writes to the viewing history data.
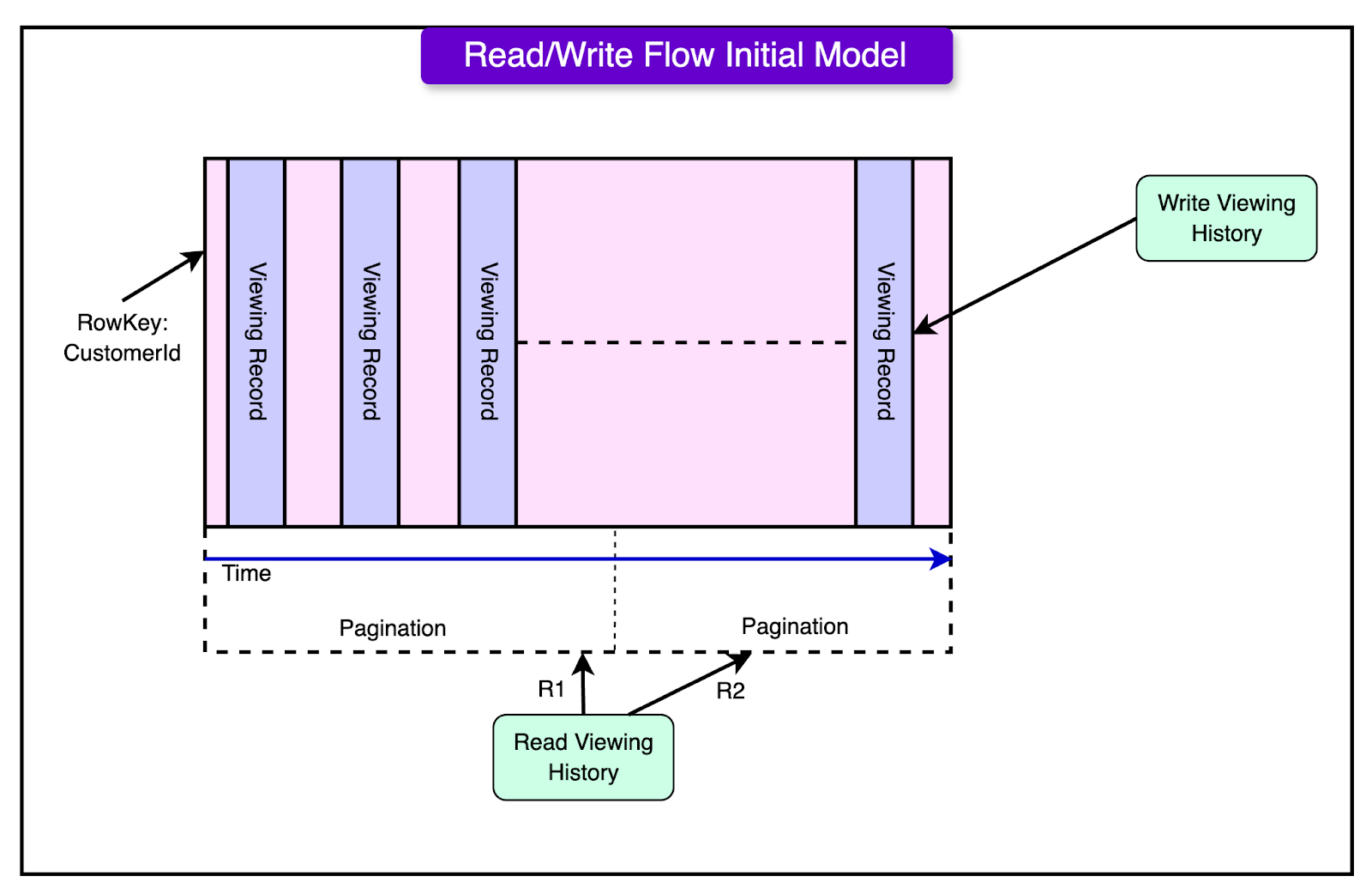
Every time a user started watching a show or movie, Netflix added a new column to their viewing history record in the database. If the user paused or stopped watching, that same column was updated to reflect their latest progress.
While storing data was easy, retrieving it efficiently became more challenging as users' viewing histories grew. Netflix used three different methods to fetch data, each with its advantages and drawbacks:
Retrieving the Entire Viewing History: If a user had only watched a few shows, Netflix could quickly fetch their entire history in one request. However, for long-time users with large viewing histories, this approach became slow and inefficient as more data accumulated.
Searching by Time Range: Sometimes, Netflix only needed to fetch records from a specific time period, like a user’s viewing history from the last month. While this method worked well in some cases, performance varied depending on how many records were stored within the selected time range.
Using Pagination for Large Histories: To avoid loading huge amounts of data at once, Netflix used pagination. This approach prevented timeouts (when a request takes too long and fails), but it also increased the overall time needed to retrieve all records.
At first, this system worked well because it provided a fast and scalable way to store viewing history. However, as more users watched more content, this system started to hit performance limits. Some of the issues were as follows:
Too Many SSTables: Apache Cassandra® stores data in files called SSTables (Sorted String Tables). Over time, the number of these SSTables increased significantly. For every read, the system had to scan multiple SSTables across the disk, making the process slower.
Compaction Overhead: Apache Cassandra® performs compactions to merge multiple SSTables into fewer, more efficient ones. With more data, these compactions took longer and required more processing power. Other operations like read repair and full column repair also became expensive.
To speed up data retrieval, Netflix introduced a caching solution called EVCache.
Instead of reading everything from the Apache Cassandra® database every time, each user’s viewing history is stored in a cache in a compressed format. When a user watches a new show, their viewing data is added to Apache Cassandra® and merged with the cached value in EVCache. If a user’s viewing history is not found in the cache, Netflix fetches it from Cassandra®, compresses it, and then stores it in EVCache for future use.
By adding EVCache, Netflix significantly reduced the load on their Apache Cassandra® database. However, this solution also had its limits.
The New Approach: Live & Compressed Storage Model
One important fact about the viewing history data was this: most users frequently accessed only their recent viewing history, while older data was rarely needed. However, storing everything the same way led to unnecessary performance and storage costs.
To solve this, Netflix redesigned its storage model by splitting viewing history into two categories:
Live Viewing History (LiveVH): It stores recently watched content that users access frequently. It is also uncompressed for fast reads and writes. This is designed for quick updates, like when a user pauses or resumes a show.
Compressed Viewing History (CompressedVH): Stores older viewing records that are accessed less frequently. It is compressed to save storage space and improve performance.

Since LiveVH and CompressedVH serve different purposes, they were tuned differently to maximize performance.
For LiveVH, which stores recent viewing records, Netflix prioritized speed and real-time updates. Frequent compactions were performed to clean up old data and keep the system running efficiently. Additionally, a low GC (Garbage Collection) grace period was set, meaning outdated records were removed quickly to free up space. Since this data was accessed often, frequent read repairs were implemented to maintain consistency, ensuring that users always saw accurate and up-to-date viewing progress.
On the other hand, CompressedVH, which stores older viewing records, was optimized for storage efficiency rather than speed. Since this data was rarely updated, fewer compactions were needed, reducing unnecessary processing overhead. Read repairs were also performed less frequently, as data consistency was less critical for archival records. The most significant optimization was compressing the stored data, which drastically reduced the storage footprint while still making older viewing history accessible when needed.
The Large View History Performance Issue
Even with compression, some users had extremely large viewing histories. For these users, reading and writing a single massive compressed file became inefficient.
If CompressedVH grows too large, retrieving data becomes slow. Also, single large files create performance bottlenecks when read or written. To avoid these issues, Netflix introduced chunking, where large compressed data is split into smaller parts and stored across multiple Apache Cassandra® database nodes.
Here’s how it works:
Instead of storing everything in one large file, Netflix stores metadata that tracks data version and chunk count.
Instead of writing one large file, each chunk is written separately. A metadata entry keeps track of all the chunks, ensuring efficient storage.
Metadata is read first, so Netflix knows how many chunks to retrieve. Chunks are fetched in parallel, significantly improving read speeds.
This system gave Netflix the headroom needed to handle future growth.
The New Challenges
With the global expansion of Netflix, the company launched its service in 130+ new countries and introduced support for 20 languages. This led to a massive surge in data storage and retrieval needs.
At the same time, Netflix introduced video previews in the user interface (UI), a feature that allowed users to watch short clips before selecting a title. While this improved the browsing experience, it also dramatically increased the volume of time-series data being stored.
When Netflix analyzed the performance of its system, it found several inefficiencies:
The storage system did not differentiate between different types of viewing data. Video previews and full-length plays were stored identically, despite having very different usage patterns.
Language preferences were stored repeatedly across multiple viewing records, leading to unnecessary duplication and wasted storage.
Since video previews generated many short playback records, they accounted for 30% of the data growth every quarter.
Netflix’s clients (such as apps and web interfaces) retrieved more data than they needed. Most queries only required recent viewing data, but the system fetched entire viewing histories regardless. Because filtering happened after data was fetched, huge amounts of unnecessary data were transferred across the network, leading to high bandwidth costs and slow performance.
Read latencies at the 99th percentile (worst-case scenarios) became highly unpredictable. Some queries were fast, but others took too long to complete, causing an inconsistent user experience.
At this stage, Netflix’s existing architecture could no longer scale efficiently.
Apache Cassandra® had been a solid choice for scalability, but by this stage, Netflix was already operating one of the largest Apache Cassandra® clusters in existence. The company had already pushed Apache Cassandra® to its limits, and without a new approach, performance issues would continue to worsen as the platform grew.
A more fundamental redesign was needed.
Netflix’s New Storage Architecture
To overcome the growing challenges of data overload, inefficient retrieval, and high latency, Netflix introduced a new storage architecture that categorized and stored data more intelligently.
Step 1: Categorizing Data by Type
One of the biggest inefficiencies in the previous system was that all viewing data (whether it was a full movie playback, a short video preview, or a language preference setting) was stored together.
Netflix solved this by splitting viewing history into three separate categories, each with its dedicated storage cluster:
Full Title Plays: Data related to complete or partial streaming of movies and TV shows. This is the most critical data because it affects resume points, recommendations, and user engagement metrics.
Video Previews: Short clips that users watch while browsing content. Since this data grows quickly but isn’t as important as full plays, it required a different storage strategy.
Language Preferences: Information on which subtitles or audio tracks a user selects. This was previously stored redundantly across multiple viewing records, wasting storage. Now, it is stored separately and referenced when needed.
Step 2: Sharding Data for Better Performance
Netflix sharded (split) its data across multiple clusters based on data type and data age, improving both storage efficiency and query performance.
See the diagram below for reference:

1 - Sharding by Data Type
Each of the three data categories (Full Plays, Previews, and Language Preferences) was assigned its separate cluster.
This allowed Netflix to tune each cluster differently based on how frequently the data was accessed and how long it needed to be stored. It also prevented one type of data from overloading the entire system.
2 - Sharding by Data Age
Not all data is accessed equally. Users frequently check their recent viewing history, but older data is rarely needed. To optimize for this, Netflix divided its data storage into three time-based clusters:
Recent Cluster (Short-Term Data): Stores viewing data from the past few days or weeks. Optimized for fast reads and writes since recent data is accessed most frequently.
Past Cluster (Archived Data): Holds viewing records from the past few months to a few years. Contains detailed records, but is tuned for slower access since older data is less frequently requested.
Historical Cluster (Summarized Data for Long-Term Storage): Stores compressed summaries of viewing history from many years ago. Instead of keeping every detail, this cluster only retains key information, reducing storage size.
Optimizations in the New Architecture
To keep the system efficient, scalable, and cost-effective, the Netflix engineering team introduced several key optimizations.
1 - Improving Storage Efficiency
With the introduction of video previews and multi-language support, Netflix had to find ways to reduce the amount of unnecessary data stored. The following strategies were adopted:
Many previews were only watched for a few seconds, which wasn’t a strong enough signal of user interest. Instead of storing every short preview play, Netflix filtered out these records before they were written to the database, significantly reducing storage overhead.
Previously, language preference data (subtitles/audio track choices) was duplicated across multiple viewing records. This was inefficient, so Netflix changed its approach. Now, each user's language preference is stored only once, and only changes (deltas) are recorded when the user selects a different language.
To keep the database from being overloaded, Netflix implemented Time-To-Live (TTL)-based expiration, meaning that unneeded records were deleted automatically after a set period.
Netflix continued using two separate storage methods to store recent data in an uncompressed format and older data in compressed format.
2 - Making Data Retrieval More Efficient
Instead of fetching all data at once, the system was redesigned to retrieve only what was needed:
Recent data requests were directed to the Recent Cluster to support low-latency access for users checking their recently watched titles.
Historical data retrieval was improved with parallel reads. Instead of pulling old records from a single location, Netflix queried multiple clusters in parallel, making data access much faster.
Records from different clusters were intelligently stitched together. Even when a user requested their entire viewing history, the system combined data from various sources quickly and efficiently.
3 - Automating Data Movement with Data Rotation
To keep the system optimized, Netflix introduced a background process that automatically moved older data to the appropriate storage location:
Recent to Past Cluster: If a viewing record was older than a certain threshold, it was moved from the Recent Cluster to the Past Cluster. This ensured that frequently accessed data stayed in a fast-access storage area, while older data was archived more efficiently.
Past to Historical Cluster: When data became older, it was summarized and compressed, then moved to the Historical Cluster for long-term storage with minimal resource usage.
Parallel writes & chunking were used to ensure that moving large amounts of data didn’t slow down the system.
See the diagram below:

4 - Caching for Faster Data Access
Netflix restructured its EVCache (in-memory caching layer) to mirror the backend storage architecture.

A new summary cache cluster was introduced, storing precomputed summaries of viewing data for most users. This meant that instead of computing summaries every time a user made a request, Netflix could fetch them instantly from the cache. They managed to achieve a 99% cache hit rate, meaning that nearly all requests were served from memory rather than querying Apache Cassandra®, reducing overall database load.
Conclusion
With the growth that Netflix went through, their engineering team had to evolve the time-series data storage system to meet the increasing demands.
Initially, Netflix relied on a simple Apache Cassandra®-based architecture, which worked well for early growth but struggled as data volume soared. The introduction of video previews, global expansion, and multilingual support pushed the system to its breaking point, leading to high latency, storage inefficiencies, and unnecessary data retrieval.
To address these challenges, Netflix redesigned its architecture by categorizing data into Full Title Plays, Video Previews, and Language Preferences and sharding data by type and age. This allowed for faster access to recent data and efficient storage for older records.
These innovations allowed Netflix to scale efficiently, reducing storage costs, improving data retrieval speeds, and ensuring a great streaming experience for millions of users worldwide.
Note: Apache Cassandra® is a registered trademark of the Apache Software Foundation.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Netflix stores 140 million hours of data per day just to make sure you can resume that episode you fell asleep to.
It is really great example of how system design should be.