
How OpenAI, Gemini, and Claude Use Agents to Power Deep Research

Power your company’s IT with AI (Sponsored)

What if you could spend most of your IT resources on innovation, not maintenance?
The latest report from the IBM Institute for Business Value explores how businesses are using intelligent automation to get more out of their technology, drive growth & cost the cost of complexity.
Disclaimer: The details in this post have been derived from the details shared online by OpenAI, Gemini, xAI, Perplexity, Microsoft, Qwen, and Anthropic Engineering Teams. All credit for the technical details goes to OpenAI, Gemini, xAI, Perplexity, Microsoft, Qwen, and Anthropic Engineering Teams. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Deep Research has become a standard capability across modern LLM platforms.
ChatGPT, Gemini, and Claude all support tasks that run for long periods of time and gather information from large portions of the public web.
A typical deep research request may involve dozens of searches, several rounds of filtering, and the careful assembly of a final, well-structured report. For example, a query like “list 100 companies working on AI agents in 2025” does not rely on a single search result. It activates a coordinated system that explores a wide landscape of information over 15 to 30 minutes before presenting a final answer.
This article explains how these systems work behind the scenes.
We will walk through the architecture that enables Deep Research, how different LLMs implement it, how agents coordinate with one another, and how the final report is synthesized and validated before being delivered to the user.
High-Level Architecture
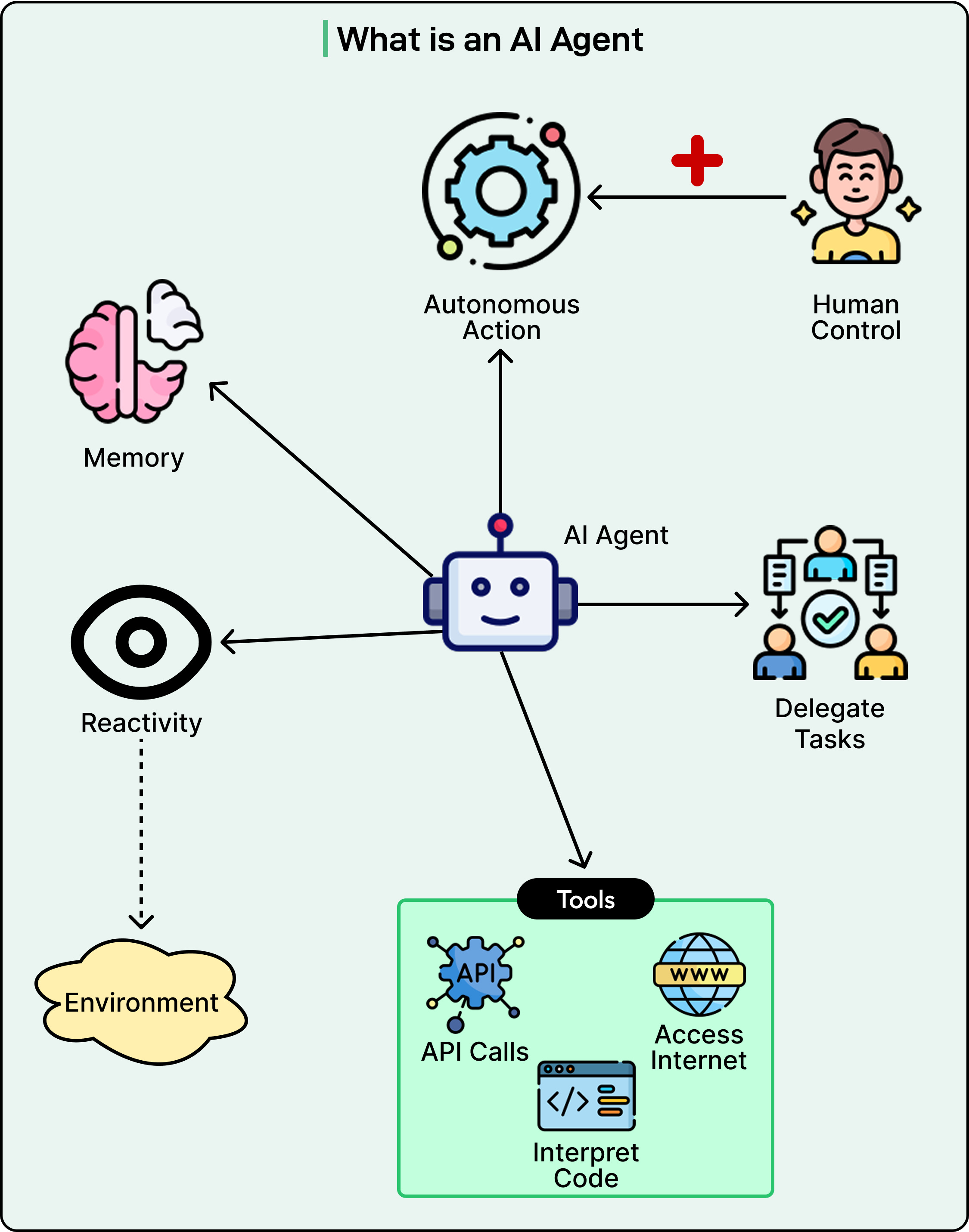
Deep Research systems are built from AI agents that cooperate with each other. In this context, an AI agent is a service driven by an LLM that can accept goals, design workflows to achieve those goals, and interact with its environment through tools such as web search or code execution.
See the diagram below to understand the concept of an AI Agent:
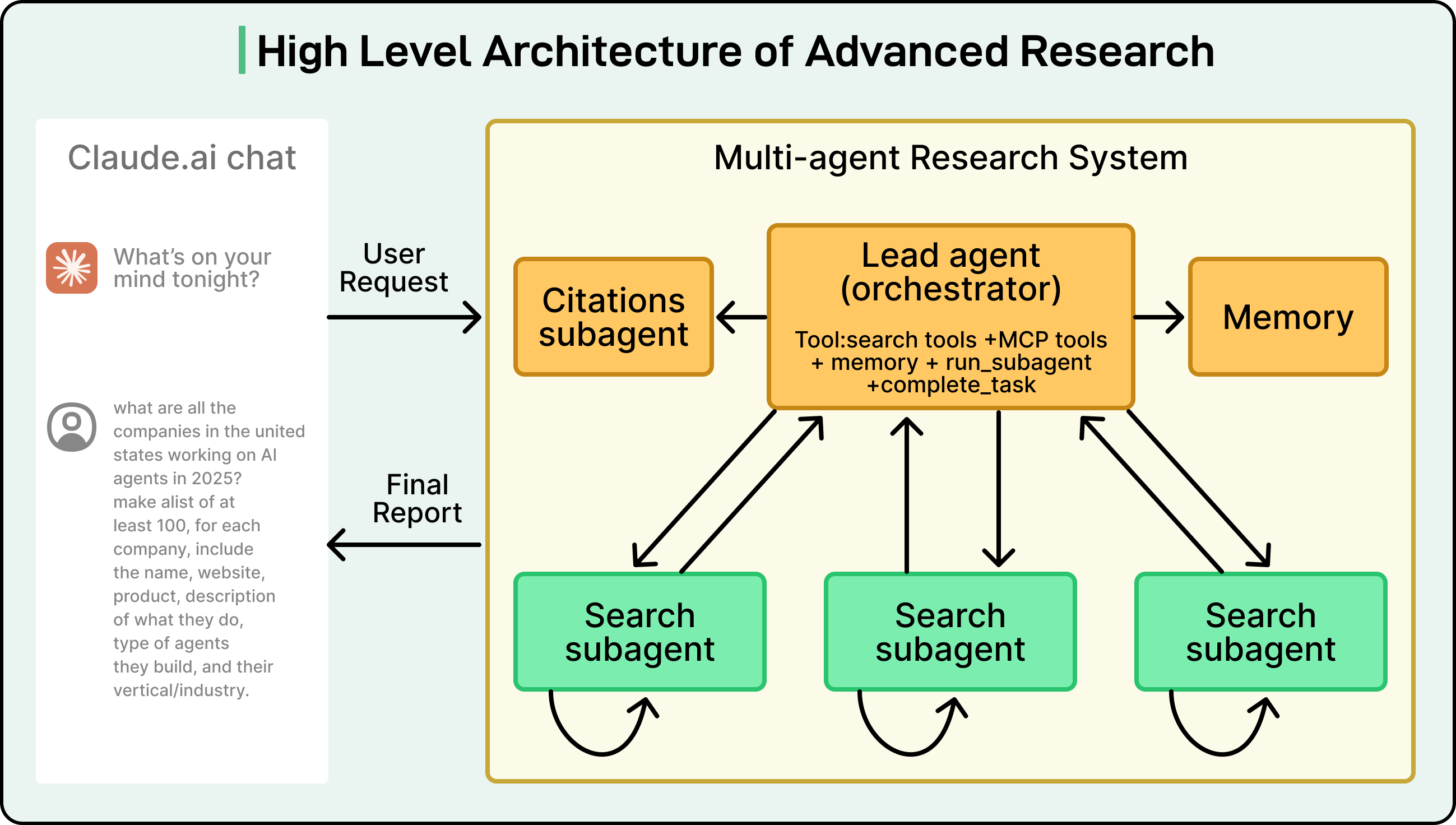
At a high level, the architecture begins with the user request. The user’s query is sent into a multi-agent research system. Inside this system, there is usually an orchestrator or lead agent that takes responsibility for the overall research strategy.
The orchestrator receives the query, interprets what the user wants, and then creates a plan for how to answer the question. That plan is broken into smaller pieces and delegated to multiple sub-agents. The most common sub-agents are “web search” agents. Each of these is instructed to search the web for a specific part of the overall topic or a particular sub-task, such as one region, one time period, or one dimension of the question.
Once the web agents finish their work, they return two things:
The content they have extracted. This typically takes the form of text snippets, summaries, or key facts.
Citations that record exactly where that content came from, such as URLs and page titles.
These results then move into what we can call the “synthesizer” flow. This stage often contains two agents: a synthesizer agent and a citations agent. In some systems, the orchestrator itself also acts as the synthesizer, so a separate agent is not required.
The synthesizer agent takes all the content returned by the web agents and converts it into the final research report. It organizes the information into sections, resolves overlaps, and builds a coherent narrative. The citations agent then reads through the synthesized report and makes sure that each statement is supported by the correct sources. It inserts citations in the right locations in the text, so that the final report is thoroughly backed by the underlying material.
After this synthesis and citation process is complete, the synthesizer (or orchestrator) returns the final, fully cited research report to the user.
Anthropic has published a high-level diagram of its “Advanced Research” mode, which illustrates such a multi-agent research system in action. It shows the lead agent, the various sub-agents, and the data flowing between them through planning, research, and synthesis.
The Current Landscape of Research Agents
Although the broad idea behind Deep Research is shared across platforms, each major provider implements its own variations.
OpenAI Deep Research
OpenAI’s deep research agent is built around a reasoning model that uses reinforcement learning.
The model is trained to plan multi-step research tasks, decide when to search, when to read, and how to combine information into a final answer. The use of reinforcement learning helps the agent improve over time by rewarding good sequences of tool calls and research decisions.
Gemini Deep Research
Google DeepMind’s Gemini Deep Research system is built on top of the Gemini model, which is multimodal. That means the same system can reason over text, images, and other types of inputs.
For deep research, this allows Gemini to integrate information from documents, web pages, and other media into a combined response. Gemini’s agent uses its planning ability to decide what to look for, how to structure the research, and how to bring everything together into one report.
Claude Advanced Research
Anthropic’s advanced research system uses a clearly defined multi-agent architecture. There is a lead agent that orchestrates several sub-agents running in parallel. Each sub-agent is asked to explore a specific part of the problem space.
For complex topics, this design allows Claude to divide the subject into multiple angles and explore them at the same time, then bring the results back to the orchestrator for synthesis.
Perplexity Deep Research
Perplexity’s deep research agent uses an iterative information retrieval loop.
Instead of a single pass of search and summary, it repeatedly adjusts its retrieval based on new insights discovered along the way.
Perplexity also uses a hybrid architecture that can autonomously select the best underlying models for different parts of the task. For example, one model might be better at summarization while another is better at search interpretation, and the system can route work accordingly.
Grok DeepSearch
Grok DeepSearch has a segment-level module processing pipeline.
Content is processed in segments, and each segment passes through a credibility assessment stage. Additionally, Grok uses a sparse attention mechanism that allows it to perform concurrent reasoning across multiple pieces of text.
The system can also dynamically allocate resources, switching between retrieval and analysis modes as needed, all inside a secure sandbox environment.
Microsoft Copilot Researcher and Analyst
Microsoft has introduced two related reasoning agents:
A Researcher is focused on complex, multi-step research tasks that combine web information with a user’s work data. It uses sophisticated orchestration and search capabilities to handle multi-stage questions.
An Analyst is an advanced data analytics agent that can interpret and transform raw data into useful insights. It uses a chain-of-thought reasoning approach to break down analytical problems, apply appropriate operations, and present the results.
Both Researcher and Analyst are designed to work securely over enterprise data and the public web.
Qwen Deep Research
Alibaba’s Qwen Deep Research is an advanced agent that supports dynamic research blueprinting.
It can generate an initial research plan, then refine that plan interactively. Qwen’s architecture supports concurrent task orchestration, which means that retrieval, validation, and synthesis of information can happen in parallel. This allows the system to retrieve data, verify it, and integrate it into the final output efficiently.
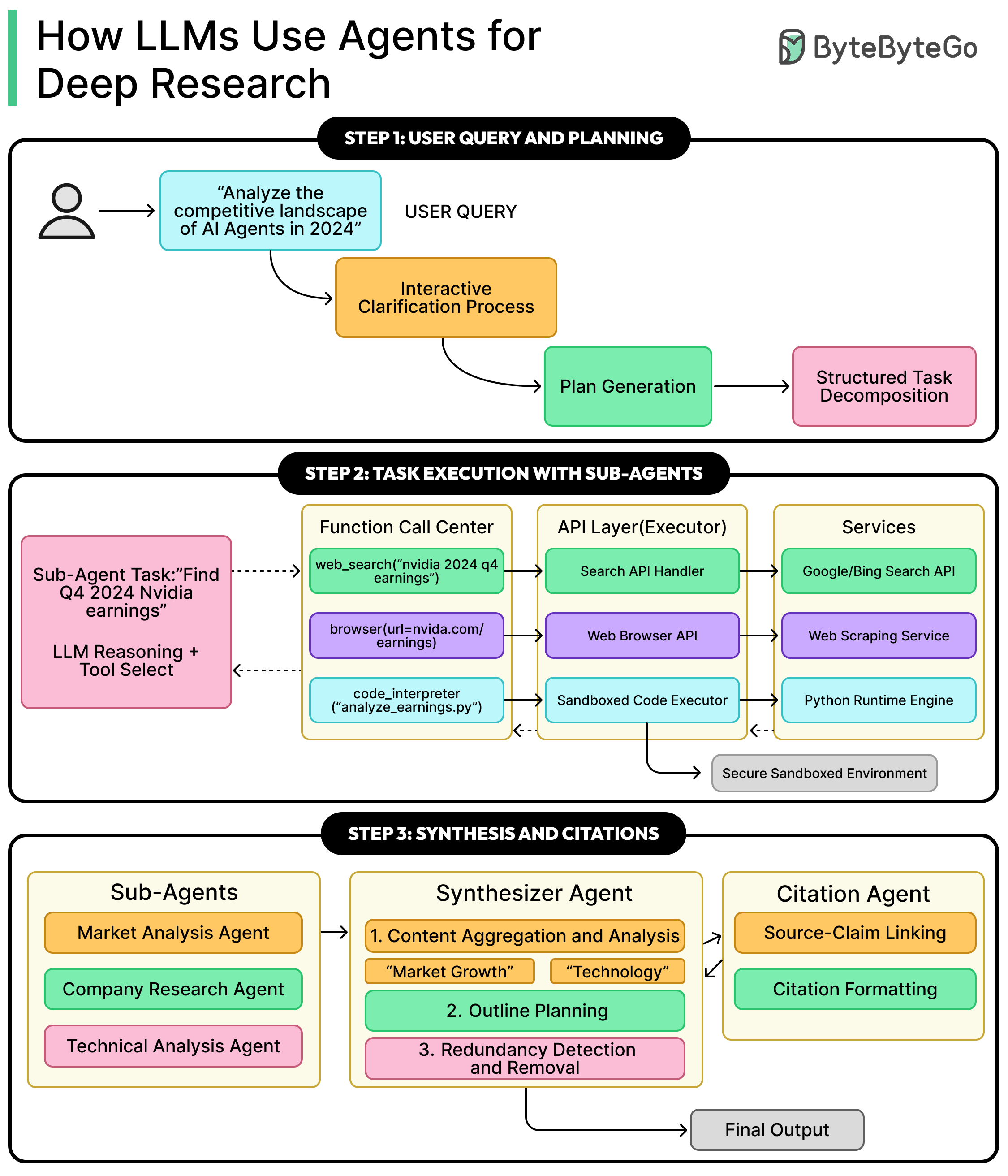
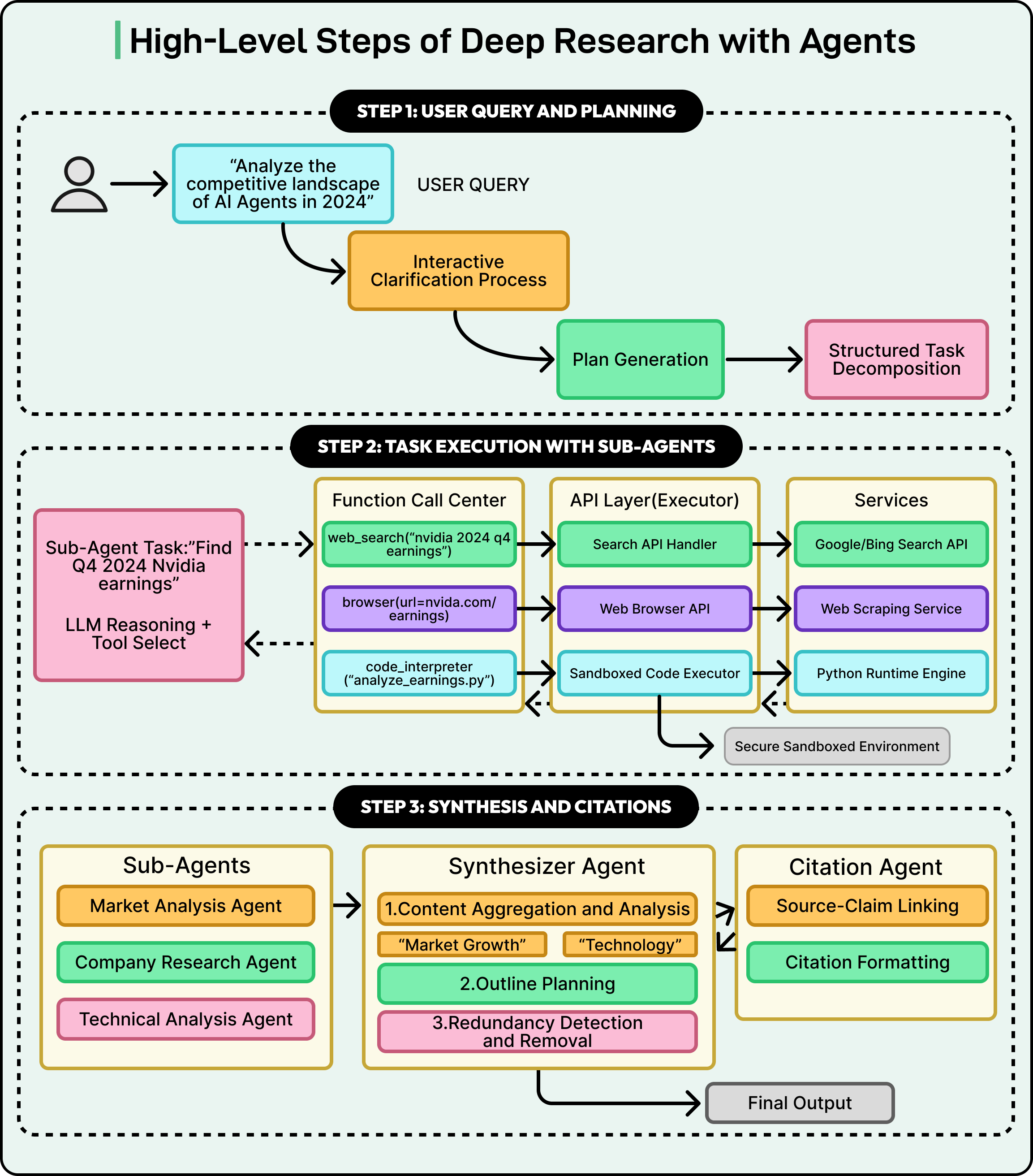
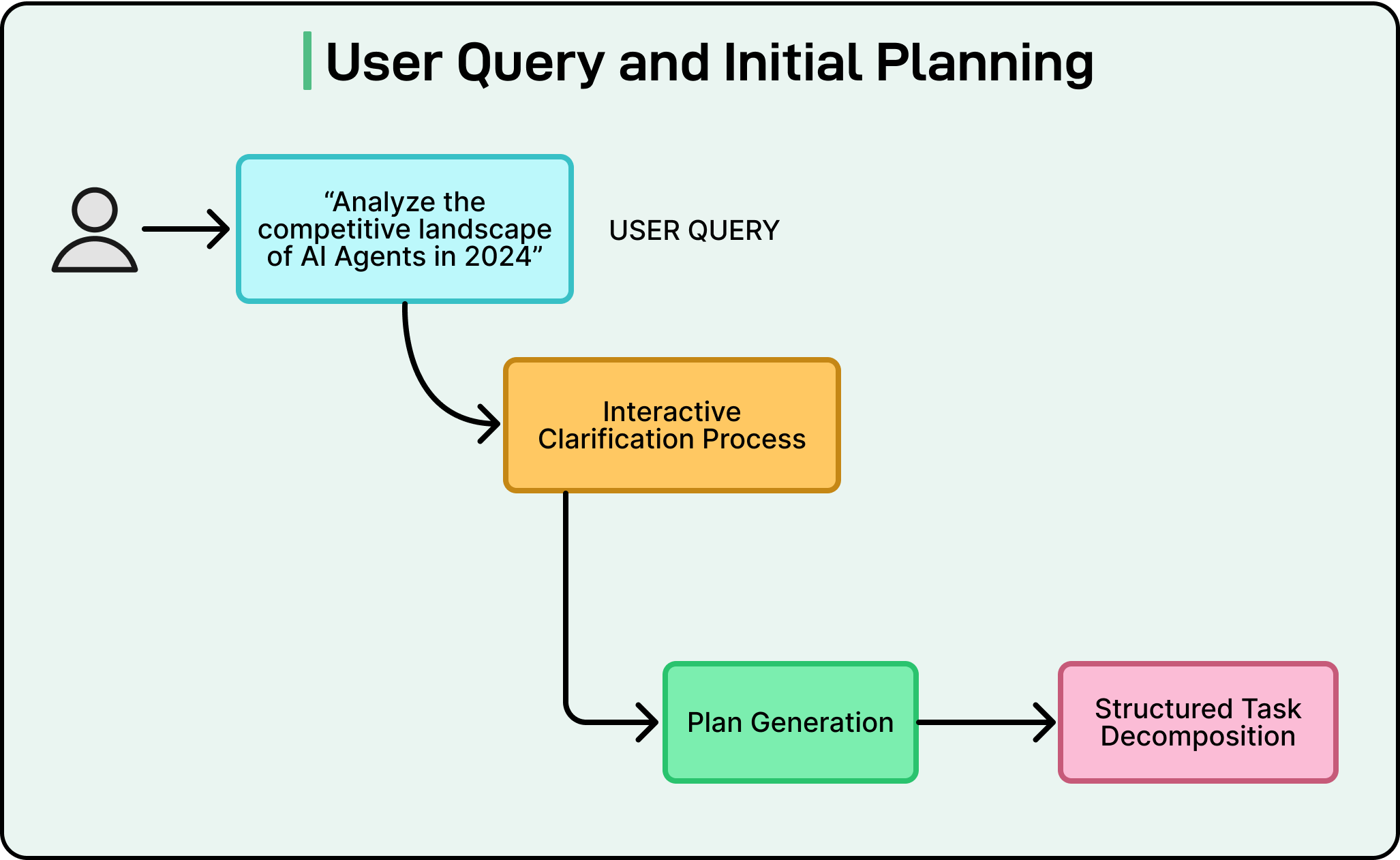
User Query and Initial Planning
The entire deep research workflow starts with a single user query.
Users can phrase requests in many different ways. Some users write very vague prompts such as “tell me everything about AI agents,” while others provide highly detailed, focused instructions. The system must be able to handle this variability and translate the query into a precise, machine-executable research plan.
This initial stage is critical. It converts the user’s often broad or ambiguous request into a clear strategy with specific steps. The quality of the final report is directly tied to the quality of this plan. If the plan is incomplete or misinterprets the user’s intent, the resulting research will miss key information or go in the wrong direction.
See the diagram below:
Different systems handle this planning phase in different ways.
Interactive Clarification (OpenAI)
Some architectures, such as OpenAI’s Deep Research, use an interactive clarification approach. Here, the agent does not immediately start a long research process. Instead, it may ask the user follow-up questions. These questions are designed to refine the research scope, clarify the objectives, and confirm exactly what information the user cares about.
For example, if the user asks for a comparison of technologies, the agent might ask whether the user wants only recent developments, whether specific regions should be included, or whether certain constraints apply. This conversational back-and-forth continues until the agent has a crisp understanding of the user’s needs, at which point it commits to the full research process.
Autonomous Plan Proposal (Gemini)
Other systems, such as Google’s Gemini, take a different path. Rather than asking the user follow-up questions by default, Gemini can autonomously generate a comprehensive multi-step plan based on its interpretation of the initial query. This plan outlines the sub-tasks and research angles the system intends to explore.
Gemini then presents this proposed plan to the user for review and approval. The user can read the plan, make edits, add constraints, or remove unwanted sub-tasks. Once the user is satisfied and approves the plan, the system begins the research process.
Sub-Agent Delegation and Parallel Execution
Once the plan is ready, the system moves from strategy to execution. Instead of a single agent performing all steps, the lead agent delegates work to multiple sub-agents that “work for” it.
The diagram below from Anthropic shows how the lead agent assigns work to specialized agents that run in parallel and then gather results back into a central synthesis process.
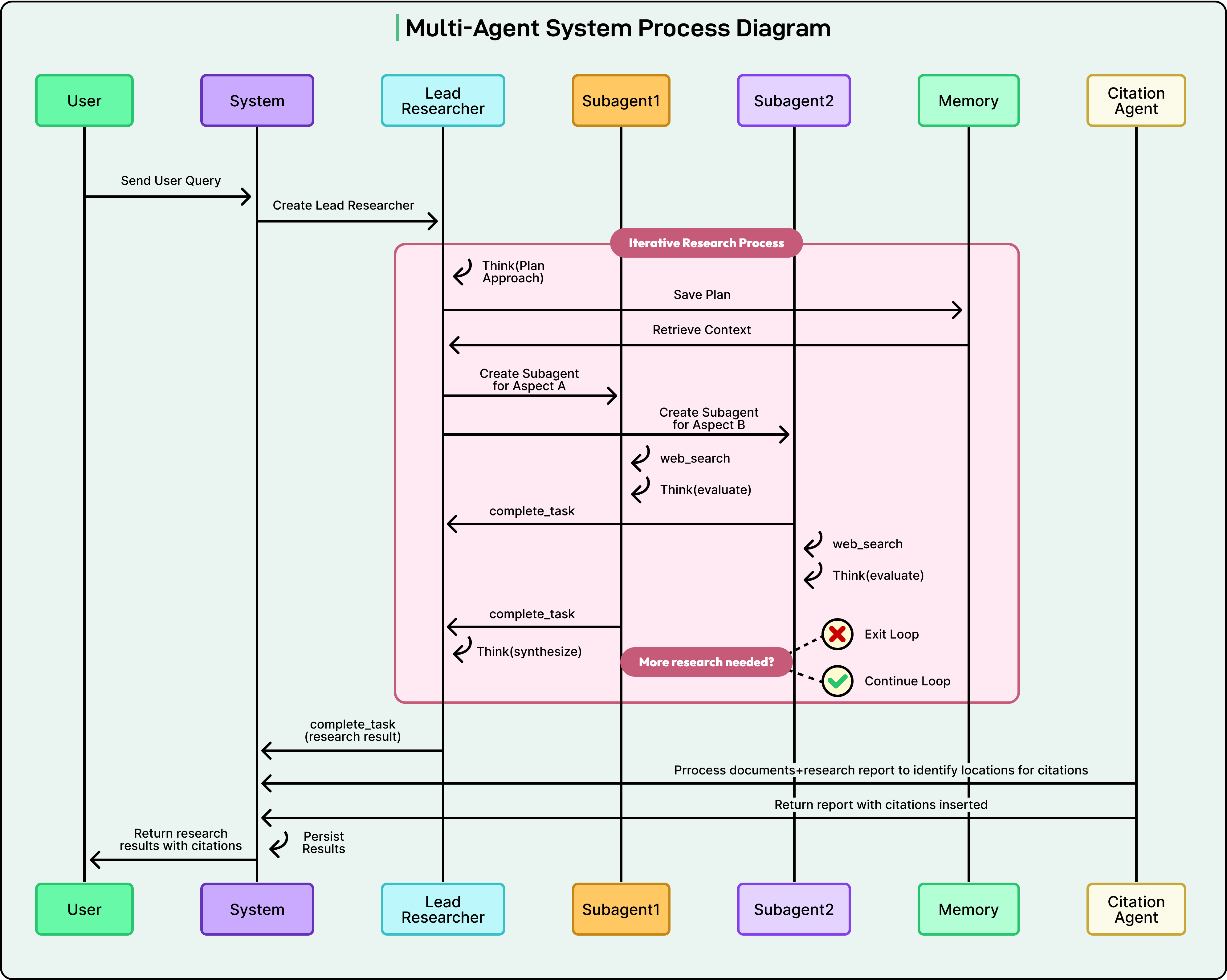
Task Delegation and Sub-Agent Specialization
The lead agent delegates each sub-task using a structured API call. Technically, this means the orchestrator calls another service (the sub-agent) with a payload that contains everything the sub-agent needs:
A precise prompt that explains its specific research goal, such as “Investigate the financial performance of NVIDIA in Q4 2024.”
Any constraints, such as time ranges, data sources, or limits on how many pages to read.
Access permissions and tool configuration, so the sub-agent knows which tools it can use.
Sub-agents are often specialized rather than fully general. While some systems may have general-purpose “research agents,” it is more common to see a pool of agents tuned for particular functions. Examples include:
A web search agent specialized in forming effective search queries, interacting with search engines, and interpreting result snippets.
A data analysis agent that has access to a code interpreter and can perform statistical analyses, process CSV files, or generate simple visualizations.
By using specialized agents, the system can apply the best tool and approach to each part of the plan, which improves both the accuracy and efficiency of the overall research.
Parallel Execution and Tool Use
A key benefit of this architecture is parallel execution. Since sub-agents are separate services, many of them can run at the same time. One sub-agent might be researching market trends, another might be gathering historical financial data, and a third might be investigating competitor strategies, all in parallel.
However, not all tasks run simultaneously. Some tasks must wait for others to complete. The orchestrator keeps track of dependencies and triggers sub-agents when their inputs are ready.
To interact with the outside world, sub-agents use tools. The agents themselves do not have direct access to the web or files. Instead, they issue tool calls that the system executes on their behalf.
Common tools include:
Search tool: The agent calls something like web_search(query=”analyst ratings for Microsoft 365 Copilot”). The system sends this query to an external search engine API (such as Google or Bing) and returns a list of URLs and snippets.
Browser tool: After receiving search results, the agent can call browse(url=”...”) to fetch the full content of a webpage. The browser tool returns the page text, which the agent then processes.
Code interpreter tool: For numerical or data-heavy tasks, the agent can write Python code and execute it in a secure, sandboxed environment. The code interpreter might read CSV data, compute averages, or run basic analyses. The agent then reads the output and incorporates the findings into its report.
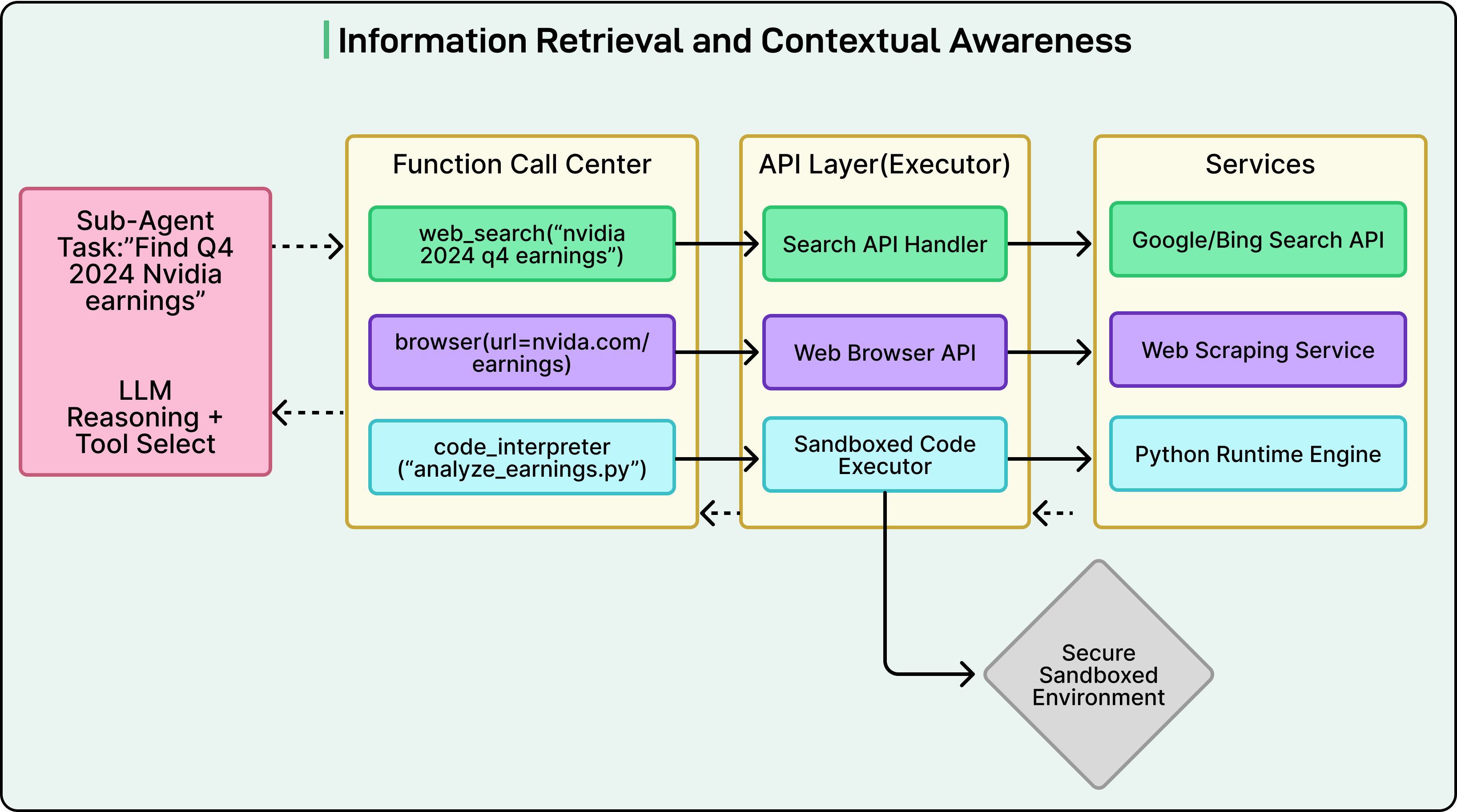
Information Retrieval and Contextual Awareness
As a sub-agent receives data from tools, it must constantly evaluate whether the information is relevant to its goal. This involves:
Checking whether the source is authoritative or credible.
Cross-referencing facts across multiple pages when possible.
Noticing when initial search results are weak and adjusting the query.
For example, if a search returns mostly irrelevant marketing pages, the agent might refine the query with more specific terms or filters. It might add keywords like “PDF,” “quarterly report,” or a specific year to narrow the results.
When the agent finds useful content, it extracts the relevant snippets and stores them along with their original URLs. This pairing of content and citation is essential because it ensures that every piece of information used later in the synthesis stage is traceable back to its source.
Each sub-agent maintains its own short-term memory or “context” of what it has seen so far. This memory allows it to build a coherent understanding of its sub-task and avoid repeating work. When the sub-agent finishes its assignment, it returns a well-structured packet of information that includes both the findings and their citations.
The output of the entire retrieval phase is not yet a single document. Instead, it is a collection of these self-contained information packets from all sub-agents, each focused on a different part of the research problem.
See the diagram below:
Synthesis and Report Generation
Once all sub-agents return their results, the system enters the synthesis phase. At this point, the system has a large set of fragmented insights, each tied to a specific part of the research plan. The objective is to transform these pieces into a unified report.
See the diagram below:
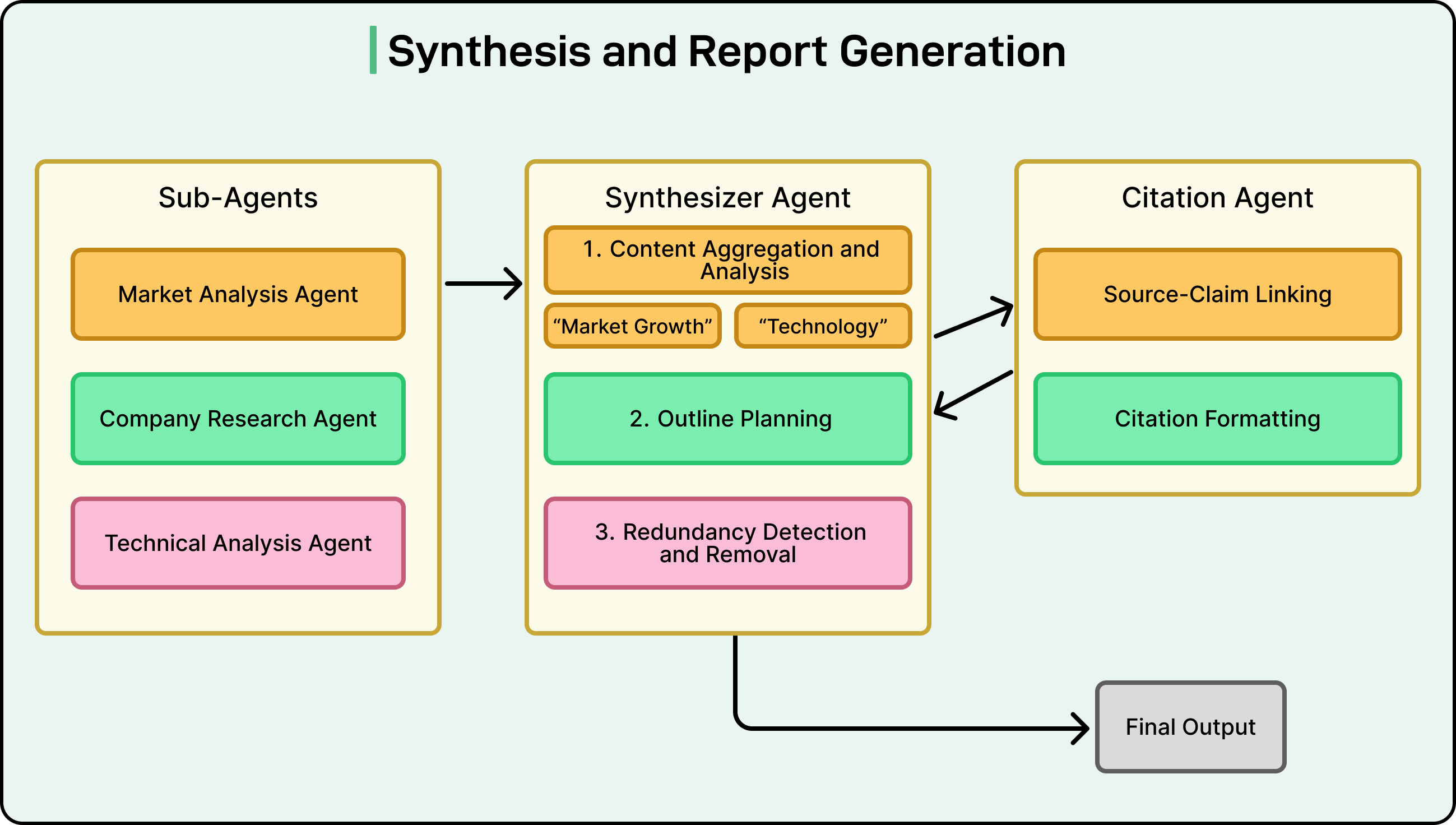
Content Aggregation and Thematic Analysis
The orchestrator or synthesizer agent begins by collecting all information packets. It performs a high-level analysis to identify themes, overlaps, and logical connections. For example, insights about market adoption may complement insights about customer sentiment, and both may feed into a broader section of the report.
The synthesizer then constructs a narrative outline for the final document. It decides the structure that best fits the material, whether chronological, thematic, or based on a problem and solution. Redundant information from multiple sub-agents is merged into a single, clean statement.
Narrative Generation and the Citation Process
With the outline ready, the agent begins writing the report. It incorporates extracted facts, creates transitions between sections, and maintains a consistent tone. As it writes, each claim is connected to its source. Some systems assign this step to a dedicated citation agent that reviews the draft and inserts citations in the correct locations.
This stage is important because it prevents hallucinations and ensures that every assertion in the final report can be traced back to a verified source.
The outcome is a polished research document supported by citations and, when needed, a formal bibliography.
Conclusion
Deep Research systems rely on multi-agent architectures that coordinate planning, parallel exploration, and structured synthesis.
Specialized sub-agents retrieve information, evaluate it, and return detailed findings. The orchestrator or synthesizer then turns this distributed knowledge into a coherent and well-cited report. As LLMs improve in planning, reasoning, and tool use, these systems will continue to become more capable, more reliable, and more comprehensive.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
“Deep Research systems rely on multi-agent architectures that coordinate planning, parallel exploration, and structured synthesis.”
This was a really good way of putting this whole idea in a simple manner.
Great post thank you.
Very nice article. Its a masterclass in itself.