
How OpenAI Scaled to 800 Million Users With Postgres

Sentry’s AI debugger fixes code wherever it breaks (Sponsored)

🤖Most AI coding tools only see your source code. Seer, Sentry’s AI debugging agent, uses everything Sentry knows about how your code has behaved in production to debug locally, in your PR, and in production.
🛠️How it works:
Seer scans & analyzes issues using all Sentry’s available context.
In development, Seer debugs alongside you as you build
In review, Seer alerts you to bugs that are likely to break production, not nits
In production, Seer can find a bug’s root cause, suggest a fix, open a PR automatically, or send the fix to your preferred IDE.
OpenAI scaled PostgreSQL to handle millions of queries per second for 800 million ChatGPT users. They did it with just a single primary writer supported by read replicas.
At first glance, this should sound impossible. The common wisdom suggests that beyond a certain scale, you must shard the database or risk failure. The conventional playbook recommends embracing the complexity of splitting the data across multiple independent databases.
OpenAI’s engineering team chose a different path. They decided to see just how far they could push PostgreSQL.
Over the past year, their database load grew by more than 10X. They experienced the familiar pattern of database-related incidents: cache layer failures causing sudden read spikes, expensive queries consuming CPU, and write storms from new features. Yet through systematic optimization across every layer of their stack, they achieved five-nines availability with low double-digit millisecond latency. But the road wasn’t easy.
In this article, we will look at the challenges OpenAI faced while scaling Postgres and how the team handled the various scenarios.
Disclaimer: This post is based on publicly shared details from the OpenAI Engineering Team. Please comment if you notice any inaccuracies.
Understanding Single-Primary Architecture
A single-primary architecture means one database instance handles all writes, while multiple read replicas handle read queries.
See the diagram below:
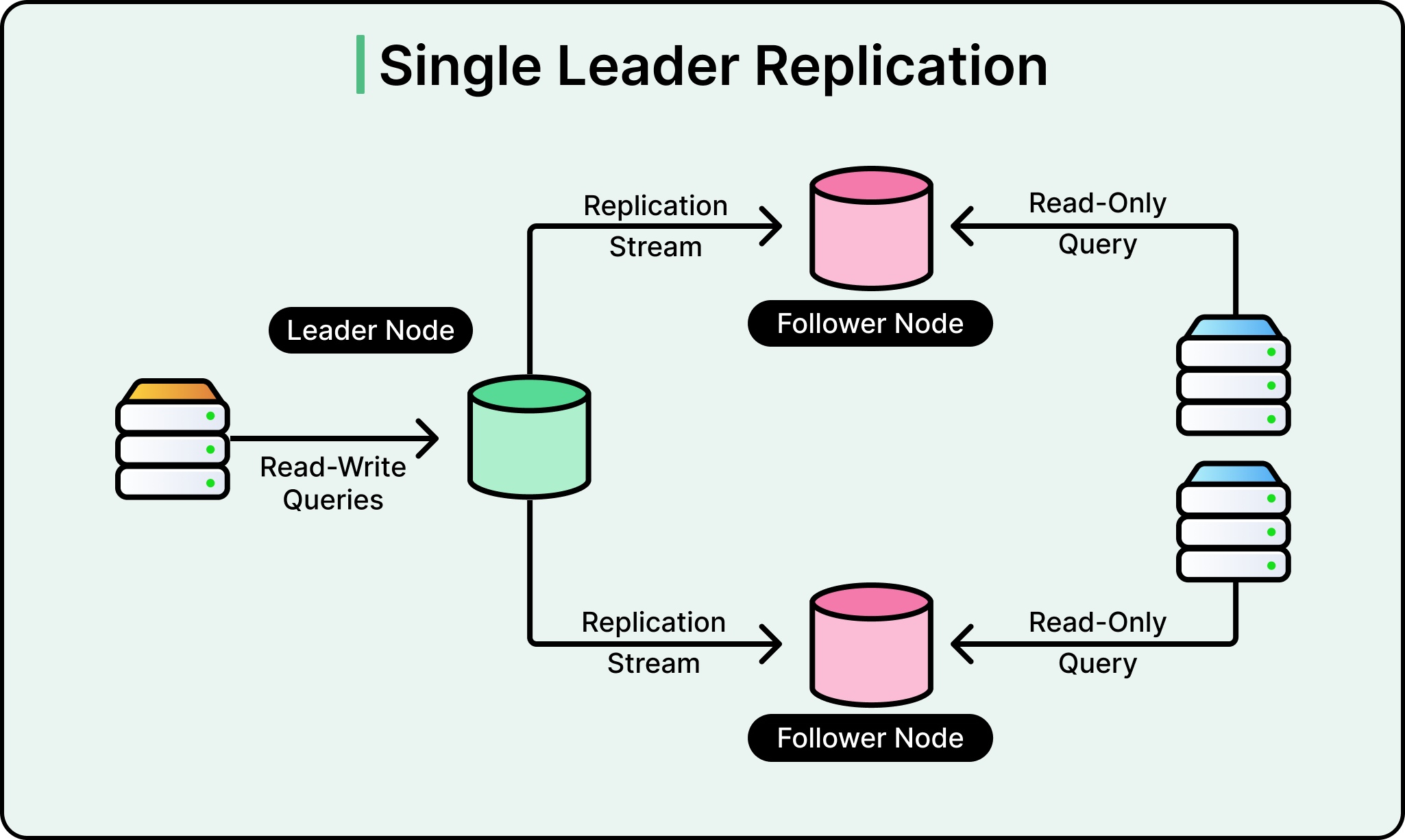
This design creates an inherent bottleneck because writes cannot be distributed. However, for read-heavy workloads like ChatGPT, where users primarily fetch data rather than modify it, this architecture can scale effectively if properly optimized.
OpenAI avoided sharding its PostgreSQL deployment for pragmatic reasons. Sharding would require modifying hundreds of application endpoints and could take months or years to complete. Since their workload is primarily read-heavy and current optimizations provide sufficient capacity, sharding remains a future consideration rather than an immediate necessity.
So how did OpenAI go about scaling the read replicas? There were three main pillars to their overall strategy:
Pillar 1: Minimizing Primary Database Load
The primary database represents the system’s most critical bottleneck. OpenAI implemented multiple strategies to reduce pressure on this single writer:
Offloading Read Traffic: OpenAI routes most read queries to replicas rather than the primary. However, some read queries must remain on the primary because they occur within write transactions. For these queries, the team ensures maximum efficiency to avoid slow operations that could cascade into broader system failures.
Migrating Write-Heavy Workloads: The team migrated workloads that could be horizontally partitioned to sharded systems like Azure Cosmos DB. These shardable workloads can be split across multiple databases without complex coordination. Workloads that are harder to shard continue to use PostgreSQL but are being gradually migrated.
Application-Level Write Optimization: OpenAI fixed application bugs that caused redundant database writes. They implemented lazy writes where appropriate to smooth traffic spikes rather than hitting the database with sudden bursts. When backfilling table fields, they enforce strict rate limits even though the process can take over a week. This patience prevents write spikes that could impact production stability.
Pillar 2: Query and Connection Optimization
First, OpenAI identified several expensive queries that consumed disproportionate CPU resources. One particularly problematic query joined 12 tables, and spikes in this query’s volume caused multiple high-severity incidents.
The team learned to avoid complex multi-table joins in their OLTP system. When joins are necessary, OpenAI breaks down complex queries and moves join logic to the application layer, where it can be distributed across multiple application servers.
Object-Relational Mapping frameworks, commonly known as ORMs, generate SQL automatically from code objects. While convenient for developers, ORMs can produce inefficient queries. OpenAI carefully reviews all ORM-generated SQL to ensure it performs as expected. They also configure timeouts like idle_in_transaction_session_timeout to prevent long-running idle queries from blocking autovacuum (PostgreSQL’s cleanup process).
Second, Azure PostgreSQL instances have a maximum connection limit of 5,000. OpenAI previously experienced incidents where connection storms exhausted all available connections, bringing down the service.
Connection pooling solves this problem by reusing database connections rather than creating new ones for each request. Think of it as carpooling. Instead of everyone driving their own car to work, people share vehicles to reduce traffic congestion.
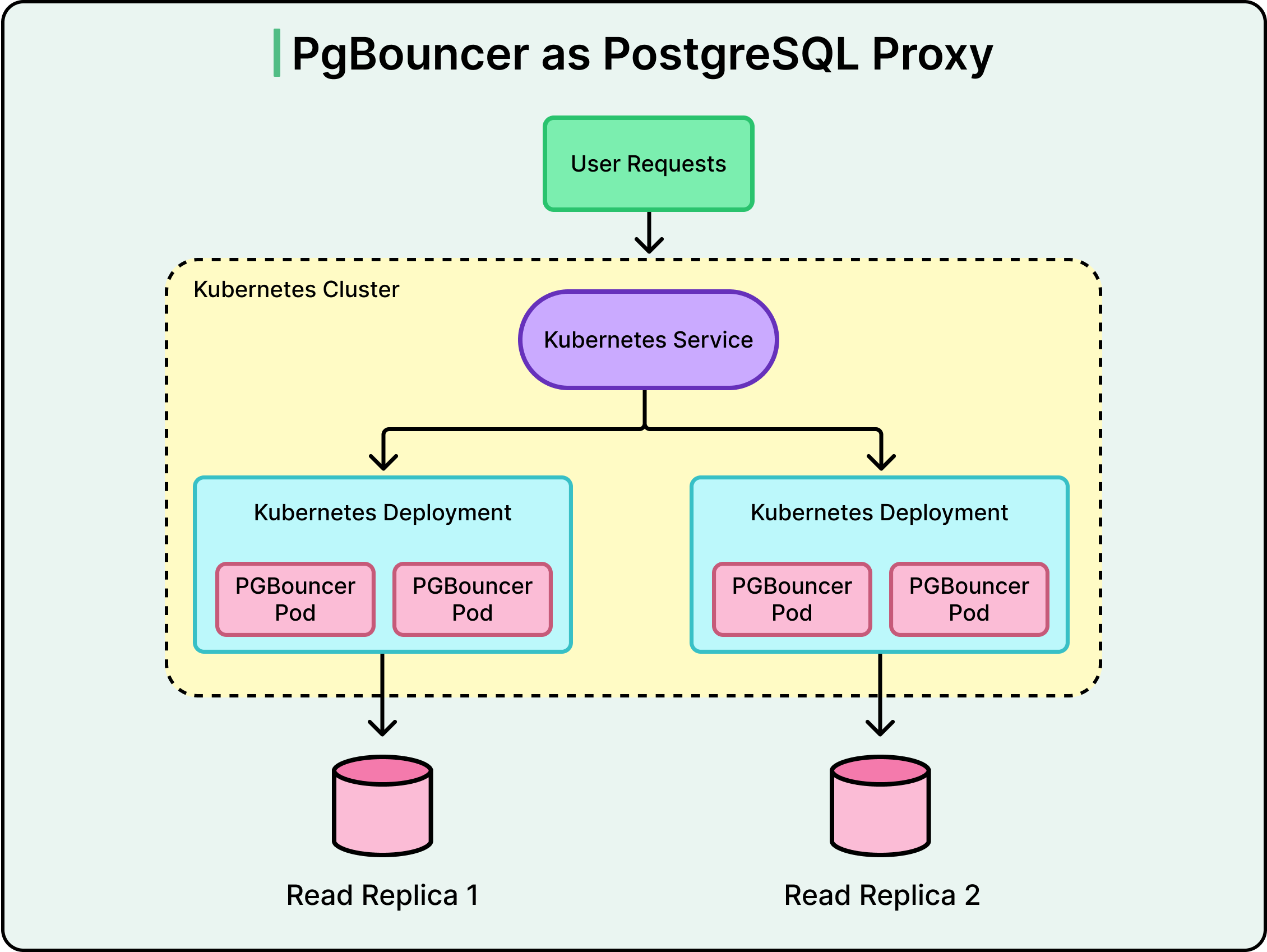
OpenAI deployed PgBouncer as a proxy layer between applications and databases. PgBouncer runs in statement or transaction pooling mode, efficiently reusing connections and reducing the number of active client connections. In benchmarks, average connection time dropped from 50 milliseconds to just 5 milliseconds.
Each read replica has its Kubernetes deployment running multiple PgBouncer pods. Multiple deployments sit behind a single Kubernetes Service that load-balances traffic across pods. OpenAI co-locates the proxy, application clients, and database replicas in the same geographic region to minimize network latency and connection overhead.
See the diagram below:
Beyond Chatbots: System Design for AI Backend (Sponsored)

Today’s AI agents are mostly chatbots and copilots - reactive tools waiting for human input. But agents are moving into the backend: running autonomously, replacing brittle rule engines with reasoning, creating capabilities you couldn’t build with deterministic pipelines.
This changes everything about your architecture. Agent reasoning takes seconds, not milliseconds. You need identity beyond API keys. You need to know why an agent made every decision. And you need to scale from one prototype to thousands.
AgentField is the open-source infrastructure layer for autonomous AI agents in production.
Pillar 3: Preventing Cascading Failures
OpenAI identified a recurring pattern in their incidents. To reduce read pressure on PostgreSQL, OpenAI uses a caching layer to serve most read traffic.
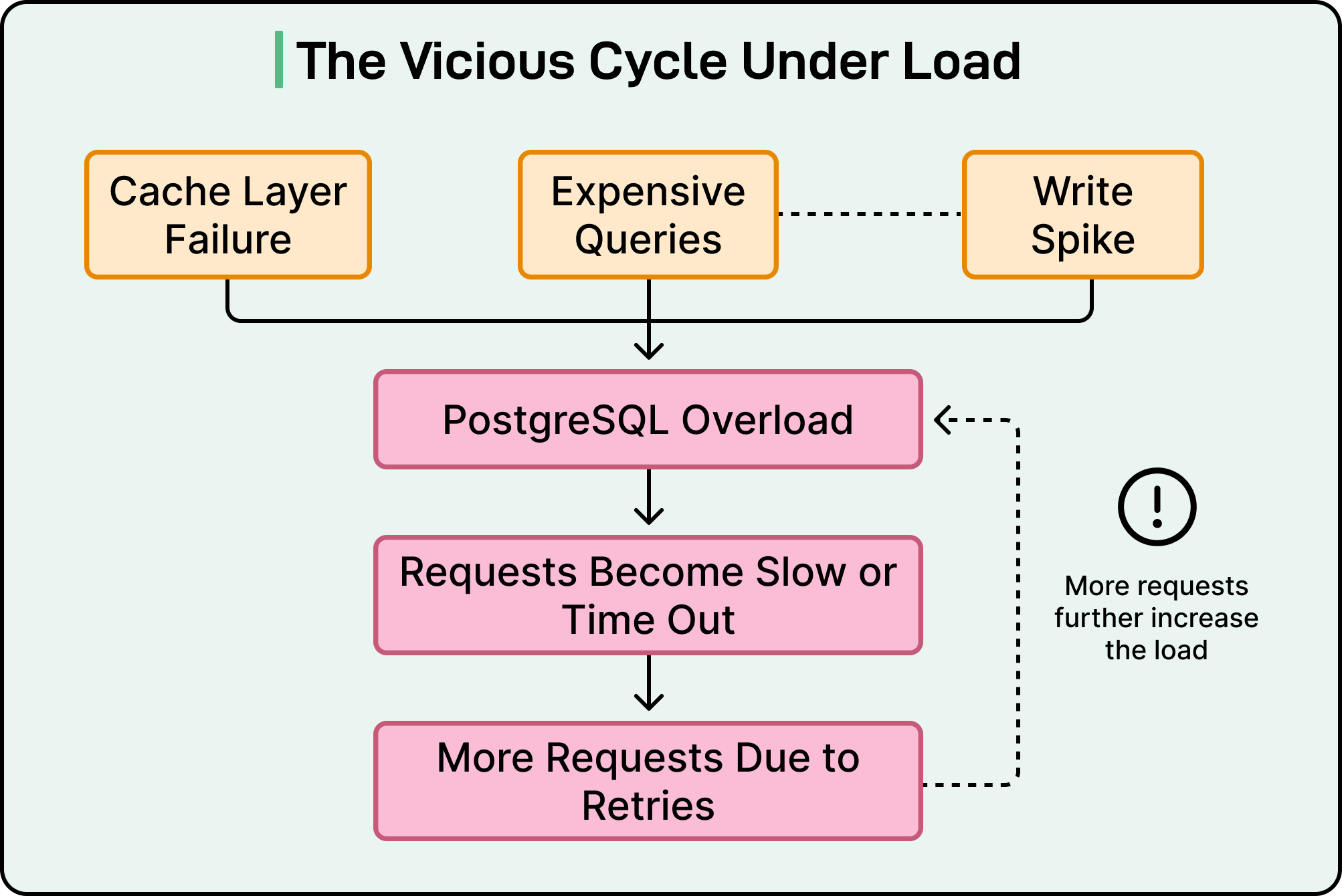
However, when cache hit rates drop unexpectedly, the burst of cache misses can push massive request volumes directly to PostgreSQL. In other words, an upstream issue causes a sudden spike in database load. This could be widespread cache misses from a caching layer failure, expensive multi-way joins saturating the CPU, or a write storm from a new feature launch.
As resource utilization climbs, query latency rises, and requests begin timing out. Applications then retry failed requests, which further amplifies the load. This creates a feedback loop that can degrade the entire service.
To prevent this situation, the OpenAI engineering team implemented a cache locking and leasing mechanism to prevent this scenario. When multiple requests miss on the same cache key, only one request acquires a lock and fetches data from PostgreSQL to repopulate the cache. All other requests wait for the cache update rather than simultaneously hitting the database.
See the diagram below:
Taking further precautions, OpenAI implemented rate limiting across the application, connection pooler, proxy, and query layers. This prevents sudden traffic spikes from overwhelming database instances and triggering cascading failures. They also avoid overly short retry intervals, which can trigger retry storms where failed requests multiply exponentially.
The team enhanced their ORM layer to support rate limiting and can fully block specific query patterns when necessary. This targeted load shedding enables rapid recovery from sudden surges of expensive queries.
Despite all this, OpenAI encountered situations where certain requests consumed disproportionate resources on PostgreSQL instances, creating a problem known as the noisy neighbor effect. For example, a new feature launch might introduce inefficient queries that heavily consume CPU, slowing down other critical features.
To mitigate this, OpenAI also isolates workloads onto dedicated instances. They split requests into low-priority and high-priority tiers and route them to separate database instances. This ensures that low-priority workload spikes cannot degrade high-priority request performance. The same strategy applies across different products and services.
Addressing PostgreSQL’s Architectural Constraints
PostgreSQL uses Multi-Version Concurrency Control for managing concurrent transactions. When a query updates a tuple (database row) or even a single field, PostgreSQL copies the entire row to create a new version. This design allows multiple transactions to access different versions simultaneously without blocking each other.
However, MVCC creates challenges for write-heavy workloads. It causes write amplification because updating one field requires writing an entire row. It also causes read amplification because queries must scan through multiple tuple versions, called dead tuples, to retrieve the latest version. This leads to table bloat, index bloat, increased index maintenance overhead, and complex autovacuum tuning requirements.
OpenAI’s primary strategy for addressing MVCC limitations involves migrating write-heavy workloads to alternative systems and optimizing applications to minimize unnecessary writes. They also restrict schema changes to lightweight operations that do not trigger full table rewrites.
Another constraint with Postgres is related to schema changes. Even small schema changes like altering a column type can trigger a full table rewrite in PostgreSQL. During a table rewrite, PostgreSQL creates a new copy of the entire table with the change applied. For large tables, this can take hours and block access.
To handle this, OpenAI enforces strict rules around schema changes:
Only lightweight schema changes are permitted, such as adding or removing certain columns that do not trigger table rewrites.
All schema changes have a 5-second timeout.
Creating and dropping indexes must be done concurrently to avoid blocking.
Schema changes are restricted to existing tables only.
New features requiring additional tables must use alternative sharded systems like Azure Cosmos DB.
When backfilling a table field, OpenAI applies strict rate limits even though the process can take over a week. This ensures stability and prevents production impact.
High Availability and Disaster Recovery
With a single primary database, the failure of that instance affects the entire service. OpenAI addressed this critical risk through multiple strategies.
First, they offloaded most critical read-only requests from the primary to replicas. If the primary fails, read operations continue functioning. While write operations would still fail, the impact is significantly reduced.
Second, OpenAI runs the primary in High Availability mode with a hot standby. A hot standby is a continuously synchronized replica that remains ready to take over immediately. If the primary fails or requires maintenance, OpenAI can quickly promote the standby to minimize downtime. The Azure PostgreSQL team has done significant work ensuring these failovers remain safe and reliable even under high load.
For read replica failures, OpenAI deploys multiple replicas in each region with sufficient capacity headroom. A single replica failure does not lead to a regional outage because traffic automatically routes to other replicas.
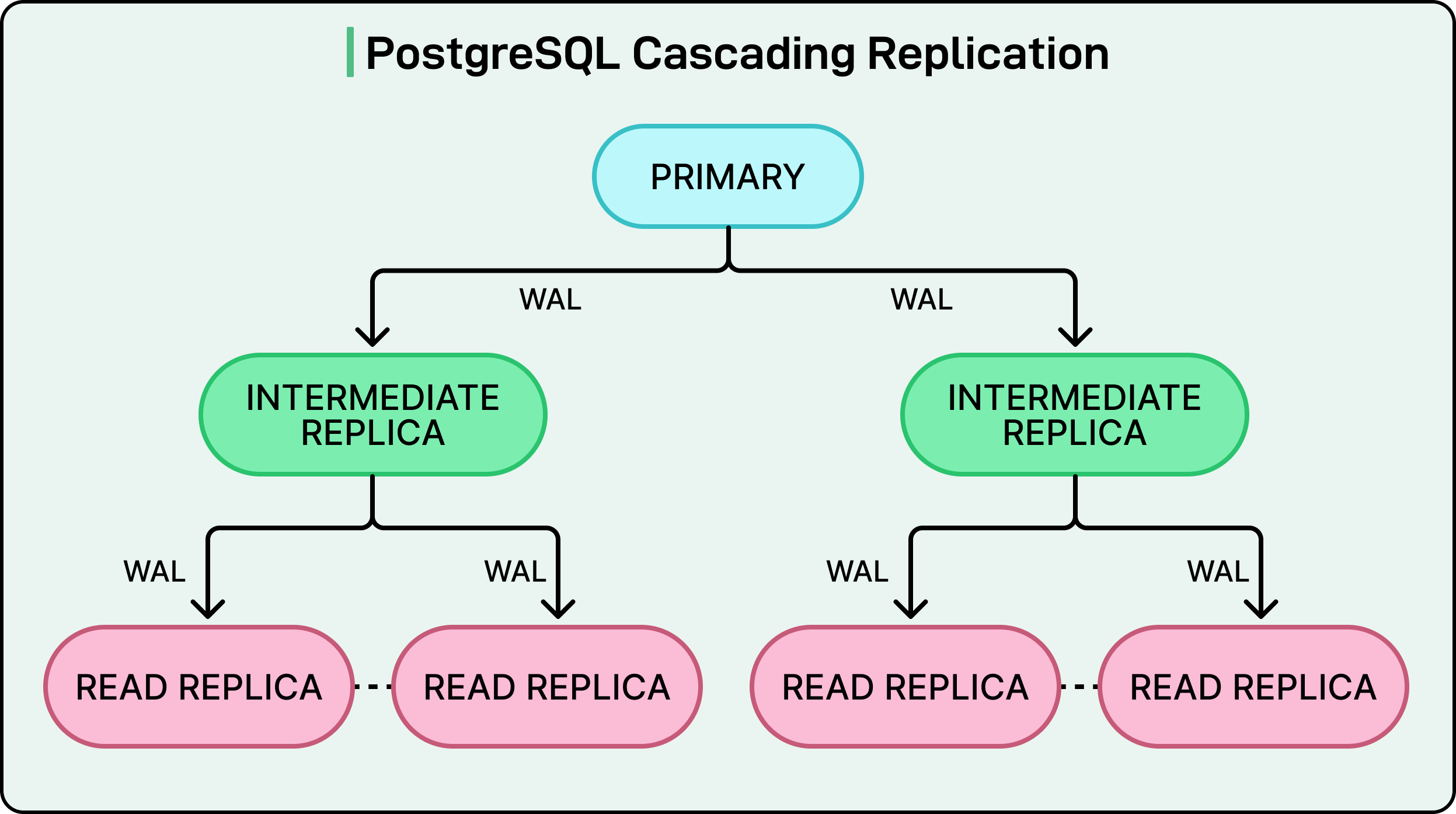
The primary database streams Write Ahead Log data to every read replica. WAL contains a record of all database changes, which replicas replay to stay synchronized. As the number of replicas increases, the primary must ship WAL to more instances, increasing pressure on network bandwidth and CPU. This causes higher and more unstable replica lag.
As mentioned, OpenAI currently operates nearly 50 read replicas across multiple geographic regions. While this scales well with large instance types and high network bandwidth, the team cannot add replicas indefinitely without eventually overloading the primary.
To address this future constraint, OpenAI is collaborating with the Azure PostgreSQL team on cascading replication. In this architecture, intermediate replicas relay WAL to downstream replicas rather than the primary streaming to every replica directly. This tree structure allows scaling to potentially over 100 replicas without overwhelming the primary. However, it introduces additional operational complexity, particularly around failover management. The feature remains in testing until the team ensures it can fail over safely.
See the diagram below:
Conclusion
OpenAI’s optimization efforts have delivered impressive results.
The system handles millions of queries per second while maintaining replication lag near zero. The architecture delivers low double-digit millisecond p99 latency, meaning 99 percent of requests complete in under roughly 50 milliseconds. The system achieves five-nines availability, equivalent to 99.999 percent uptime.
Over the past 12 months, OpenAI experienced only one SEV-0 PostgreSQL incident. This occurred during the viral launch of ChatGPT ImageGen when write traffic suddenly surged by more than 10x as over 100 million new users signed up within a week.
Looking ahead, OpenAI continues migrating remaining write-heavy workloads to sharded systems. The team is working with Azure to enable cascading replication for safely scaling to significantly more read replicas. They will continue exploring additional approaches, including sharded PostgreSQL or alternative distributed systems as infrastructure demands grow.
OpenAI’s experience shows that PostgreSQL can reliably support much larger read-heavy workloads than conventional wisdom suggests. However, achieving this scale requires rigorous optimization, careful monitoring, and operational discipline. The team’s success came not from adopting the latest distributed database technology but from deeply understanding their workload characteristics and eliminating bottlenecks.
References:
Why chatgpt is read-heavy
Each prompt triggers:
- Tokenization (read model vocab)
- Forward pass through billions of parameters
- Retrieval from KV cache
- Sampling
This is compute-heavy reading of model weights, not writing data.
The model weights (hundreds of GBs in large models) are:
- Loaded into GPU memory
- Read repeatedly during inference
- Rarely modified
There is no write to the model during inference.
Writes are limited to:
- Logging conversation history
- Analytics
- Abuse monitoring
Compared to inference traffic, this write volume is small.
Infrastructure stories like this matter because they expose where AI economics become real. User growth looks exciting, but the harder question is where sustainable margins come from when model and serving costs are this high. In my own market analysis work, the winners were usually companies with distribution plus disciplined infrastructure spend, not just better demos.
I dug into those dynamics with February data on who is actually capturing value in the agent wave: https://thoughts.jock.pl/p/ai-agent-landscape-feb-2026-data Scale is impressive, but efficiency will decide who survives.