
How OpenAI Uses Kubernetes And Apache Kafka for GenAI

Supercharge Cursor and Claude with your team’s knowledge (Sponsored)

AI coding tools become more reliable when they understand the “why” behind your code.
With Unblocked’s MCP server, tools like Cursor and Claude now leverage your team’s historical knowledge across tools like GitHub, Slack, Confluence, and Jira, so the code they generate actually makes sense in your system.
“With Claude Code + Unblocked MCP, I’ve finally found the holy grail of engineering productivity: context-aware coding. It’s not hallucinating. It’s pulling insight from everything I’ve ever worked on.” — Staff Engineer @ Nava Benefits
Disclaimer: The details in this post have been derived from the official documentation shared online by the OpenAI and Confluent Engineering Team. All credit for the technical details goes to OpenAI and the Confluent Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
AI systems like the ones developed at OpenAI rely on vast amounts of data. The quality, freshness, and availability of this data directly influence how well the models perform. In the early days, most organizations processed data in batch mode.
Batch processing means you collect data over hours or days and then process it all at once. This approach works well for certain use cases, but it comes with an obvious downside: by the time the data is ready, it may already be stale. For fast-moving AI systems, where user interactions, experiments, and new content are being generated constantly, stale data slows everything down.
This is where stream processing comes in.
In streaming systems, data is processed as it arrives, almost in real time. Instead of waiting for a daily or hourly batch job, the system can quickly transform, clean, and route data to wherever it is needed. For an AI research organization, this means two very important things.
First, fresher training data can be delivered to models, strengthening what the OpenAI Engineering Team calls the “data flywheel.” The more quickly models can learn from new information, the faster they improve.
Second, experimentation becomes faster. Running experiments on models is a daily activity at OpenAI, and the ability to ingest and preprocess logs in near real time means researchers can test ideas, see results, and adjust without long delays.
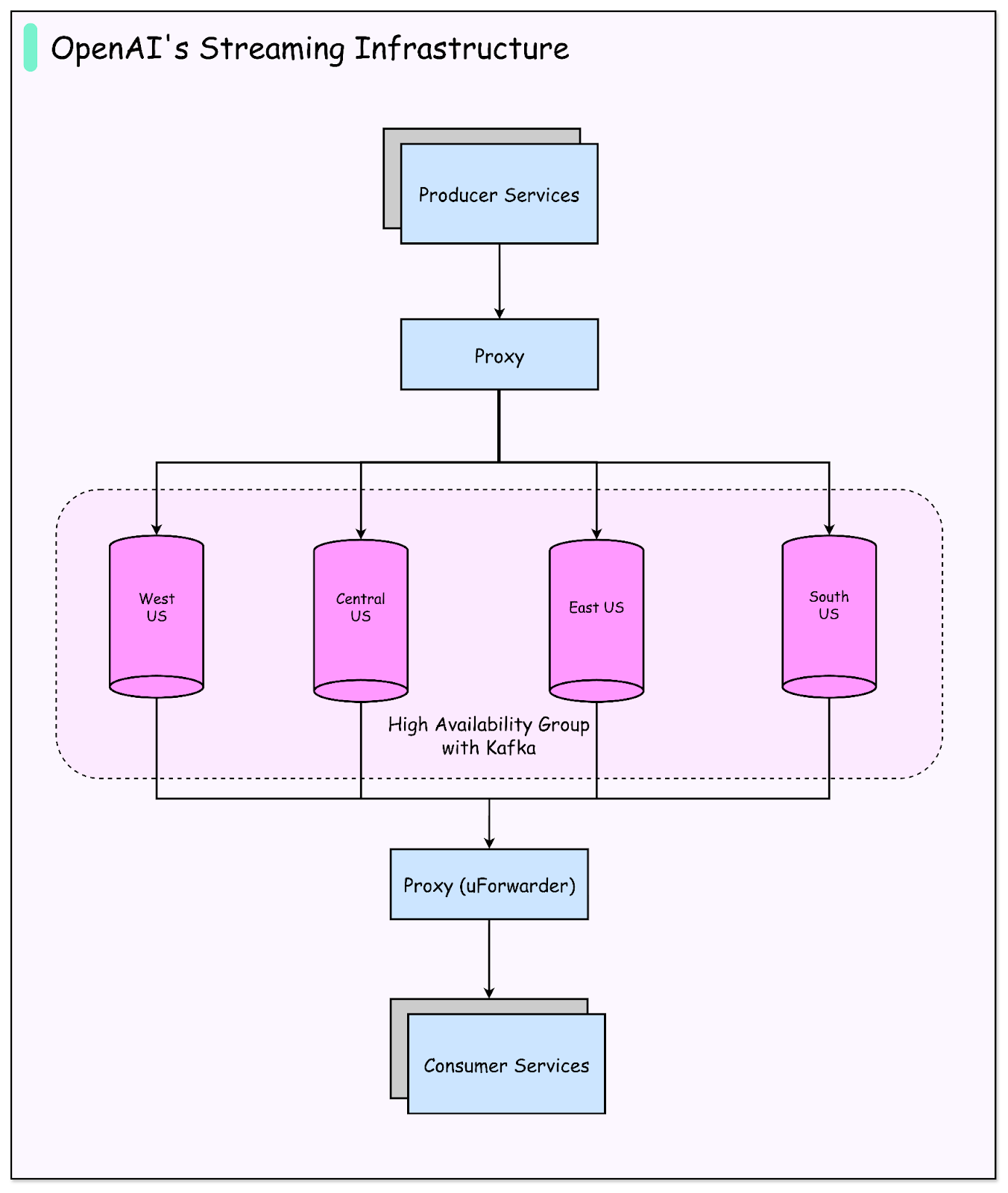
Recognizing these benefits, the OpenAI Engineering Team set out to design a stream processing platform that could handle their unique requirements. They sought a solution where Python is the standard language, while also being scalable, reliable, and fault-tolerant. The platform had to integrate with their existing infrastructure, particularly Kafka, which serves as their backbone for event streaming. Most importantly, it needed to remain highly available even when parts of the system or the cloud provider had issues.
The result was a platform centered on PyFlink running on Kubernetes, reinforced by custom engineering around high availability, state management, and Kafka resilience. In this article, we will understand how OpenAI built such a system and the challenges they faced.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo
Challenges
When the OpenAI Engineering Team began designing its stream processing platform, three major challenges stood out.
The first was the dominance of Python in AI development. Almost every researcher and engineer at OpenAI works primarily in Python. While Apache Flink is powerful, its strongest APIs were originally written in Java and Scala. For a team that wanted data pipelines to feel natural to machine learning practitioners, it was essential to provide a Python-first experience. This meant adopting and extending PyFlink, the Python API for Flink, even though it came with limitations that required additional work.
The second challenge came from cloud capacity and scalability constraints. Cloud providers impose limits on resources like compute, storage, and networking. At the scale that OpenAI operates, these limits can create bottlenecks when running streaming jobs. The platform needed to be resilient to these constraints, ensuring that pipelines could continue to run even if resource availability shifted unexpectedly.
The third and perhaps most complex challenge was the multi-primary Kafka setup. OpenAI runs Kafka in a high-availability configuration where there are multiple primary clusters. This design improves reliability but makes things more complicated for applications like Flink. Standard Flink connectors often assume a single Kafka cluster. In a multi-primary setup, if one cluster becomes unavailable, the default behavior is for Flink to treat this as a fatal error and bring down the entire pipeline. That is unacceptable for mission-critical AI workloads.
Architecture Deep Dive
The stream processing platform at OpenAI is built around Apache Flink, accessed through its Python API called PyFlink. Flink is the engine that actually runs the streaming computations, but by itself, it is not enough.
To make it reliable and usable at OpenAI’s scale, the engineering team added several layers:
A control plane that manages jobs and coordinates failover across multiple Flink clusters.
A Kubernetes-based setup that runs Flink reliably, with isolation between different teams and use cases.
Watchdog services that monitor Kafka and react to changes so pipelines stay stable.
State and storage management that decouples pipeline state from individual clusters, ensuring that jobs can survive outages and move seamlessly between environments.
These layers work together to provide a resilient and developer-friendly system. Let’s look at each one in more detail.
1 - Control Plane
The control plane is the part of the system responsible for job management. In practical terms, this means that when a new streaming job is created, updated, or restarted, the control plane is the service that keeps track of what should be running and where.
See the diagram below that shows the central role of the control plane.
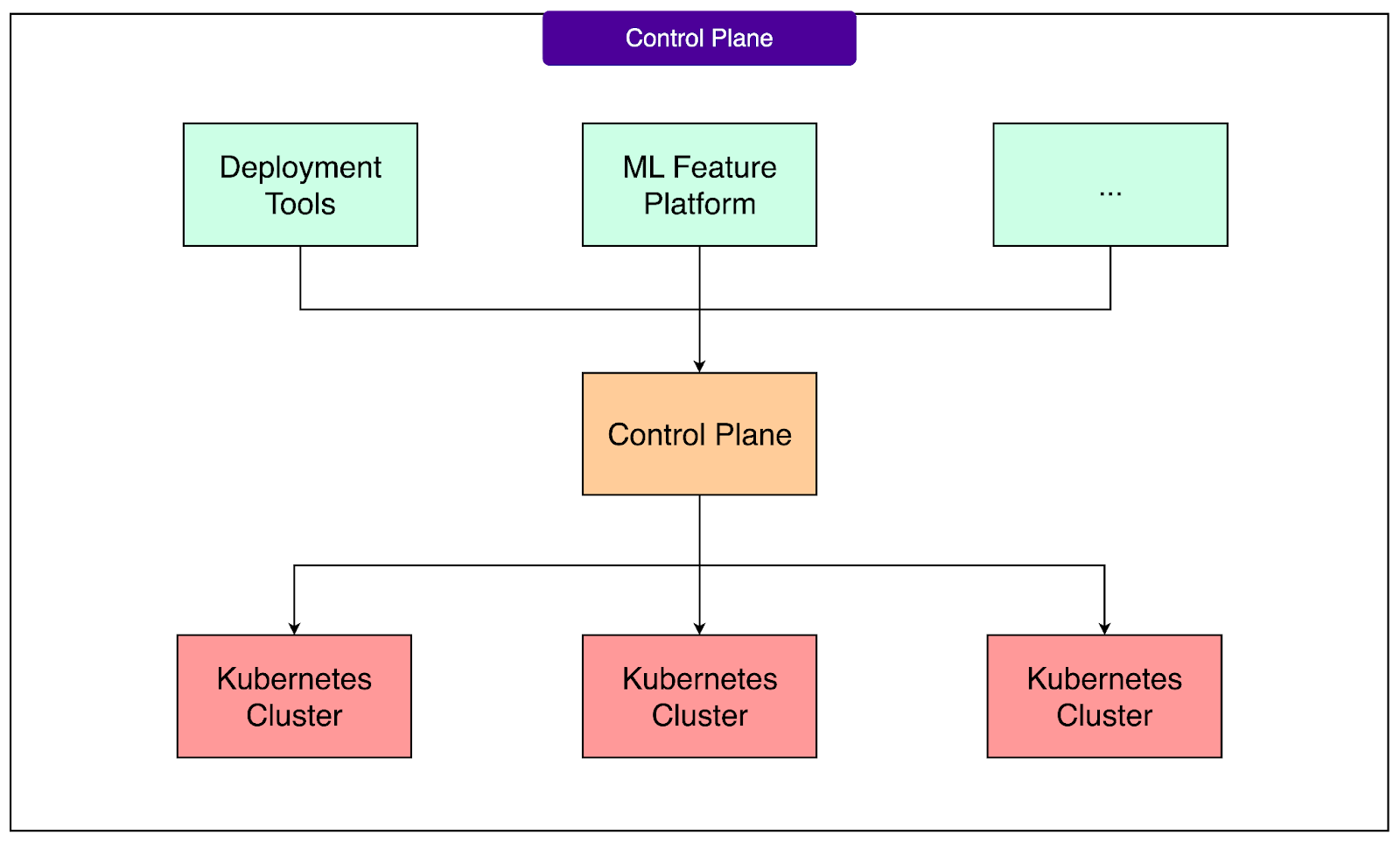
At OpenAI, jobs need to survive failures at the cluster level, not just at the task level. Cloud provider issues that affect an entire Kubernetes cluster are not rare, and without a higher-level manager, an outage could bring down critical pipelines. The control plane addresses this by supporting multi-cluster failover. If one cluster becomes unhealthy, the control plane can move the job to another cluster while ensuring that the job’s state is preserved.
Another important detail is that the control plane integrates with OpenAI’s existing service deployment infrastructure. This means that developers do not need to learn a new system to manage their streaming jobs. Submitting, upgrading, or rolling back a job fits into the same deployment workflows they already use for other services. This integration reduces friction and helps standardize operations across the organization.
2 - Kubernetes Setup
Flink itself does not run directly on bare machines. Instead, it is deployed on Kubernetes, the container orchestration system widely used across the industry.
OpenAI chose to use the Flink Kubernetes Operator, which automates the lifecycle of Flink deployments on Kubernetes. The operator makes it easier to launch Flink jobs, monitor them, and recover from failures without manual intervention.
One of the key design choices here is per-namespace isolation. In Kubernetes, namespaces are a way to partition resources. See the diagram below:
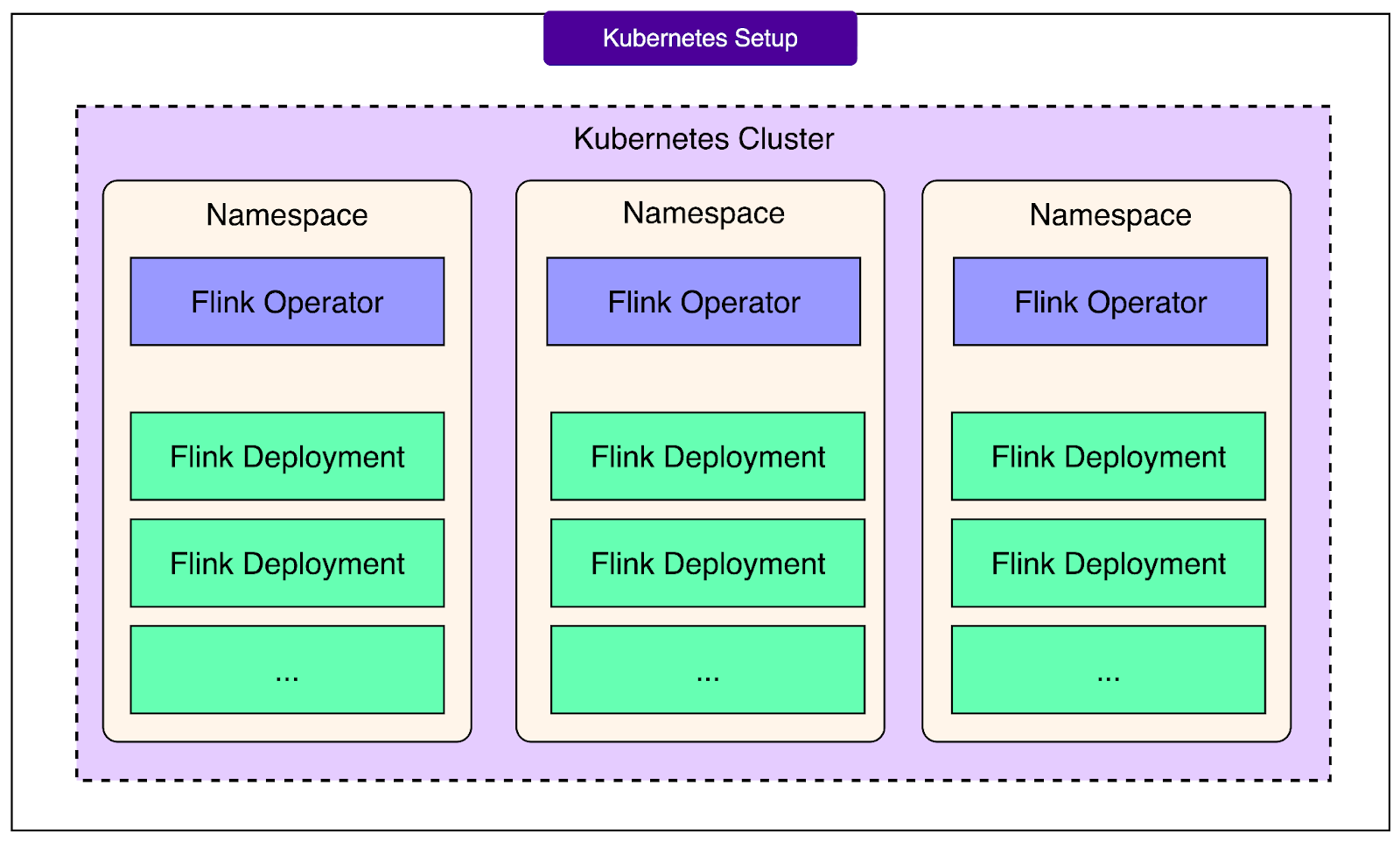
By giving each team or project its own namespace, OpenAI ensures that pipelines are isolated from each other. This improves both reliability and security. If something goes wrong in one namespace, it does not automatically affect pipelines running elsewhere. Similarly, teams only have access to their own storage accounts and resources, reducing the chance of accidental interference.
3 - Watchdogs
Streaming pipelines are tightly connected to Kafka, the messaging system that provides the streams of data. However, Kafka itself is a dynamic system: topics may change, partitions may shift, or clusters may fail over. If a Flink job does not react to these changes, it can become unstable or even crash.
To address this, the OpenAI Engineering Team built cluster-local watchdog services. These watchdogs monitor Kafka’s topology and automatically adjust Flink pipelines when changes occur. For example, if a Kafka topic gains new partitions, the watchdog ensures that the Flink job scales appropriately to read from them. If a cluster fails, the watchdog helps the job adapt without requiring a manual restart.
See the diagram below:
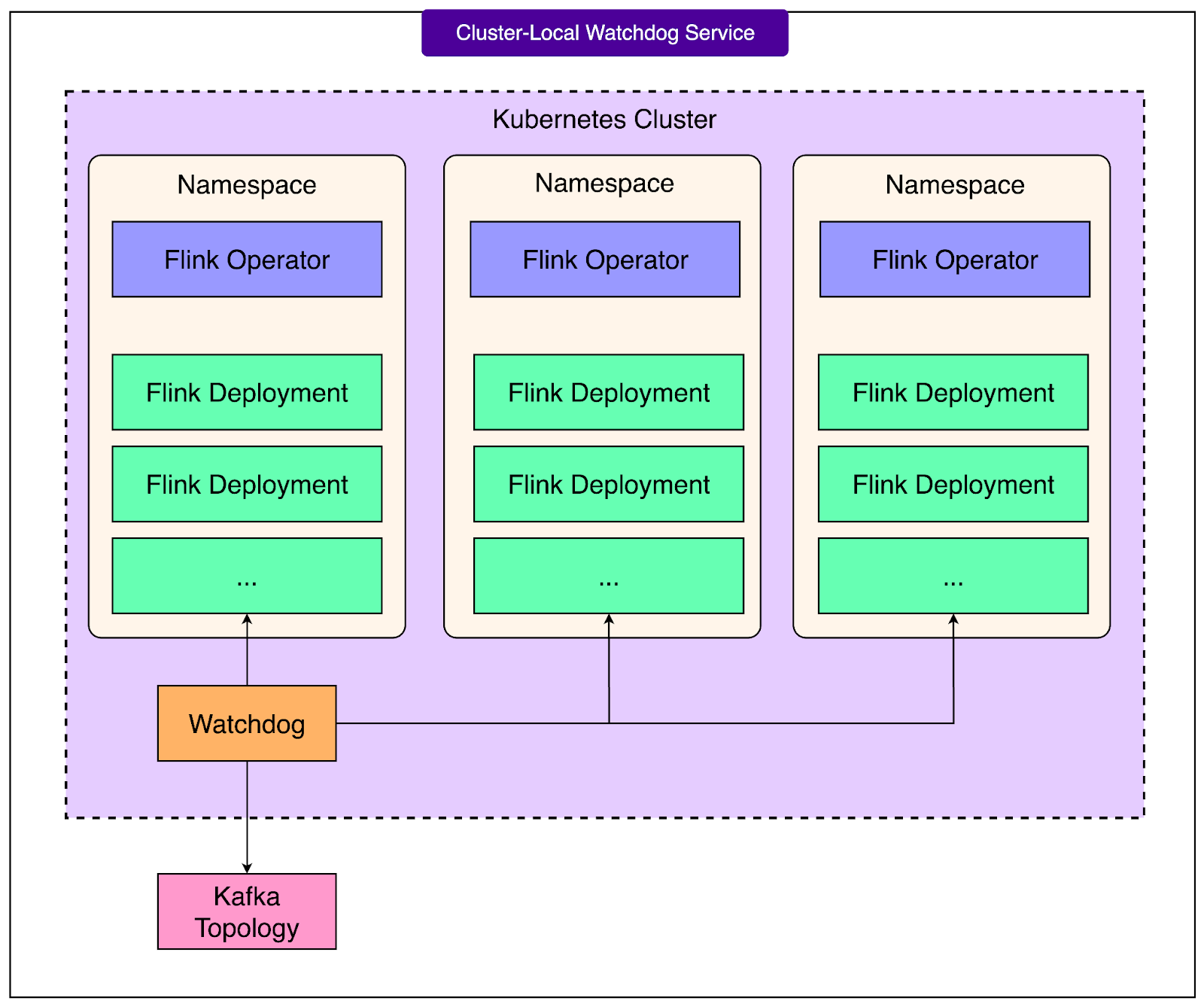
This automation is critical for keeping jobs running smoothly in a production environment where both Kafka and the underlying infrastructure may change at any time.
4 - State and Storage
One of the hardest problems in stream processing is managing state. State refers to the memory that a job keeps as it processes data, such as counts, windows, or intermediate results. If a job fails and restarts without its state, it may produce incorrect results.
OpenAI uses RocksDB, an embedded key-value database, to store local operator state within Flink. RocksDB is designed to handle large amounts of data efficiently and is widely used in streaming systems for this purpose.
However, local state is not enough. To make jobs resilient across clusters, OpenAI designed per-namespace blob storage accounts with high availability. These storage accounts are used to checkpoint and back up the state in a durable manner. Since they are separate from any single Kubernetes cluster, a Flink pipeline can move to a new cluster and recover its state from storage.
See the diagram below:
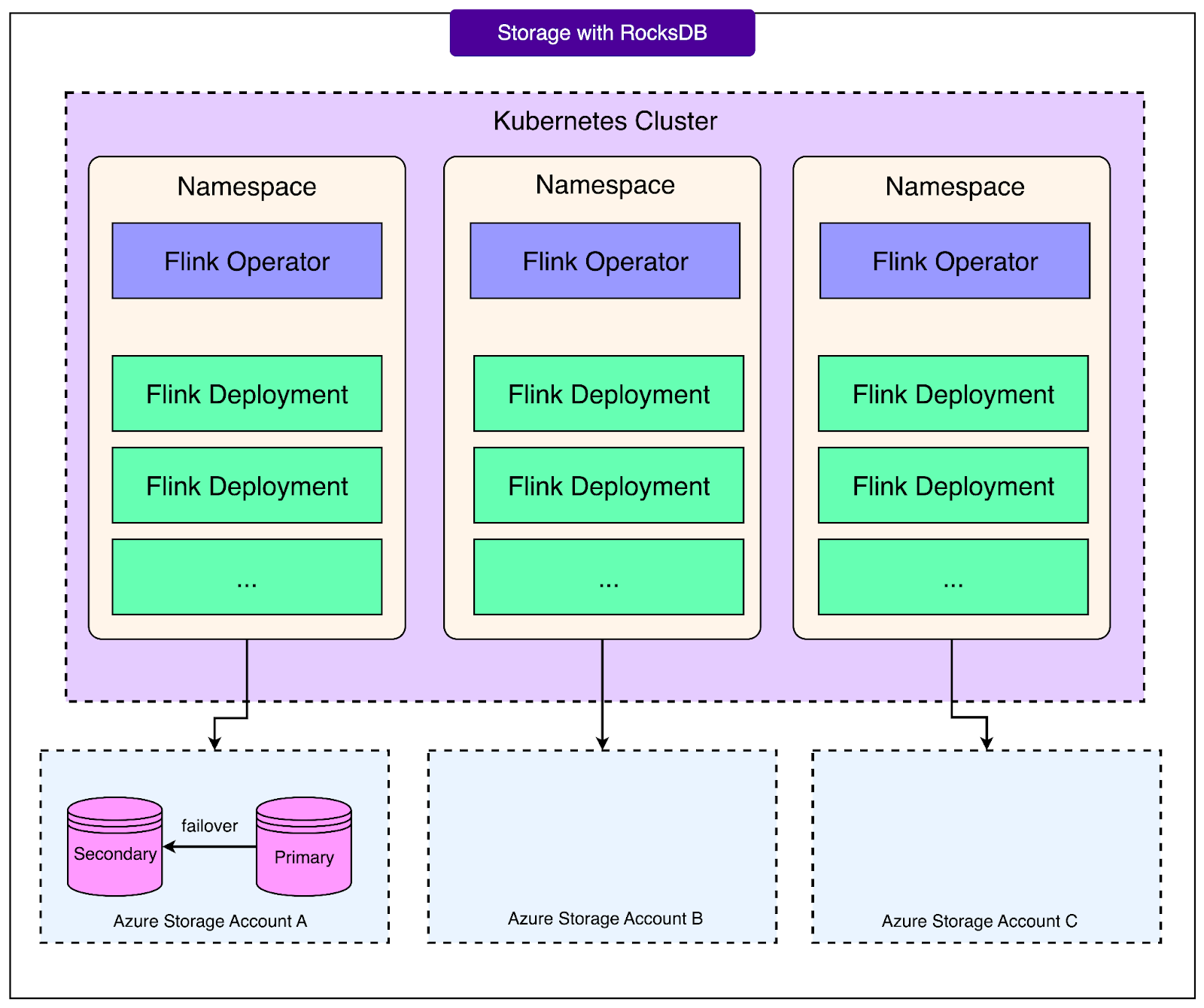
Finally, to improve security and reliability, the team upgraded hadoop-azure to version 3.4.1. This upgrade enables Azure workload identity authentication, which simplifies access to blob storage and avoids the need for managing long-lived credentials inside the cluster. In practice, this means jobs can securely authenticate to storage services without extra complexity for developers.
PyFlink: Python-Friendly Streaming
At the heart of OpenAI’s streaming platform is PyFlink, the Python interface for Apache Flink. Since Python has become the de facto language for AI and machine learning, making streaming accessible to Python developers was a priority for the OpenAI Engineering Team. With PyFlink, developers can write pipelines using familiar tools rather than learning a new language like Java or Scala.
PyFlink offers two major APIs as follows:
The DataStream API is designed for detailed control of streaming operations, where developers can write step-by-step instructions for how data should be transformed.
The Table/SQL API is more declarative. Developers can write SQL-like queries to process streams in a way that feels closer to working with a database. Both APIs integrate seamlessly with OpenAI’s existing Python monorepo, which means researchers can use their favorite Python libraries alongside streaming jobs without friction
There are two ways PyFlink can run Python operators: process mode and thread mode.
In process mode, Python code runs in its own process, which provides isolation but introduces extra communication overhead between the Java Virtual Machine (JVM) and Python. This can sometimes cause timeouts.
In thread mode, Python runs within the same process as Java, reducing overhead but also reducing isolation. Each mode involves trade-offs between efficiency and safety
Despite its usefulness, PyFlink still has limitations. Some performance-critical functions, such as certain operators and source/sink connectors, often need to be written in Java and wrapped for use in Python. Features like asynchronous I/O and streaming joins, which are common in advanced streaming use cases, are not yet supported in PyFlink’s DataStream API. These gaps remain an active area of development, both inside OpenAI and in the open-source Flink community.
By embracing PyFlink despite these limitations, OpenAI ensures that streaming feels natural for its Python-first research teams while still delivering the power of Flink underneath.
Kafka Connector Design
A critical part of OpenAI’s streaming platform is its integration with Kafka, the event streaming system that delivers continuous flows of data.
Kafka is used across OpenAI for logs, training data, and experiment results, so making Flink and Kafka work reliably together was essential. However, the OpenAI Engineering Team faced a unique complication: their Kafka deployment is multi-primary. Instead of a single primary Kafka cluster, they run several primaries for high availability.
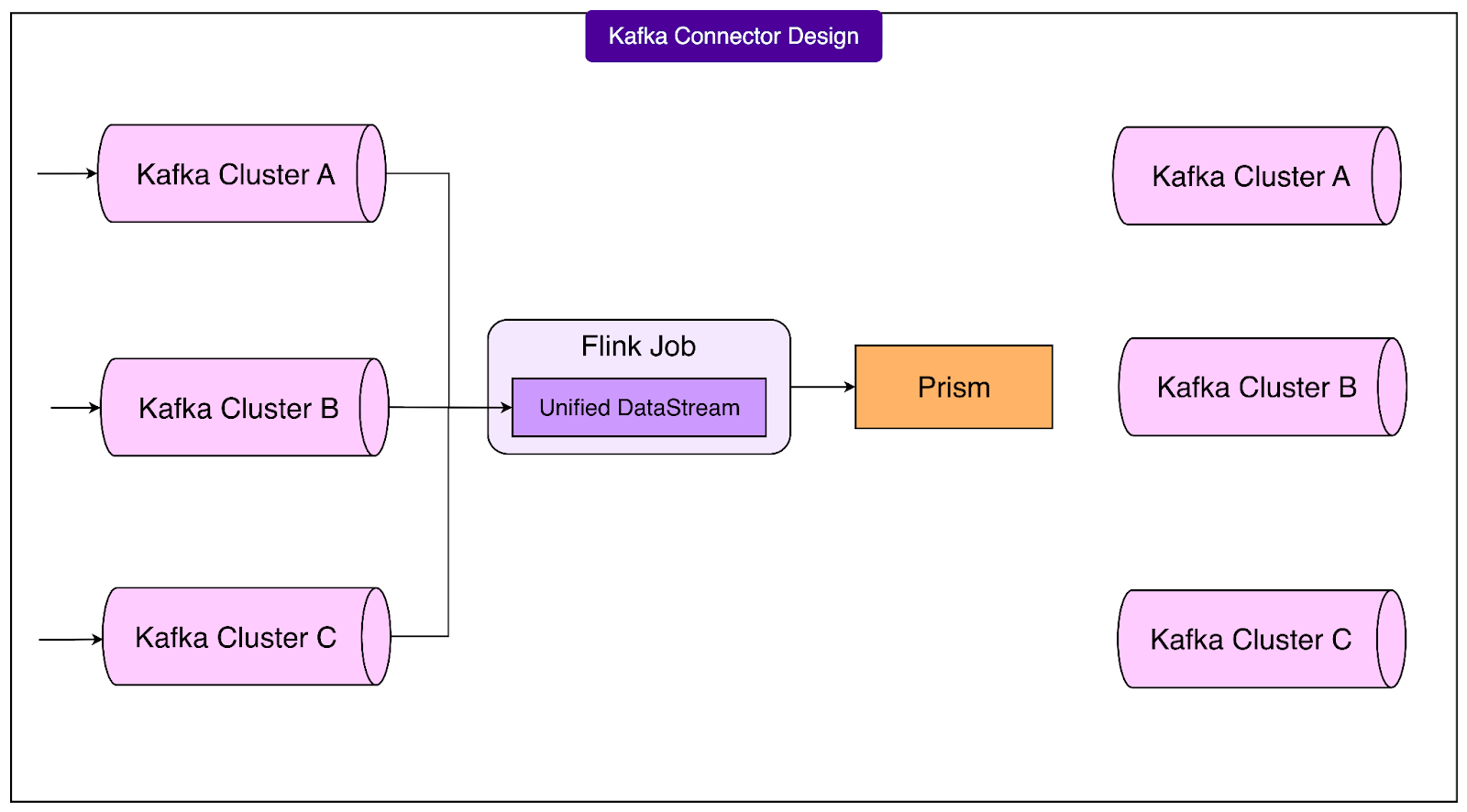
This design improves resilience because if one cluster goes down, others remain available. Unfortunately, it also creates a problem for Flink. By default, the Flink Kafka connector assumes there is only one primary cluster. If one of OpenAI’s clusters becomes unavailable, Flink interprets this as a fatal error and fails the entire pipeline. For mission-critical workloads, this behavior is unacceptable.
To handle this, the Engineering Team designed custom connectors with two key ideas.
First, for reading, they built a union of Kafka streams, allowing a job to consume data from multiple primaries at the same time.
Second, for writing, they introduced the Prism Sink, which can write data back into Kafka. One important limitation here is that the Prism Sink does not yet provide end-to-end exactly-once guarantees, meaning that in rare cases, duplicate or missing events can occur.
They also improved connector resilience through open-source contributions.
With FLINK-37366, the Kafka connector gained the ability to retry topic metadata fetches instead of failing immediately. They also built a dynamic Kafka source connector that can adjust at runtime, further improving reliability.
High-Availability and Failover
In large-scale cloud environments, failures are not rare events. Entire clusters can go down because of outages at the cloud provider level, and these disruptions can affect critical services. The OpenAI Engineering Team knew that their streaming platform needed to keep running even when such failures happened. This requirement shaped the way they designed high availability (HA) and failover.
The responsibility for handling these situations lies with the control plane.
If a Kubernetes cluster hosting Flink becomes unavailable, the control plane steps in to trigger a job failover. Rather than leaving the pipeline offline, it automatically restarts the job on another healthy cluster. This ensures continuity of service without requiring engineers to manually intervene during an outage. See the diagram below:
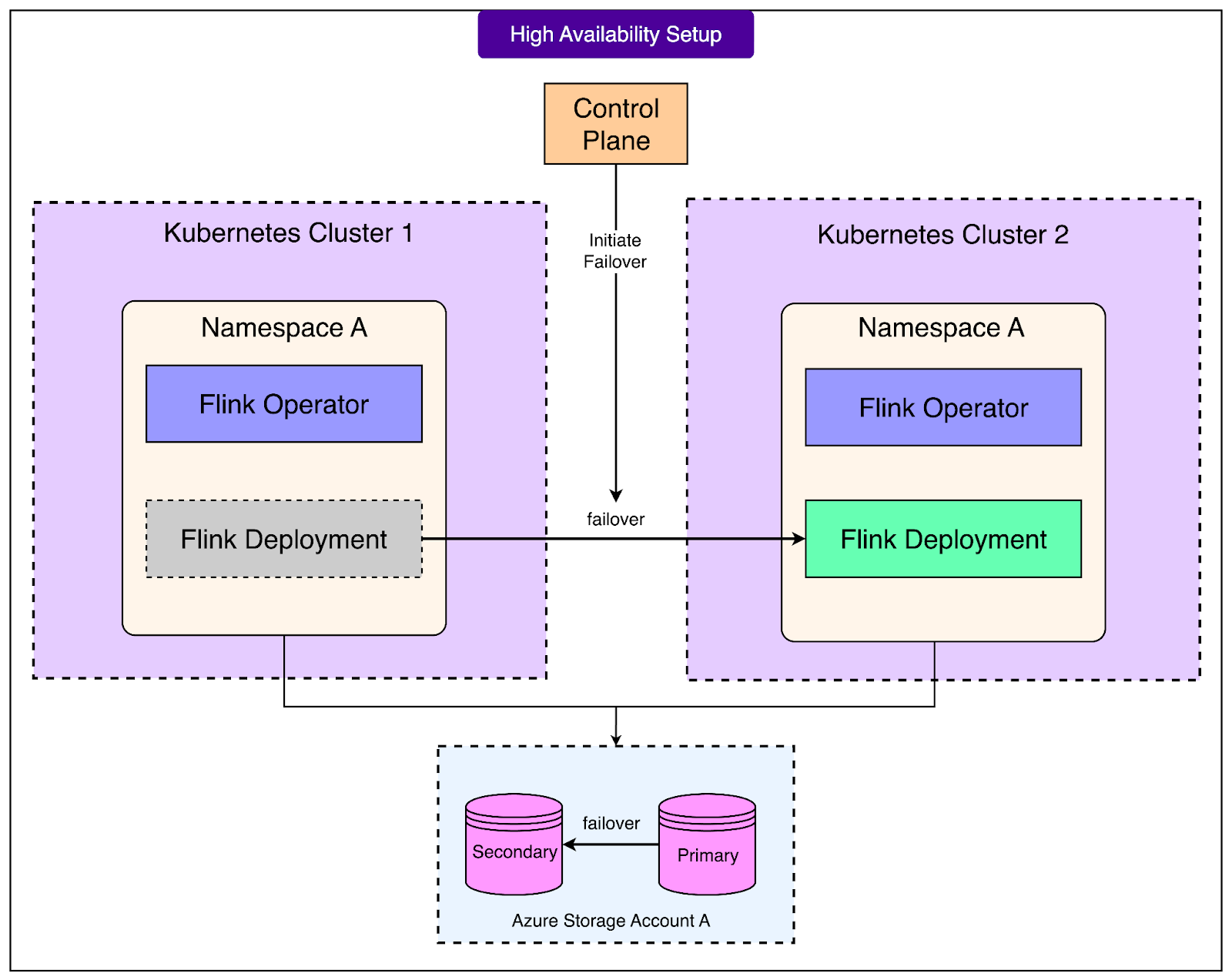
A key enabler of this design is decoupled state and HA storage. The state of a Flink job (the memory of what it has processed so far) is not tied to any single cluster. Instead, it is stored in separate, highly available blob storage accounts. Because of this separation, a pipeline can recover its state and continue processing even if it has to move between clusters.
Additionally, the state and HA storage accounts themselves can fail over independently. This means the platform is resilient at multiple levels: both the compute clusters and the storage layers can withstand outages without permanently breaking a pipeline.
By combining automatic failover with decoupled storage, OpenAI ensures that its most important streaming pipelines remain reliable, even in the face of inevitable cloud-wide failures.
Conclusion
Building a stream processing platform at the scale required by OpenAI is not just about running Apache Flink.
It is about carefully addressing the unique needs of AI research: Python-first workflows, resilience to cloud-wide failures, and seamless integration with Kafka. By layering PyFlink, Kubernetes orchestration, custom watchdog services, and decoupled state management, the OpenAI Engineering Team created a system that is both powerful and reliable.
The key takeaway is that streaming is no longer optional for cutting-edge AI development. Fresh training data and fast experiment feedback loops directly translate to better models and faster innovation. A platform that cannot recover gracefully from outages or adapt to changing infrastructure would quickly become a bottleneck.
At the same time, the system is still evolving. OpenAI has already contributed improvements back to the open-source community, such as fixes in PyFlink and enhancements to the Kafka connector. The roadmap points toward an even smoother experience: a dynamic control plane that automates failover, self-service streaming SQL for easier adoption, and core PyFlink enhancements like async I/O and streaming joins.
In short, OpenAI’s work shows how streaming can be made reliable and developer-friendly, paving the way for more resilient AI systems in the future.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Except for ChatGPT, you’re the only one who’s helped me understand so many things that were completely beyond my scope.